Courses
Intermediate Python
4 ชม.
1.4M
เพื่อแสดงความเข้าใจในโครงสร้างข้อมูลพื้นฐาน ต้องมั่นใจในโครงสร้างหลักและการนำไปใช้งานอย่างยิ่ง คำถามลักษณะต่อไปนี้จะทดสอบความสามารถในการอธิบายแนวคิดและแสดงความรู้ของคุณ
โครงสร้างข้อมูลจำแนกได้ดังนี้:
อาเรย์และลิงก์ลิสต์เป็นสองวิธีในการเก็บกลุ่มของรายการ แต่กลไกต่างกัน มาดูจุดต่างหลัก ๆ:
สแตกคือลิสต์ที่เรียงลำดับซึ่งเพิ่มและนำออกรายการที่ปลายด้านเดียว เรียกว่า top ใช้หลักการเข้าหลังออกก่อน (LIFO): องค์ประกอบที่ใส่ล่าสุดจะถูกนำออกก่อน
สแตกใช้ได้ในหลายงาน เช่น การประเมินนิพจน์ การย้อนรอย การจัดการหน่วยความจำ และการเรียก-ส่งคืนฟังก์ชัน
ใน Python ลิสต์ทำงานเป็นสแตกได้ทันที: append() คือ push และ pop() คือนำ top ออก
my_stack = []
item = 1
my_stack.append(item)
my_stack.pop()ด้วยการติดตามตำแหน่งของ top ด้วยดัชนี จะทำให้การดำเนินการรวดเร็วและมีประสิทธิภาพ
คิวเป็นโครงสร้างแบบเข้าก่อนออกก่อน (FIFO) — คล้ายแถวหน้าร้าน คนเข้าท้ายแถวและออกหัวแถว
ใน Python สามารถติดตั้งคิวได้หลายแบบ:
ใช้ลิสต์ และใช้เมธอด append() และ pop():
my_queue = []
item = 1
# Enqueue
my_queue.append(item)
# Dequeue
my_queue.pop(0)ใช้ deque() จากไลบรารี collections ซึ่งทำ append() และ pop() เร็วกว่า list:
from collections import deque
my_queue = deque()
item = 1
# Enqueue
my_queue.append(item)
# Dequeue
my_queue.popleft()ใช้มอดูลในตัว queue.Queue:
from queue import Queue
my_queue = Queue(maxsize = 3)
# Enqueue
my_queue.put(item)
# Dequeue
my_queue.get()ไบนารีทรีคือโครงสร้างข้อมูลที่แต่ละโหนดมีลูกได้ไม่เกินสองโหนด: ลูกซ้ายและลูกขวา จากนั้นต้นไม้ค้นหาแบบทวิภาค (BST) เป็นชนิดเฉพาะของไบนารีทรีที่มีคุณสมบัติการเรียงลำดับชัดเจน: สำหรับทุกโหนด คีย์ทั้งหมดในซับทรีฝั่งซ้ายมีค่าน้อยกว่า ฝั่งขวามากกว่า และทั้งสองซับทรีเป็น BST เช่นกัน
คุณสมบัติเหล่านี้ช่วยให้การค้นหา การแทรก และการลบทำได้มีประสิทธิภาพ โดยทั่วไปมีเวลาเชิงซ้อน O(log n) เมื่อเป็นต้นไม้ที่สมดุล
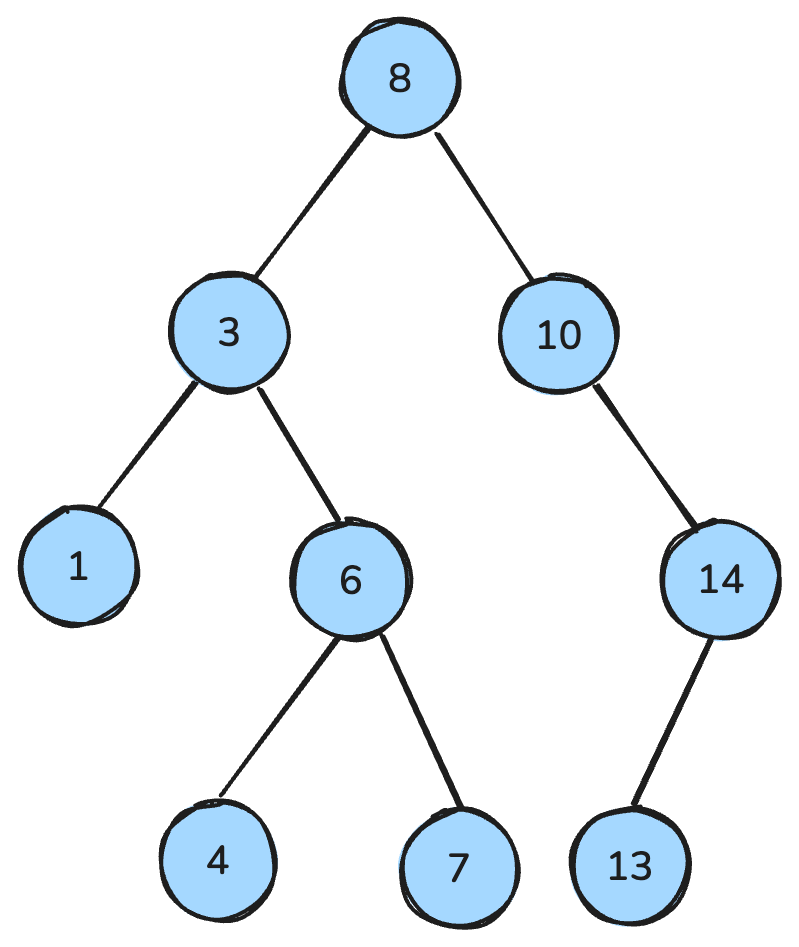
ต้นไม้ค้นหาแบบทวิภาค ภาพโดยผู้เขียน
แฮชชิงเป็นเทคนิคที่รับข้อมูลขนาดใดก็ได้แล้วแปลงเป็นค่าขนาดคงที่ที่เรียกว่าค่าแฮช โดยใช้ฟังก์ชันแฮช
การใช้งานที่พบบ่อยคือในตารางแฮช ซึ่งช่วยจับคู่คีย์กับตำแหน่งเฉพาะในอาเรย์ ทำให้ง่ายต่อการค้นหาและดึงข้อมูลอย่างรวดเร็ว แฮชชิงยังประยุกต์ได้หลากหลาย ตั้งแต่การช่วยรักษาความปลอดภัยรหัสผ่านในคริปโตกราฟีไปจนถึงการจัดระเบียบข้อมูลผ่านการขจัดข้อมูลซ้ำ
ฮีปเป็นโครงสร้างข้อมูลลักษณะคล้ายต้นไม้และปฏิบัติตามกฎพิเศษ
ในแม็กซ์ฮีป พ่อแม่ทุกโหนดมีค่ามากกว่าหรือเท่ากับลูก ในมินฮีป พ่อแม่ทุกโหนดมีค่าน้อยกว่าหรือเท่ากับลูก
ฮีปมักใช้สร้างคิวลำดับความสำคัญ เพื่อจัดเรียงรายการตามความสำคัญหรือมูลค่า และสำคัญต่อการเรียงแบบฮีปซอร์ต ซึ่งเป็นวิธีจัดระเบียบข้อมูลอย่างมีประสิทธิภาพ
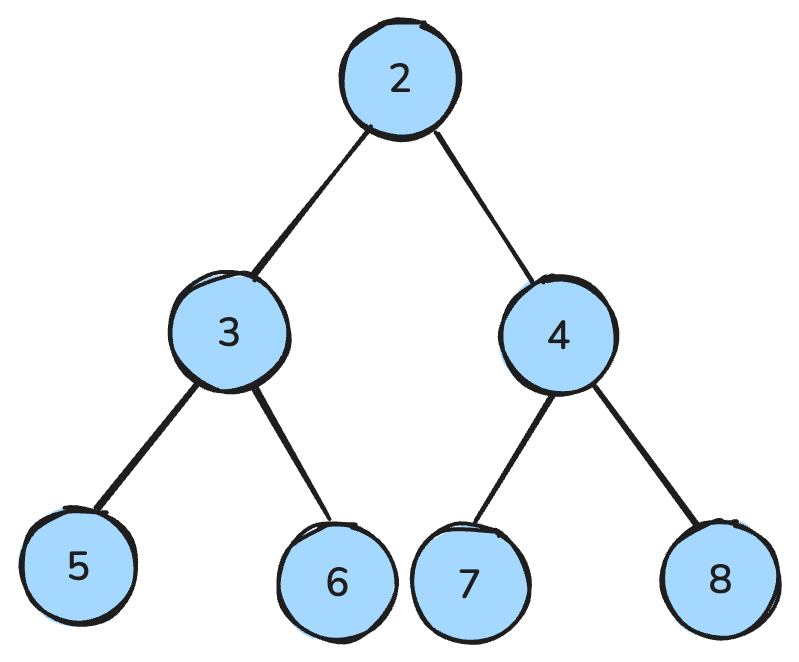
มินฮีปคือพ่อแม่ทุกโหนดมีค่าน้อยกว่าลูก — ภาพโดยผู้เขียน
เมื่อครอบคลุมพื้นฐานแล้ว มาต่อด้วยคำถามระดับกลางที่สำรวจความชำนาญทางเทคนิคในการติดตั้งและใช้งานแนวคิดพื้นฐานเหล่านี้
BST ที่สมดุลจะคงความสูงของซับทรีซ้ายและขวาให้ใกล้เคียงกัน การทำให้ BST สมดุลสำคัญมากเพื่อรักษาประสิทธิภาพของการค้นหา แทรก และลบ
เทคนิคอย่าง AVL tree และ red-black tree มักใช้เพื่อให้สมดุลด้วยตัวเอง AVL คุมส่วนต่างความสูงระหว่างซ้าย-ขวาไม่เกิน 1 ขณะที่ red-black tree มีข้อกำหนดความสมดุลที่เข้มงวดกว่า
มินฮีปมักรองรับด้วยลิสต์ สองปฏิบัติการหลักคือ insert (เพิ่มองค์ประกอบแล้วดันขึ้นเพื่อคงคุณสมบัติฮีป) และ extract_min (นำรากออกแล้วดันลงเพื่อเรียงใหม่):
class MinHeap:
def __init__(self):
self.heap = []
def __len__(self): # Get the size of the heap
return len(self.heap)
def __parent(self, i): # Get the parent index
return (i - 1) // 2
def __left(self, i): # Get the left child index
return 2 * i + 1
def __right(self, i): # Get the right child index
return 2 * i + 2
def __swap(self, i, j): # Swap two elements
self.heap[i], self.heap[j] = self.heap[j], self.heap[i]
def __heapify_up(self, i): # Restore min-heap property after insertion
while i > 0 and self.heap[i] < self.heap[self.__parent(i)]:
self.__swap(i, self.__parent(i))
i = self.__parent(i)
def __heapify_down(self, i): # Restore min-heap property after extraction
while True:
smallest = i
left = self.__left(i)
right = self.__right(i)
if left < len(self) and self.heap[left] < self.heap[smallest]:
smallest = left
if right < len(self) and self.heap[right] < self.heap[smallest]:
smallest = right
if smallest != i:
self.__swap(i, smallest)
i = smallest
else:
break
def insert(self, val): # Insert a value into the heap
self.heap.append(val)
self.__heapify_up(len(self) - 1)
def extract_min(self): # Extract the minimum value from the heap
if not self.heap:
return None
min_val = self.heap[0]
self.heap[0] = self.heap[-1]
self.heap.pop()
self.__heapify_down(0)
return min_valไทร หรือ prefix tree เป็นโครงสร้างข้อมูลแบบต้นไม้ที่ออกแบบเพื่อค้นหาสตริงและจับคู่คำนำหน้าได้อย่างมีประสิทธิภาพ
ในไทร แต่ละโหนดแทนอักขระหนึ่งตัว และเส้นทางจากรากไปยังโหนดต่าง ๆ แทนสตริงที่สมบูรณ์ ไทรถูกใช้บ่อยในระบบเติมคำอัตโนมัติ เครื่องมือตรวจการสะกด และการติดตั้งดิกชันนารี
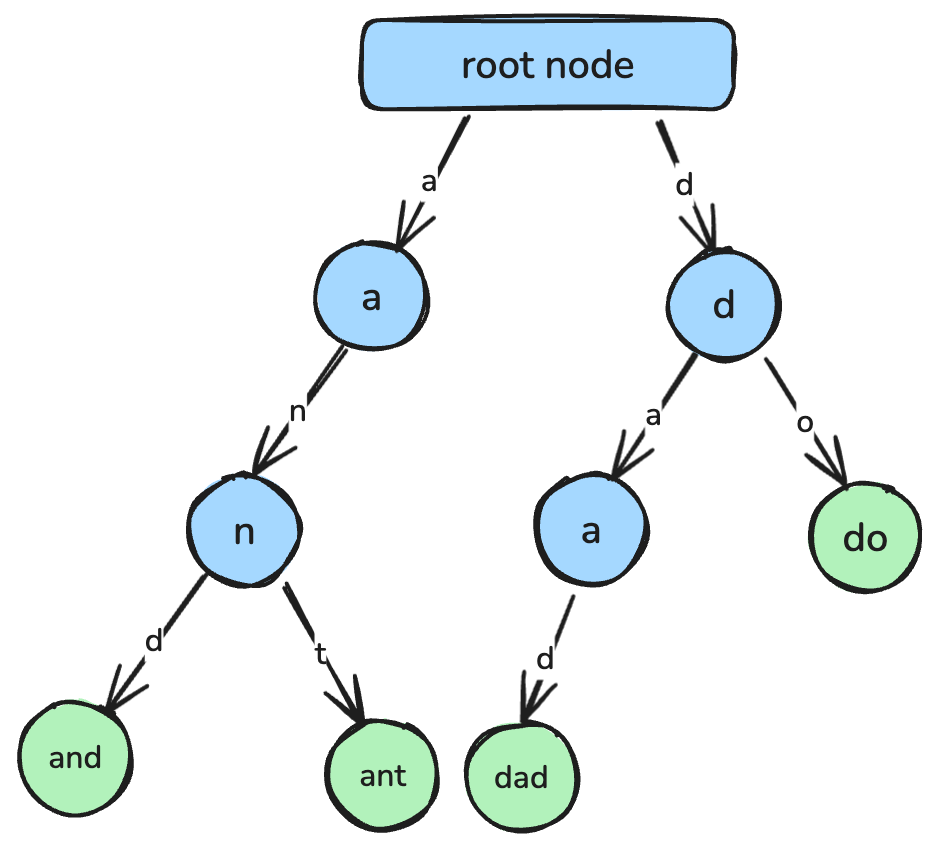
ไทรที่แต่ละโหนดแทนอักขระ ซึ่งเชื่อมต่อกันเป็นสตริง ภาพโดยผู้เขียน
คอลลิชันเกิดขึ้นเมื่อคีย์ต่างกันสองตัวแฮชไปยังดัชนีเดียวกัน
มีหลายวิธีแก้คอลลิชัน ได้แก่ chaining ที่เก็บองค์ประกอบที่ชนกันไว้ในลิงก์ลิสต์ที่ดัชนีนั้น และ open addressing ที่ค้นหาช่องว่างถัดไปในอาเรย์ด้วยวิธี probing เช่น linear probing, quadratic probing หรือ double hashing
กราฟเป็นโครงสร้างข้อมูลที่ประกอบด้วยกลุ่มจุดยอด (vertices หรือ nodes) เชื่อมโยงกันด้วยเส้นเชื่อม (edges) ใช้แสดงความสัมพันธ์และการเชื่อมต่อระหว่างเอนทิตีต่าง ๆ
Depth-first search (DFS) เป็นอัลกอริทึมที่สำรวจกราฟหรือต้นไม้โดยดำดิ่งไปตามกิ่งหนึ่งให้ลึกก่อนแล้วจึงย้อนกลับ สามารถติดตั้งด้วยสแตกแบบชัดเจนหรือรีเคอร์ชัน เวลาเชิงซ้อนคือ O(V + E) โดย V คือจำนวนจุดยอด และ E คือจำนวนเส้นเชื่อม หมายถึงอาจต้องตรวจจุดยอดและเส้นเชื่อมทั้งหมด
Breadth-first search (BFS) สำรวจโหนดทุกตัวในระดับความลึกปัจจุบันอย่างเป็นระบบก่อนย้ายไปยังระดับถัดไป มีประสิทธิภาพในการหาเส้นทางสั้นสุดในกราฟที่ไม่มีน้ำหนัก และมักติดตั้งด้วยคิว เช่นเดียวกับ DFS มีเวลาเชิงซ้อน O(V + E)
อัลกอริทึมการเรียงลำดับจำเป็นต่อการประมวลผลข้อมูลอย่างมีประสิทธิภาพ — ช่วยให้ค้นหาเร็วขึ้น วิเคราะห์ข้อมูลดีขึ้น และมองเห็นภาพได้ง่ายขึ้น เมื่อเลือกใช้งาน มีจุดแลกเปลี่ยนสำคัญที่ควรคำนึงถึง:
ตัวอย่างการติดตั้ง Python ที่กระชับของแต่ละแบบ:
# Bubble sort — sorts in place
def bubble_sort(arr):
n = len(arr)
for i in range(n):
for j in range(0, n - i - 1):
if arr[j] > arr[j + 1]:
arr[j], arr[j + 1] = arr[j + 1], arr[j]
# Quick sort — sorts in place
def partition(arr, low, high):
pivot = arr[high]
i = low - 1
for j in range(low, high):
if arr[j] <= pivot:
i += 1
arr[i], arr[j] = arr[j], arr[i]
arr[i + 1], arr[high] = arr[high], arr[i + 1]
return i + 1
def quick_sort(arr, low, high):
if low < high:
pi = partition(arr, low, high)
quick_sort(arr, low, pi - 1)
quick_sort(arr, pi + 1, high)
# Merge sort — returns a new sorted list
def merge(left, right):
result = []
i = j = 0
while i < len(left) and j < len(right):
if left[i] <= right[j]:
result.append(left[i])
i += 1
else:
result.append[right[j])
j += 1
result.extend(left[i:])
result.extend(right[j:])
return result
def merge_sort(arr):
if len(arr) <= 1:
return arr
mid = len(arr) // 2
left_half = merge_sort(arr[:mid])
right_half = merge_sort(arr[mid:])
return merge(left_half, right_half)nums = [3, 1, 4, 1, 5, 9, 2, 6]
bubble_sort(nums) # sorts nums in place
quick_sort(nums, 0, len(nums) - 1) # also in place
sorted_nums = merge_sort(nums) # returns a new listในห้องสัมภาษณ์ คำตอบข้างต้นก็เพียงพอ แต่หากอยากโดดเด่น ให้เอ่ยว่าฟังก์ชันในตัวของ Python อย่าง sorted() และ list.sort() ใช้ Timsort ซึ่งเป็นไฮบริดของ merge sort และ insertion sort จึงแทบไม่ต้องเขียนอัลกอริทึมเรียงเองในโค้ดโปรดักชัน
มีอัลกอริทึมหลายตัวสำหรับหาเส้นทางสั้นสุดในกราฟ
สำหรับกราฟไม่มีน้ำหนัก BFS จะสำรวจโหนดเป็นชั้นอย่างมีประสิทธิภาพ ในกราฟมีน้ำหนักที่น้ำหนักไม่เป็นลบ อัลกอริทึมของ Dijkstra จะหาเส้นทางสั้นสุดโดยพิจารณาจุดยอดที่ใกล้สุดก่อน
อัลกอริทึม A* เพิ่มประสิทธิภาพด้วยฮิวริสติกในการประมาณค่าใช้จ่ายที่เหลือ ตัวเลือกอัลกอริทึมขึ้นกับลักษณะของกราฟและข้อกำหนดของปัญหา
มาดูคำถามขั้นสูงสำหรับผู้สมัครสายอาวุโสหรือผู้ที่ต้องการแสดงความรู้เชิงลึกด้านโครงสร้างข้อมูลเฉพาะทางหรือซับซ้อน
Dynamic programming เป็นวิธีแก้ปัญหาซับซ้อนโดยแบ่งเป็นปัญหาย่อยที่ทับซ้อนกัน แทนที่จะเริ่มคำนวณใหม่ทุกครั้ง จะเก็บผลลัพธ์ของส่วนย่อยไว้ เพื่อลดการคำนวณซ้ำ
วิธีนี้มีประโยชน์มากในการหาลำดับร่วมยาวสุดของสองสตริง หรือหาต้นทุนต่ำสุดเพื่อไปยังจุดหนึ่งบนกริด
B-tree เป็นโครงสร้างต้นไม้ที่สมดุล ออกแบบมาเพื่อการเข้าถึงดิสก์อย่างมีประสิทธิภาพ คุณลักษณะบางประการ:
ข้อได้เปรียบเหนือ BST มีดังนี้:
การเรียงลำดับแบบทอปอโลยีเป็นอัลกอริทึมที่จัดลำดับจุดยอดของกราฟมีทิศทางไร้วงจร (DAG) โดยถ้ามีเส้นเชื่อมจากจุดยอด u ไปยัง v แล้ว u ต้องมาก่อน v ในลำดับ มักใช้ในการจัดตารางงาน — กำหนดลำดับการทำงานให้เคารพการพึ่งพากัน — รวมถึงในระบบบิลด์ ตัวจัดการแพ็กเกจ และการวางแผนรายวิชาที่มีวิชาบังคับก่อน
มินฮีป เป็นการติดตั้งเฉพาะของคิวลำดับความสำคัญ กำหนดเป็นต้นไม้ทวิภาคสมบูรณ์ที่ค่าของแต่ละโหนดน้อยกว่าหรือเท่ากับค่าของลูก ทำให้ค้นหาและดึงค่าน้อยสุดได้มีประสิทธิภาพ
ขณะที่ คิวลำดับความสำคัญ เป็นโครงสร้างข้อมูลเชิงนามธรรมที่ใส่องค์ประกอบพร้อมลำดับความสำคัญได้ และนำออกตามลำดับความสำคัญ มินฮีปเป็นวิธีติดตั้งที่พบบ่อยเพราะจัดการปฏิบัติการเหล่านี้ได้อย่างมีประสิทธิภาพ
โครงสร้างข้อมูลแบบเซตไม่ทับซ้อน หรือ union-find รักษาคอลเลกชันของเซตที่ไม่ทับซ้อนกัน โดยรองรับสองปฏิบัติการหลัก:
การประยุกต์ใช้มีมาก แต่ที่พบบ่อยคือ อัลกอริทึมของ Kruskal เพื่อหาต้นไม้ครอบคลุมขั้นต่ำของกราฟ และปัญหาโฟลว์ในเครือข่าย สำหรับระบุคอมโพเนนต์ที่เชื่อมต่อในกราฟ
เซกเมนต์ทรีเป็นโครงสร้างข้อมูลที่ออกแบบมาเพื่อรองรับการคิวรีช่วง (range queries) และการอัปเดตบนอาเรย์อย่างมีประสิทธิภาพ เหมาะกับสถานการณ์ที่ต้องทำซ้ำ ๆ เช่น หาผลรวม ค่าน้อยสุด ค่ามากสุด หรือหาตัวหารร่วมมากของช่วงองค์ประกอบในอาเรย์
สร้างเป็นต้นไม้ทวิภาค โดยแต่ละโหนดแทนช่วงหนึ่งของอาเรย์ ใบไม้แทนองค์ประกอบเดี่ยว ๆ ส่วนโหนดภายในเก็บข้อมูลที่รวมค่าจากลูกตามปฏิบัติการที่ใช้ ทำให้ทั้งการอัปเดตและการคิวรีมีเวลาเชิงซ้อน O(log n)
ซัฟฟิกซ์ทรีเก็บทุกซัฟฟิกซ์ของสตริง ทำให้ตอบคำถามการค้นหาแพตเทิร์นได้ตามความยาวแพตเทิร์น ไม่ใช่ความยาวข้อความ ซัฟฟิกซ์ทรีจริงใช้การบีบอัดขอบเพื่อให้ใช้พื้นที่ O(n) และมักสร้างด้วยอัลกอริทึมของ Ukkonen — แต่นั่นซับซ้อนจนผู้สัมภาษณ์แทบไม่คาดหวังให้เขียนสดภายใน 45 นาที
ทางเลือกที่พบบ่อยคือซัฟฟิกซ์ไทรที่ง่ายกว่า เก็บหนึ่งอักขระต่อโหนด ใช้พื้นที่ O(n²) แต่เขียนและอธิบายได้ง่าย เคล็ดลับในห้องสัมภาษณ์คือรู้ข้อแลกเปลี่ยนและบอกกล่าวอย่างชัดเจน
นี่คือตัวอย่างติดตั้งใน Python ที่กระชับ:
class SuffixTrieNode:
def __init__(self):
self.children = {} # Map of character -> child node
self.indices = [] # Starting positions of suffixes passing through this node
class SuffixTrie:
def __init__(self, text):
self.root = SuffixTrieNode()
self.text = text + "$" # Append a unique terminator
self._build()
def _build(self):
"""Insert every suffix of the text into the trie."""
for i in range(len(self.text)):
self._insert_suffix(i)
def _insert_suffix(self, index):
node = self.root
for i in range(index, len(self.text)):
c = self.text[i]
if c not in node.children:
node.children[c] = SuffixTrieNode()
node = node.children[c]
node.indices.append(index)
def search(self, pattern):
"""Return all starting positions where `pattern` appears in the text."""
node = self.root
for c in pattern:
if c not in node.children:
return []
node = node.children[c]
return node.indicesควอดทรีเป็นโครงสร้างต้นไม้แบบลำดับชั้นที่แบ่งย่อยพื้นที่สองมิติซ้ำ ๆ ออกเป็นสี่ควอดแรนต์เท่า ๆ กัน เทคนิคการแบ่งพื้นที่นี้มีประสิทธิผลมากในงานประมวลผลภาพ การตรวจการชนในเกม และระบบสารสนเทศภูมิศาสตร์เพื่อการจัดเก็บและดึงข้อมูลเชิงพื้นที่อย่างมีประสิทธิภาพ
การแสดงความรู้โครงสร้างข้อมูลนั้นสำคัญ แต่การแสดงให้เห็นว่ารู้จักใช้ให้เหมาะสมยิ่งทำให้โดดเด่น ส่วนนี้จะทบทวนการประยุกต์ใช้ความรู้โครงสร้างข้อมูลกับสถานการณ์จริง
ด้วยธรรมชาติของปัญหาแบบเรียลไทม์ จึงต้องใช้โครงสร้างข้อมูลที่มีประสิทธิภาพ
จากประสบการณ์ของฉัน จะใช้ควอดทรีสำหรับข้อมูลภูมิศาสตร์ คิวลำดับความสำคัญเพื่อจัดอันดับการจับคู่ตามระยะทางและความเร่งด่วนของผู้โดยสาร และตารางแฮชเพื่อค้นหาตำแหน่งนักขับและผู้โดยสารอย่างรวดเร็ว
สามารถใช้โครงสร้างข้อมูลผสมผสานเพื่อแนะนำสินค้าอย่างมีประสิทธิภาพจากพฤติกรรมผู้ใช้
เมทริกซ์ผู้ใช้-สินค้าแบบเบาบางใช้เก็บปฏิสัมพันธ์ แท็บแฮชใช้แม็ปผู้ใช้และสินค้าอย่างรวดเร็ว คิวลำดับความสำคัญจัดอันดับคำแนะนำ และโครงสร้างกราฟจำลองความสัมพันธ์ผู้ใช้-สินค้าเพื่อการวิเคราะห์ขั้นสูง เช่น การตรวจจับชุมชน
โครงสร้างข้อมูลแบบกราฟมีประสิทธิภาพสูงในการตรวจจับและลบแอคเคานต์สแปม โดยแทนผู้ใช้เป็นโหนดและการเชื่อมต่อเป็นเส้นเชื่อม วิเคราะห์โทโพโลยีเครือข่ายเพื่อระบุคลัสเตอร์หนาแน่น โหนดโดดเดี่ยว และการพุ่งขึ้นของกิจกรรม เพื่อระบุบัญชีที่น่าสงสัย
ควรใช้โครงสร้างข้อมูลหลายชนิดร่วมกันในแอปแชตเรียลไทม์
ตารางแฮชเก็บรหัสผู้ใช้และรายชื่อการเชื่อมต่อ เพื่อค้นหาผู้ใช้ที่จะส่งข้อความหาได้รวดเร็ว คิวสำหรับผู้ใช้แต่ละรายเพื่อคงลำดับข้อความให้ตรงตามการส่ง และต้นไม้ เช่น AVL tree สำหรับเก็บและดึงสถานะออนไลน์/ออฟไลน์อย่างมีประสิทธิภาพ เพื่ออัปเดตความพร้อมใช้งานแบบเรียลไทม์
สำหรับตัวตรวจการสะกด การค้นหาคำอย่างมีประสิทธิภาพสำคัญมาก ไทรเป็นโครงสร้างข้อมูลที่เหมาะ โหนดแต่ละตัวแทนตัวอักษร และเส้นทางในไทรก่อเป็นคำ ทำให้ค้นหาตามคำนำหน้าได้รวดเร็ว ช่วยเสนอคำแก้ไขได้ไว
ในสถานการณ์นี้ เซกเมนต์ทรีโดดเด่นมาก เพราะรับมือกับคิวรีช่วงและการอัปเดตได้มีประสิทธิภาพ เราสามารถแทนแผนที่เกมเป็นอาเรย์ 1 มิติ โดยแต่ละองค์ประกอบสอดคล้องกับช่องกริด และเก็บข้อมูลว่ามีสิ่งปลูกสร้างหรือไม่
การเตรียมสัมภาษณ์เรื่องโครงสร้างข้อมูลอาจท้าทาย แต่การวางแผนเป็นระบบช่วยให้จัดการได้!
โฟกัสที่การเชี่ยวชาญแนวคิดพื้นฐานของโครงสร้างข้อมูล เช่น อาเรย์ ลิงก์ลิสต์ สแตก คิว ต้นไม้ กราฟ และตารางแฮช เข้าใจหลักการ วิธีจัดการข้อมูล และเวลาเชิงซ้อนของปฏิบัติการอย่างการแทรก ลบ และค้นหา
รู้แนวคิดอย่างเดียวไม่พอ ควรรู้จักติดตั้งโครงสร้างข้อมูลเหล่านี้จากศูนย์ด้วย สามารถมีส่วนร่วมกับ คอร์สของ DataCamp เพื่อฝึกโจทย์เขียนโค้ดที่ช่วยลับทักษะแก้ปัญหา
การเข้าใจข้อแลกเปลี่ยนระหว่างโครงสร้างข้อมูลเป็นกุญแจ เช่น อาเรย์เข้าถึงเร็วแต่มีต้นทุนสูงในการแทรก/ลบ ขณะที่ลิงก์ลิสต์แก้ไขได้มีประสิทธิภาพแต่ต้องไล่ลำดับเพื่อเข้าถึง เตรียมพร้อมอธิบายข้อแลกเปลี่ยนเหล่านี้ในการสัมภาษณ์
จำไว้ว่า การสื่อสารสำคัญพอ ๆ กับโค้ด. ผู้สัมภาษณ์มองหาผู้สมัครที่ปรับการอธิบายให้เหมาะกับผู้ฟังได้ ดังที่กล่าวไว้ใน พอดแคสต์ DataFramed ว่าด้วยอนาคตของงานด้านข้อมูล:
คุณต้องสามารถสื่อสารอินไซต์ได้ทุกแบบ ทั้งให้เด็กหกขวบเข้าใจได้ และให้ฉันหรือคนที่เทคนิคเข้มข้นกว่านั้นพอใจได้ ถ้าคุณรู้จริง คุณทำให้มันง่ายมากก็ได้ หรือจะซับซ้อนจนมีแต่ผู้เชี่ยวชาญระดับสูงจริง ๆ เท่านั้นที่เข้าใจก็ได้
Mo Chen, Data & Analytics Manager at NatWest Group
เรียนรู้เพิ่มเติมเกี่ยวกับโครงสร้างข้อมูลและพื้นฐาน Python ด้วยคอร์สเหล่านี้!
Courses
Courses
Courses