
Courses
Python nâng cao
4 giờ
1.4M
Để thể hiện hiểu biết về các cấu trúc dữ liệu cơ bản, bạn cần tự tin vào các cấu trúc cốt lõi và cách hiện thực chúng. Những câu hỏi sau sẽ kiểm tra khả năng giải thích ý tưởng và thể hiện kiến thức của bạn.
Cấu trúc dữ liệu được phân loại như sau:
Mảng và danh sách liên kết đều là cách lưu trữ nhóm phần tử, nhưng chúng hoạt động khác nhau. Dưới đây là những khác biệt chính:
Ngăn xếp là một danh sách có thứ tự, nơi bạn thêm và loại bỏ phần tử ở một đầu gọi là đỉnh (top). Nó tuân theo nguyên tắc vào sau ra trước (LIFO): phần tử được thêm gần nhất sẽ được lấy ra đầu tiên.
Ngăn xếp được dùng trong nhiều ứng dụng như đánh giá biểu thức, quay lui (backtracking), quản lý bộ nhớ, và lời gọi/trả về hàm.
Trong Python, list hoạt động như một ngăn xếp ngay từ đầu: append() là push, và pop() loại bỏ phần tử trên cùng.
my_stack = []
item = 1
my_stack.append(item)
my_stack.pop()Bằng cách theo dõi vị trí của đỉnh bằng chỉ số, bạn có thể thực hiện các thao tác này nhanh và hiệu quả.
Hàng đợi là cấu trúc vào trước ra trước (FIFO) — giống như xếp hàng ở cửa hàng: người vào ở cuối và ra ở đầu.
Trong Python, bạn có thể triển khai hàng đợi bằng nhiều cách:
Dùng mảng hoặc list và tận dụng các phương thức append() và pop():
my_queue = []
item = 1
# Enqueue
my_queue.append(item)
# Dequeue
my_queue.pop(0)Dùng deque() từ thư viện collections, thực hiện append() và pop() nhanh hơn list:
from collections import deque
my_queue = deque()
item = 1
# Enqueue
my_queue.append(item)
# Dequeue
my_queue.popleft()Dùng mô-đun tích hợp sẵn queue.Queue:
from queue import Queue
my_queue = Queue(maxsize = 3)
# Enqueue
my_queue.put(item)
# Dequeue
my_queue.get()Cây nhị phân là một cấu trúc dữ liệu trong đó mỗi nút có tối đa hai con: con trái và con phải. Còn cây tìm kiếm nhị phân (BST) là một loại cây nhị phân cụ thể có các thuộc tính sắp xếp rõ ràng: Đối với mỗi nút, tất cả các khóa ở cây con bên trái nhỏ hơn, tất cả các khóa ở cây con bên phải lớn hơn, và cả hai cây con đều là BST.
Các thuộc tính này giúp thực hiện hiệu quả các thao tác như tìm kiếm, chèn và xóa, thường đạt độ phức tạp thời gian O(log n) trong các cây cân bằng.
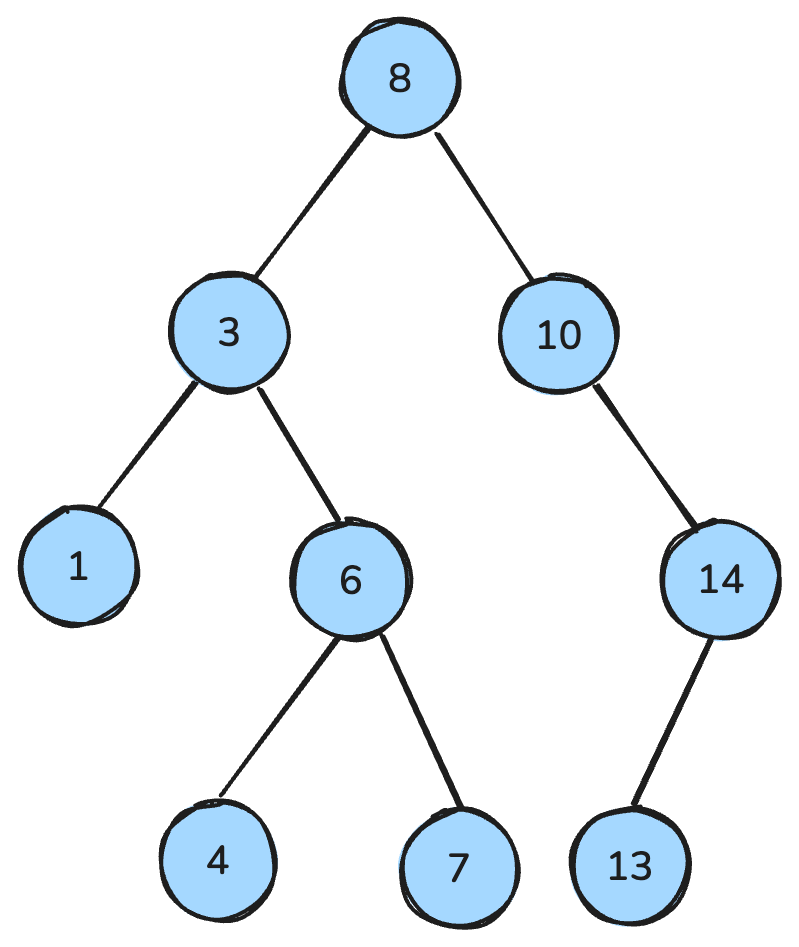
Cây tìm kiếm nhị phân. Ảnh: Tác giả.
Băm là kỹ thuật nhận dữ liệu có kích thước bất kỳ và chuyển nó thành một giá trị có kích thước cố định gọi là giá trị băm thông qua một hàm băm.
Một ứng dụng phổ biến của băm là trong bảng băm, nơi nó giúp ánh xạ khóa tới vị trí cụ thể trong mảng, giúp tìm và truy xuất dữ liệu nhanh chóng. Băm có nhiều ứng dụng, từ hỗ trợ bảo mật mật khẩu trong mật mã học đến tổ chức dữ liệu thông qua khử trùng lặp.
Heap là một cấu trúc dữ liệu giống cây và tuân theo các quy tắc đặc biệt.
Trong max-heap, mỗi nút cha lớn hơn hoặc bằng các nút con; trong min-heap, mỗi nút cha nhỏ hơn hoặc bằng các nút con.
Heap thường được dùng để tạo hàng đợi ưu tiên (priority queue), giúp sắp xếp phần tử theo mức độ quan trọng hoặc giá trị. Chúng cũng quan trọng trong sắp xếp heap (heap sort), một phương pháp tổ chức dữ liệu hiệu quả.
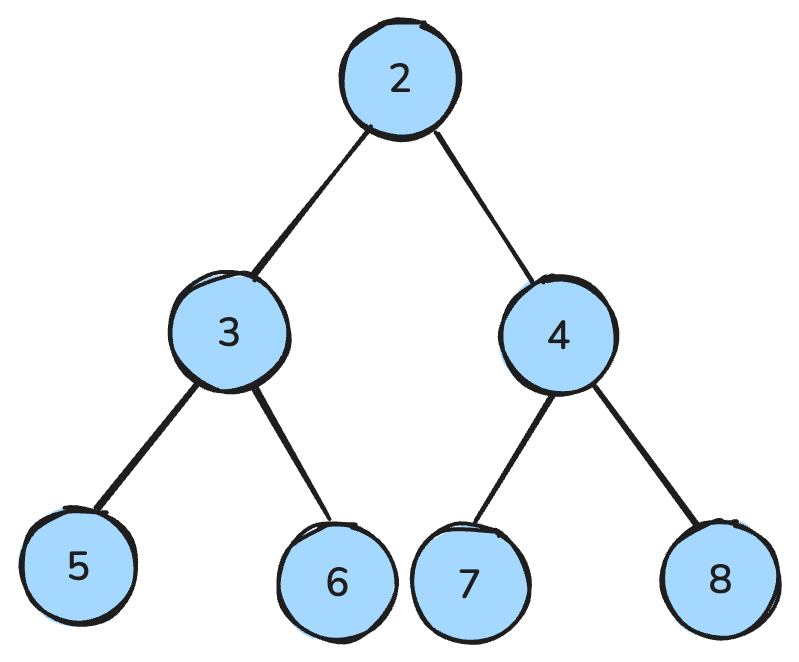
Min-heap là nơi tất cả các nút cha nhỏ hơn các nút con — ảnh: Tác giả.
Sau khi đã bao quát phần cơ bản, hãy chuyển sang một số câu hỏi mức trung cấp để khám phá khả năng triển khai và sử dụng các khái niệm nền tảng này của bạn.
Một cây tìm kiếm nhị phân cân bằng duy trì chiều cao tương đối đồng đều giữa cây con trái và phải. Cân bằng BST rất quan trọng để giữ cho các thao tác tìm kiếm, chèn và xóa hiệu quả.
Các kỹ thuật như cây AVL và cây đỏ-đen thường được dùng để tự cân bằng. Cây AVL duy trì chênh lệch chiều cao tối đa 1 giữa hai cây con của bất kỳ nút nào, trong khi cây đỏ-đen có các ràng buộc cân bằng chặt chẽ khác.
Min-heap thường được hỗ trợ bởi một list. Hai thao tác chính là insert (thêm phần tử và đẩy nó lên để khôi phục thuộc tính heap) và extract_min (loại bỏ gốc và sàng xuống để khôi phục trật tự):
class MinHeap:
def __init__(self):
self.heap = []
def __len__(self): # Get the size of the heap
return len(self.heap)
def __parent(self, i): # Get the parent index
return (i - 1) // 2
def __left(self, i): # Get the left child index
return 2 * i + 1
def __right(self, i): # Get the right child index
return 2 * i + 2
def __swap(self, i, j): # Swap two elements
self.heap[i], self.heap[j] = self.heap[j], self.heap[i]
def __heapify_up(self, i): # Restore min-heap property after insertion
while i > 0 and self.heap[i] < self.heap[self.__parent(i)]:
self.__swap(i, self.__parent(i))
i = self.__parent(i)
def __heapify_down(self, i): # Restore min-heap property after extraction
while True:
smallest = i
left = self.__left(i)
right = self.__right(i)
if left < len(self) and self.heap[left] < self.heap[smallest]:
smallest = left
if right < len(self) and self.heap[right] < self.heap[smallest]:
smallest = right
if smallest != i:
self.__swap(i, smallest)
i = smallest
else:
break
def insert(self, val): # Insert a value into the heap
self.heap.append(val)
self.__heapify_up(len(self) - 1)
def extract_min(self): # Extract the minimum value from the heap
if not self.heap:
return None
min_val = self.heap[0]
self.heap[0] = self.heap[-1]
self.heap.pop()
self.__heapify_down(0)
return min_valTrie, còn gọi là cây tiền tố (prefix tree), là cấu trúc dữ liệu dạng cây được thiết kế để truy xuất chuỗi và khớp tiền tố hiệu quả.
Trong trie, mỗi nút biểu diễn một ký tự, và các đường đi từ gốc tới các nút tương ứng với các chuỗi hoàn chỉnh. Trie thường được dùng trong tính năng tự động hoàn thành, công cụ kiểm tra chính tả và triển khai từ điển.
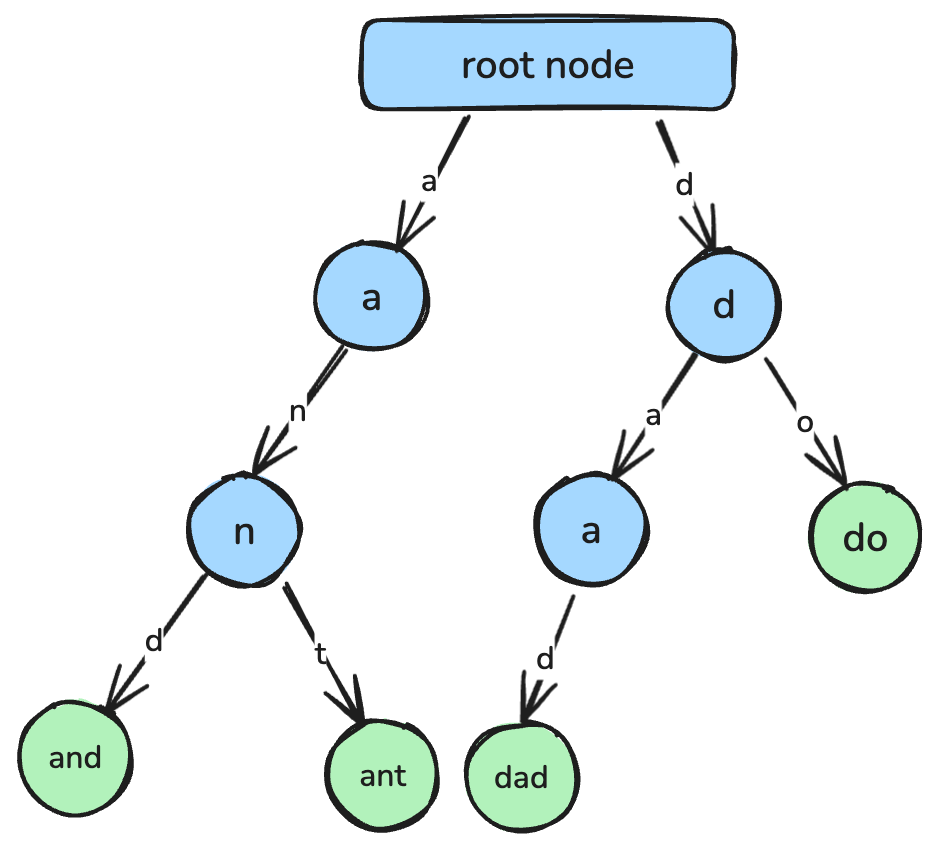
Trie, nơi mỗi nút biểu diễn một ký tự kết nối lại để tạo thành chuỗi. Ảnh: Tác giả.
Va chạm xảy ra khi hai khóa khác nhau băm tới cùng một chỉ số.
Có một số phương pháp xử lý va chạm, gồm chaining (xâu chuỗi), trong đó các phần tử va chạm được lưu trong danh sách liên kết tại chỉ số tương ứng; và open addressing (địa chỉ mở), tức là tìm ô trống tiếp theo trong mảng thông qua các phương pháp thăm dò như thăm dò tuyến tính, thăm dò bậc hai hoặc băm kép.
Một đồ thị là một cấu trúc dữ liệu gồm tập hợp các đỉnh (nút) được liên kết bởi các cạnh. Cấu trúc này hữu ích để minh họa mối quan hệ và kết nối giữa các thực thể khác nhau.
Duyệt sâu trước (DFS) là thuật toán khám phá đồ thị hoặc cây bằng cách đi sâu theo từng nhánh trước khi quay lui. Có thể triển khai bằng ngăn xếp tường minh hoặc đệ quy. Độ phức tạp thời gian là O(V + E), với V là số đỉnh và E là số cạnh, nghĩa là có thể phải duyệt toàn bộ đỉnh và cạnh.
Duyệt rộng trước (BFS) lần lượt khám phá tất cả các nút ở cùng một mức độ sâu trước khi chuyển sang mức tiếp theo. Nó hiệu quả để tìm đường đi ngắn nhất trong đồ thị không trọng số và thường được triển khai bằng hàng đợi. Tương tự DFS, BFS có độ phức tạp O(V + E), cần xem xét tất cả đỉnh và cạnh.
Các thuật toán sắp xếp rất cần thiết cho xử lý dữ liệu hiệu quả — chúng cho phép tìm kiếm nhanh hơn, phân tích dữ liệu tốt hơn và trực quan hóa dữ liệu dễ dàng hơn. Khi lựa chọn giữa chúng, có một vài đánh đổi chính cần lưu ý:
Dưới đây là các triển khai Python gọn gàng cho từng thuật toán:
# Bubble sort — sorts in place
def bubble_sort(arr):
n = len(arr)
for i in range(n):
for j in range(0, n - i - 1):
if arr[j] > arr[j + 1]:
arr[j], arr[j + 1] = arr[j + 1], arr[j]
# Quick sort — sorts in place
def partition(arr, low, high):
pivot = arr[high]
i = low - 1
for j in range(low, high):
if arr[j] <= pivot:
i += 1
arr[i], arr[j] = arr[j], arr[i]
arr[i + 1], arr[high] = arr[high], arr[i + 1]
return i + 1
def quick_sort(arr, low, high):
if low < high:
pi = partition(arr, low, high)
quick_sort(arr, low, pi - 1)
quick_sort(arr, pi + 1, high)
# Merge sort — returns a new sorted list
def merge(left, right):
result = []
i = j = 0
while i < len(left) and j < len(right):
if left[i] <= right[j]:
result.append(left[i])
i += 1
else:
result.append(right[j])
j += 1
result.extend(left[i:])
result.extend(right[j:])
return result
def merge_sort(arr):
if len(arr) <= 1:
return arr
mid = len(arr) // 2
left_half = merge_sort(arr[:mid])
right_half = merge_sort(arr[mid:])
return merge(left_half, right_half)nums = [3, 1, 4, 1, 5, 9, 2, 6]
bubble_sort(nums) # sorts nums in place
quick_sort(nums, 0, len(nums) - 1) # also in place
sorted_nums = merge_sort(nums) # returns a new listTrong phỏng vấn, câu trả lời trên là đủ. Nhưng nếu bạn muốn nổi bật, hãy nhắc rằng sorted() và list.sort() tích hợp sẵn của Python dùng Timsort, một biến thể lai giữa merge sort và insertion sort. Đó là lý do bạn hầu như không bao giờ viết thuật toán sắp xếp từ đầu trong môi trường Python sản xuất.
Có nhiều thuật toán để tìm đường đi ngắn nhất trong đồ thị.
Với đồ thị không trọng số, duyệt rộng trước khám phá các nút theo từng lớp rất hiệu quả. Trong đồ thị có trọng số với cạnh không âm, thuật toán Dijkstra xác định đường đi ngắn nhất bằng cách xét trước đỉnh gần nhất.
Thuật toán A* cải thiện hiệu quả bằng cách dùng heuristic để ước lượng chi phí còn lại. Việc chọn thuật toán phụ thuộc vào đặc điểm đồ thị và yêu cầu bài toán cụ thể.
Hãy khám phá một số câu hỏi nâng cao dành cho ứng viên nhắm tới vị trí cấp cao hoặc muốn thể hiện hiểu biết sâu về các cấu trúc dữ liệu chuyên biệt hay phức tạp.
Lập trình động là phương pháp giải bài toán phức tạp bằng cách chia chúng thành các bài toán con chồng lặp nhỏ hơn. Thay vì làm lại từ đầu mỗi lần, bạn lưu lời giải của các phần nhỏ đó, giúp tránh lặp lại tính toán.
Phương pháp này rất hữu ích để tìm dãy con chung dài nhất giữa hai chuỗi hoặc tìm chi phí tối thiểu để tới một điểm cụ thể trên lưới.
B-tree là cấu trúc dữ liệu cây cân bằng được thiết kế để truy cập đĩa hiệu quả. Một số đặc điểm:
Chúng mang lại nhiều ưu điểm so với cây tìm kiếm nhị phân:
Sắp xếp topo là thuật toán dùng để sắp thứ tự các đỉnh của một đồ thị có hướng không chu trình (DAG) sao cho nếu có cạnh từ đỉnh u tới đỉnh v thì u xuất hiện trước v trong thứ tự. Thuật toán này thường dùng trong lập lịch tác vụ — xác định thứ tự chạy các tác vụ để tôn trọng phụ thuộc — cũng như trong hệ thống build, trình quản lý gói, và lập kế hoạch học phần có học phần tiên quyết.
Một min-heap là một cách triển khai cụ thể của hàng đợi ưu tiên, được định nghĩa là một cây nhị phân đầy đủ trong đó giá trị của mỗi nút không lớn hơn giá trị các nút con, cho phép tìm và trích xuất phần tử nhỏ nhất hiệu quả.
Ngược lại, hàng đợi ưu tiên là một cấu trúc dữ liệu trừu tượng cho phép chèn phần tử kèm mức ưu tiên, và các phần tử được lấy ra theo thứ tự ưu tiên. Min-heap là cách triển khai phổ biến cho hàng đợi ưu tiên nhờ khả năng xử lý các thao tác này hiệu quả.
Cấu trúc dữ liệu tập rời, còn gọi là union-find, duy trì một tập hợp các tập rời nhau. Cấu trúc này hỗ trợ hai thao tác chính:
Có nhiều ứng dụng của tập rời, nhưng phổ biến nhất là thuật toán Kruskal để tìm cây khung nhỏ nhất của đồ thị và bài toán luồng mạng để xác định các thành phần liên thông trong đồ thị.
Cây đoạn là cấu trúc dữ liệu được thiết kế để hỗ trợ hiệu quả các truy vấn theo khoảng và cập nhật trên một mảng. Nó đặc biệt hữu ích trong các tình huống cần lặp đi lặp lại các phép như tính tổng, giá trị nhỏ nhất, lớn nhất, hoặc ước số chung lớn nhất trên một khoảng phần tử cụ thể của mảng.
Cấu trúc này được xây dựng như một cây nhị phân, trong đó mỗi nút biểu diễn một đoạn của mảng. Các lá tương ứng với từng phần tử của mảng, trong khi các nút bên trong lưu thông tin tổng hợp từ các nút con theo phép toán đang thực hiện. Chúng đạt độ phức tạp O(log n) cho cả cập nhật và truy vấn.
Cây hậu tố lưu mọi hậu tố của một chuỗi để truy vấn mẫu có thời gian tỉ lệ với độ dài mẫu, không phụ thuộc độ dài văn bản. Cây hậu tố “đúng nghĩa” dùng nén cạnh để đạt O(n) bộ nhớ và thường được xây bằng thuật toán Ukkonen — nhưng điều đó đủ phức tạp để người phỏng vấn hiếm khi kỳ vọng bạn mã hóa từ đầu trong 45 phút.
Một thỏa hiệp phổ biến là trie hậu tố đơn giản hơn, lưu một ký tự mỗi nút. Nó dùng O(n²) bộ nhớ nhưng dễ viết và giải thích hơn nhiều. Mẹo trong phỏng vấn là hiểu rõ đánh đổi và nói ra điều đó một cách rõ ràng.
Dưới đây là một triển khai Python gọn gàng:
class SuffixTrieNode:
def __init__(self):
self.children = {} # Map of character -> child node
self.indices = [] # Starting positions of suffixes passing through this node
class SuffixTrie:
def __init__(self, text):
self.root = SuffixTrieNode()
self.text = text + "$" # Append a unique terminator
self._build()
def _build(self):
"""Insert every suffix of the text into the trie."""
for i in range(len(self.text)):
self._insert_suffix(i)
def _insert_suffix(self, index):
node = self.root
for i in range(index, len(self.text)):
c = self.text[i]
if c not in node.children:
node.children[c] = SuffixTrieNode()
node = node.children[c]
node.indices.append(index)
def search(self, pattern):
"""Return all starting positions where `pattern` appears in the text."""
node = self.root
for c in pattern:
if c not in node.children:
return []
node = node.children[c]
return node.indicesQuadtree là cấu trúc dữ liệu cây phân cấp, đệ quy chia không gian hai chiều thành bốn phần tư bằng nhau. Kỹ thuật phân vùng không gian này rất hiệu quả cho các ứng dụng như xử lý ảnh, phát hiện va chạm trong trò chơi, và hệ thống thông tin địa lý để lưu trữ và truy xuất dữ liệu không gian hiệu quả.
Thể hiện kiến thức về cấu trúc dữ liệu là quan trọng, nhưng chứng minh rằng bạn biết dùng chúng đúng lúc đúng chỗ sẽ giúp bạn nổi bật trong buổi phỏng vấn. Trong phần này, chúng ta sẽ xem cách áp dụng kiến thức cấu trúc dữ liệu vào các tình huống thực tiễn.
Do tính chất thời gian thực, thách thức này đòi hỏi các cấu trúc dữ liệu hiệu quả.
Theo kinh nghiệm của tôi, tôi sẽ dùng quadtree cho dữ liệu địa lý, hàng đợi ưu tiên để xếp hạng các ghép đôi tiềm năng dựa trên khoảng cách và mức độ khẩn cấp của hành khách, và bảng băm để tra cứu nhanh vị trí tài xế và hành khách.
Chúng ta có thể kết hợp nhiều cấu trúc dữ liệu để gợi ý sản phẩm hiệu quả dựa trên hành vi người dùng.
Ma trận thưa user-item sẽ lưu tương tác người dùng - sản phẩm, trong khi bảng băm ánh xạ hiệu quả người dùng và sản phẩm. Hàng đợi ưu tiên xếp hạng gợi ý, và cấu trúc đồ thị có thể mô hình hóa quan hệ người dùng - sản phẩm cho các phân tích nâng cao như phát hiện cộng đồng.
Cấu trúc dữ liệu đồ thị có thể rất hiệu quả để phát hiện và loại bỏ tài khoản spam trên nền tảng mạng xã hội. Bằng cách biểu diễn người dùng là nút và kết nối của họ là cạnh, bạn có thể phân tích tô-pô mạng. Việc xác định các cụm dày đặc, nút cô lập và đột biến hoạt động đột ngột có thể giúp gắn cờ các tài khoản đáng ngờ.
Tôi sẽ dùng kết hợp nhiều cấu trúc dữ liệu trong một ứng dụng chat thời gian thực.
Bảng băm sẽ lưu ID người dùng và danh sách kết nối tương ứng, cho phép tra cứu nhanh người dùng để gửi tin nhắn. Hàng đợi sẽ được triển khai cho mỗi người dùng để duy trì thứ tự tin nhắn, đảm bảo chúng được gửi theo trình tự. Ngoài ra, cây, như cây AVL, có thể dùng để lưu và truy xuất trạng thái online/offline hiệu quả, cho phép cập nhật thời gian thực về tình trạng sẵn sàng của người dùng.
Với bộ kiểm tra chính tả, tra cứu từ hiệu quả là rất quan trọng. Trie sẽ là cấu trúc dữ liệu lý tưởng. Mỗi nút trong trie biểu diễn một chữ cái, và các đường đi qua trie tạo thành từ. Điều này cho phép tìm kiếm theo tiền tố nhanh, giúp bộ kiểm tra chính tả đề xuất sửa lỗi cho từ sai một cách nhanh chóng.
Trong tình huống này, cây đoạn là lựa chọn nổi bật. Chúng rất giỏi xử lý truy vấn theo khoảng và cập nhật hiệu quả. Ta có thể biểu diễn bản đồ trò chơi dưới dạng mảng 1D, mỗi phần tử tương ứng một ô lưới. Mỗi ô có thể lưu thông tin về sự hiện diện hay vắng mặt của một công trình.
Tôi hiểu rằng chuẩn bị cho phỏng vấn cấu trúc dữ liệu có thể là thách thức, nhưng một cách tiếp cận có cấu trúc sẽ giúp bạn thấy dễ dàng hơn!
Tập trung nắm vững các khái niệm nền tảng của cấu trúc dữ liệu như mảng, danh sách liên kết, ngăn xếp, hàng đợi, cây, đồ thị và bảng băm. Hiểu nguyên lý của chúng, cách quản lý dữ liệu và độ phức tạp thời gian của các thao tác như chèn, xóa và tìm kiếm.
Biết khái niệm là tốt nhưng chưa đủ. Bạn nên biết cách tự triển khai các cấu trúc dữ liệu này từ đầu. Bạn có thể tham gia các khóa học DataCamp để tận dụng các thử thách mã hóa giúp mài giũa kỹ năng giải quyết vấn đề.
Hiểu các đánh đổi giữa các cấu trúc dữ liệu là chìa khóa. Ví dụ, mảng cho phép truy cập nhanh nhưng tốn kém khi chèn và xóa, trong khi danh sách liên kết cho phép chỉnh sửa hiệu quả nhưng cần duyệt để truy cập. Hãy sẵn sàng thảo luận các đánh đổi này trong buổi phỏng vấn.
Hãy nhớ, giao tiếp cũng quan trọng như mã. Người phỏng vấn tìm kiếm ứng viên có thể điều chỉnh cách giải thích phù hợp với đối tượng. Như đã bàn trong podcast DataFramed về tương lai của các vai trò dữ liệu:
Bạn cần có khả năng truyền đạt mọi loại insight theo cách mà một đứa trẻ sáu tuổi cũng hiểu được và đồng thời làm hài lòng tôi hoặc thậm chí cả những người còn kỹ thuật hơn nữa. Vậy nên nếu bạn thực sự nắm vững vấn đề, bạn có thể diễn giải thật đơn giản, nhưng cũng có thể làm nó phức tạp đến mức, thực lòng mà nói, chỉ những người thực sự, thực sự xuất sắc về chuyên môn kỹ thuật mới hiểu được.
Mo Chen, Data & Analytics Manager at NatWest Group
Tìm hiểu thêm về cấu trúc dữ liệu và những điều cơ bản của Python với các khóa học này!
Courses
Courses
Courses
blogs
Matt Crabtree
10 phút