
Curso
Python intermediário
4 h
1.4M
Para demonstrar seu entendimento, é importante ter segurança nas estruturas centrais e suas implementações. As perguntas a seguir testam sua habilidade de explicar esses conceitos e mostrar seu conhecimento.
As estruturas de dados são classificadas da seguinte forma:
Arrays e listas ligadas armazenam grupos de itens, mas funcionam de maneiras diferentes. Veja as principais diferenças:
Uma pilha é uma lista ordenada na qual você adiciona e remove itens por uma única extremidade, chamada topo. Segue o princípio LIFO (last-in, first-out): o último elemento que entrou é o primeiro a sair.
Pilhas são usadas em várias aplicações, como avaliação de expressões, backtracking, gerenciamento de memória e chamadas/retornos de funções.
Em Python, uma lista funciona como pilha nativamente: append() é o push, e pop() remove o topo.
my_stack = []
item = 1
my_stack.append(item)
my_stack.pop()Mantendo o índice do topo, você torna essas operações rápidas e eficientes.
Uma fila segue o princípio FIFO (first-in, first-out) — como a fila de um caixa, em que as pessoas entram atrás e saem pela frente.
Em Python, você pode implementar uma fila de diferentes maneiras:
Usando uma lista e aproveitando os métodos append() e pop():
my_queue = []
item = 1
# Enfileirar (enqueue)
my_queue.append(item)
# Desenfileirar (dequeue)
my_queue.pop(0)Usando deque() da biblioteca collections, que executa append() e pop() mais rápido que listas:
from collections import deque
my_queue = deque()
item = 1
# Enfileirar
my_queue.append(item)
# Desenfileirar
my_queue.popleft()Usando o módulo interno queue.Queue:
from queue import Queue
my_queue = Queue(maxsize = 3)
# Enfileirar
my_queue.put(item)
# Desenfileirar
my_queue.get()Uma árvore binária é uma estrutura em que cada nó tem no máximo dois filhos: esquerdo e direito. Já a árvore de busca binária (BST) é um tipo específico de árvore binária com propriedades de ordenação: para todo nó, todas as chaves na subárvore esquerda são menores, todas as chaves na subárvore direita são maiores, e ambas as subárvores também são BSTs.
Essas propriedades permitem operações eficientes de busca, inserção e remoção, normalmente com complexidade O(log n) em árvores balanceadas.
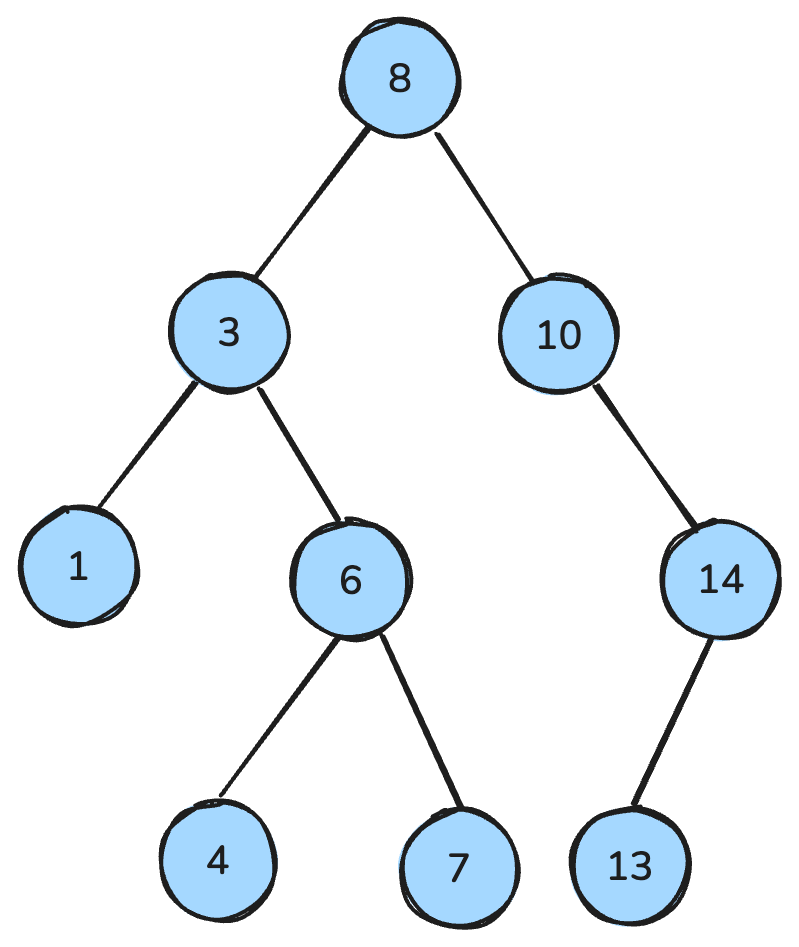
Árvore de busca binária. Imagem do autor.
Hashing é uma técnica que transforma dados de qualquer tamanho em um valor de tamanho fixo chamado hash, usando uma função de hash.
Um uso comum é em tabelas hash, associando chaves a posições específicas em um array, o que facilita localizar e recuperar dados rapidamente. Hashing também é aplicado em criptografia (armazenamento seguro de senhas) e em deduplicação para organizar dados.
Heap é uma estrutura em forma de árvore que segue regras específicas.
Em um max-heap, todo pai é maior ou igual aos filhos; em um min-heap, todo pai é menor ou igual aos filhos.
Heaps são muito usados para criar filas de prioridade, classificando itens por importância. Também são a base do heap sort, um método eficiente de ordenação.
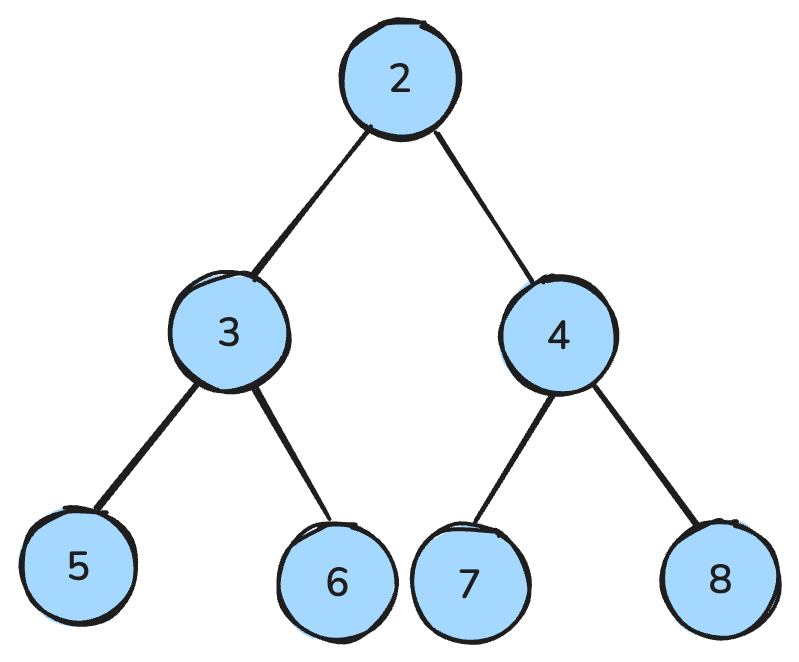
Em um min-heap, todos os nós pai são menores que os filhos — imagem do autor.
Depois dos fundamentos, vamos a perguntas de nível intermediário que exploram sua proficiência técnica em implementar e usar esses conceitos.
Uma BST balanceada mantém alturas semelhantes entre as subárvores esquerda e direita. Balancear é crucial para preservar a eficiência de busca, inserção e remoção.
Técnicas como árvores AVL e árvores rubro-negras são usadas para auto-balanceamento. AVL mantém diferença de altura de no máximo 1 entre as subárvores; árvores rubro-negras têm restrições de balanceamento mais rígidas.
Um min-heap normalmente é suportado por uma lista. As duas operações-chave são insert (adiciona um elemento e faz o bubble-up para restaurar a propriedade do heap) e extract_min (remove a raiz e faz o sift-down para reordenar):
class MinHeap:
def __init__(self):
self.heap = []
def __len__(self): # Tamanho do heap
return len(self.heap)
def __parent(self, i): # Índice do pai
return (i - 1) // 2
def __left(self, i): # Índice do filho esquerdo
return 2 * i + 1
def __right(self, i): # Índice do filho direito
return 2 * i + 2
def __swap(self, i, j): # Troca dois elementos
self.heap[i], self.heap[j] = self.heap[j], self.heap[i]
def __heapify_up(self, i): # Restaura a propriedade de min-heap após inserção
while i > 0 and self.heap[i] < self.heap[self.__parent(i)]:
self.__swap(i, self.__parent(i))
i = self.__parent(i)
def __heapify_down(self, i): # Restaura a propriedade de min-heap após extração
while True:
smallest = i
left = self.__left(i)
right = self.__right(i)
if left < len(self) and self.heap[left] < self.heap[smallest]:
smallest = left
if right < len(self) and self.heap[right] < self.heap[smallest]:
smallest = right
if smallest != i:
self.__swap(i, smallest)
i = smallest
else:
break
def insert(self, val): # Insere um valor no heap
self.heap.append(val)
self.__heapify_up(len(self) - 1)
def extract_min(self): # Extrai o menor valor do heap
if not self.heap:
return None
min_val = self.heap[0]
self.heap[0] = self.heap[-1]
self.heap.pop()
self.__heapify_down(0)
return min_valUma trie, também chamada de árvore de prefixos, é uma estrutura em árvore projetada para busca eficiente de strings e correspondência de prefixos.
Em uma trie, cada nó representa um caractere, e os caminhos da raiz até os nós formam strings completas. Tries são comuns em autocomplete, corretores ortográficos e implementação de dicionários.
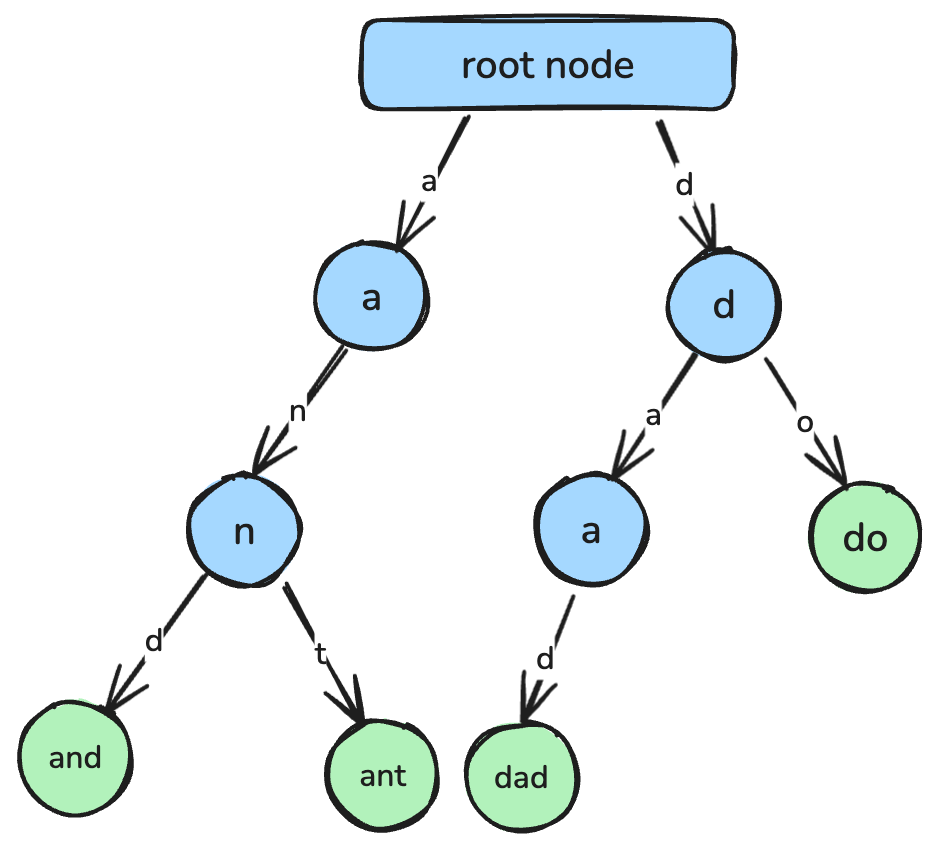
Uma trie, em que cada nó representa um caractere que se conecta para formar uma string. Imagem do autor.
Colisão ocorre quando duas chaves diferentes geram o mesmo índice.
Há vários métodos para resolver colisões, incluindo encadeamento (chaining), em que os elementos colidentes são armazenados em uma lista ligada no índice correspondente, e endereçamento aberto (open addressing), que busca o próximo espaço disponível por técnicas de sondagem como linear, quadrática ou double hashing.
Um grafo é uma estrutura composta por um conjunto de vértices (nós) interconectados por arestas. Ele é útil para representar relações e conexões entre entidades.
Depth-first search (DFS) explora um grafo/árvore mergulhando ao máximo em cada ramo antes de retroceder. Pode ser implementada com uma pilha explícita ou recursão. A complexidade é O(V + E), em que V é o número de vértices e E o de arestas.
Breadth-first search (BFS) explora sistematicamente todos os nós do nível atual antes de ir para o próximo. É eficaz para achar o caminho mais curto em grafos não ponderados e costuma ser implementada com uma fila. Assim como DFS, tem complexidade O(V + E).
Algoritmos de ordenação são fundamentais para processamento eficiente de dados — possibilitam buscas mais rápidas, melhor análise e visualização. Ao escolher, considere alguns trade-offs:
Veja implementações limpas em Python:
# Bubble sort — ordena in-place
def bubble_sort(arr):
n = len(arr)
for i in range(n):
for j in range(0, n - i - 1):
if arr[j] > arr[j + 1]:
arr[j], arr[j + 1] = arr[j + 1], arr[j]
# Quick sort — ordena in-place
def partition(arr, low, high):
pivot = arr[high]
i = low - 1
for j in range(low, high):
if arr[j] <= pivot:
i += 1
arr[i], arr[j] = arr[j], arr[i]
arr[i + 1], arr[high] = arr[high], arr[i + 1]
return i + 1
def quick_sort(arr, low, high):
if low < high:
pi = partition(arr, low, high)
quick_sort(arr, low, pi - 1)
quick_sort(arr, pi + 1, high)
# Merge sort — retorna uma nova lista ordenada
def merge(left, right):
result = []
i = j = 0
while i < len(left) and j < len(right):
if left[i] <= right[j]:
result.append(left[i])
i += 1
else:
result.append(right[j])
j += 1
result.extend(left[i:])
result.extend(right[j:])
return result
def merge_sort(arr):
if len(arr) <= 1:
return arr
mid = len(arr) // 2
left_half = merge_sort(arr[:mid])
right_half = merge_sort(arr[mid:])
return merge(left_half, right_half)nums = [3, 1, 4, 1, 5, 9, 2, 6]
bubble_sort(nums) # ordena nums in-place
quick_sort(nums, 0, len(nums) - 1) # também in-place
sorted_nums = merge_sort(nums) # retorna nova listaEm uma entrevista, o conteúdo acima é suficiente. Para se destacar, mencione que sorted() e list.sort() do Python usam o Timsort, um híbrido de merge sort e insertion sort. Por isso, quase nunca vale escrever um sort do zero em produção.
Há vários algoritmos para encontrar caminhos mínimos em grafos.
Para grafos não ponderados, a busca em largura explora os nós por camadas. Em grafos ponderados com arestas não negativas, o algoritmo de Dijkstra encontra o caminho mais curto examinando primeiro o vértice mais próximo.
O algoritmo A* melhora a eficiência usando heurísticas para estimar o custo restante. A escolha depende das características do grafo e dos requisitos do problema.
Agora, algumas perguntas avançadas para quem busca posições sênior ou quer demonstrar domínio de estruturas especializadas e complexas.
Programação dinâmica resolve problemas complexos dividindo-os em subproblemas menores e sobrepostos. Em vez de recalcular tudo do zero, guardamos soluções parciais para evitar trabalho repetido.
Ela é muito útil para encontrar a maior subsequência comum entre duas strings ou o custo mínimo para chegar a um ponto em uma grade.
B-trees são árvores balanceadas projetadas para acesso eficiente a disco. Algumas características:
Vantagens sobre árvores de busca binária:
Ordenação topológica organiza os vértices de um grafo acíclico direcionado (DAG) de forma que, se existir uma aresta do vértice u para o vértice v, então u aparece antes de v na ordem. É usada em agendamento de tarefas — definindo a ordem de execução respeitando dependências —, além de sistemas de build, gerenciadores de pacotes e planejamento de pré-requisitos de cursos.
Um min-heap é uma implementação específica de fila de prioridade e é uma árvore binária completa em que o valor de cada nó é menor ou igual ao de seus filhos, permitindo encontrar e extrair o mínimo com eficiência.
Já a fila de prioridade é uma estrutura abstrata que permite inserir elementos com uma prioridade associada, e a remoção ocorre em ordem de prioridade. Min-heaps são uma forma comum de implementá-la por gerenciarem essas operações com eficiência.
Um conjunto disjunto, também chamado de union-find, mantém uma coleção de conjuntos que não se intersectam. Essa estrutura dá suporte a duas operações principais:
Há muitas aplicações, com destaque para o algoritmo de Kruskal (encontrar a árvore geradora mínima) e o problema de fluxo em redes para determinar componentes conectados.
Segment tree é uma estrutura projetada para consultas e atualizações eficientes em intervalos de um array. É especialmente útil quando precisamos, repetidamente, somar, encontrar mínimo/máximo ou o MDC em um intervalo específico.
Ela é construída como uma árvore binária, em que cada nó representa um segmento do array. As folhas correspondem a elementos individuais; nós internos agregam valores dos filhos conforme a operação. Tanto atualizações quanto consultas alcançam O(log n).
Uma árvore de sufixos armazena todos os sufixos de uma string para responder a consultas de padrão em tempo proporcional ao tamanho do padrão, não do texto. Uma árvore verdadeira usa compressão de arestas para obter O(n) de espaço e geralmente é construída com o algoritmo de Ukkonen — complexo demais para implementar do zero em uma entrevista curta.
Um meio-termo comum é a trie de sufixos, que armazena um caractere por nó. Usa O(n²) de espaço, mas é bem mais simples de escrever e explicar. Em entrevista, vale explicitar esse trade-off.
Aqui vai uma implementação limpa em Python:
class SuffixTrieNode:
def __init__(self):
self.children = {} # Mapa caractere -> nó filho
self.indices = [] # Posições iniciais dos sufixos que passam por este nó
class SuffixTrie:
def __init__(self, text):
self.root = SuffixTrieNode()
self.text = text + "$" # Anexa um terminador único
self._build()
def _build(self):
"""Insere todos os sufixos do texto na trie."""
for i in range(len(self.text)):
self._insert_suffix(i)
def _insert_suffix(self, index):
node = self.root
for i in range(index, len(self.text)):
c = self.text[i]
if c not in node.children:
node.children[c] = SuffixTrieNode()
node = node.children[c]
node.indices.append(index)
def search(self, pattern):
"""Retorna todas as posições iniciais onde `pattern` aparece no texto."""
node = self.root
for c in pattern:
if c not in node.children:
return []
node = node.children[c]
return node.indicesQuadtrees são estruturas hierárquicas que subdividem recursivamente um espaço 2D em quatro quadrantes iguais. Essa técnica de particionamento espacial é muito eficaz em processamento de imagens, detecção de colisão em jogos e sistemas de informações geográficas para armazenamento e consulta espacial eficientes.
Mostrar que você conhece as estruturas de dados é importante, mas saber quando usá-las do jeito certo faz você se destacar na entrevista. Nesta seção, veremos como aplicar esse conhecimento em situações práticas.
Por ser um problema em tempo real, você vai precisar de estruturas eficientes.
Eu usaria quadtrees para dados geográficos, filas de prioridade para ranquear os matches por distância e urgência, e tabelas hash para buscas rápidas das localizações de motoristas e passageiros.
Podemos combinar várias estruturas para recomendar produtos de forma eficaz.
Uma matriz esparsa usuário–item armazena interações; tabelas hash mapeiam usuários e itens com eficiência; filas de prioridade ranqueiam recomendações; e grafos modelam relações usuário–item para análises mais sofisticadas, como detecção de comunidades.
Um grafo é muito eficaz para detectar e remover spam. Representando usuários como nós e conexões como arestas, é possível analisar a topologia: clusters muito densos, nós isolados e picos súbitos de atividade ajudam a sinalizar contas suspeitas.
Eu usaria uma combinação de estruturas.
Tabelas hash para mapear IDs de usuários às suas conexões, permitindo lookups rápidos. Filas para cada usuário, mantendo a ordem das mensagens. Além disso, árvores (como AVL) para armazenar e consultar status online/offline com atualizações em tempo real.
Para um corretor, a busca eficiente é crucial. A trie é ideal: cada nó representa uma letra e os caminhos formam palavras. Isso permite buscas rápidas por prefixo e sugestões ágeis para correções.
Nesse cenário, segment trees se destacam. Elas lidam muito bem com consultas por intervalo e atualizações. Podemos representar o mapa do jogo como um array 1D, em que cada posição é uma célula da grade que indica presença ou ausência de uma estrutura.
Eu sei que se preparar para esse tipo de entrevista pode ser desafiador, mas uma abordagem estruturada deixa tudo mais leve!
Foque em dominar os conceitos fundamentais: arrays, listas ligadas, pilhas, filas, árvores, grafos e tabelas hash. Entenda seus princípios, como gerenciam dados e as complexidades de tempo de operações como inserção, remoção e busca.
Conhecer os conceitos é ótimo, mas não basta. Você deve saber implementar essas estruturas do zero. Para isso, aproveite os cursos da DataCamp e os desafios de código que vão afiar sua resolução de problemas.
Entender os trade-offs é chave. Por exemplo, arrays oferecem acesso rápido, mas inserções e exclusões podem ser custosas; listas ligadas facilitam modificações, mas exigem percursos para acesso. Esteja pronto para discutir essas trocas na entrevista.
Lembre-se: comunicação é tão importante quanto código. Entrevistadores buscam quem adapta a explicação ao público. Como discutido no podcast DataFramed sobre o futuro das carreiras em dados:
Você precisa ser capaz de entregar qualquer insight de um jeito que uma criança de seis anos entenda e também de um jeito que satisfaça a mim ou alguém ainda mais técnico. Se você realmente domina o assunto, consegue simplificar bastante, mas também tornar tão complexo que, honestamente, só quem está lá no topo em expertise técnica vai acompanhar.
Mo Chen, Data & Analytics Manager at NatWest Group
Melhore sua carreira como cientista de dados profissional.

Aprofunde-se em estruturas de dados e nos fundamentos de Python com estes cursos!
Curso
Curso
Curso
blog
Tim Lu
9 min
blog
Srujana Maddula
15 min
blog
Austin Chia
15 min
Tutorial
Sejal Jaiswal