
Cours
Python intermédiaire
4 h
1.4M
Pour démontrer votre maîtrise des structures de données de base, vous devez être à l’aise avec les structures fondamentales et leurs implémentations. Des questions comme celles ci-dessous testent votre capacité à expliquer ces notions et à prouver vos connaissances.
On distingue généralement :
Les tableaux et les listes chaînées permettent tous deux de stocker des collections d’éléments, mais leur fonctionnement diffère. Voici l’essentiel :
Une pile est une liste ordonnée où l’on ajoute et retire des éléments par une seule extrémité, appelée le sommet. Elle suit le principe LIFO (Last In, First Out) : le dernier élément ajouté est le premier à sortir.
Les piles s’emploient notamment pour l’évaluation d’expressions, le backtracking, la gestion de la mémoire et les appels/retours de fonctions.
En Python, une liste se comporte naturellement comme une pile : append() correspond à push et pop() retire l’élément au sommet.
my_stack = []
item = 1
my_stack.append(item)
my_stack.pop()En suivant l’indice du sommet, ces opérations restent rapides et efficaces.
Une file est une structure FIFO (First In, First Out) — comme une file d’attente au magasin : on entre par l’arrière et on sort par l’avant.
En Python, on peut l’implémenter de plusieurs façons :
Avec une liste en utilisant append() et pop() :
my_queue = []
item = 1
# Enfiler
my_queue.append(item)
# Défiler
my_queue.pop(0)Avec deque() du module collections, qui rend append() et pop() plus rapides que sur les listes :
from collections import deque
my_queue = deque()
item = 1
# Enfiler
my_queue.append(item)
# Défiler
my_queue.popleft()Avec le module standard queue.Queue :
from queue import Queue
my_queue = Queue(maxsize = 3)
# Enfiler
my_queue.put(item)
# Défiler
my_queue.get()Un arbre binaire est une structure où chaque nœud a au plus deux enfants : un enfant gauche et un enfant droit. Un binary search tree (BST) est un type particulier d’arbre binaire avec des propriétés d’ordre : pour chaque nœud, toutes les clés du sous-arbre gauche sont plus petites, celles du sous-arbre droit sont plus grandes, et les deux sous-arbres sont eux-mêmes des BST.
Ces propriétés permettent des opérations efficaces (recherche, insertion, suppression) avec une complexité typique de O(log n) lorsque l’arbre est équilibré.
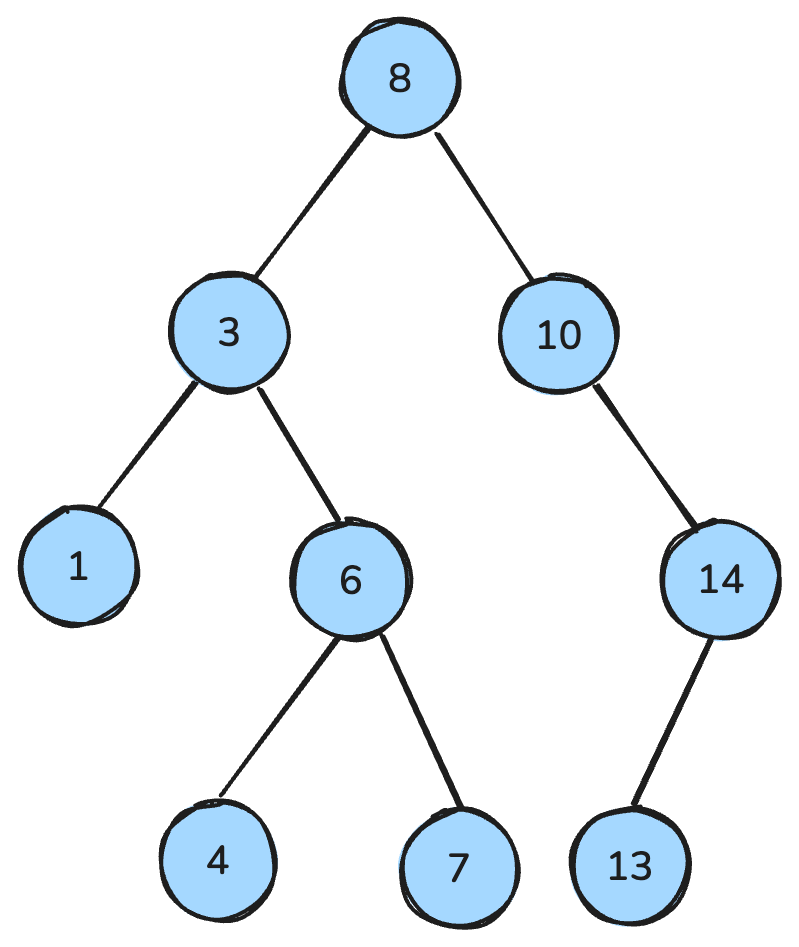
Arbre binaire de recherche. Image de l’auteur.
Le hachage est une technique qui transforme des données de taille quelconque en une valeur de taille fixe appelée valeur de hachage, au moyen d’une fonction de hachage.
Une utilisation courante est la table de hachage, qui associe des clés à des emplacements précis d’un tableau pour accélérer la recherche et la récupération des données. Le hachage sert aussi bien en cryptographie (sécurisation des mots de passe) qu’en déduplication pour organiser les données.
Un tas est une structure arborescente qui obéit à des règles spécifiques.
Dans un max-heap, chaque parent est supérieur ou égal à ses enfants ; dans un min-heap, chaque parent est inférieur ou égal à ses enfants.
Les tas servent notamment à implémenter des files de priorité, pour trier des éléments selon leur importance. Ils sont également à la base du tri par tas (heap sort), une méthode efficace d’organisation des données.
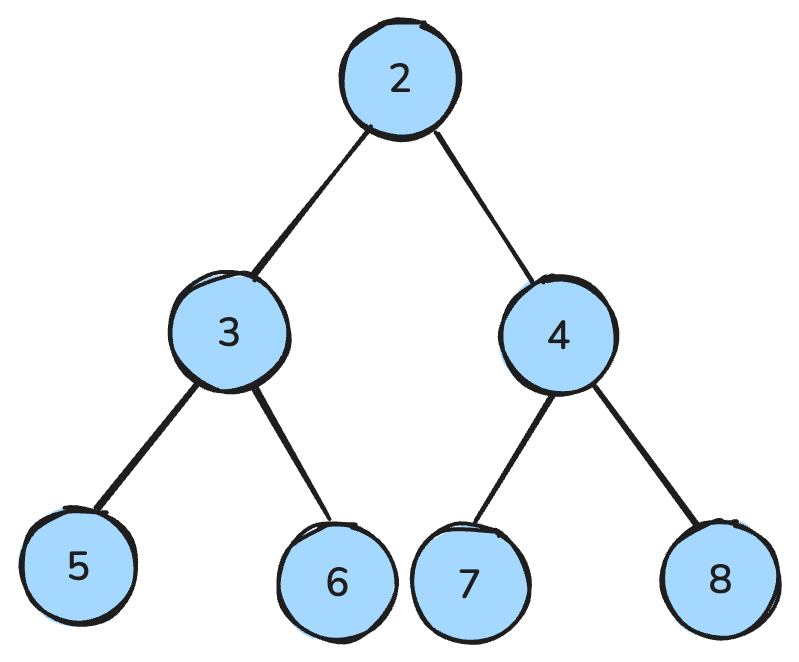
Dans un min-heap, tous les nœuds parents sont plus petits que leurs enfants — image de l’auteur.
Après les bases, passons à des questions de niveau intermédiaire qui explorent votre capacité à implémenter et utiliser ces concepts clés.
Un BST équilibré maintient des hauteurs gauche/droite relativement proches. L’équilibrage est indispensable pour conserver des recherches, insertions et suppressions efficaces.
Des techniques comme les arbres AVL et les arbres rouge-noir permettent l’auto-équilibrage. Les AVL imposent un écart de hauteur maximal de 1 entre les sous-arbres gauche et droit de tout nœud, tandis que les rouge-noir appliquent d’autres contraintes de balance.
Un min-heap s’appuie généralement sur une liste. Les deux opérations clés sont insert (ajoute un élément puis le remonte pour rétablir la propriété de tas) et extract_min (retire la racine puis fait redescendre pour réordonner) :
class MinHeap:
def __init__(self):
self.heap = []
def __len__(self): # Taille du tas
return len(self.heap)
def __parent(self, i): # Index du parent
return (i - 1) // 2
def __left(self, i): # Index de l'enfant gauche
return 2 * i + 1
def __right(self, i): # Index de l'enfant droit
return 2 * i + 2
def __swap(self, i, j): # Échanger deux éléments
self.heap[i], self.heap[j] = self.heap[j], self.heap[i]
def __heapify_up(self, i): # Rétablir la propriété après insertion
while i > 0 and self.heap[i] < self.heap[self.__parent(i)]:
self.__swap(i, self.__parent(i))
i = self.__parent(i)
def __heapify_down(self, i): # Rétablir la propriété après extraction
while True:
smallest = i
left = self.__left(i)
right = self.__right(i)
if left < len(self) and self.heap[left] < self.heap[smallest]:
smallest = left
if right < len(self) and self.heap[right] < self.heap[smallest]:
smallest = right
if smallest != i:
self.__swap(i, smallest)
i = smallest
else:
break
def insert(self, val): # Insérer une valeur
self.heap.append(val)
self.__heapify_up(len(self) - 1)
def extract_min(self): # Extraire la valeur minimale
if not self.heap:
return None
min_val = self.heap[0]
self.heap[0] = self.heap[-1]
self.heap.pop()
self.__heapify_down(0)
return min_valUn trie, ou arbre des préfixes, est une structure arborescente conçue pour l’indexation efficace de chaînes et la recherche par préfixe.
Chaque nœud représente un caractère, et les chemins depuis la racine forment des chaînes complètes. Les tries sont utilisés pour l’autocomplétion, la correction orthographique et l’implémentation de dictionnaires.
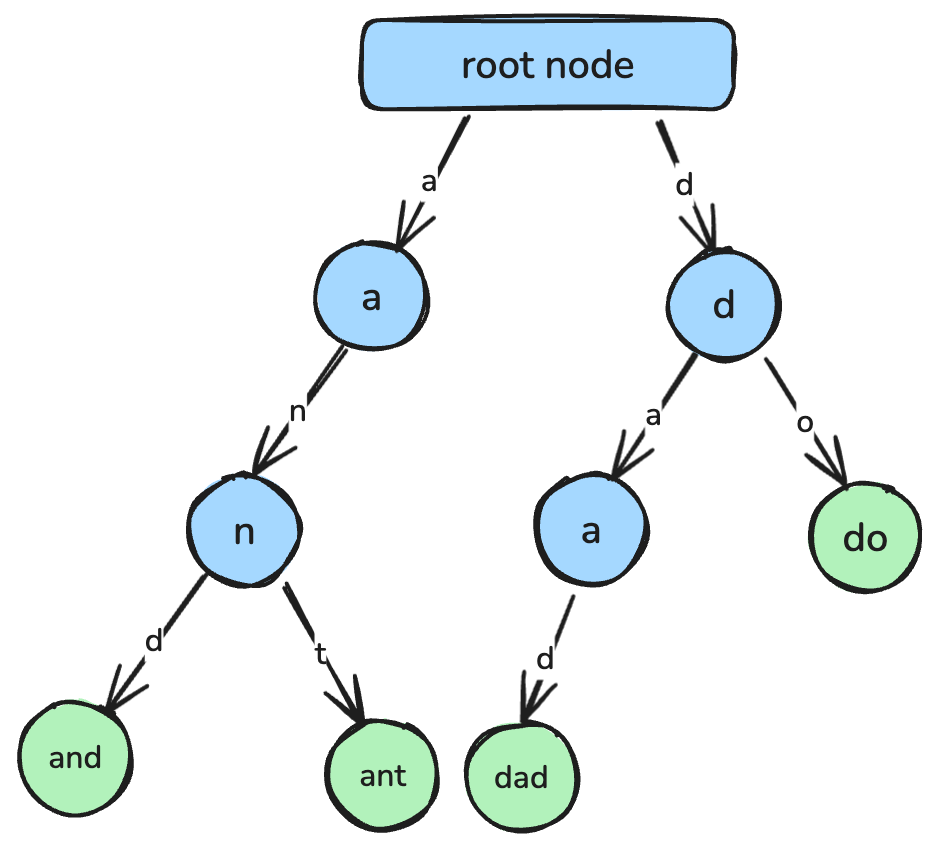
Un trie où chaque nœud représente un caractère qui s’assemble pour former une chaîne. Image de l’auteur.
Une collision survient lorsque deux clés différentes produisent le même indice.
Plusieurs méthodes existent : l’enchaînement (stockage des éléments en collision dans une liste chaînée à l’indice concerné) et le sondage (open addressing), qui recherche la prochaine case libre via des stratégies comme le sondage linéaire, quadratique ou le double hachage.
Un graphe est une structure composée de sommets (nœuds) reliés par des arêtes. Elle sert à représenter des relations et des connexions entre entités.
La recherche en profondeur (DFS) explore un graphe/arbre en s’enfonçant dans une branche avant de revenir en arrière. Elle s’implémente avec une pile explicite ou par récursion. Sa complexité est O(V + E), V étant le nombre de sommets et E celui des arêtes.
La recherche en largeur (BFS) parcourt systématiquement tous les nœuds d’un niveau avant de passer au suivant. Efficace pour trouver le plus court chemin dans les graphes non pondérés, elle s’appuie généralement sur une file. Comme la DFS, sa complexité est O(V + E).
Les algorithmes de tri sont essentiels pour traiter les données efficacement : ils accélèrent la recherche, facilitent l’analyse et la visualisation. Voici les principaux compromis à considérer :
Voici des implémentations Python claires :
# Bubble sort — tri en place
def bubble_sort(arr):
n = len(arr)
for i in range(n):
for j in range(0, n - i - 1):
if arr[j] > arr[j + 1]:
arr[j], arr[j + 1] = arr[j + 1], arr[j]
# Quick sort — tri en place
def partition(arr, low, high):
pivot = arr[high]
i = low - 1
for j in range(low, high):
if arr[j] <= pivot:
i += 1
arr[i], arr[j] = arr[j], arr[i]
arr[i + 1], arr[high] = arr[high], arr[i + 1]
return i + 1
def quick_sort(arr, low, high):
if low < high:
pi = partition(arr, low, high)
quick_sort(arr, low, pi - 1)
quick_sort(arr, pi + 1, high)
# Merge sort — retourne une nouvelle liste triée
def merge(left, right):
result = []
i = j = 0
while i < len(left) and j < len(right):
if left[i] <= right[j]:
result.append(left[i])
i += 1
else:
result.append(right[j])
j += 1
result.extend(left[i:])
result.extend(right[j:])
return result
def merge_sort(arr):
if len(arr) <= 1:
return arr
mid = len(arr) // 2
left_half = merge_sort(arr[:mid])
right_half = merge_sort(arr[mid:])
return merge(left_half, right_half)nums = [3, 1, 4, 1, 5, 9, 2, 6]
bubble_sort(nums) # trie nums en place
quick_sort(nums, 0, len(nums) - 1) # en place également
sorted_nums = merge_sort(nums) # retourne une nouvelle listeEn entretien, cette réponse suffit. Pour vous démarquer, mentionnez que les fonctions Python intégrées sorted() et list.sort() utilisent Timsort, un hybride de merge sort et insertion sort. D’où le fait qu’on n’écrive presque jamais un tri from scratch en production Python.
Plusieurs algorithmes existent pour trouver le plus court chemin.
Pour les graphes non pondérés, la BFS explore efficacement couche par couche. Dans les graphes pondérés à arêtes non négatives, l’algorithme de Dijkstra identifie le plus court chemin en examinant d’abord le sommet le plus proche.
L’algorithme A* améliore l’efficacité via des heuristiques qui estiment le coût restant. Le choix dépend des caractéristiques du graphe et des exigences du problème.
Voyons des questions plus avancées, utiles pour des postes seniors ou pour démontrer une connaissance approfondie de structures spécialisées ou complexes.
La programmation dynamique résout des problèmes complexes en les décomposant en sous-problèmes qui se recouvrent. Plutôt que de recalculer sans cesse, on mémorise les solutions intermédiaires afin d’éviter les répétitions.
Elle est très utile pour la plus longue sous-séquence commune entre deux chaînes, ou pour calculer le coût minimal afin d’atteindre une case donnée sur une grille.
Les B-trees sont des arbres équilibrés conçus pour des accès disque efficaces. Caractéristiques :
Avantages face aux BST :
Le tri topologique ordonne les sommets d’un graphe orienté acyclique (DAG) de sorte que s’il existe une arête de u vers v, u précède v dans l’ordre. Il s’emploie pour l’ordonnancement de tâches (respect des dépendances), les systèmes de build, les gestionnaires de packages et la planification de prérequis de cours.
Un min-heap est une implémentation spécifique d’une file de priorité : un arbre binaire complet où la valeur de chaque nœud est inférieure ou égale à celles de ses enfants, ce qui permet de trouver et d’extraire le minimum efficacement.
À l’inverse, une file de priorité est une structure abstraite où l’on insère des éléments assortis d’une priorité, et l’extraction respecte cet ordre de priorité. Les min-heaps sont une manière courante de les implémenter.
La structure d’ensembles disjoints, ou union-find, maintient une collection d’ensembles mutuellement exclusifs. Elle supporte deux opérations principales :
Ses applications les plus courantes incluent l’algorithme de Kruskal pour l’arbre couvrant minimum et les problèmes de flot pour identifier les composantes connexes d’un graphe.
Un segment tree est une structure conçue pour accélérer les requêtes et mises à jour sur des plages d’un tableau. Elle est particulièrement utile pour répéter des opérations comme la somme, le minimum, le maximum ou le PGCD sur des intervalles.
Il s’agit d’un arbre binaire où chaque nœud représente un segment du tableau. Les feuilles correspondent aux éléments individuels et les nœuds internes agrègent les valeurs de leurs enfants selon l’opération. Les mises à jour et requêtes se font en O(log n).
Un arbre des suffixes stocke chaque suffixe d’une chaîne, ce qui permet de répondre aux requêtes de motif en un temps proportionnel à la longueur du motif, et non à celle du texte. Un véritable arbre des suffixes compresse les arêtes pour atteindre O(n) d’espace et se construit typiquement avec l’algorithme d’Ukkonen — mais cela reste trop complexe pour un codage complet en 45 minutes d’entretien.
Un compromis courant est le trie des suffixes, plus simple, où chaque nœud stocke un caractère. Il utilise O(n²) d’espace mais est bien plus facile à écrire et à expliquer. L’astuce en entretien est de connaître ce compromis et de l’expliciter.
Voici une implémentation Python claire :
class SuffixTrieNode:
def __init__(self):
self.children = {} # Dictionnaire caractère -> nœud enfant
self.indices = [] # Positions de départ des suffixes passant par ce nœud
class SuffixTrie:
def __init__(self, text):
self.root = SuffixTrieNode()
self.text = text + "$" # Ajouter un terminateur unique
self._build()
def _build(self):
"""Insérer chaque suffixe du texte dans le trie."""
for i in range(len(self.text)):
self._insert_suffix(i)
def _insert_suffix(self, index):
node = self.root
for i in range(index, len(self.text)):
c = self.text[i]
if c not in node.children:
node.children[c] = SuffixTrieNode()
node = node.children[c]
node.indices.append(index)
def search(self, pattern):
"""Retourne toutes les positions de début où `pattern` apparaît dans le texte."""
node = self.root
for c in pattern:
if c not in node.children:
return []
node = node.children[c]
return node.indicesLes quadtrees sont des arbres hiérarchiques qui subdivisent récursivement un espace 2D en quatre quadrants égaux. Cette partition spatiale est très efficace pour le traitement d’images, la détection de collisions dans les jeux et les SIG, afin de stocker et retrouver des données spatiales rapidement.
Connaître les structures de données est essentiel, mais savoir quand les utiliser fera la différence en entretien. Dans cette section, nous voyons comment les appliquer à des situations concrètes.
Le temps réel impose des structures efficaces.
J’utiliserais des quadtrees pour les données géographiques, des files de priorité pour classer les correspondances selon la distance et l’urgence, et des tables de hachage pour l’accès rapide aux positions conducteurs/passagers.
On peut combiner plusieurs structures de données pour recommander efficacement.
Une matrice utilisateur-produit clairsemée stockera les interactions, des tables de hachage mapperont efficacement utilisateurs et items, des files de priorité classeront les recommandations, et des graphes modéliseront les relations pour des analyses avancées comme la détection de communautés.
Le graphe est très pertinent pour détecter et supprimer les comptes de spam. Modélisez les utilisateurs comme des nœuds et leurs liens comme des arêtes. L’identification de clusters denses, de nœuds isolés et de pics d’activité soudains permet de repérer les comptes suspects.
Je combinerais plusieurs structures.
Des tables de hachage pour associer les IDs utilisateurs à leurs connexions (recherches rapides). Des files par utilisateur pour garantir l’ordre de livraison des messages. Et des arbres, par exemple AVL, pour gérer efficacement le statut en ligne/hors ligne et les mises à jour en temps réel.
Pour un correcteur, la recherche rapide est cruciale. Un trie est idéal : chaque nœud représente une lettre et les chemins forment des mots, ce qui permet des recherches par préfixe rapides et de suggérer des corrections efficacement.
Dans ce cas, les arbres de segments sont un excellent choix. Ils gèrent très bien les requêtes de plage et les mises à jour. On peut représenter la carte du jeu comme un tableau 1D où chaque cellule correspond à une case et stocke la présence d’une structure.
La préparation peut sembler ardue, mais une approche structurée la rend beaucoup plus gérable !
Concentrez-vous sur les fondamentaux : tableaux, listes chaînées, piles, files, arbres, graphes et tables de hachage. Comprenez leurs principes, la gestion des données et les complexités en temps des opérations (insertion, suppression, recherche).
Connaître la théorie ne suffit pas. Vous devez savoir implémenter ces structures from scratch. Vous pouvez suivre des cours DataCamp pour vous exercer avec des défis de code et renforcer votre capacité à résoudre des problèmes.
Comprendre les compromis entre structures est déterminant. Par exemple, les tableaux permettent un accès direct mais rendent les insertions/suppressions coûteuses, alors que les listes chaînées modifient efficacement mais nécessitent un parcours pour l’accès. Soyez prêt à en discuter.
N’oubliez pas : la communication compte autant que le code. Les recruteurs recherchent des profils capables d’adapter leur discours à l’audience. Comme discuté dans le podcast DataFramed sur l’avenir des métiers de la donnée :
Vous devez être capable de délivrer n’importe quel insight de façon à la fois compréhensible par un enfant de six ans et satisfaisante pour moi ou quelqu’un d’encore plus technique. Si vous maîtrisez vraiment votre sujet, vous pouvez le simplifier à l’extrême, mais aussi l’expliquer à un niveau de complexité que, honnêtement, seuls les experts les plus pointus comprennent.
Mo Chen, Data & Analytics Manager at NatWest Group
Boostez votre carrière en tant que data scientist professionnel.

Approfondissez les structures de données et les bases de Python avec ces cours !
Cours
Cours
Cours
blog
Nisha Arya Ahmed
15 min
blog
Kurtis Pykes
15 min
blog
Nathaniel Taylor-Leach
8 min
Tutoriel
Sejal Jaiswal