
Curso
Python intermedio
4 h
1.4M
Para demostrar que dominas las estructuras de datos básicas, necesitas seguridad en las estructuras clave y sus implementaciones. Preguntas como las siguientes pondrán a prueba tu capacidad para explicarlas y evidenciar tu conocimiento.
Las estructuras de datos se clasifican así:
Los arrays y las listas enlazadas son dos formas de almacenar conjuntos de elementos, pero funcionan distinto. Estas son las diferencias clave:
Una pila es una lista ordenada en la que añades y quitas elementos por un único extremo, llamado cima. Sigue el principio LIFO (último en entrar, primero en salir): el elemento más reciente es el primero en eliminarse.
Las pilas se usan en evaluación de expresiones, backtracking, gestión de memoria y llamadas y retornos de funciones.
En Python, una lista funciona como pila directamente: append() es push y pop() elimina el elemento superior.
my_stack = []
item = 1
my_stack.append(item)
my_stack.pop()Llevando el control del índice de la cima, estas operaciones son rápidas y eficientes.
Una cola es una estructura FIFO (primero en entrar, primero en salir), como la cola de una tienda: se entra por detrás y se sale por delante.
En Python, puedes implementarla de varias formas:
Usando una lista y los métodos append() y pop():
my_queue = []
item = 1
# Encolar
my_queue.append(item)
# Desencolar
my_queue.pop(0)Usando deque() de la librería collections, que hace append() y pop() más rápido que las listas:
from collections import deque
my_queue = deque()
item = 1
# Encolar
my_queue.append(item)
# Desencolar
my_queue.popleft()Usando el módulo integrado queue.Queue:
from queue import Queue
my_queue = Queue(maxsize = 3)
# Encolar
my_queue.put(item)
# Desencolar
my_queue.get()Un árbol binario es una estructura de datos donde cada nodo tiene como mucho dos hijos: izquierdo y derecho. Un árbol de búsqueda binaria (BST) es un tipo específico de árbol binario con propiedades de orden: para cada nodo, todas las claves del subárbol izquierdo son menores, todas las del derecho son mayores, y ambos subárboles son a su vez BST.
Estas propiedades permiten operaciones eficientes como búsqueda, inserción y borrado, con una complejidad temporal típica de O(log n) en árboles balanceados.
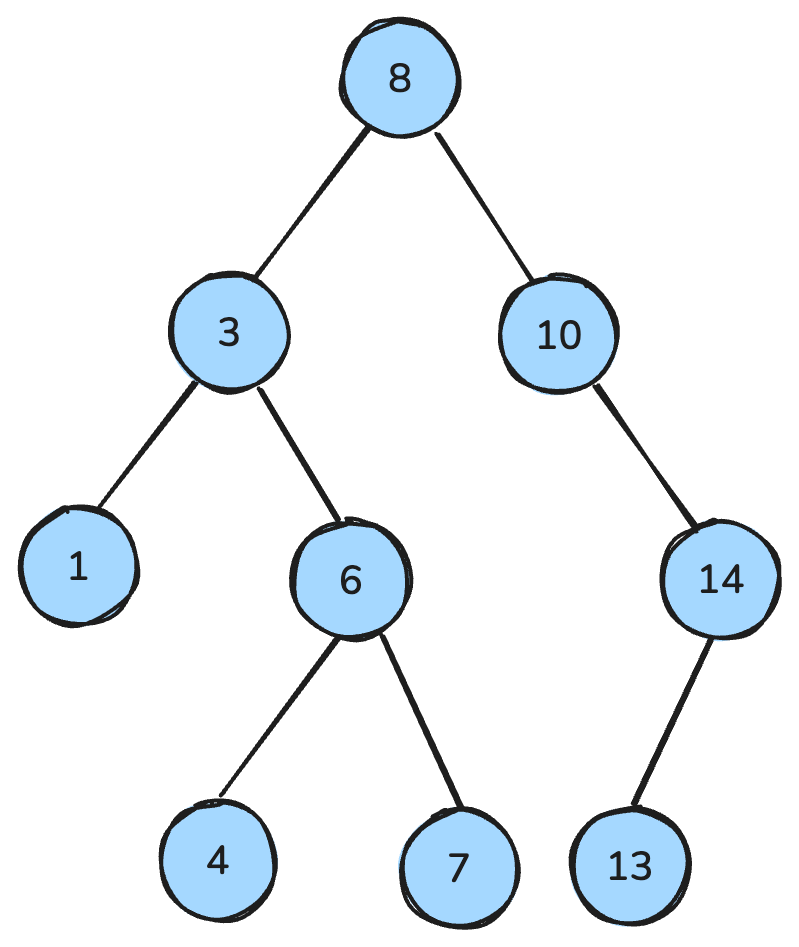
Árbol de búsqueda binaria. Imagen del autor.
El hashing es una técnica que toma datos de cualquier tamaño y los transforma en un valor de tamaño fijo llamado valor hash mediante una función hash.
Un uso común son las tablas hash, donde ayuda a asignar claves a posiciones concretas de un array, facilitando encontrar y recuperar datos rápidamente. También se aplica en criptografía para proteger contraseñas y en deduplicación para mantener los datos organizados.
Un heap es una estructura con forma de árbol que cumple reglas especiales.
En un max-heap, cada padre es mayor o igual que sus hijos; en un min-heap, cada padre es menor o igual que sus hijos.
Los heaps se usan a menudo para crear colas de prioridad, que ordenan elementos según su importancia o valor. También son clave en el heap sort, un método eficiente de ordenación.
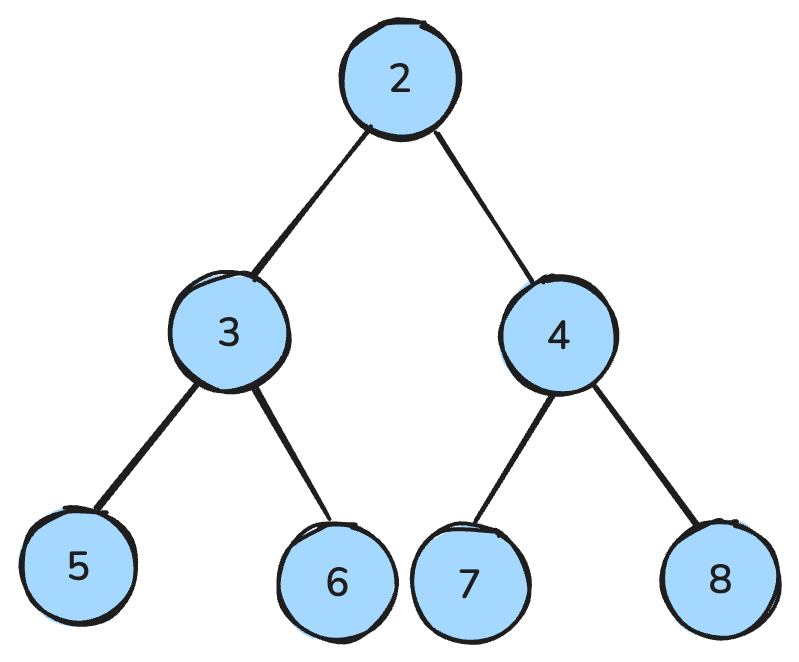
Un min-heap es aquel en el que todos los padres son menores que los hijos. Imagen del autor.
Tras cubrir lo básico, pasemos a preguntas de nivel intermedio que exploran tu pericia técnica implementando y usando estos conceptos fundamentales.
Un árbol de búsqueda binaria balanceado mantiene una altura relativamente similar entre sus subárboles izquierdo y derecho. Equilibrarlo es crucial para conservar operaciones eficientes de búsqueda, inserción y borrado.
Técnicas como los árboles AVL y los árboles rojo-negro se emplean para el autoequilibrado. Los AVL limitan la diferencia de altura entre subárboles a 1, mientras que los rojo-negro aplican restricciones de balance más estrictas.
Un min-heap suele respaldarse con una lista. Las dos operaciones clave son insert (añade un elemento y lo hace subir para restaurar la propiedad de heap) y extract_min (elimina la raíz y hace bajar para reordenar):
class MinHeap:
def __init__(self):
self.heap = []
def __len__(self): # Tamaño del heap
return len(self.heap)
def __parent(self, i): # Índice del padre
return (i - 1) // 2
def __left(self, i): # Índice del hijo izquierdo
return 2 * i + 1
def __right(self, i): # Índice del hijo derecho
return 2 * i + 2
def __swap(self, i, j): # Intercambiar dos elementos
self.heap[i], self.heap[j] = self.heap[j], self.heap[i]
def __heapify_up(self, i): # Restaurar la propiedad tras insertar
while i > 0 and self.heap[i] < self.heap[self.__parent(i)]:
self.__swap(i, self.__parent(i))
i = self.__parent(i)
def __heapify_down(self, i): # Restaurar la propiedad tras extraer
while True:
smallest = i
left = self.__left(i)
right = self.__right(i)
if left < len(self) and self.heap[left] < self.heap[smallest]:
smallest = left
if right < len(self) and self.heap[right] < self.heap[smallest]:
smallest = right
if smallest != i:
self.__swap(i, smallest)
i = smallest
else:
break
def insert(self, val): # Insertar un valor
self.heap.append(val)
self.__heapify_up(len(self) - 1)
def extract_min(self): # Extraer el mínimo
if not self.heap:
return None
min_val = self.heap[0]
self.heap[0] = self.heap[-1]
self.heap.pop()
self.__heapify_down(0)
return min_valUn trie, también llamado árbol de prefijos, es una estructura en árbol diseñada para recuperar cadenas y hacer coincidencias por prefijo de forma eficiente.
En un trie, cada nodo representa un carácter y los caminos desde la raíz corresponden a cadenas completas. Se usa en autocompletado, correctores ortográficos y en la implementación de diccionarios.
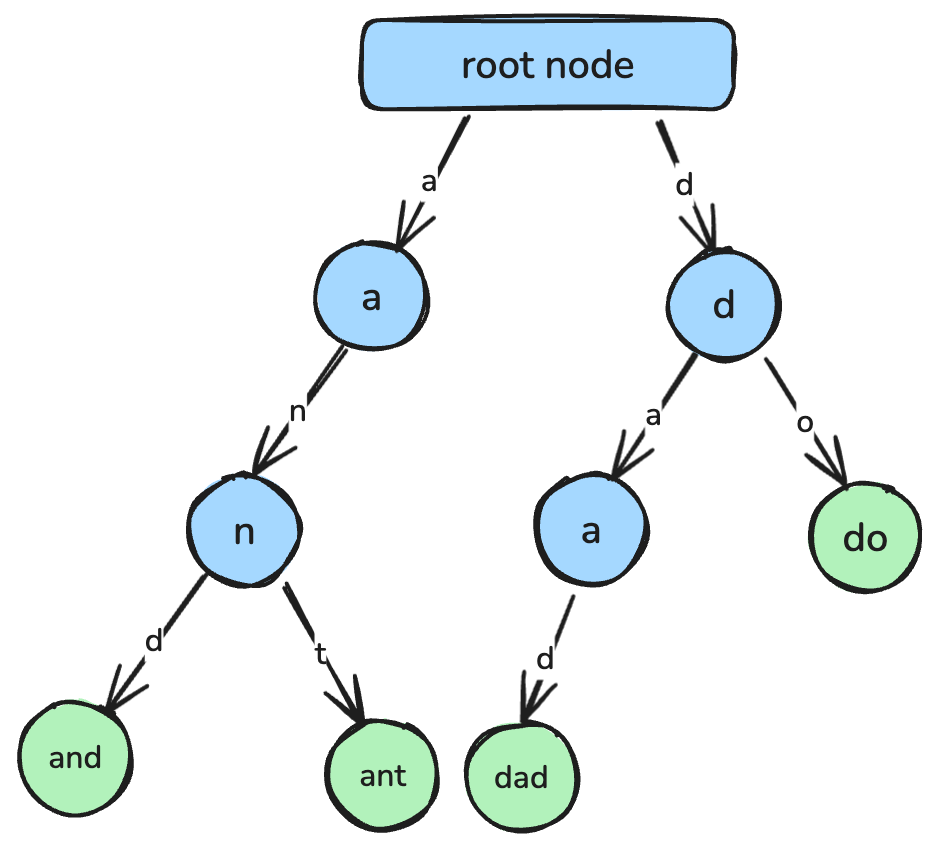
Un trie, donde cada nodo representa un carácter que se conecta para formar una cadena. Imagen del autor.
Una colisión ocurre cuando dos claves distintas hashéan al mismo índice.
Hay varios métodos para resolver colisiones: el encadenamiento, donde los elementos colisionados se guardan en una lista enlazada en ese índice, y la direccionamiento abierto, que busca el siguiente hueco libre mediante técnicas como sondeo lineal, cuadrático o doble hashing.
Un grafo es una estructura formada por vértices (nodos) conectados por aristas. Es muy útil para representar relaciones y conexiones entre entidades.
Depth-first search (DFS) explora un grafo o árbol profundizando en cada rama antes de retroceder. Puede implementarse con una pila explícita o con recursión. Su complejidad es O(V + E), donde V es el número de vértices y E el de aristas, lo que implica que puede examinar todos los elementos.
Breadth-first search (BFS) recorre sistemáticamente todos los nodos del nivel actual antes de pasar al siguiente. Es eficaz para encontrar caminos más cortos en grafos no ponderados y suele implementarse con una cola. Como DFS, su complejidad es O(V + E).
Los algoritmos de ordenación son esenciales para procesar datos con eficiencia: permiten búsquedas rápidas, mejor análisis y visualizaciones más claras. Al elegir entre ellos, ten en cuenta estos compromisos clave:
Aquí tienes implementaciones limpias en Python:
# Bubble sort — ordena in situ
def bubble_sort(arr):
n = len(arr)
for i in range(n):
for j in range(0, n - i - 1):
if arr[j] > arr[j + 1]:
arr[j], arr[j + 1] = arr[j + 1], arr[j]
# Quick sort — ordena in situ
def partition(arr, low, high):
pivot = arr[high]
i = low - 1
for j in range(low, high):
if arr[j] <= pivot:
i += 1
arr[i], arr[j] = arr[j], arr[i]
arr[i + 1], arr[high] = arr[high], arr[i + 1]
return i + 1
def quick_sort(arr, low, high):
if low < high:
pi = partition(arr, low, high)
quick_sort(arr, low, pi - 1)
quick_sort(arr, pi + 1, high)
# Merge sort — devuelve una nueva lista ordenada
def merge(left, right):
result = []
i = j = 0
while i < len(left) and j < len(right):
if left[i] <= right[j]:
result.append(left[i])
i += 1
else:
result.append(right[j])
j += 1
result.extend(left[i:])
result.extend(right[j:])
return result
def merge_sort(arr):
if len(arr) <= 1:
return arr
mid = len(arr) // 2
left_half = merge_sort(arr[:mid])
right_half = merge_sort(arr[mid:])
return merge(left_half, right_half)nums = [3, 1, 4, 1, 5, 9, 2, 6]
bubble_sort(nums) # ordena nums in situ
quick_sort(nums, 0, len(nums) - 1) # también in situ
sorted_nums = merge_sort(nums) # devuelve una lista nuevaEn una entrevista, lo anterior suele bastar. Pero si quieres destacar, menciona que las funciones integradas de Python sorted() y list.sort() usan Timsort, un híbrido de merge sort e insertion sort. Por eso casi nunca escribes una ordenación desde cero en Python en producción.
Hay varios algoritmos para hallar caminos más cortos en grafos.
En grafos no ponderados, BFS explora eficazmente capa a capa. En grafos ponderados con aristas no negativas, el algoritmo de Dijkstra identifica el camino más corto examinando primero el vértice más cercano.
El algoritmo A* mejora la eficiencia usando heurísticas para estimar el coste restante. La elección depende de las características del grafo y de los requisitos del problema.
Veamos preguntas avanzadas para quienes buscan puestos senior o quieren demostrar un conocimiento profundo de estructuras especializadas o complejas.
La programación dinámica resuelve problemas complejos dividiéndolos en subproblemas solapados más pequeños. En lugar de recalcular desde cero, guardas las soluciones de esas partes para no repetir trabajo.
Es muy útil, por ejemplo, para encontrar la subsecuencia común más larga entre dos cadenas o el coste mínimo para llegar a un punto de una cuadrícula.
Los B-trees son estructuras balanceadas diseñadas para acceder a disco de forma eficiente. Algunas características:
Ofrecen ventajas sobre los árboles de búsqueda binaria:
El orden topológico es un algoritmo que ordena los vértices de un grafo acíclico dirigido (DAG) de modo que si hay una arista del vértice u al vértice v, entonces u aparece antes que v en el orden. Se usa mucho en planificación de tareas para respetar dependencias, y en sistemas de build, gestores de paquetes y planificación de prerrequisitos académicos.
Un min-heap es una implementación específica de una cola de prioridad y se define como un árbol binario completo donde el valor de cada nodo es menor o igual que el de sus hijos, lo que permite encontrar y extraer el mínimo con eficiencia.
Por su parte, una cola de prioridad es una estructura abstracta que permite insertar elementos con una prioridad asociada y los extrae según esa prioridad. Los min-heaps son una forma común de implementarlas por su eficiencia.
Una estructura de conjuntos disjuntos, o union-find, mantiene una colección de conjuntos que no se solapan. Admite dos operaciones principales:
Tiene muchas aplicaciones, pero las más comunes son el algoritmo de Kruskal para hallar el árbol de expansión mínima y problemas de flujo en redes para determinar componentes conectados.
Un segment tree es una estructura diseñada para realizar consultas y actualizaciones por rangos sobre un array de forma eficiente. Es especialmente útil cuando repetimos operaciones como suma, mínimo, máximo o máximo común divisor sobre subrangos del array.
Se construye como un árbol binario donde cada nodo representa un segmento del array. Las hojas corresponden a elementos individuales y los nodos internos agregan los valores de sus hijos según la operación. Logran O(log n) tanto en actualizaciones como en consultas.
Un árbol de sufijos almacena todos los sufijos de una cadena para responder consultas de patrones en tiempo proporcional a la longitud del patrón, no del texto. Un árbol de sufijos "real" usa compresión de aristas para lograr O(n) espacio y normalmente se construye con el algoritmo de Ukkonen, pero es lo bastante complejo como para que rara vez te pidan programarlo desde cero en 45 minutos.
Una alternativa común es el trie de sufijos, más simple, que guarda un carácter por nodo. Usa O(n²) espacio pero es mucho más fácil de escribir y explicar. El truco en la entrevista es conocer el compromiso y explicitarlo.
Aquí tienes una implementación limpia en Python:
class SuffixTrieNode:
def __init__(self):
self.children = {} # Mapa de carácter -> nodo hijo
self.indices = [] # Posiciones iniciales de los sufijos que pasan por este nodo
class SuffixTrie:
def __init__(self, text):
self.root = SuffixTrieNode()
self.text = text + "$" # Añadir un terminador único
self._build()
def _build(self):
"""Insertar todos los sufijos del texto en el trie."""
for i in range(len(self.text)):
self._insert_suffix(i)
def _insert_suffix(self, index):
node = self.root
for i in range(index, len(self.text)):
c = self.text[i]
if c not in node.children:
node.children[c] = SuffixTrieNode()
node = node.children[c]
node.indices.append(index)
def search(self, pattern):
"""Devolver todas las posiciones iniciales donde `pattern` aparece en el texto."""
node = self.root
for c in pattern:
if c not in node.children:
return []
node = node.children[c]
return node.indicesLos quadtrees son una estructura jerárquica que subdivide recursivamente un espacio bidimensional en cuatro cuadrantes iguales. Esta partición espacial es muy efectiva en procesamiento de imágenes, detección de colisiones en videojuegos y sistemas de información geográfica para almacenar y recuperar datos espaciales con eficiencia.
Demostrar que conoces las estructuras de datos es importante, pero saber cuándo usarlas correctamente te hará destacar en la entrevista. En esta sección, veremos cómo aplicar tus conocimientos a situaciones prácticas.
Por la naturaleza en tiempo real del problema, necesitarás estructuras de datos eficientes.
En mi experiencia, usaría quadtrees para datos geográficos, colas de prioridad para clasificar emparejamientos por distancia y urgencia, y tablas hash para búsquedas rápidas de ubicaciones de conductores y pasajeros.
Podemos combinar varias estructuras para recomendar productos eficazmente a partir del comportamiento del usuario.
Una matriz dispersa usuario–ítem almacenaría interacciones; tablas hash mapearían usuarios y artículos; colas de prioridad clasificarían recomendaciones, y grafos modelarían relaciones usuario–ítem para análisis avanzados como detección de comunidades.
Un grafo es muy eficaz para detectar y eliminar cuentas de spam. Representando usuarios como nodos y sus conexiones como aristas, puedes analizar la topología: identificar clústeres densos, nodos aislados y picos de actividad ayuda a señalar cuentas sospechosas.
Usaría una combinación de estructuras.
Tablas hash para almacenar IDs de usuario y sus conexiones, permitiendo búsquedas rápidas de destinatarios. Colas por usuario para mantener el orden de los mensajes. Además, árboles como los AVL para gestionar y consultar con eficiencia el estado en línea/fuera de línea y actualizar la disponibilidad en tiempo real.
Para un corrector, la búsqueda eficiente es clave. Un trie es ideal: cada nodo representa una letra y los caminos forman palabras. Permite búsquedas rápidas por prefijo y sugerencias ágiles para palabras mal escritas.
En este escenario, los segment trees destacan. Son muy buenos gestionando consultas por rango y actualizaciones. Podemos representar el mapa como un array 1D donde cada celda corresponde a una casilla y almacena si hay o no una estructura.
Prepararte puede ser todo un reto, pero un enfoque estructurado lo hace mucho más llevadero.
Concéntrate en dominar los fundamentos: arrays, listas enlazadas, pilas, colas, árboles, grafos y tablas hash. Entiende sus principios, cómo gestionan los datos y las complejidades temporales de inserción, eliminación y búsqueda.
Saber la teoría está bien, pero no basta. Debes saber implementarlas desde cero. Puedes aprovechar los cursos de DataCamp para practicar con retos de código que afiancen tu capacidad de resolver problemas.
Entender los compromisos entre estructuras es clave. Por ejemplo, los arrays dan acceso rápido pero las inserciones y borrados son costosos; las listas enlazadas permiten modificaciones eficientes pero requieren recorrido para acceder. Prepárate para comentarlos en tu entrevista.
Recuerda: comunicar es tan importante como programar. Quienes entrevistan buscan candidatos capaces de adaptar sus explicaciones a la audiencia. Como se comenta en el podcast DataFramed sobre el futuro de los roles de datos:
Tienes que ser capaz de transmitir cualquier tipo de insight de forma que lo entienda un niño de seis años y también de una manera que me satisfaga a mí o a alguien aún más técnico. Si de verdad dominas el tema, puedes simplificarlo al máximo, pero también hacerlo tan complejo que, sinceramente, solo la gente con un nivel técnico muy, muy alto lo entienda.
Mo Chen, Data & Analytics Manager at NatWest Group
Potencia tu carrera como científico de datos profesional.

¡Aprende más sobre estructuras de datos y los fundamentos de Python con estos cursos!
Curso
Curso
Curso
blog
Abid Ali Awan
15 min
blog
Abid Ali Awan
15 min
blog
Elena Kosourova
15 min
blog
Tim Lu
9 min
blog
Abid Ali Awan
15 min
blog
Nisha Arya Ahmed
15 min
