Course
Intermediate Python
4 ч
1.4M
Чтобы продемонстрировать понимание базовых структур данных, важно уверенно владеть ключевыми структурами и их реализациями. Вопросы ниже проверяют вашу способность объяснять эти идеи и показывать знание темы.
Структуры данных классифицируют так:
Массивы и связные списки — два способа хранить наборы элементов, но работают они по‑разному. Основные различия:
Стек — это упорядоченный список, в который элементы добавляются и удаляются с одного конца — вершины. Он следует принципу LIFO: последним пришёл — первым вышел.
Стэки применяются для вычисления выражений, бэктрекинга, управления памятью, а также при вызовах и возвратах функций.
В Python список из коробки работает как стек: append() — это push, а pop() — удаление верхнего элемента.
my_stack = []
item = 1
my_stack.append(item)
my_stack.pop()Отслеживая индекс вершины, можно сделать эти операции быстрыми и эффективными.
Очередь — это структура FIFO: кто первым пришёл, тот первым обслуживается — как очередь в магазине: люди заходят с хвоста и выходят из головы.
В Python очередь можно реализовать по‑разному:
С помощью массива или списка, используя методы append() и pop():
my_queue = []
item = 1
# Enqueue
my_queue.append(item)
# Dequeue
my_queue.pop(0)С помощью deque() из библиотеки collections, где append() и pop() выполняются быстрее, чем у списков:
from collections import deque
my_queue = deque()
item = 1
# Enqueue
my_queue.append(item)
# Dequeue
my_queue.popleft()С использованием встроенного модуля queue.Queue:
from queue import Queue
my_queue = Queue(maxsize = 3)
# Enqueue
my_queue.put(item)
# Dequeue
my_queue.get()Бинарное дерево — это структура данных, где у каждого узла не более двух детей: левый и правый. Бинарное дерево поиска (BST) — особый вид бинарного дерева с упорядоченными свойствами: для каждого узла все ключи в левом поддереве меньше, все ключи в правом — больше, и оба поддерева сами являются BST.
Эти свойства обеспечивают эффективный поиск, вставку и удаление, обычно с трудоёмкостью O(log n) в сбалансированных деревьях.
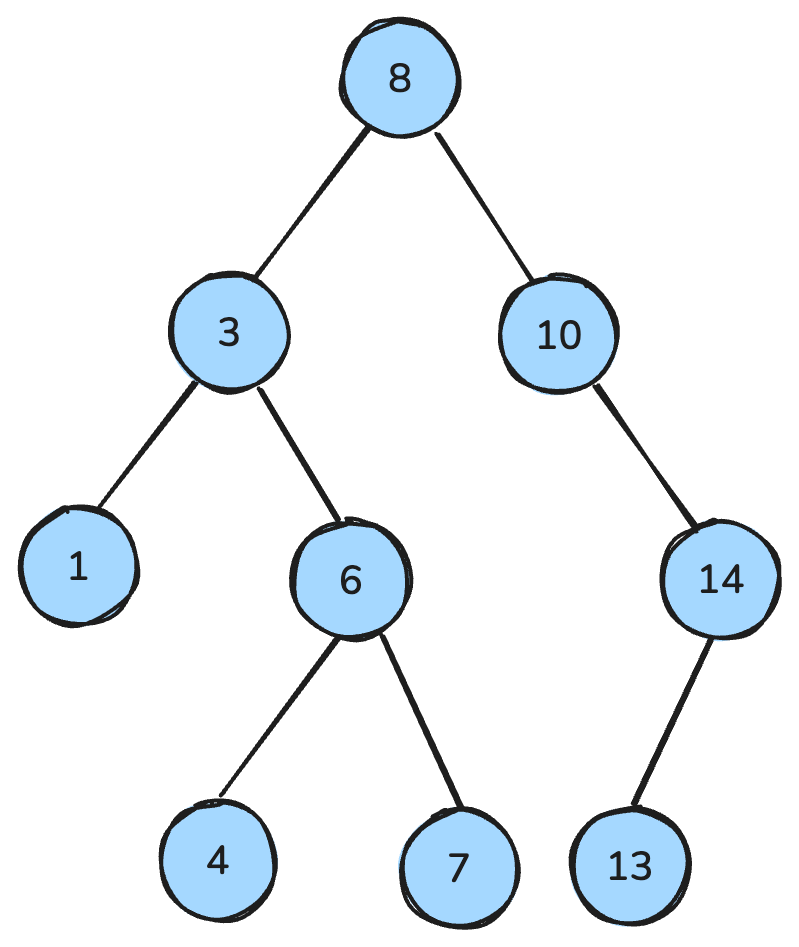
Бинарное дерево поиска. Изображение автора.
Хеширование — это техника, которая преобразует данные любого размера в значение фиксированного размера — хеш-значение — с помощью хеш-функции.
Обычное применение — хеш-таблицы, где хеширование помогает сопоставлять ключи с конкретными позициями в массиве, что позволяет быстро находить и извлекать данные. Также хеширование применяется для защиты паролей в криптографии и для дедупликации при организации данных.
Куча — это древовидная структура данных со специальными правилами.
В max-куче каждый родитель больше или равен своим детям; в min-куче — меньше или равен.
Кучи часто используют для реализации очередей с приоритетом, где элементы упорядочиваются по важности или значению. Они также важны для пирамидальной сортировки — метода эффективной организации данных.
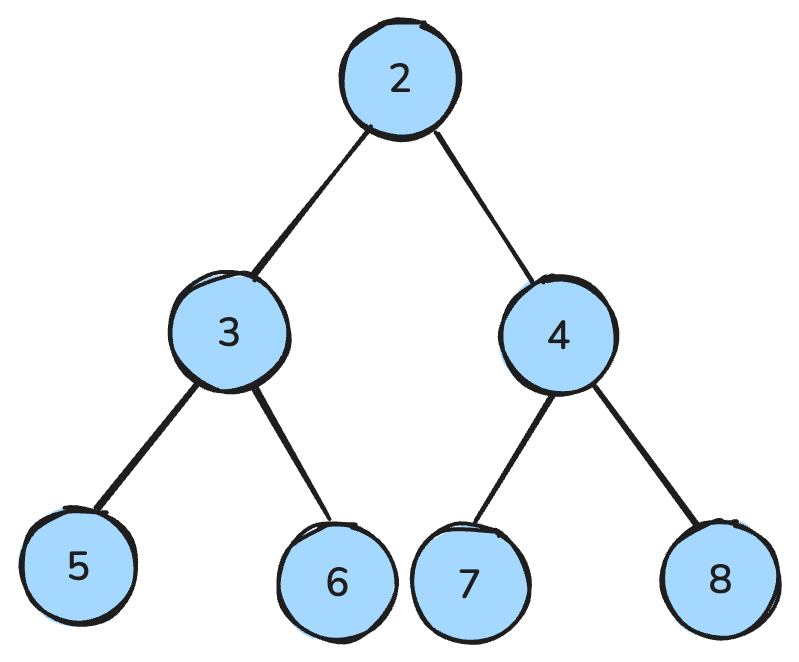
Min-куча — это когда все родительские узлы меньше дочерних. Изображение автора.
Разобрав основы, перейдём к вопросам среднего уровня, которые проверяют умение реализовывать и применять фундаментальные концепции.
Сбалансированное бинарное дерево поиска поддерживает сопоставимые высоты левого и правого поддеревьев. Балансировка BST важна для сохранения эффективности поиска, вставки и удаления.
Для самобалансировки часто используют деревья AVL и красно-чёрные деревья. AVL поддерживают разницу высот поддеревьев любого узла не более 1, тогда как у красно-чёрных деревьев действуют иные жёсткие ограничения баланса.
Min-куча обычно хранится в списке. Две ключевые операции — insert (добавляет элемент и поднимает его для восстановления свойства кучи) и extract_min (удаляет корень и просеивает вниз для восстановления порядка):
class MinHeap:
def __init__(self):
self.heap = []
def __len__(self): # Get the size of the heap
return len(self.heap)
def __parent(self, i): # Get the parent index
return (i - 1) // 2
def __left(self, i): # Get the left child index
return 2 * i + 1
def __right(self, i): # Get the right child index
return 2 * i + 2
def __swap(self, i, j): # Swap two elements
self.heap[i], self.heap[j] = self.heap[j], self.heap[i]
def __heapify_up(self, i): # Restore min-heap property after insertion
while i > 0 and self.heap[i] < self.heap[self.__parent(i)]:
self.__swap(i, self.__parent(i))
i = self.__parent(i)
def __heapify_down(self, i): # Restore min-heap property after extraction
while True:
smallest = i
left = self.__left(i)
right = self.__right(i)
if left < len(self) and self.heap[left] < self.heap[smallest]:
smallest = left
if right < len(self) and self.heap[right] < self.heap[smallest]:
smallest = right
if smallest != i:
self.__swap(i, smallest)
i = smallest
else:
break
def insert(self, val): # Insert a value into the heap
self.heap.append(val)
self.__heapify_up(len(self) - 1)
def extract_min(self): # Extract the minimum value from the heap
if not self.heap:
return None
min_val = self.heap[0]
self.heap[0] = self.heap[-1]
self.heap.pop()
self.__heapify_down(0)
return min_valБор, или префиксное дерево, — древовидная структура данных, оптимизированная для быстрого поиска строк и сопоставления префиксов.
В боре каждый узел представляет один символ, а пути от корня к узлам соответствуют полным строкам. Боры широко применяются в автодополнении, проверке орфографии и при реализации словарей.
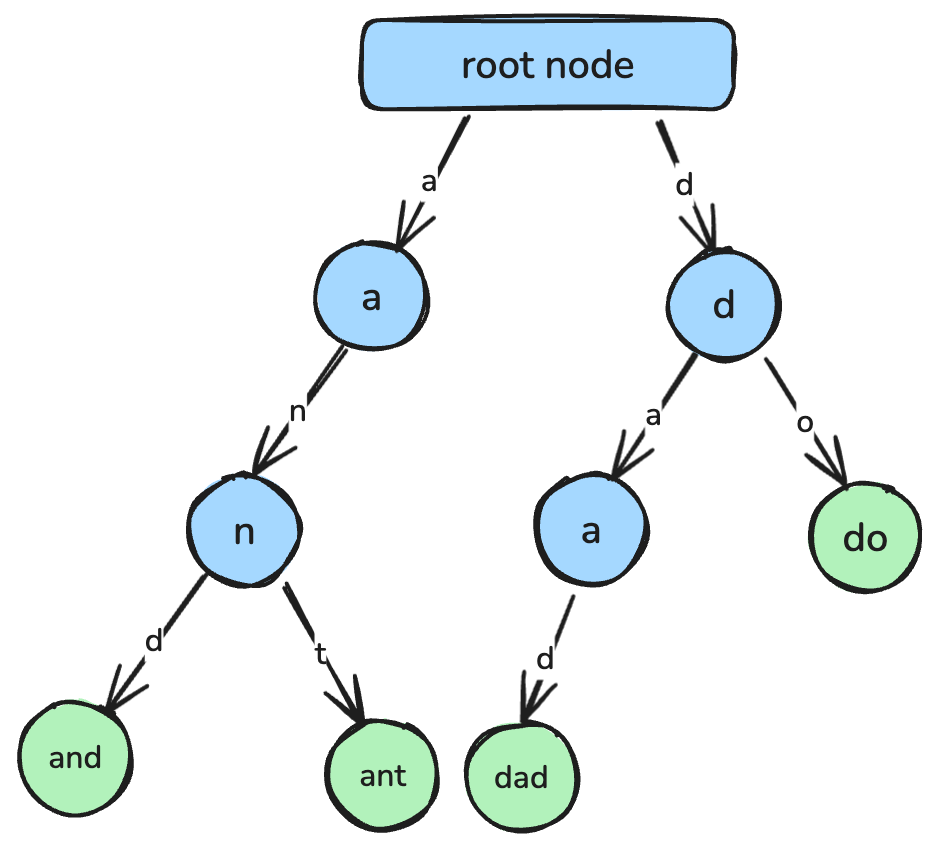
Бор, в котором каждый узел представляет отдельный символ, образующий строку. Изображение автора.
Коллизия возникает, когда два разных ключа хешируются в один и тот же индекс.
Существует несколько методов разрешения коллизий: цепочки (chaining), когда столкнувшиеся элементы хранятся в связном списке по соответствующему индексу, и открытая адресация (open addressing), при которой с помощью пробирования — линейного, квадратичного или двойного хеширования — ищется следующая свободная ячейка массива.
Граф — это структура данных, состоящая из набора вершин (узлов), соединённых рёбрами. Такая структура удобна для моделирования связей и отношений между объектами.
Поиск в глубину (DFS) — алгоритм, который проходит граф или дерево, углубляясь в ветви до упора с последующим откатом. Реализуется явным стеком или рекурсией. Сложность — O(V + E), где V — число вершин, E — число рёбер, то есть в худшем случае просматриваются все вершины и рёбра.
Поиск в ширину (BFS) последовательно исследует все узлы текущего уровня глубины, прежде чем переходить к следующему. Эффективен для поиска кратчайшего пути в невзвешенных графах и обычно реализуется очередью. Как и DFS, имеет сложность O(V + E), требуя просмотра всех вершин и рёбер.
Алгоритмы сортировки необходимы для эффективной обработки данных — они ускоряют поиск, улучшают анализ и упрощают визуализацию. Выбирая между ними, учитывайте несколько ключевых компромиссов:
Вот аккуратные реализации на Python:
# Bubble sort — sorts in place
def bubble_sort(arr):
n = len(arr)
for i in range(n):
for j in range(0, n - i - 1):
if arr[j] > arr[j + 1]:
arr[j], arr[j + 1] = arr[j + 1], arr[j]
# Quick sort — sorts in place
def partition(arr, low, high):
pivot = arr[high]
i = low - 1
for j in range(low, high):
if arr[j] <= pivot:
i += 1
arr[i], arr[j] = arr[j], arr[i]
arr[i + 1], arr[high] = arr[high], arr[i + 1]
return i + 1
def quick_sort(arr, low, high):
if low < high:
pi = partition(arr, low, high)
quick_sort(arr, low, pi - 1)
quick_sort(arr, pi + 1, high)
# Merge sort — returns a new sorted list
def merge(left, right):
result = []
i = j = 0
while i < len(left) and j < len(right):
if left[i] <= right[j]:
result.append(left[i])
i += 1
else:
result.append(right[j])
j += 1
result.extend(left[i:])
result.extend(right[j:])
return result
def merge_sort(arr):
if len(arr) <= 1:
return arr
mid = len(arr) // 2
left_half = merge_sort(arr[:mid])
right_half = merge_sort(arr[mid:])
return merge(left_half, right_half)nums = [3, 1, 4, 1, 5, 9, 2, 6]
bubble_sort(nums) # sorts nums in place
quick_sort(nums, 0, len(nums) - 1) # also in place
sorted_nums = merge_sort(nums) # returns a new listНа собеседовании этого ответа достаточно. Но чтобы выделиться, упомяните, что встроенные sorted() и list.sort() в Python используют Timsort — гибрид сортировки слиянием и вставками. Поэтому в продакшн-коде Python почти никогда не пишут сортировку с нуля.
Для поиска кратчайшего пути в графах применяют несколько алгоритмов.
Для невзвешенных графов эффективен поиск в ширину, проходящий граф по слоям. В взвешенных графах с неотрицательными рёбрами алгоритм Дейкстры находит кратчайший путь, сначала рассматривая ближайшую вершину.
Алгоритм A* повышает эффективность, используя эвристику для оценки оставшейся стоимости. Выбор алгоритма зависит от свойств графа и требований задачи.
Рассмотрим продвинутые вопросы — для претендентов на старшие роли или тех, кто хочет показать глубокие знания специализированных и сложных структур данных.
Динамическое программирование — это метод решения сложных задач путём разбиения их на пересекающиеся подзадачи. Вместо того чтобы каждый раз начинать с нуля, вы запоминаете решения для меньших частей, избегая повторных вычислений.
Этот подход полезен, например, для нахождения наибольшей общей подпоследовательности двух строк или минимальной стоимости достижения точки на сетке.
B-деревья — сбалансированные структуры, оптимизированные для работы с диском. Их особенности:
Преимущества перед бинарными деревьями поиска:
Топологическая сортировка — это упорядочивание вершин ориентированного ациклического графа (DAG) так, чтобы если есть ребро из вершины u в вершину v, то u предшествует v в порядке. Её используют для планирования задач — определения порядка выполнения с учётом зависимостей, а также в системах сборки, менеджерах пакетов и планировании учебных курсов.
Min-куча — это конкретная реализация очереди с приоритетом: полное бинарное дерево, где значение каждого узла не больше значений его детей, что позволяет эффективно находить и извлекать минимум.
А очередь с приоритетом — абстрактная структура, позволяющая вставлять элементы с приоритетом и извлекать их по порядку приоритета. Min-кучи — распространённый способ её реализации благодаря эффективной поддержке этих операций.
Структура непересекающихся множеств, или Union-Find, поддерживает набор раздельных множеств. Две основные операции:
Применения многочисленны, но самые известные — алгоритм Краскала для нахождения минимального остовного дерева и задачи о потоках в сети для определения компонент связности графа.
Дерево отрезков — структура данных для эффективных диапазонных запросов и обновлений по массиву. Особенно полезно, когда нужно многократно вычислять сумму, минимум, максимум или НОД на заданном диапазоне элементов массива.
Оно строится как бинарное дерево, где каждый узел представляет сегмент массива. Листья соответствуют отдельным элементам, а внутренние узлы агрегируют значения детей в соответствии с операцией. И обновления, и запросы выполняются за O(log n).
Суффиксное дерево хранит все суффиксы строки, чтобы отвечать на запросы по образцу за время, пропорциональное длине образца, а не текста. Настоящее суффиксное дерево использует сжатие рёбер, занимает O(n) памяти и обычно строится алгоритмом Укконена — это достаточно сложно, поэтому на собеседовании редко ожидают код с нуля за 45 минут.
Компромисс — более простой суффиксный бор (trie), где в узле один символ. Он требует O(n²) памяти, но его гораздо проще написать и объяснить. На интервью важно знать этот компромисс и проговорить его.
Вот аккуратная реализация на Python:
class SuffixTrieNode:
def __init__(self):
self.children = {} # Map of character -> child node
self.indices = [] # Starting positions of suffixes passing through this node
class SuffixTrie:
def __init__(self, text):
self.root = SuffixTrieNode()
self.text = text + "$" # Append a unique terminator
self._build()
def _build(self):
"""Insert every suffix of the text into the trie."""
for i in range(len(self.text)):
self._insert_suffix(i)
def _insert_suffix(self, index):
node = self.root
for i in range(index, len(self.text)):
c = self.text[i]
if c not in node.children:
node.children[c] = SuffixTrieNode()
node = node.children[c]
node.indices.append(index)
def search(self, pattern):
"""Return all starting positions where `pattern` appears in the text."""
node = self.root
for c in pattern:
if c not in node.children:
return []
node = node.children[c]
return node.indicesКвадродеревья — иерархические деревья, которые рекурсивно делят двумерное пространство на четыре равных квадранта. Такая пространственная декомпозиция эффективна в обработке изображений, обнаружении столкновений в играх и в ГИС для эффективного хранения и поиска пространственных данных.
Знание структур данных важно, но умение правильно выбирать их под задачу выделит вас на собеседовании. В этом разделе рассмотрим практическое применение структур данных.
Из‑за требования работы в реальном времени здесь нужны эффективные структуры данных.
По моему опыту, я бы использовал квадродеревья для геоданных, очереди с приоритетом — для ранжирования кандидатов по расстоянию и срочности, и хеш-таблицы — для быстрых поисков локаций водителей и пассажиров.
Можно сочетать несколько структур данных для эффективных рекомендаций.
Разреженная пользовательско‑товарная матрица хранит взаимодействия, хеш-таблицы сопоставляют пользователей и товары, очереди с приоритетом ранжируют рекомендации, а графовые структуры моделируют связи пользователь‑товар для продвинутого анализа, например обнаружения сообществ.
Графовая структура данных очень эффективна для обнаружения и удаления спам-аккаунтов. Представив пользователей как узлы, а связи — как рёбра, можно анализировать топологию сети. Выявление плотных кластеров, изолированных узлов и резких всплесков активности помогает помечать подозрительные аккаунты.
В реальном‑времени я бы комбинировал несколько структур.
Хеш-таблицы хранили бы идентификаторы пользователей и их списки подключений для быстрых адресаций. Для каждого пользователя — очереди, чтобы сохранять порядок сообщений. Дополнительно деревья (например, AVL) — для эффективного хранения и получения статуса онлайн/оффлайн с мгновенным обновлением доступности.
Для спеллчекера крайне важен быстрый поиск слов. Идеальной структурой будет бор. Каждый узел бора представляет букву, а пути образуют слова. Это обеспечивает быстрый поиск по префиксам и оперативные подсказки исправлений.
В этом сценарии дерево отрезков — отличный выбор. Оно хорошо обрабатывает диапазонные запросы и обновления. Карту можно представить как одномерный массив, где каждая ячейка — клетка сетки. В клетке хранится информация о наличии/отсутствии постройки.
Подготовка к такому собеседованию может быть сложной, но структурированный подход делает её управляемой!
Сконцентрируйтесь на фундаментальных концепциях: массивы, связные списки, стэки, очереди, деревья, графы и хеш-таблицы. Понимайте их принципы, управление данными и трудоёмкость операций вставки, удаления и поиска.
Знаний понятий недостаточно — важно уметь реализовывать эти структуры с нуля. Вы можете воспользоваться курсами DataCamp, чтобы прокачать навыки решения задач на практике.
Понимание компромиссов между структурами данных — ключ. Например, массивы обеспечивают быстрый доступ, но дорого стоят вставки и удаления; связные списки, наоборот, удобны для модификаций, но требуют обхода для доступа. Будьте готовы обсуждать такие компромиссы.
Помните, что коммуникация так же важна, как код. Интервьюеры ищут кандидатов, умеющих адаптировать объяснения к аудитории. Как обсуждалось в подкасте DataFramed о будущем дата-ролей:
Вам нужно уметь преподнести любой инсайт так, чтобы его понял и шестилетний ребёнок, и так, чтобы это устроило меня или даже кого-то ещё более технического. Если вы действительно разбираетесь в теме, вы можете объяснить её очень просто, но и усложнить настолько, что, по правде говоря, поймут лишь те, у кого действительно высокий уровень технической экспертизы.
Mo Chen, Data & Analytics Manager at NatWest Group
Изучите больше о структурах данных и основах Python с этими курсами!
Course
Course
Course