course
Python średnio zaawansowany
4 godz.
1.4M
Aby pokazać, że rozumiesz podstawowe struktury danych, musisz pewnie znać kluczowe struktury i ich implementacje. Poniższe pytania sprawdzą twoją umiejętność wyjaśniania tych idei i pokażą twoją wiedzę.
Struktury danych klasyfikujemy następująco:
Tablice i listy połączone to dwa sposoby przechowywania grup elementów, ale działają inaczej. Oto główne różnice:
Stos to uporządkowana lista, do której dodajesz i z której usuwasz elementy na jednym końcu, zwanym wierzchołkiem. Obowiązuje zasada LIFO (last in, first out): ostatnio dodany element jest usuwany jako pierwszy.
Stosy znajdują zastosowanie m.in. w obliczaniu wyrażeń, backtrackingu, zarządzaniu pamięcią oraz wywołaniach i powrotach funkcji.
W Pythonie lista działa jako stos od razu: append() to push, a pop() usuwa element z wierzchu.
my_stack = []
item = 1
my_stack.append(item)
my_stack.pop()Śledząc pozycję wierzchołka za pomocą indeksu, możesz sprawić, że te operacje będą szybkie i wydajne.
Kolejka to struktura FIFO (first in, first out) — jak kolejka w sklepie, gdzie ludzie wchodzą na koniec i wychodzą z przodu.
W Pythonie możesz zaimplementować kolejkę na różne sposoby:
Za pomocą tablicy lub listy, korzystając z metod append() i pop():
my_queue = []
item = 1
# Enqueue
my_queue.append(item)
# Dequeue
my_queue.pop(0)Używając deque() z biblioteki collections, która wykonuje append() i pop() szybciej niż listy:
from collections import deque
my_queue = deque()
item = 1
# Enqueue
my_queue.append(item)
# Dequeue
my_queue.popleft()Używając wbudowanego modułu queue.Queue:
from queue import Queue
my_queue = Queue(maxsize = 3)
# Enqueue
my_queue.put(item)
# Dequeue
my_queue.get()Drzewo binarne to struktura danych, w której każdy węzeł ma co najwyżej dwoje dzieci: lewe i prawe. Natomiast drzewo wyszukiwań binarnych (BST) to szczególny typ drzewa binarnego o określonych właściwościach porządku: Dla każdego węzła wszystkie klucze w lewym poddrzewie są mniejsze, wszystkie w prawym — większe, a oba poddrzewa same są BST.
Te właściwości umożliwiają wydajne operacje, takie jak wyszukiwanie, wstawianie i usuwanie — zwykle o złożoności O(log n) w drzewach zrównoważonych.
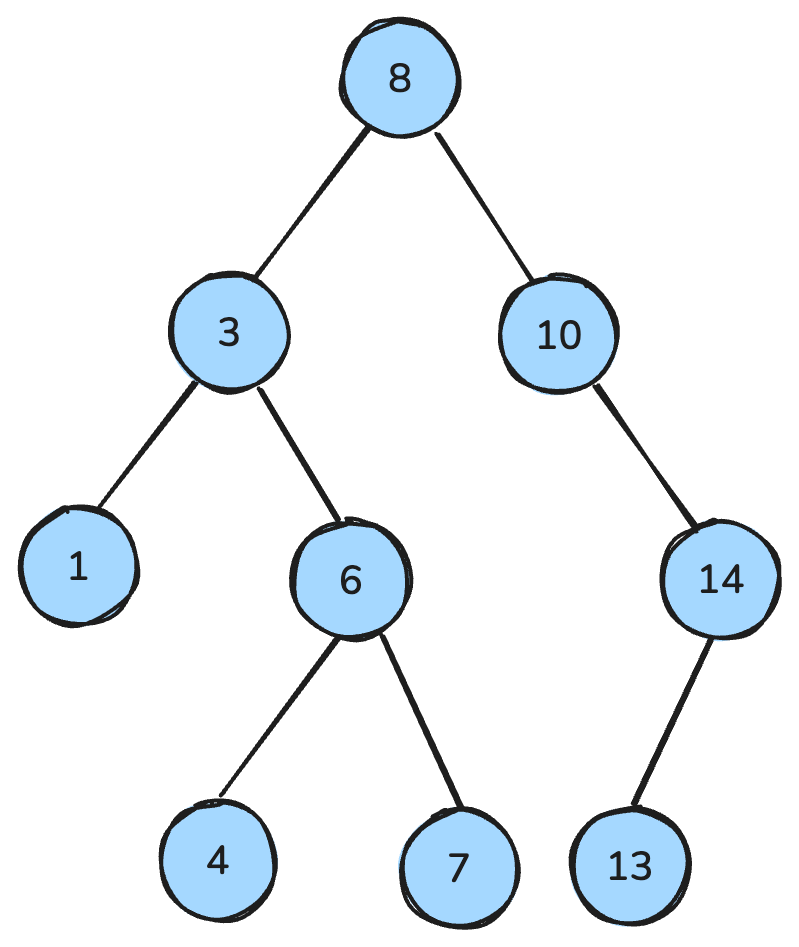
Drzewo BST. Ilustracja autora.
Haszowanie to technika, która przekształca dane o dowolnym rozmiarze w wartość o stałej długości, zwaną wartością skrótu (hash), używając funkcji skrótu.
Częstym zastosowaniem haszowania są tablice haszujące, gdzie pomaga ono przyporządkować klucze do konkretnych lokalizacji w tablicy, co umożliwia szybkie znajdowanie i pobieranie danych. Haszowanie ma wiele zastosowań — od zabezpieczania haseł w kryptografii po porządkowanie danych poprzez deduplikację.
Kopiec to struktura przypominająca drzewo, która spełnia określone reguły.
W kopcu maksymalnym każdy rodzic jest większy lub równy swoim dzieciom; w kopcu minimalnym — mniejszy lub równy dzieciom.
Kopce często służą do tworzenia kolejek priorytetowych, które sortują elementy na podstawie ważności lub wartości. Są też ważne przy sortowaniu przez kopcowanie — metodzie efektywnego porządkowania danych.
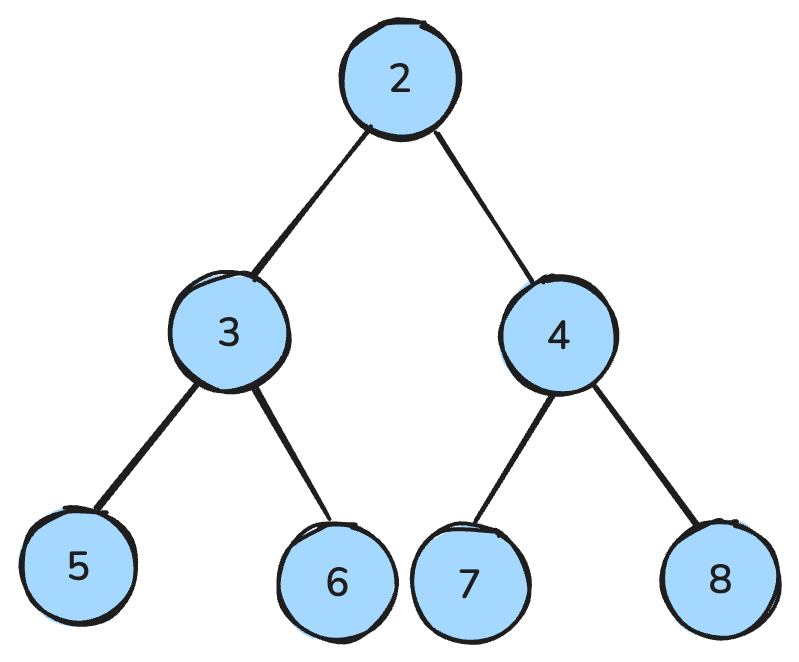
Kopiec minimalny to struktura, w której wszyscy rodzice są mniejsi od dzieci — ilustracja autora.
Skoro omówiliśmy podstawy, przejdźmy do pytań na poziomie średnio zaawansowanym, które sprawdzą twoje umiejętności implementacji i wykorzystania tych fundamentalnych koncepcji.
Zrównoważone drzewo BST utrzymuje zbliżone wysokości lewego i prawego poddrzewa. Równoważenie BST jest bardzo ważne, by zachować wydajne operacje wyszukiwania, wstawiania i usuwania.
Techniki takie jak drzewa AVL i drzewa czerwono-czarne są powszechnie używane do samoczynnego równoważenia. Drzewa AVL utrzymują różnicę wysokości między lewym a prawym poddrzewem każdego węzła nie większą niż 1, podczas gdy drzewa czerwono-czarne mają równie restrykcyjne reguły równowagi.
Kopiec minimalny zwykle opiera się na liście. Dwie kluczowe operacje to insert (dodaje element i przepycha go w górę, by przywrócić własność kopca) oraz extract_min (usuwa korzeń i przepycha w dół, by przywrócić porządek):
class MinHeap:
def __init__(self):
self.heap = []
def __len__(self): # Get the size of the heap
return len(self.heap)
def __parent(self, i): # Get the parent index
return (i - 1) // 2
def __left(self, i): # Get the left child index
return 2 * i + 1
def __right(self, i): # Get the right child index
return 2 * i + 2
def __swap(self, i, j): # Swap two elements
self.heap[i], self.heap[j] = self.heap[j], self.heap[i]
def __heapify_up(self, i): # Restore min-heap property after insertion
while i > 0 and self.heap[i] < self.heap[self.__parent(i)]:
self.__swap(i, self.__parent(i))
i = self.__parent(i)
def __heapify_down(self, i): # Restore min-heap property after extraction
while True:
smallest = i
left = self.__left(i)
right = self.__right(i)
if left < len(self) and self.heap[left] < self.heap[smallest]:
smallest = left
if right < len(self) and self.heap[right] < self.heap[smallest]:
smallest = right
if smallest != i:
self.__swap(i, smallest)
i = smallest
else:
break
def insert(self, val): # Insert a value into the heap
self.heap.append(val)
self.__heapify_up(len(self) - 1)
def extract_min(self): # Extract the minimum value from the heap
if not self.heap:
return None
min_val = self.heap[0]
self.heap[0] = self.heap[-1]
self.heap.pop()
self.__heapify_down(0)
return min_valTrie, znane też jako drzewo prefiksów, to struktura oparta na drzewie zaprojektowana do wydajnego wyszukiwania łańcuchów i dopasowywania prefiksów.
W trie każdy węzeł reprezentuje pojedynczy znak, a ścieżki od korzenia do węzłów odpowiadają kompletnym łańcuchom. Trie są powszechnie używane w takich zastosowaniach jak autouzupełnianie, narzędzia do sprawdzania pisowni oraz implementacja słowników.
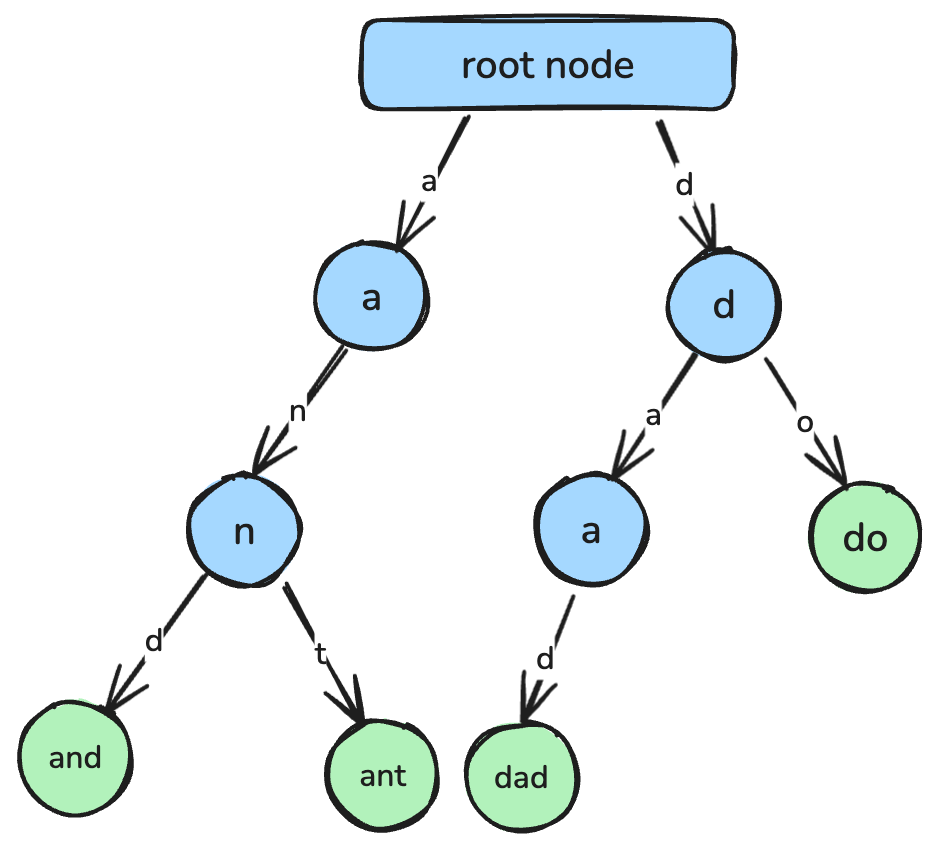
Trie, gdzie każdy węzeł reprezentuje pojedynczy znak łączący się w łańcuch. Ilustracja autora.
Kolizja występuje, gdy dwa różne klucze haszują się do tego samego indeksu.
Istnieje kilka metod rozwiązywania kolizji, w tym łańcuchowanie (chaining), gdzie kolidujące elementy są przechowywane w liście połączonej pod danym indeksem, oraz adresowanie otwarte (open addressing), które polega na znajdowaniu kolejnego wolnego miejsca poprzez sondowanie liniowe, kwadratowe lub podwójne haszowanie.
Graf to struktura danych składająca się ze zbioru wierzchołków (węzłów) połączonych krawędziami. Struktura ta dobrze obrazuje relacje i połączenia między różnymi bytami.
Przeszukiwanie w głąb (DFS) to algorytm, który eksploruje graf lub drzewo, schodząc maksymalnie w głąb każdej gałęzi, zanim się cofnie. Można je zaimplementować za pomocą jawnego stosu lub rekurencji. Złożoność czasowa to O(V + E), gdzie V to liczba wierzchołków, a E — liczba krawędzi, co oznacza, że może zajść potrzeba zbadania wszystkich wierzchołków i krawędzi.
Przeszukiwanie wszerz (BFS) systematycznie eksploruje wszystkie węzły na bieżącym poziomie głębokości, zanim przejdzie do następnego. Jest skuteczne w znajdowaniu najkrótszej ścieżki w grafach nieważonych i zazwyczaj wykorzystuje kolejkę. Podobnie jak DFS, BFS ma złożoność O(V + E), wymagając przejrzenia wszystkich wierzchołków i krawędzi.
Algorytmy sortowania są kluczowe dla wydajnego przetwarzania danych — umożliwiają szybsze wyszukiwanie, lepszą analizę i łatwiejszą wizualizację. Wybierając między nimi, warto pamiętać o kilku kompromisach:
Oto przejrzyste implementacje w Pythonie:
# Bubble sort — sorts in place
def bubble_sort(arr):
n = len(arr)
for i in range(n):
for j in range(0, n - i - 1):
if arr[j] > arr[j + 1]:
arr[j], arr[j + 1] = arr[j + 1], arr[j]
# Quick sort — sorts in place
def partition(arr, low, high):
pivot = arr[high]
i = low - 1
for j in range(low, high):
if arr[j] <= pivot:
i += 1
arr[i], arr[j] = arr[j], arr[i]
arr[i + 1], arr[high] = arr[high], arr[i + 1]
return i + 1
def quick_sort(arr, low, high):
if low < high:
pi = partition(arr, low, high)
quick_sort(arr, low, pi - 1)
quick_sort(arr, pi + 1, high)
# Merge sort — returns a new sorted list
def merge(left, right):
result = []
i = j = 0
while i < len(left) and j < len(right):
if left[i] <= right[j]:
result.append(left[i])
i += 1
else:
result.append[right[j]]
j += 1
result.extend(left[i:])
result.extend(right[j:])
return result
def merge_sort(arr):
if len(arr) <= 1:
return arr
mid = len(arr) // 2
left_half = merge_sort(arr[:mid])
right_half = merge_sort(arr[mid:])
return merge(left_half, right_half)nums = [3, 1, 4, 1, 5, 9, 2, 6]
bubble_sort(nums) # sorts nums in place
quick_sort(nums, 0, len(nums) - 1) # also in place
sorted_nums = merge_sort(nums) # returns a new listNa rozmowie powyższa odpowiedź zwykle wystarczy. Jeśli jednak chcesz się wyróżnić, wspomnij, że wbudowane w Pythona sorted() i list.sort() używają Timsorta, hybrydy merge sorta i insertion sorta. Dlatego w produkcyjnym Pythonie prawie nigdy nie piszesz sortowania od zera.
Do znajdowania najkrótszej ścieżki w grafach można użyć kilku algorytmów.
W grafach nieważonych BFS skutecznie eksploruje węzły warstwa po warstwie. W grafach ważonych z nieujemnymi krawędziami algorytm Dijkstry wyznacza najkrótszą ścieżkę, badając najpierw najbliższy wierzchołek.
Algorytm A* poprawia wydajność, używając heurystyk do oszacowania pozostałego kosztu. Wybór algorytmu zależy od charakterystyki grafu i wymagań problemu.
Przyjrzyjmy się teraz pytaniom dla kandydatów na stanowiska seniorskie lub tych, którzy chcą pokazać głęboką wiedzę o specjalistycznych, złożonych strukturach danych.
Programowanie dynamiczne to metoda rozwiązywania złożonych problemów poprzez podział na mniejsze, nakładające się podproblemy. Zamiast zaczynać od zera za każdym razem, zapamiętujesz rozwiązania tych mniejszych części, dzięki czemu nie powtarzasz obliczeń.
Metoda ta świetnie sprawdza się m.in. przy znajdowaniu najdłuższej wspólnej podsekwencji dwóch łańcuchów czy minimalnego kosztu dotarcia do konkretnego punktu na siatce.
Drzewa B to zrównoważone struktury drzew przeznaczone do wydajnego dostępu do dysku. Oto ich cechy:
Dają kilka przewag nad drzewami BST:
Sortowanie topologiczne to algorytm porządkujący wierzchołki skierowanego acyklicznego grafu (DAG) tak, aby jeśli istnieje krawędź z wierzchołka u do wierzchołka v, to u występuje przed v w uporządkowaniu. Jest powszechnie używane do harmonogramowania zadań — ustalania kolejności ich uruchomienia z uwzględnieniem zależności — a także w systemach budowania, menedżerach pakietów i planowaniu przedmiotów z warunkami wstępnymi.
Kopiec minimalny to konkretna implementacja kolejki priorytetowej i jest zdefiniowany jako pełne drzewo binarne, w którym wartość każdego węzła jest mniejsza lub równa wartości jego dzieci, co umożliwia wydajne znajdowanie i usuwanie elementu minimalnego.
Z kolei kolejka priorytetowa to abstrakcyjna struktura danych, która pozwala wstawiać elementy z przypisanym priorytetem, a elementy są zdejmowane w kolejności priorytetów. Kopce minimalne są popularnym sposobem implementacji kolejek priorytetowych dzięki wydajnemu zarządzaniu tymi operacjami.
Struktura zbiorów rozłącznych, znana też jako union-find, utrzymuje kolekcję rozłącznych zbiorów. Wspiera dwa podstawowe działania:
Struktury zbiorów rozłącznych mają wiele zastosowań, z których najczęstsze to algorytm Kruskala do wyznaczania minimalnego drzewa rozpinającego oraz problem przepływu w sieci do określania spójnych składowych grafu.
Drzewo przedziałowe to struktura zaprojektowana do wydajnego wykonywania zapytań i aktualizacji na zakresach w tablicy. Szczególnie przydaje się, gdy wielokrotnie trzeba obliczać sumę, minimum, maksimum lub NWD na określonym zakresie elementów.
Buduje się je jako drzewo binarne, gdzie każdy węzeł reprezentuje segment tablicy. Liście odpowiadają pojedynczym elementom, a węzły wewnętrzne przechowują informacje agregujące wartości dzieci zgodnie z wykonywaną operacją. Uzyskujemy O(log n) zarówno dla aktualizacji, jak i zapytań.
Drzewo sufiksowe przechowuje wszystkie sufiksy łańcucha, dzięki czemu zapytania o wzorce można obsłużyć w czasie proporcjonalnym do długości wzorca, a nie tekstu. Prawdziwe drzewo sufiksowe używa kompresji krawędzi, osiągając pamięć O(n), i zwykle buduje się je algorytmem Ukkonena — ale to na tyle złożone, że rekruterzy rzadko oczekują implementacji od zera w 45 minut.
Popularnym kompromisem jest prostsze trie sufiksów, które przechowuje jeden znak na węzeł. Zużywa O(n²) pamięci, ale jest dużo łatwiejsze do napisania i wytłumaczenia. Sztuka na rozmowie polega na tym, by znać ten trade-off i jasno go zakomunikować.
Oto przejrzysta implementacja w Pythonie:
class SuffixTrieNode:
def __init__(self):
self.children = {} # Map of character -> child node
self.indices = [] # Starting positions of suffixes passing through this node
class SuffixTrie:
def __init__(self, text):
self.root = SuffixTrieNode()
self.text = text + "$" # Append a unique terminator
self._build()
def _build(self):
"""Insert every suffix of the text into the trie."""
for i in range(len(self.text)):
self._insert_suffix(i)
def _insert_suffix(self, index):
node = self.root
for i in range(index, len(self.text)):
c = self.text[i]
if c not in node.children:
node.children[c] = SuffixTrieNode()
node = node.children[c]
node.indices.append(index)
def search(self, pattern):
"""Return all starting positions where `pattern` appears in the text."""
node = self.root
for c in pattern:
if c not in node.children:
return []
node = node.children[c]
return node.indicesQuadtree to hierarchiczna struktura drzewa, która rekurencyjnie dzieli przestrzeń dwuwymiarową na cztery równe ćwiartki. Ta technika partycjonowania przestrzeni świetnie sprawdza się w przetwarzaniu obrazów, wykrywaniu kolizji w grach oraz w systemach informacji geograficznej do wydajnego przechowywania i wyszukiwania danych przestrzennych.
Znajomość struktur danych jest ważna, ale to umiejętność właściwego ich zastosowania wyróżni cię na rozmowie. W tej sekcji przejrzymy, jak przekuć wiedzę o strukturach w praktyczne rozwiązania.
Ze względu na działanie w czasie rzeczywistym potrzebne będą wydajne struktury danych.
Z mojego doświadczenia użyłbym quadtree do danych geograficznych, kolejek priorytetowych do rangowania dopasowań na podstawie dystansu i pilności, oraz tablic haszujących do szybkiego wyszukiwania lokalizacji kierowców i pasażerów.
Możemy wykorzystać kombinację struktur danych, aby skutecznie rekomendować produkty na podstawie zachowań użytkowników.
Rzadka macierz użytkownik–produkt przechowa interakcje, tablice haszujące posłużą do efektywnego mapowania użytkowników i produktów, kolejki priorytetowe uporządkują rekomendacje, a grafy odwzorują relacje użytkownik–produkt do bardziej zaawansowanych analiz, jak wykrywanie społeczności.
Graf może być bardzo skuteczny w wykrywaniu i usuwaniu kont spamerskich. Reprezentując użytkowników jako węzły, a ich połączenia jako krawędzie, możesz analizować topologię sieci. Identyfikacja gęsto połączonych klastrów, izolowanych węzłów i nagłych skoków aktywności pomaga oznaczać podejrzane konta.
Użyłbym kombinacji struktur danych w aplikacji czatu w czasie rzeczywistym.
Tablice haszujące przechowywałyby identyfikatory użytkowników i ich listy połączeń, umożliwiając szybkie wyszukiwanie adresatów. Kolejki dla każdego użytkownika utrzymywałyby kolejność wiadomości, zapewniając dostarczanie w tej samej sekwencji. Dodatkowo drzewa, np. AVL, mogłyby służyć do wydajnego przechowywania i pobierania statusu online/offline, zapewniając aktualizacje w czasie rzeczywistym.
Dla sprawdzania pisowni kluczowy jest szybki dostęp do słów. Trie będzie idealną strukturą. Każdy węzeł trie reprezentuje literę, a ścieżki tworzą słowa. To umożliwia szybkie wyszukiwanie po prefiksach i sprawne podpowiadanie korekt błędnych słów.
W tym scenariuszu świetnie sprawdzą się drzewa przedziałowe. Doskonale radzą sobie z zapytaniami zakresowymi i aktualizacjami. Mapę gry możemy reprezentować jako tablicę 1D, gdzie każdy element odpowiada komórce siatki. Każda komórka może przechowywać informację o obecności lub braku struktury.
Wiem, że przygotowania do rozmowy o strukturach danych mogą być wymagające, ale uporządkowane podejście bardzo w tym pomaga!
Skup się na opanowaniu podstawowych koncepcji: tablic, list połączonych, stosów, kolejek, drzew, grafów i tablic haszujących. Zrozum ich zasady, sposób zarządzania danymi i złożoności czasowe operacji takich jak wstawianie, usuwanie i wyszukiwanie.
Sama teoria to za mało. Powinieneś/powinnaś umieć zaimplementować te struktury od zera. Możesz skorzystać z kursów DataCamp, aby wykorzystać wyzwania programistyczne, które wyostrzą twoje umiejętności rozwiązywania problemów.
Zrozumienie kompromisów między strukturami danych jest kluczowe. Na przykład tablice zapewniają szybki dostęp, ale wstawianie i usuwanie bywa kosztowne, podczas gdy listy połączone ułatwiają modyfikacje, lecz wymagają przechodzenia dla dostępu. Przygotuj się do omówienia tych kompromisów.
Pamiętaj, że komunikacja jest równie ważna co kod. Rekruterzy szukają osób, które potrafią dostosować wyjaśnienia do odbiorcy. Jak omawiano w podcaście DataFramed o przyszłości ról data:
Musisz umieć przekazać dowolny wgląd tak, by zrozumiało to sześcioletnie dziecko, ale też w sposób satysfakcjonujący dla mnie czy nawet kogoś jeszcze bardziej technicznego. Jeśli naprawdę znasz temat, potrafisz go maksymalnie uprościć, ale też tak skomplikować, że szczerze — zrozumieją go tylko osoby na najwyższym poziomie ekspertyzy technicznej.
Mo Chen, Data & Analytics Manager at NatWest Group
Poznaj lepiej struktury danych i podstawy Pythona dzięki tym kursom!
course
course
course