course
Intermediate Python
4 timmar
1.4M
För att visa att du förstår grundläggande datastrukturer behöver du vara mycket trygg med kärnstrukturerna och deras implementationer. Frågor som följande testar din förmåga att förklara dessa idéer och visar din kunskap.
Datastrukturer klassificeras enligt följande:
Arrayer och länkade listor är två sätt att lagra grupper av objekt, men de fungerar olika. Här är de viktigaste skillnaderna:
En stack är en ordnad lista där du lägger till och tar bort objekt i ena änden, kallad toppen. Den följer principen sist in, först ut (LIFO): det senast tillagda elementet är det som tas bort först.
Stackar kan användas i flera tillämpningar, såsom uttrycksvärdering, backtracking, minneshantering samt funktionsanrop och returvärden.
I Python fungerar en lista som en stack direkt: append() är push, och pop() tar bort det översta objektet.
my_stack = []
item = 1
my_stack.append(item)
my_stack.pop()Genom att hålla reda på toppens position med ett index kan du göra dessa operationer snabba och effektiva.
En kö är en först in, först ut-struktur (FIFO) — som en kö i en butik, där folk går in bakifrån och lämnar längst fram.
I Python kan du implementera en kö med olika tekniker:
Med en array eller lista och genom att använda metoderna append() och pop():
my_queue = []
item = 1
# Enqueue
my_queue.append(item)
# Dequeue
my_queue.pop(0)Med deque() från biblioteket collections, som utför append()- och pop()-funktioner snabbare än listor:
from collections import deque
my_queue = deque()
item = 1
# Enqueue
my_queue.append(item)
# Dequeue
my_queue.popleft()Med den inbyggda modulen queue.Queue:
from queue import Queue
my_queue = Queue(maxsize = 3)
# Enqueue
my_queue.put(item)
# Dequeue
my_queue.get()Ett binärt träd är en datastruktur där varje nod har högst två barn: ett vänsterbarn och ett högerbarn. Ett binärt sökträd (BST) är sedan en specifik typ av binärt träd som har särskilda ordningsegenskaper: För varje nod är alla nycklar i vänstra delträdet mindre, alla nycklar i högra delträdet större, och båda delträden är i sig BST.
Dessa egenskaper möjliggör effektiva operationer såsom sökning, insättning och borttagning, vanligtvis med tidskomplexiteten O(log n) i balanserade träd.
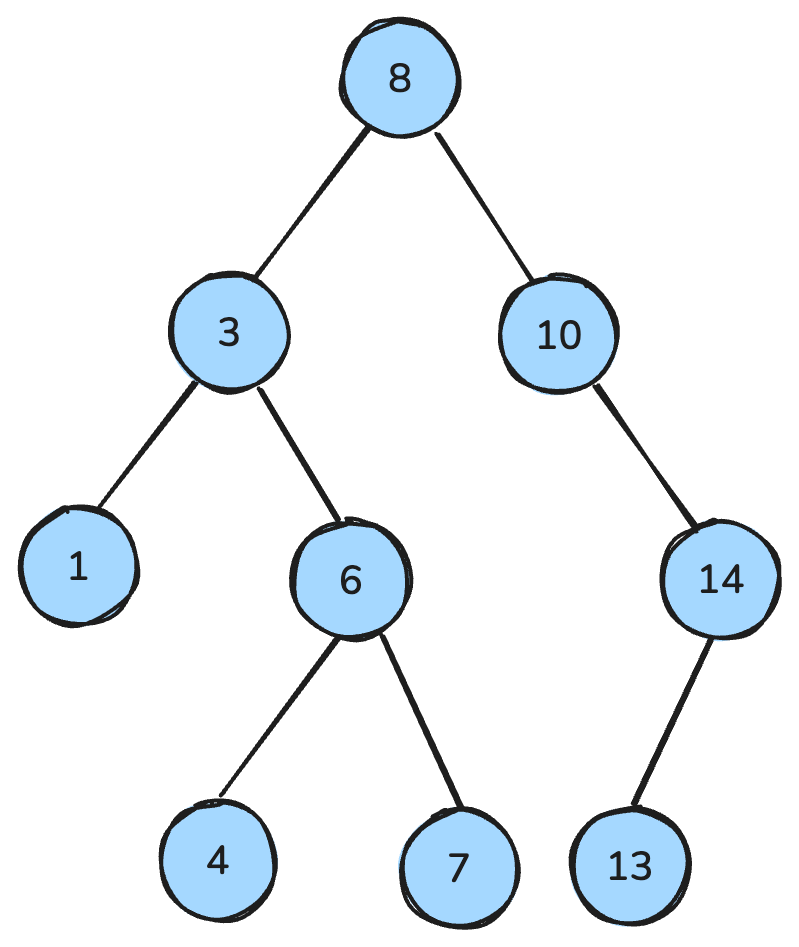
Binärt sökträd. Bild av författaren.
Hashing är en teknik som tar data av godtycklig storlek och omvandlar den till ett värde med fast storlek, kallat ett hashvärde med hjälp av en hashfunktion.
En vanlig användning av hashing är i hashtabeller, där det hjälper till att matcha nycklar med specifika positioner i en array, vilket gör det enkelt att snabbt hitta och hämta data. Hashing kan ha många tillämpningar, från att hjälpa till att säkra lösenord inom kryptografi till att hålla data organiserad genom deduplicering.
En heap är en datastruktur som liknar ett träd och följer särskilda regler.
I en max-heap är varje förälder större än eller lika med sina barn; i en min-heap är varje förälder mindre än eller lika med sina barn.
Heapar används ofta för att skapa prioritetsköer, som hjälper till att sortera objekt baserat på deras vikt eller värde. De är också viktiga för heapsort, som är en metod för att organisera data effektivt.
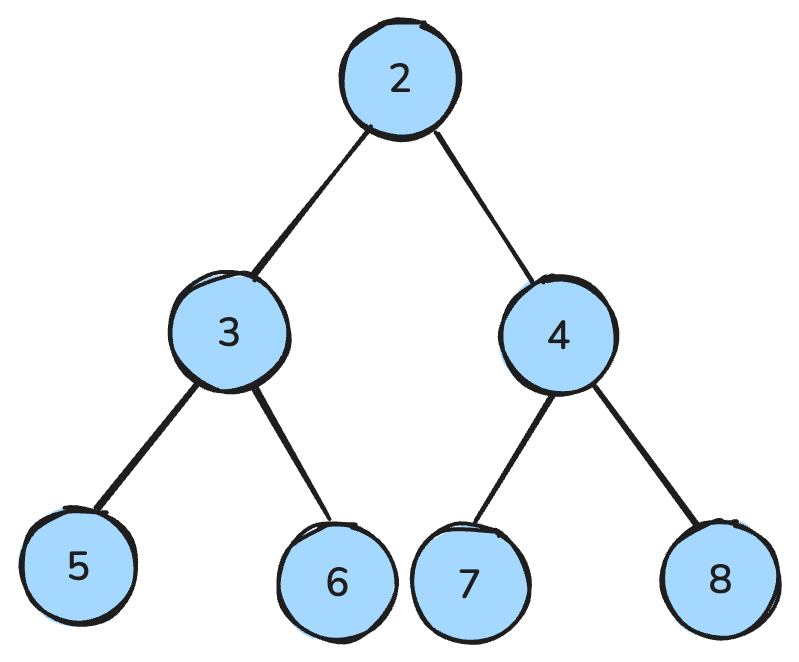
En min-heap är där alla föräldranoder är mindre än barnen — bild av författaren.
Efter grunderna går vi vidare till frågor på mellannivå som utforskar din tekniska skicklighet i att implementera och använda dessa fundamentala koncept.
Ett balanserat binärt sökträd upprätthåller relativt lika höjd mellan sina vänstra och högra delträd. Att balansera ett BST är mycket viktigt för att bibehålla effektiva sök-, insättnings- och borttagningsoperationer.
Tekniker som AVL-träd och röd-svarta träd används ofta för att åstadkomma självbalansering. AVL-träd upprätthåller en höjdskillnad på högst 1 mellan vänstra och högra delträdet för varje nod, medan röd-svarta träd har striktare balanskrav.
En min-heap stöds vanligtvis av en lista. De två nyckeloperationerna är insert (som lägger till ett element och bubblar upp det för att återställa heap-egenskapen) och extract_min (som tar bort roten och siftar ned för att återställa ordningen):
class MinHeap:
def __init__(self):
self.heap = []
def __len__(self): # Get the size of the heap
return len(self.heap)
def __parent(self, i): # Get the parent index
return (i - 1) // 2
def __left(self, i): # Get the left child index
return 2 * i + 1
def __right(self, i): # Get the right child index
return 2 * i + 2
def __swap(self, i, j): # Swap two elements
self.heap[i], self.heap[j] = self.heap[j], self.heap[i]
def __heapify_up(self, i): # Restore min-heap property after insertion
while i > 0 and self.heap[i] < self.heap[self.__parent(i)]:
self.__swap(i, self.__parent(i))
i = self.__parent(i)
def __heapify_down(self, i): # Restore min-heap property after extraction
while True:
smallest = i
left = self.__left(i)
right = self.__right(i)
if left < len(self) and self.heap[left] < self.heap[smallest]:
smallest = left
if right < len(self) and self.heap[right] < self.heap[smallest]:
smallest = right
if smallest != i:
self.__swap(i, smallest)
i = smallest
else:
break
def insert(self, val): # Insert a value into the heap
self.heap.append(val)
self.__heapify_up(len(self) - 1)
def extract_min(self): # Extract the minimum value from the heap
if not self.heap:
return None
min_val = self.heap[0]
self.heap[0] = self.heap[-1]
self.heap.pop()
self.__heapify_down(0)
return min_valEn trie, även känd som ett prefixträd, är en trädbaserad datastruktur utformad för effektiv stränghämtning och prefixmatchning.
I en trie representerar varje nod ett enskilt tecken, och vägarna från roten till noderna motsvarar kompletta strängar. Tries används ofta i olika tillämpningar, såsom autofullständningsfunktioner, stavningskontroller och implementation av ordlistor.
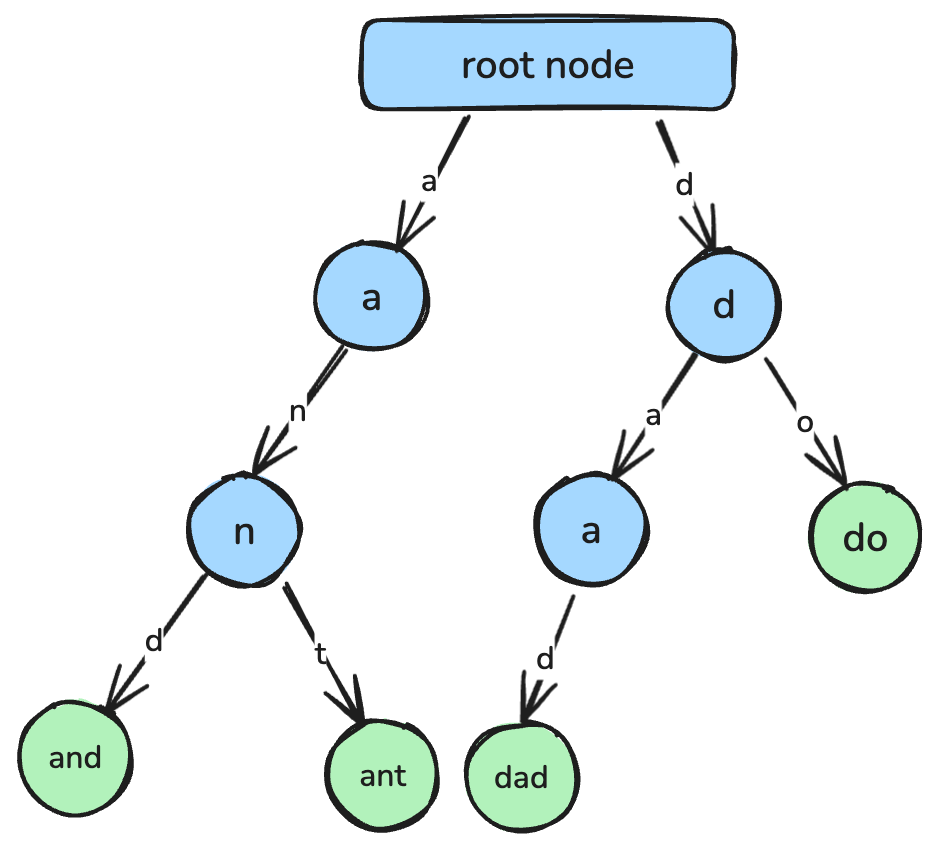
En trie där varje nod representerar ett enskilt tecken som kopplas samman till en sträng. Bild av författaren.
En kollision uppstår när två olika nycklar hashas till samma index.
Det finns flera metoder för att lösa kollisioner, inklusive kedjning, där kolliderande element lagras i en länkad lista vid motsvarande index, och öppen adressering, som innebär att man hittar nästa lediga plats i arrayen via sonderingsmetoder som linjär sondering, kvadratisk sondering eller dubbel hashing.
En graf är en datastruktur som består av en samling hörn, även kallade noder, sammankopplade med kanter. Denna struktur är användbar för att illustrera relationer och kopplingar mellan olika entiteter.
Depth-first search (DFS) är en algoritm som utforskar en graf eller ett träd genom att gå djupt i varje gren innan den backar. Den kan implementeras med en explicit stack eller via rekursion. Tidskomplexiteten är O(V + E), där V är antalet hörn och E är antalet kanter, vilket betyder att den kan behöva undersöka alla hörn och kanter.
Breadth-first search (BFS) utforskar systematiskt alla noder på aktuell djupnivå innan den går vidare till nästa nivå. Den är effektiv för att hitta kortaste vägen i oviktade grafer och implementeras vanligtvis med en kö. Liksom DFS har BFS tidskomplexiteten O(V + E) och kräver en genomgång av alla hörn och kanter.
Sorteringsalgoritmer är avgörande för effektiv databehandling — de möjliggör snabbare sökning, förbättrad dataanalys och enklare datavisualisering. När du väljer mellan dem finns det några viktiga avvägningar att ha i åtanke:
Här är rena Python-implementationer av var och en:
# Bubble sort — sorts in place
def bubble_sort(arr):
n = len(arr)
for i in range(n):
for j in range(0, n - i - 1):
if arr[j] > arr[j + 1]:
arr[j], arr[j + 1] = arr[j + 1], arr[j]
# Quick sort — sorts in place
def partition(arr, low, high):
pivot = arr[high]
i = low - 1
for j in range(low, high):
if arr[j] <= pivot:
i += 1
arr[i], arr[j] = arr[j], arr[i]
arr[i + 1], arr[high] = arr[high], arr[i + 1]
return i + 1
def quick_sort(arr, low, high):
if low < high:
pi = partition(arr, low, high)
quick_sort(arr, low, pi - 1)
quick_sort(arr, pi + 1, high)
# Merge sort — returns a new sorted list
def merge(left, right):
result = []
i = j = 0
while i < len(left) and j < len(right):
if left[i] <= right[j]:
result.append(left[i])
i += 1
else:
result.append(right[j])
j += 1
result.extend(left[i:])
result.extend(right[j:])
return result
def merge_sort(arr):
if len(arr) <= 1:
return arr
mid = len(arr) // 2
left_half = merge_sort(arr[:mid])
right_half = merge_sort(arr[mid:])
return merge(left_half, right_half)nums = [3, 1, 4, 1, 5, 9, 2, 6]
bubble_sort(nums) # sorts nums in place
quick_sort(nums, 0, len(nums) - 1) # also in place
sorted_nums = merge_sort(nums) # returns a new listI en intervju räcker svaret ovan. Men om du vill sticka ut, nämn att Pythons inbyggda sorted() och list.sort() använder Timsort, en hybrid av mergesort och insertionssortering. Det är därför du nästan aldrig skriver en sortering från grunden i produktions-Python.
Flera algoritmer kan användas för att hitta kortaste vägen i grafer.
För oviktade grafer är breadth-first search effektivt och utforskar noder lager för lager. I viktade grafer med icke-negativa kanter identifierar Dijkstras algoritm kortaste vägen genom att undersöka närmaste hörn först.
Algoritmen A* ökar effektiviteten genom att använda heuristik för att uppskatta återstående kostnader. Valet av algoritm beror på grafens egenskaper och de specifika kraven i problemet.
Låt oss utforska några avancerade intervjufrågor för dig som söker mer seniora roller eller vill visa djup kunskap om specialiserade eller komplexa datastrukturer.
Dynamisk programmering är en metod för att lösa komplexa problem genom att dela upp dem i mindre överlappande delproblem. I stället för att börja från noll varje gång håller du reda på lösningarna till de mindre delarna, vilket betyder att du slipper göra samma beräkningar upprepade gånger.
Denna metod är mycket användbar för att hitta den längsta gemensamma delsekvensen mellan två strängar eller för att hitta minsta kostnad för att nå en specifik punkt på ett rutnät.
B-träd är balanserade träddatastrukturer utformade för effektiv disktillgång. Några av dess egenskaper är:
De erbjuder flera fördelar jämfört med binära sökträd:
Topologisk sortering är en algoritm som används för att ordna hörnen i en riktad acyklisk graf (DAG) så att om det finns en kant från hörn u till hörn v så kommer u före v i ordningen. Det används ofta vid schemaläggning av uppgifter — att avgöra i vilken ordning uppgifter måste köras för att respektera sina beroenden — samt i byggsystem, pakethanterare och planering av kursförkunskaper.
En min-heap är en specifik implementation av en prioritetskö och definieras som ett komplett binärt träd där värdet i varje nod är mindre än eller lika med värdena hos dess barn, vilket möjliggör effektiva operationer när man hittar och extraherar minsta elementet.
En prioritetskö å andra sidan är en abstrakt datastruktur som tillåter insättning av element med en associerad prioritet, där element tas ut i ordning efter sin prioritet. Min-heapar är ett vanligt sätt att implementera prioritetsköer på grund av deras förmåga att hantera dessa operationer effektivt.
En disjoint-set-datastruktur, även känd som union-find, underhåller en samling åtskilda mängder. Denna datastruktur stöder två primära operationer:
Det finns många tillämpningar av disjoint sets, men de vanligaste är Kruskal's algoritm för att hitta ett grafs minimala uppspännande träd och nätverksflödesproblemet för att avgöra sammanhängande komponenter i en graf.
Ett segmentträd är en datastruktur utformad för att möjliggöra effektiva intervallfrågor och uppdateringar på en array. Den är särskilt användbar i scenarier där vi upprepade gånger behöver utföra operationer såsom att hitta summan, minimum, maximum eller största gemensamma delare över ett specifikt intervall av element i arrayen.
Det konstrueras som ett binärt träd där varje nod representerar ett segment av arrayen. Trädets blad motsvarar enskilda element i arrayen, medan interna noder lagrar information som aggregerar värdena från sina barnnoder enligt den operation som utförs. De uppnår O(log n) i tidskomplexitet för både uppdateringar och frågor.
Ett suffixtree lagrar varje suffix av en sträng så att sökningar kan besvaras på tid proportionell mot mönstrets längd, inte textens längd. Ett riktigt suffixtree använder kantkompression för att uppnå O(n) utrymme och byggs vanligtvis med Ukkonens algoritm — men det är så pass komplext att intervjuare sällan förväntar sig att du kodar det från grunden på 45 minuter.
Ett vanligt kompromissval är det enklare suffixtriet, som lagrar ett tecken per nod. Det använder O(n²) utrymme men är mycket lättare att skriva och förklara. Knepet på en intervju är att känna till avvägningen och säga det uttryckligen.
Här är en ren Python-implementation:
class SuffixTrieNode:
def __init__(self):
self.children = {} # Map of character -> child node
self.indices = [] # Starting positions of suffixes passing through this node
class SuffixTrie:
def __init__(self, text):
self.root = SuffixTrieNode()
self.text = text + "$" # Append a unique terminator
self._build()
def _build(self):
"""Insert every suffix of the text into the trie."""
for i in range(len(self.text)):
self._insert_suffix(i)
def _insert_suffix(self, index):
node = self.root
for i in range(index, len(self.text)):
c = self.text[i]
if c not in node.children:
node.children[c] = SuffixTrieNode()
node = node.children[c]
node.indices.append(index)
def search(self, pattern):
"""Return all starting positions where `pattern` appears in the text."""
node = self.root
for c in pattern:
if c not in node.children:
return []
node = node.children[c]
return node.indicesQuadtrees är en hierarkisk träddatastruktur som rekursivt delar upp ett tvådimensionellt utrymme i fyra lika kvadranter. Denna rumsliga partitioneringsteknik är mycket effektiv för tillämpningar som bildbehandling, kollisiondetektering i spel och geografiska informationssystem för effektiv lagring och hämtning av rumslig data.
Att visa din kunskap om datastrukturer är viktigt, men att visa att du vet när du ska använda dem på rätt sätt får dig att sticka ut på intervjun. I det här avsnittet går vi igenom hur du tillämpar din kunskap om datastrukturer i praktiska situationer.
På grund av problemets realtidsnatur krävs effektiva datastrukturer för denna utmaning.
Utifrån min erfarenhet skulle jag använda quadtrees för geografisk data, prioritetsköer för att rangordna potentiella matchningar baserat på avstånd och passagerarens brådska, samt hashtabeller för effektiva uppslag av förares och passagerares positioner.
Vi kan använda en kombination av datastrukturer för att effektivt rekommendera produkter baserat på användarbeteende.
En gles användar-objekt-matris skulle lagra interaktioner mellan användare och produkter, medan hashtabeller effektivt mappar användare och objekt. Prioritetsköer skulle rangordna rekommendationer, och grafstrukturer kan modellera relationer mellan användare och objekt för mer sofistikerade analyser som att upptäcka gemenskaper.
En grafdatastruktur kan vara mycket effektiv för att upptäcka och ta bort spamkonton på en social nätverksplattform. Du kan analysera nätverkstopologin genom att representera användare som noder och deras kopplingar som kanter. Att identifiera tätt sammanlänkade kluster, isolerade noder och plötsliga aktivitetsökningar kan hjälpa till att flagga misstänkta konton.
Jag skulle använda en kombination av datastrukturer i en realtidschatt.
Hashtabeller skulle lagra användar-ID:n och deras motsvarande anslutningslistor, vilket möjliggör snabba uppslag av vilka användare som ska få meddelanden. Köer skulle implementeras för varje användare för att bevara ordningen på meddelandena och säkerställa att de levereras i den sekvens de skickades. Dessutom kan träd, såsom AVL-träd, användas för att effektivt lagra och hämta användares online-/offlinestatus, vilket möjliggör realtidsuppdateringar av tillgänglighet.
För en stavningskontroll är effektiv orduppslagning mycket viktig. En trie skulle vara en idealisk datastruktur. Varje nod i trien representerar en bokstav och vägar genom trien bildar ord. Detta möjliggör snabba prefixbaserade sökningar, vilket gör att stavningskontrollen snabbt kan föreslå korrigeringar för felstavade ord.
I just detta scenario utmärker sig segmentträd som ett utmärkt val. De är mycket bra på att hantera intervallfrågor och uppdateringar effektivt. Vi kan representera spelkartan som en endimensionell array, där varje element motsvarar en rutnätscell. Varje cell kan lagra information om en struktur finns eller inte.
Jag vet att det kan vara utmanande att förbereda sig för en intervju om datastrukturer, men ett strukturerat angreppssätt kan göra det mer hanterbart!
Fokusera på att bemästra de grundläggande koncepten bakom datastrukturer, såsom arrayer, länkade listor, stackar, köer, träd, grafer och hashtabeller. Förstå deras principer, hur de hanterar data och tidskomplexiteten för operationer som insättning, borttagning och sökning.
Att kunna koncepten är bra men inte tillräckligt. Du bör veta hur man implementerar dessa datastrukturer från grunden. Du kan engagera dig i DataCamp-kurser för att dra nytta av kodningsutmaningar som skärper dina problemlösningsfärdigheter.
Att förstå avvägningarna mellan datastrukturer är nyckeln. Till exempel möjliggör arrayer snabb åtkomst men kan vara kostsamma för insättningar och borttagningar, medan länkade listor erbjuder effektiva ändringar men kräver genomgång för åtkomst. Var beredd att diskutera dessa avvägningar under intervjun.
Kom ihåg att kommunikation är minst lika viktig som kod. Intervjuare letar efter kandidater som kan anpassa sina förklaringar till publiken. Som diskuterats i DataFramed-podden om datarollernas framtid:
Du måste kunna leverera vilken typ av insikt som helst på ett sätt som ett sexårigt barn kan förstå och på ett sätt som skulle tillfredsställa mig eller till och med någon ännu mer teknisk. Så om du verkligen kan dina grejer kan du verkligen förenkla det, men du kan också göra det så komplicerat att ärligt talat bara de som verkligen, verkligen ligger i topp vad gäller teknisk expertis kan förstå.
Mo Chen, Data & Analytics Manager at NatWest Group
Lär dig mer om datastrukturer och grunderna i Python med dessa kurser!
course
course
course