
Kurs
Orta Seviye Python
4 sa
1.4M
Temel veri yapılarını anladığınızı göstermek için çekirdek yapılara ve uygulamalarına çok güvenmeniz gerekir. Aşağıdaki gibi sorular, bu fikirleri açıklama becerinizi ve bilginizi ortaya koyacaktır.
Veri yapıları şu şekilde sınıflandırılır:
Diziler ve bağlı listeler, öğe gruplarını depolamanın iki yoludur; ancak farklı çalışırlar. Başlıca farklar şunlardır:
Yığın, yalnızca bir uçtan (tepe/top) öğe ekleyip çıkarabildiğiniz sıralı bir listedir. Son giren ilk çıkar (LIFO) ilkesini izler: En son eklenen öğe ilk çıkarılır.
Yığınlar; ifade değerlendirme, geri izleme (backtracking), bellek yönetimi ve fonksiyon çağrı/dönüşleri gibi birçok uygulamada kullanılabilir.
Python'da liste, kutudan çıktığı haliyle yığın gibi çalışır: append() itme (push), pop() ise üstteki öğeyi kaldırır.
my_stack = []
item = 1
my_stack.append(item)
my_stack.pop()Tepenin konumunu bir indeksle takip ederek bu işlemleri hızlı ve verimli kılabilirsiniz.
Kuyruk, ilk giren ilk çıkar (FIFO) yapısıdır — mağaza kuyruğu gibi; insanlar arkadan girer, önden çıkar.
Python'da bir kuyruğu farklı tekniklerle uygulayabilirsiniz:
Bir dizi veya liste kullanıp append() ve pop() yöntemlerinden yararlanarak:
my_queue = []
item = 1
# Enqueue
my_queue.append(item)
# Dequeue
my_queue.pop(0)collections kütüphanesindeki deque()'yi kullanarak; bu yapı append() ve pop() işlevlerini listelere göre daha hızlı gerçekleştirir:
from collections import deque
my_queue = deque()
item = 1
# Enqueue
my_queue.append(item)
# Dequeue
my_queue.popleft()Yerleşik queue.Queue modülünü kullanarak:
from queue import Queue
my_queue = Queue(maxsize = 3)
# Enqueue
my_queue.put(item)
# Dequeue
my_queue.get()İkili bir ağaç, her düğümün en fazla iki çocuğa sahip olduğu (sol ve sağ çocuk) bir veri yapısıdır. İkili arama ağacı (BST) ise belirgin sıralama özelliklerine sahip özel bir ikili ağaç türüdür: Her düğüm için sol alt ağaçtaki tüm anahtarlar daha küçük, sağ alt ağaçtaki tüm anahtarlar daha büyüktür ve her iki alt ağaç da kendi başlarına BST'dir.
Bu özellikler, arama, ekleme ve silme gibi işlemleri verimli kılar; dengeli ağaçlarda tipik olarak O(log n) zaman karmaşıklığına ulaşır.
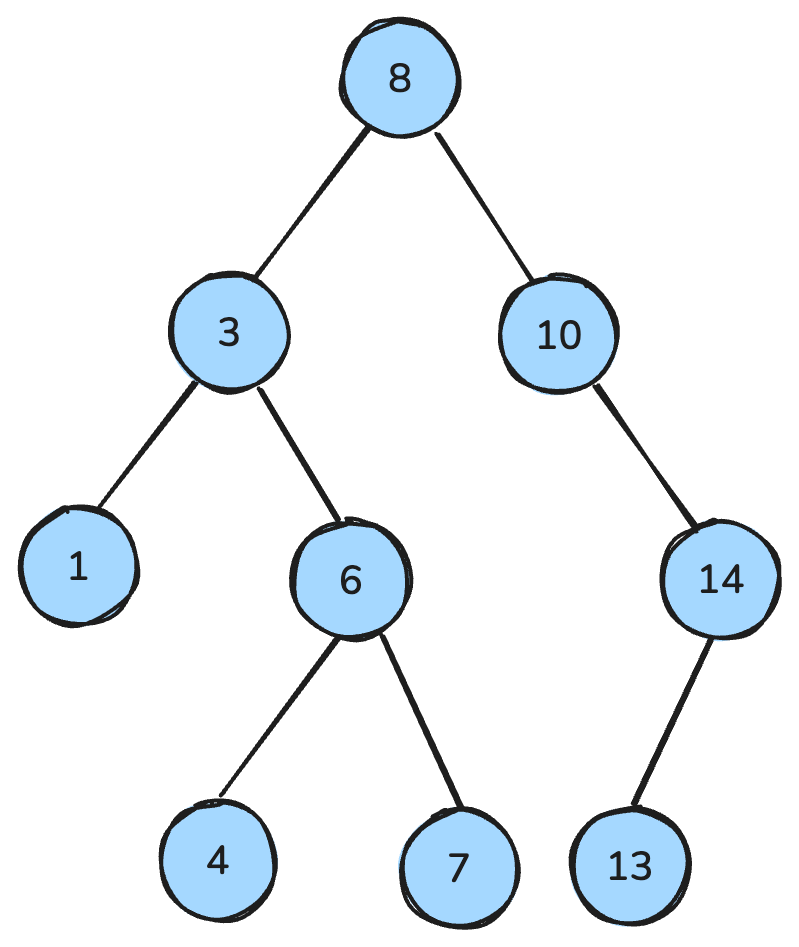
İkili arama ağacı. Görsel: Yazar.
Adresleme (hashing), herhangi bir boyuttaki veriyi bir adresleme işlevi kullanarak sabit boyutlu bir değere, yani adres değeri (hash value)ne dönüştüren bir tekniktir.
Adreslemenin yaygın bir kullanımı, anahtarları bir dizideki belirli konumlarla eşleştirmeye yardımcı olduğu adresleme tablolarıdır; bu da veriyi hızlıca bulup almayı kolaylaştırır. Adresleme; kriptografide parolaları güvenceye almaktan yinelemeleri kaldırarak (deduplication) veriyi düzenli tutmaya kadar pek çok alanda kullanılabilir.
Yığın, ağaç benzeri bir veri yapısıdır ve özel kuralları takip eder.
Maks-yığında her ebeveyn, çocuklarından büyük veya onlara eşittir; min-yığında ise her ebeveyn, çocuklarından küçük veya onlara eşittir.
Yığınlar genellikle, öğeleri önem veya değere göre sıralamaya yardımcı olan öncelik kuyruklarını oluşturmak için kullanılır. Ayrıca, veriyi verimli şekilde düzenlemenin bir yöntemi olan yığın sıralaması (heap sort) için de önemlidirler.
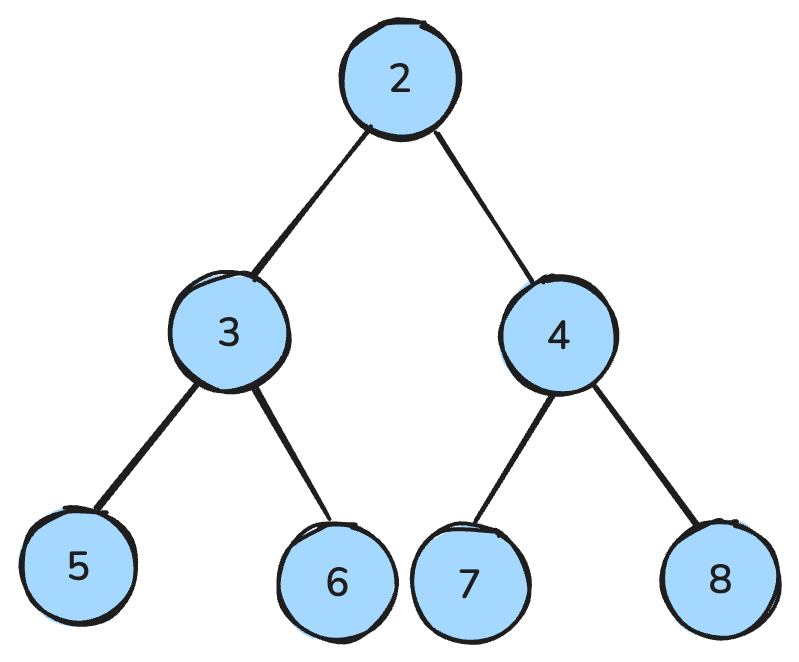
Tüm ebeveyn düğümlerin çocuklardan küçük olduğu bir min-yığın — görsel: Yazar.
Temelleri ele aldığımıza göre, bu temel kavramları uygulama ve kullanmadaki teknik yeterliliğinizi irdeleyen orta seviye veri yapısı mülakat sorularına geçelim.
Dengeli bir ikili arama ağacı, sol ve sağ alt ağaçlarının yüksekliklerini görece olarak eşit tutar. Bir BST'yi dengelemek; arama, ekleme ve silme işlemlerinin verimliliğini korumak için çok önemlidir.
AVL ağaçları ve kırmızı-siyah ağaçlar gibi teknikler, kendini dengeleme sağlamak için yaygın olarak kullanılır. AVL ağaçları, herhangi bir düğümün sol ve sağ alt ağaçları arasındaki yükseklik farkını en fazla 1'de tutarken, kırmızı-siyah ağaçlar daha sıkı denge kısıtlarına sahiptir.
Bir min-yığın genellikle bir liste ile desteklenir. İki temel işlem insert (bir öğe ekler ve yığın özelliğini geri kazandırmak için yukarı kabartır) ve extract_min (kökü kaldırır ve düzeni sağlamak için aşağı süzer):
class MinHeap:
def __init__(self):
self.heap = []
def __len__(self): # Get the size of the heap
return len(self.heap)
def __parent(self, i): # Get the parent index
return (i - 1) // 2
def __left(self, i): # Get the left child index
return 2 * i + 1
def __right(self, i): # Get the right child index
return 2 * i + 2
def __swap(self, i, j): # Swap two elements
self.heap[i], self.heap[j] = self.heap[j], self.heap[i]
def __heapify_up(self, i): # Restore min-heap property after insertion
while i > 0 and self.heap[i] < self.heap[self.__parent(i)]:
self.__swap(i, self.__parent(i))
i = self.__parent(i)
def __heapify_down(self, i): # Restore min-heap property after extraction
while True:
smallest = i
left = self.__left(i)
right = self.__right(i)
if left < len(self) and self.heap[left] < self.heap[smallest]:
smallest = left
if right < len(self) and self.heap[right] < self.heap[smallest]:
smallest = right
if smallest != i:
self.__swap(i, smallest)
i = smallest
else:
break
def insert(self, val): # Insert a value into the heap
self.heap.append(val)
self.__heapify_up(len(self) - 1)
def extract_min(self): # Extract the minimum value from the heap
if not self.heap:
return None
min_val = self.heap[0]
self.heap[0] = self.heap[-1]
self.heap.pop()
self.__heapify_down(0)
return min_valTrie, önek ağacı olarak da bilinen, verimli dize getirme ve önek eşleştirmesi için tasarlanmış ağaç tabanlı bir veri yapısıdır.
Bir trie'da her düğüm tek bir karakteri temsil eder ve kökten düğümlere giden yollar tam dizelere karşılık gelir. Otomatik tamamlama, yazım denetimi araçları ve sözlüklerin uygulanması gibi çeşitli uygulamalarda yaygın olarak kullanılır.
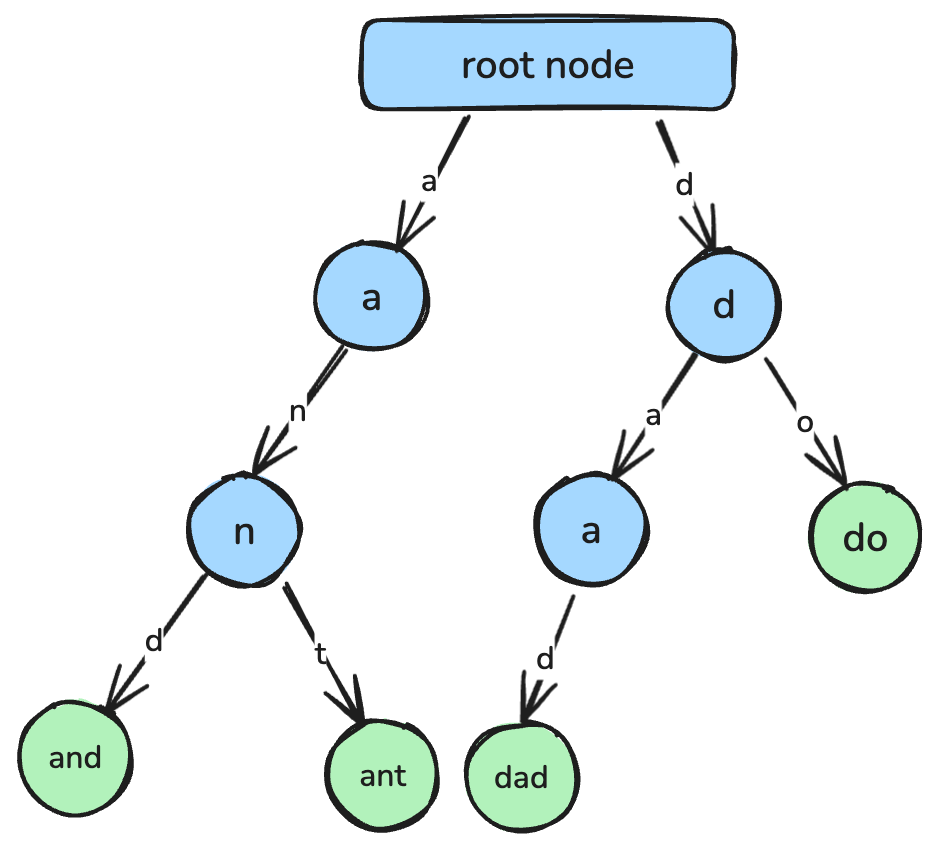
Bir trie: Her düğüm bir karakteri temsil eder ve birleşerek bir dizeyi oluşturur. Görsel: Yazar.
İki farklı anahtar aynı indekse adreslendiğinde çakışma meydana gelir.
Çakışmaları çözmek için birkaç yöntem vardır: zincirleme (chaining) — çakışan öğeler ilgili indekste bir bağlı listede tutulur — ve açık adresleme (open addressing) — doğrusal, karesel yoklama veya çift adresleme gibi yoklama yöntemleriyle dizide bir sonraki uygun yuva bulunur.
Bir graf, düğümler (tepe noktaları) kümesinin, kenarlarla birbirine bağlandığı bir veri yapısıdır. Bu yapı, çeşitli varlıklar arasındaki ilişkileri ve bağlantıları görselleştirmede kullanışlıdır.
Derinlik öncelikli arama (DFS), geri izleme yapmadan önce her dalı derinlemesine keşfeden bir algoritmadır. Açık bir yığın kullanılarak veya özyinelemeyle uygulanabilir. Zaman karmaşıklığı O(V + E)'dir; burada V tepe noktası, E kenar sayısıdır; yani tüm tepe ve kenarların incelenmesi gerekebilir.
Genişlik öncelikli arama (BFS), bir seviyedeki tüm düğümleri sistematik olarak keşfettikten sonra bir sonraki seviyeye geçer. Ağırlıksız graflarda en kısa yolu bulmada etkilidir ve genellikle bir kuyrukla uygulanır. DFS gibi, BFS de O(V + E) zaman karmaşıklığına sahiptir ve tüm tepe ve kenarların gözden geçirilmesini gerektirir.
Sıralama algoritmaları, verilerin verimli işlenmesi için temeldir — daha hızlı arama, gelişmiş veri analizi ve daha kolay görselleştirme sağlarlar. Aralarında seçim yaparken akılda tutulması gereken bazı temel ödünleşimler vardır:
İşte her birinin sade Python uygulamaları:
# Bubble sort — sorts in place
def bubble_sort(arr):
n = len(arr)
for i in range(n):
for j in range(0, n - i - 1):
if arr[j] > arr[j + 1]:
arr[j], arr[j + 1] = arr[j + 1], arr[j]
# Quick sort — sorts in place
def partition(arr, low, high):
pivot = arr[high]
i = low - 1
for j in range(low, high):
if arr[j] <= pivot:
i += 1
arr[i], arr[j] = arr[j], arr[i]
arr[i + 1], arr[high] = arr[high], arr[i + 1]
return i + 1
def quick_sort(arr, low, high):
if low < high:
pi = partition(arr, low, high)
quick_sort(arr, low, pi - 1)
quick_sort(arr, pi + 1, high)
# Merge sort — returns a new sorted list
def merge(left, right):
result = []
i = j = 0
while i < len(left) and j < len(right):
if left[i] <= right[j]:
result.append(left[i])
i += 1
else:
result.append[right[j])
j += 1
result.extend(left[i:])
result.extend(right[j:])
return result
def merge_sort(arr):
if len(arr) <= 1:
return arr
mid = len(arr) // 2
left_half = merge_sort(arr[:mid])
right_half = merge_sort(arr[mid:])
return merge(left_half, right_half)nums = [3, 1, 4, 1, 5, 9, 2, 6]
bubble_sort(nums) # sorts nums in place
quick_sort(nums, 0, len(nums) - 1) # also in place
sorted_nums = merge_sort(nums) # returns a new listMülakatta yukarıdaki cevap yeterlidir. Ancak öne çıkmak isterseniz, Python'un yerleşik sorted() ve list.sort() işlevlerinin, birleşim sıralaması ile ekleme sıralamasının bir melezi olan Timsort'u kullandığını belirtin. Bu yüzden üretim ortamında Python'da neredeyse hiç sıfırdan sıralama yazmazsınız.
Graflarda en kısa yolu bulmak için birkaç algoritma kullanılabilir.
Ağırlıksız graflar için genişlik öncelikli arama, düğümleri katman katman etkili biçimde keşfeder. Ağırlıklı graflarda ve negatif olmayan kenarlarda Dijkstra algoritması en yakın tepeyi önce değerlendirerek en kısa yolu belirler.
A* arama algoritması, kalan maliyetleri tahmin etmek için sezgisel yöntemler kullanarak verimliliği artırır. Algoritma seçimi, grafın özelliklerine ve özel problem gereksinimlerine bağlıdır.
Daha kıdemli roller arayanlar veya özelleşmiş/karmaşık veri yapılarında derin bilgi sergilemek isteyenler için bazı ileri düzey mülakat sorularını inceleyelim.
Dinamik programlama, karmaşık problemleri, üst üste binen daha küçük alt problemlere bölerek çözmeye yarayan bir yöntemdir. Her seferinde baştan başlamak yerine, bu küçük parçaların çözümlerini saklarsınız; böylece aynı hesaplamaları tekrarlamanız gerekmez.
Bu yöntem, iki dize arasındaki en uzun ortak alt diziyi bulmak veya bir ızgarada belirli bir noktaya ulaşmanın minimum maliyetini hesaplamak gibi durumlarda çok kullanışlıdır.
B-ağaçları, disk erişimini verimli hale getirmek için tasarlanmış dengeli ağaç veri yapılarıdır. Bazı özellikleri şunlardır:
İkili arama ağaçlarına göre çeşitli avantajlar sunarlar:
Topolojik sıralama, bir yönlendirilmiş döngüsüz grafın (DAG) tepe noktalarını, tepe u'dan tepe v'ye bir kenar varsa u’nun sıralamada v’den önce görüneceği şekilde düzenleyen bir algoritmadır. Görev zamanlamada — bağımlılıkları gözeterek görevlerin hangi sırayla çalıştırılacağını belirlemede — ve derleme sistemleri, paket yöneticileri ile ders önkoşul planlamasında yaygın olarak kullanılır.
Bir min-yığın, bir öncelik kuyruğunun belirli bir uygulamasıdır ve her düğümün değerinin çocuklarının değerlerinden küçük veya onlara eşit olduğu, minimum öğeyi bulma ve çıkarma işlemlerini verimli kılan eksiksiz bir ikili ağaç olarak tanımlanır.
Öte yandan, bir öncelik kuyruğu, öğelerin bir öncelikle eklendiği ve çıkarılmalarının öncelik sırasına göre yapıldığı soyut bir veri yapısıdır. Bu işlemleri verimli yönettiğinden, öncelik kuyruklarını uygulamanın yaygın bir yolu min-yığınlardır.
Ayrık-küme veri yapısı, union-find olarak da bilinir ve ayrık kümeler koleksiyonunu tutar. Bu veri yapısı iki temel işlemi destekler:
Ayrık kümelerin birçok uygulaması vardır; ancak en yaygınları bir grafın minimum kapsayan ağacını bulmak için Kruskal algoritması ve bir graf içinde bağlı bileşenleri belirlemek için ağ akışı problemidir.
Segment ağacı, bir dizi üzerinde aralık (range) sorgularını ve güncellemelerini verimli hale getirmek için tasarlanmış bir veri yapısıdır. Dizideki belirli bir öğe aralığı üzerinde toplam, minimum, maksimum veya en büyük ortak bölen gibi işlemleri tekrarla gerçekleştirmemiz gereken senaryolarda özellikle kullanışlıdır.
İkili ağaç olarak inşa edilir; her düğüm dizinin bir bölümünü temsil eder. Ağacın yaprakları dizinin tekil öğelerine karşılık gelirken, iç düğümler, gerçekleştirilen işleme göre çocuk düğümlerin değerlerini birleştiren bilgileri saklar. Hem güncellemeler hem de sorgular için O(log n) zaman karmaşıklığına ulaşırlar.
Bir son ek ağacı, bir dizgenin her son ekini depolar; böylece desen sorguları, metnin uzunluğu yerine desenin uzunluğuyla orantılı sürede yanıtlanır. Gerçek bir son ek ağacı, O(n) alan elde etmek için kenar sıkıştırması kullanır ve tipik olarak Ukkonen'in algoritmasıyla inşa edilir — ancak bu, 45 dakikada sıfırdan kodlamanız beklenecek kadar basit değildir.
Yaygın bir uzlaşma, düğüm başına bir karakter depolayan daha basit son ek trie’ıdır. O(n²) alan kullanır ancak yazması ve açıklaması çok daha kolaydır. Mülakatta püf nokta, bu ödünleşimi bilmek ve bunu açıkça ifade etmektir.
İşte sade bir Python uygulaması:
class SuffixTrieNode:
def __init__(self):
self.children = {} # Map of character -> child node
self.indices = [] # Starting positions of suffixes passing through this node
class SuffixTrie:
def __init__(self, text):
self.root = SuffixTrieNode()
self.text = text + "$" # Append a unique terminator
self._build()
def _build(self):
"""Insert every suffix of the text into the trie."""
for i in range(len(self.text)):
self._insert_suffix(i)
def _insert_suffix(self, index):
node = self.root
for i in range(index, len(self.text)):
c = self.text[i]
if c not in node.children:
node.children[c] = SuffixTrieNode()
node = node.children[c]
node.indices.append(index)
def search(self, pattern):
"""Return all starting positions where `pattern` appears in the text."""
node = self.root
for c in pattern:
if c not in node.children:
return []
node = node.children[c]
return node.indicesDörtlü ağaçlar, iki boyutlu bir uzayı dört eşit çeyreğe özyinelemeli olarak bölen hiyerarşik ağaç veri yapılarıdır. Bu mekânsal bölümlendirme tekniği; görüntü işleme, oyunlarda çarpışma tespiti ve coğrafi bilgi sistemlerinde mekânsal verilerin verimli depolanması ve alınması gibi uygulamalar için oldukça etkilidir.
Veri yapısı bilginizi göstermek önemlidir; ancak onları ne zaman ve nasıl doğru kullanacağınızı sergilemek mülakatta sizi öne çıkarır. Bu bölümde, veri yapısı bilginizi pratik durumlara nasıl uygulayacağınızı gözden geçireceğiz.
Sorunun gerçek zamanlı doğası nedeniyle, bu zorluk verimli veri yapıları gerektirecektir.
Deneyimime göre, coğrafi veriler için dörtlü ağaçlar, aday eşleşmeleri mesafe ve yolcu aciliyeti temelinde sıralamak için öncelik kuyrukları ve sürücü ile yolcu konumlarının verimli şekilde bulunması için adresleme tabloları kullanırdım.
Kullanıcı davranışına dayalı ürün önerilerini etkili biçimde yapmak için veri yapılarının bir kombinasyonundan yararlanabiliriz.
Seyrek bir kullanıcı-öğe matrisi, kullanıcı-ürün etkileşimlerini depolarken; adresleme tabloları kullanıcıları ve öğeleri verimli şekilde eşler. Öncelik kuyrukları önerileri sıralar ve graf yapıları, topluluk tespiti gibi daha gelişmiş analizler için kullanıcı-öğe ilişkilerini modelleyebilir.
Bir graf veri yapısı, sosyal ağ platformunda istenmeyen hesapları tespit ve kaldırmada oldukça etkili olabilir. Kullanıcıları düğüm, bağlantıları kenar olarak temsil ederek ağ topolojisini analiz edebilirsiniz. Yoğun bağlı kümeleri, izole düğümleri ve etkinlikte ani artışları belirlemek, şüpheli hesapları işaretlemeye yardımcı olur.
Gerçek zamanlı bir sohbet uygulamasında, veri yapılarını birlikte kullanırdım.
Adresleme tabloları, kullanıcı kimliklerini ve karşılık gelen bağlantı listelerini saklayarak mesaj gönderilecek kullanıcıların hızlıca bulunmasını sağlar. Kuyruklar, her kullanıcı için mesaj sırasını koruyarak iletimin gönderim sırasına göre yapılmasını garanti eder. Ayrıca, kullanıcıların çevrimiçi/çevrimdışı durumlarını verimli biçimde saklayıp almak için AVL ağaçları gibi ağaçlar kullanılabilir; bu da kullanıcı kullanılabilirliğinin gerçek zamanlı güncellenmesini sağlar.
Bir yazım denetleyicisinde, verimli kelime araması çok önemlidir. Bir trie ideal bir veri yapısıdır. Trie'daki her düğüm bir harfi temsil eder ve trie içindeki yollar kelimeleri oluşturur. Bu, önek tabanlı hızlı aramalar sağlar ve yazım denetleyicisinin hatalı yazılmış kelimeler için hızlıca düzeltme önermesine imkân tanır.
Bu özel senaryoda, segment ağaçları mükemmel bir seçimdir. Aralık sorgularını ve güncellemeleri verimli şekilde ele alırlar. Oyun haritasını, her öğenin bir ızgara hücresine karşılık geldiği 1B bir dizi olarak temsil edebiliriz. Her hücre, bir yapının varlığına/yokluğuna ilişkin bilgi tutabilir.
Veri yapıları mülakatına hazırlanmanın zorlayıcı olabileceğini biliyorum; ancak yapılandırılmış bir yaklaşım bunu daha yönetilebilir kılabilir!
Diziler, bağlı listeler, yığınlar, kuyruklar, ağaçlar, graflar ve adresleme tabloları gibi veri yapılarına ilişkin temel kavramlarda ustalaşmaya odaklanın. İlkelerini, verileri nasıl yönettiklerini ve ekleme, silme, arama gibi işlemlerin zaman karmaşıklıklarını anlayın.
Kavramları bilmek iyidir ama yeterli değildir. Bu veri yapılarını sıfırdan nasıl uygulayacağınızı da bilmelisiniz. DataCamp kursları ile etkileşime girerek, problem çözme becerilerinizi geliştiren kodlama meydan okumalarından yararlanabilirsiniz.
Veri yapıları arasındaki ödünleşimleri anlamak kritik önemdedir. Örneğin, diziler hızlı erişim sağlar ancak ekleme ve silmeler maliyetli olabilir; bağlı listeler verimli değişiklik imkânı sunar ancak erişim için dolaşım gerekir. Mülakatta bu ödünleşimleri tartışmaya hazır olun.
Unutmayın, iletişim en az kod kadar önemlidir. Mülakatçılar, açıklamalarını dinleyiciye uyarlayabilen adaylar arar. DataFramed podcast'inde veri rollerinin geleceği tartışılırken de belirtildiği gibi:
Her türden içgörüyü, altı yaşındaki bir çocuğun anlayabileceği şekilde ve beni ya da daha da teknik birini tatmin edecek şekilde sunabilmeniz gerekir. Yani gerçekten konunuza hâkimseniz, onu gerçekten basitleştirebilirsiniz; ama aynı zamanda öyle karmaşık hale de getirebilirsiniz ki, dürüst olmak gerekirse, yalnızca teknik uzmanlığı gerçekten çok yüksek olan insanlar anlayabilir.
Mo Chen, Data & Analytics Manager at NatWest Group
Bu kurslarla veri yapıları ve Python temelleri hakkında daha fazlasını öğrenin!
Kurs
Kurs
Kurs
blog
Dario Radečić
15 dk.
blog
Abid Ali Awan
14 dk.
Eğitim
Adel Nehme
Eğitim
Kurtis Pykes
