
Kurs
Python für Fortgeschrittene
4 Std.
1.4M
Um dein Verständnis grundlegender Datenstrukturen zu zeigen, solltest du bei den Kernstrukturen und ihren Implementierungen sehr sicher sein. Fragen wie die folgenden prüfen, wie gut du diese Ideen erklären und dein Wissen belegen kannst.
Datenstrukturen lassen sich wie folgt einteilen:
Arrays und verkettete Listen speichern Elementgruppen, funktionieren aber unterschiedlich. Hier die wichtigsten Unterschiede:
Ein Stack ist eine geordnete Liste, bei der du Elemente nur an einem Ende – dem Top – hinzufügst und entfernst. Er folgt dem Last-in-first-out-Prinzip (LIFO): Das zuletzt eingefügte Element wird als erstes entfernt.
Stacks werden u. a. bei Ausdrucksauswertung, Backtracking, Speicherverwaltung sowie bei Funktionsaufrufen und -rückgaben eingesetzt.
In Python lässt sich eine Liste direkt als Stack verwenden: append() entspricht push, und pop() entfernt das Top-Element.
my_stack = []
item = 1
my_stack.append(item)
my_stack.pop()Wenn du die Position des Tops per Index nachverfolgst, werden diese Operationen schnell und effizient.
Eine Queue folgt dem First-in-first-out-Prinzip (FIFO) – wie eine Schlange im Laden: Hinten rein, vorne raus.
In Python kannst du eine Queue auf verschiedene Arten implementieren:
Mit einem Array bzw. einer Liste und den Methoden append() und pop():
my_queue = []
item = 1
# Enqueue
my_queue.append(item)
# Dequeue
my_queue.pop(0)Mit deque() aus der collections-Bibliothek, das append()- und pop()-Operationen schneller ausführt als Listen:
from collections import deque
my_queue = deque()
item = 1
# Enqueue
my_queue.append(item)
# Dequeue
my_queue.popleft()Mit dem eingebauten Modul queue.Queue:
from queue import Queue
my_queue = Queue(maxsize = 3)
# Enqueue
my_queue.put(item)
# Dequeue
my_queue.get()Ein Binärbaum ist eine Datenstruktur, bei der jeder Knoten höchstens zwei Kinder hat: ein linkes und ein rechtes. Ein Binary Search Tree (BST) ist ein spezieller Binärbaum mit einer eindeutigen Ordnungsregel: Für jeden Knoten sind alle Schlüssel im linken Teilbaum kleiner, alle Schlüssel im rechten Teilbaum größer, und beide Teilbäume sind wiederum BSTs.
Diese Eigenschaften ermöglichen effizientes Suchen, Einfügen und Löschen – in balancierten Bäumen typischerweise mit der Zeitkomplexität O(log n).
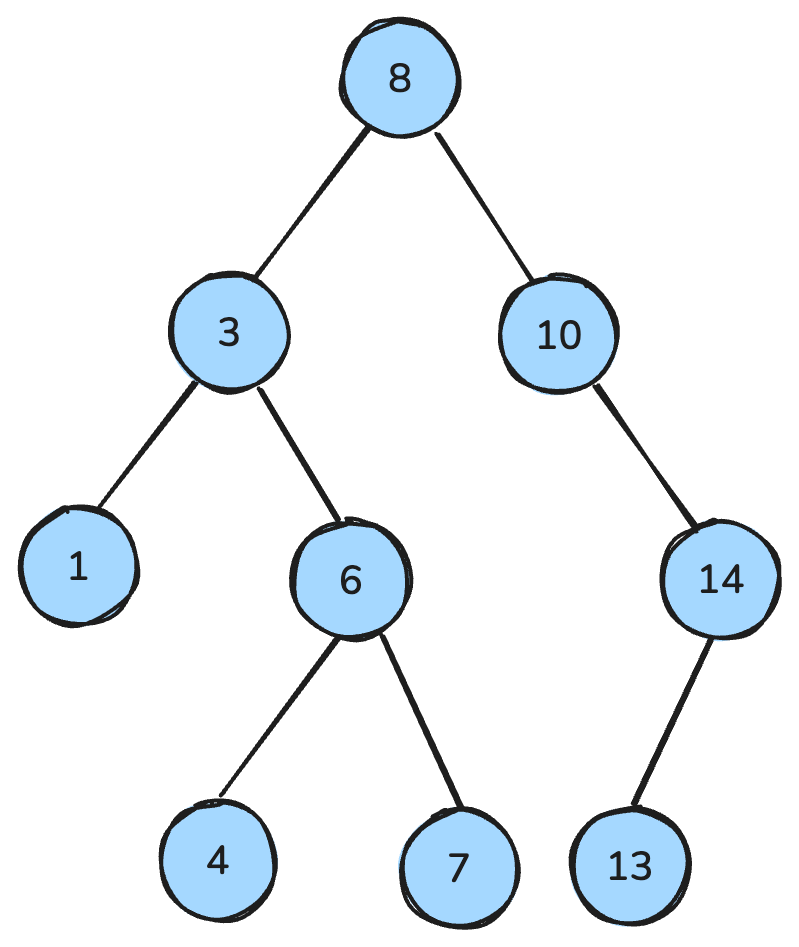
Binary Search Tree. Abbildung: Autorin/Autor.
Hashing ist eine Technik, die Daten beliebiger Größe mithilfe einer Hashfunktion in einen Wert fester Länge – den Hashwert – umwandelt.
Ein häufiger Einsatz ist die Hashtabelle: Schlüssel werden auf Positionen in einem Array abgebildet, sodass Daten schnell gefunden und abgerufen werden können. Hashing findet viele Anwendungen – von der Passwortsicherung in der Kryptografie bis zur Deduplizierung für geordnete Datenspeicherung.
Ein Heap ist eine baumartige Datenstruktur mit speziellen Ordnungsregeln.
Im Max-Heap ist jeder Elternknoten größer oder gleich seinen Kindern; im Min-Heap ist jeder Elternknoten kleiner oder gleich seinen Kindern.
Heaps werden oft für Prioritätswarteschlangen verwendet, um Elemente nach Wichtigkeit zu verwalten. Außerdem sind sie wichtig für Heapsort, eine Methode zur effizienten Datenordnung.
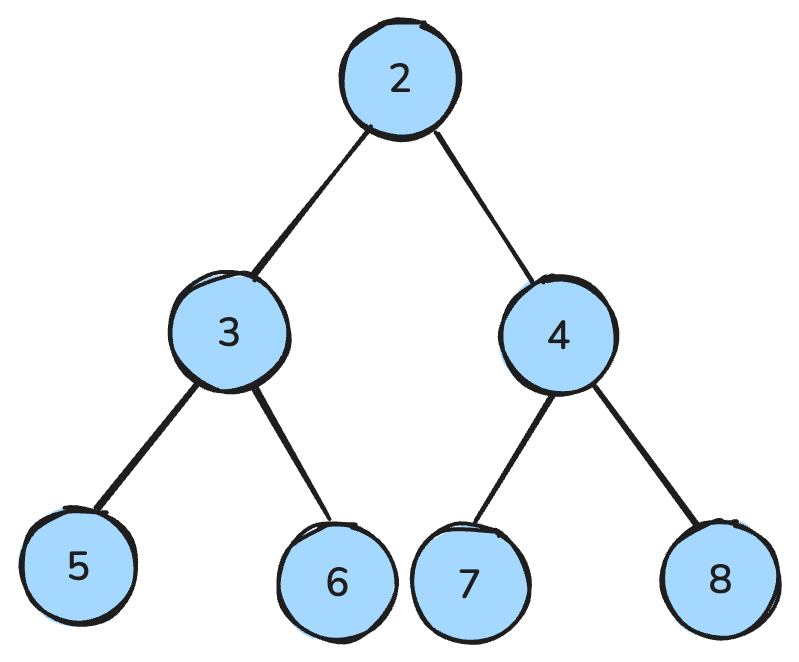
Ein Min-Heap, in dem alle Elternknoten kleiner sind als ihre Kinder – Abbildung: Autorin/Autor.
Nach den Grundlagen schauen wir uns nun Fragen auf mittlerem Niveau an, die deine technische Souveränität bei Implementierung und Einsatz dieser Konzepte beleuchten.
Ein balancierter BST hält die Höhen seiner linken und rechten Teilbäume ungefähr im Gleichgewicht. Das ist wichtig, um effizientes Suchen, Einfügen und Löschen zu erhalten.
Techniken wie AVL-Bäume und Red-Black-Trees sorgen für Selbstbalancierung. AVL-Bäume erlauben eine Höhendifferenz von höchstens 1 zwischen linkem und rechtem Teilbaum eines Knotens, während Red-Black-Trees strengere Balancebedingungen umsetzen.
Ein Min-Heap wird typischerweise durch eine Liste unterlegt. Die zwei Kernoperationen sind insert (fügt ein Element ein und „bubbelt“ es nach oben, um die Heap-Eigenschaft wiederherzustellen) und extract_min (entfernt die Wurzel und siftet nach unten, um die Ordnung wiederherzustellen):
class MinHeap:
def __init__(self):
self.heap = []
def __len__(self): # Get the size of the heap
return len(self.heap)
def __parent(self, i): # Get the parent index
return (i - 1) // 2
def __left(self, i): # Get the left child index
return 2 * i + 1
def __right(self, i): # Get the right child index
return 2 * i + 2
def __swap(self, i, j): # Swap two elements
self.heap[i], self.heap[j] = self.heap[j], self.heap[i]
def __heapify_up(self, i): # Restore min-heap property after insertion
while i > 0 and self.heap[i] < self.heap[self.__parent(i)]:
self.__swap(i, self.__parent(i))
i = self.__parent(i)
def __heapify_down(self, i): # Restore min-heap property after extraction
while True:
smallest = i
left = self.__left(i)
right = self.__right(i)
if left < len(self) and self.heap[left] < self.heap[smallest]:
smallest = left
if right < len(self) and self.heap[right] < self.heap[smallest]:
smallest = right
if smallest != i:
self.__swap(i, smallest)
i = smallest
else:
break
def insert(self, val): # Insert a value into the heap
self.heap.append(val)
self.__heapify_up(len(self) - 1)
def extract_min(self): # Extract the minimum value from the heap
if not self.heap:
return None
min_val = self.heap[0]
self.heap[0] = self.heap[-1]
self.heap.pop()
self.__heapify_down(0)
return min_valEin Trie, auch Präfixbaum genannt, ist eine baumbasierte Datenstruktur für effiziente String-Suche und Präfixabgleich.
In einem Trie repräsentiert jeder Knoten ein einzelnes Zeichen, und Pfade von der Wurzel zu Knoten entsprechen vollständigen Strings. Tries werden u. a. für Autovervollständigung, Rechtschreibprüfung und die Implementierung von Wörterbüchern verwendet.
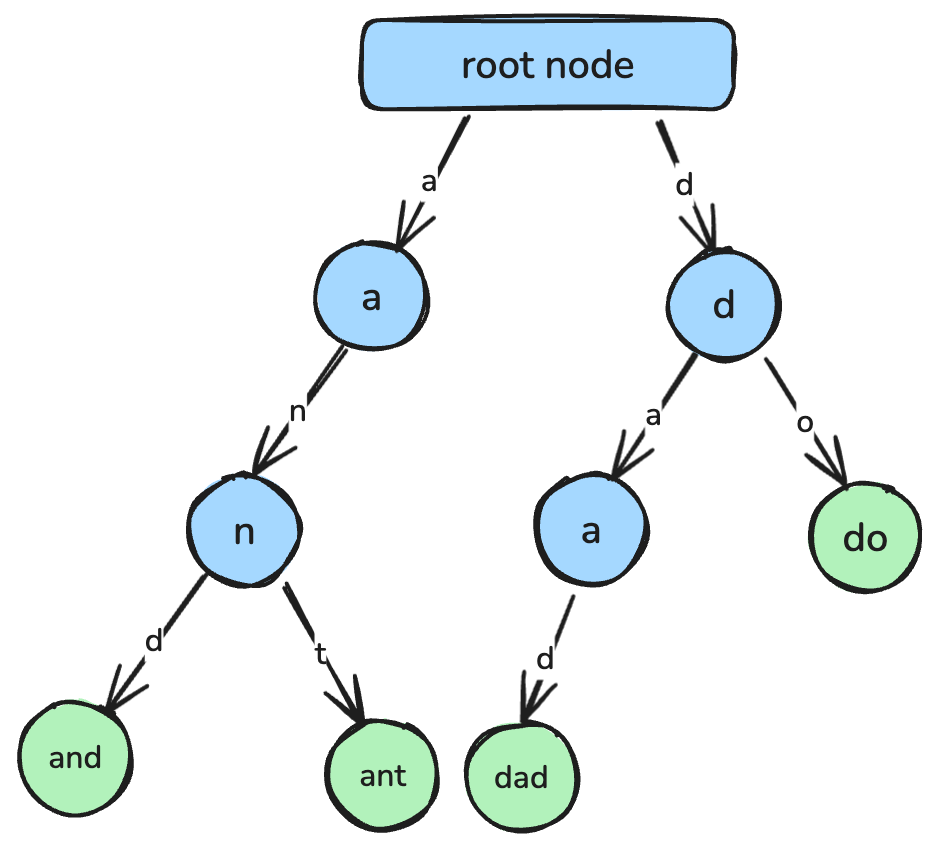
Ein Trie, in dem jeder Knoten ein Zeichen repräsentiert, die zusammen einen String bilden. Abbildung: Autorin/Autor.
Eine Kollision tritt auf, wenn zwei verschiedene Schlüssel auf denselben Index hashen.
Es gibt mehrere Methoden zur Auflösung: Beim Chaining werden kollidierende Elemente in einer verketteten Liste am entsprechenden Index gespeichert. Beim Open Addressing wird per Sondieren – etwa lineares oder quadratisches Sondieren oder Double Hashing – der nächste freie Platz im Array gefunden.
Ein Graph ist eine Datenstruktur aus einer Menge von Knoten (Vertices), die durch Kanten (Edges) verbunden sind. So lassen sich Beziehungen und Verbindungen zwischen Entitäten darstellen.
Depth-First Search (DFS) durchsucht einen Graphen oder Baum, indem es jeweils so tief wie möglich in einen Zweig geht, bevor es zurückkehrt. Implementierbar mit explizitem Stack oder rekursiv. Die Zeitkomplexität ist O(V + E), wobei V die Anzahl Knoten und E die Anzahl Kanten ist.
Breadth-First Search (BFS) erkundet systematisch alle Knoten einer Ebene, bevor es zur nächsten übergeht. Es eignet sich zum Finden kürzester Wege in ungewichteten Graphen und wird typischerweise mit einer Queue implementiert. Wie DFS hat BFS eine Zeitkomplexität von O(V + E).
Sortieralgorithmen sind essenziell für effiziente Datenverarbeitung – sie ermöglichen schnelleres Suchen, bessere Analysen und leichtere Visualisierung. Bei der Wahl gibt es einige zentrale Trade-offs:
Hier sind saubere Python-Implementierungen:
# Bubble sort — sorts in place
def bubble_sort(arr):
n = len(arr)
for i in range(n):
for j in range(0, n - i - 1):
if arr[j] > arr[j + 1]:
arr[j], arr[j + 1] = arr[j + 1], arr[j]
# Quick sort — sorts in place
def partition(arr, low, high):
pivot = arr[high]
i = low - 1
for j in range(low, high):
if arr[j] <= pivot:
i += 1
arr[i], arr[j] = arr[j], arr[i]
arr[i + 1], arr[high] = arr[high], arr[i + 1]
return i + 1
def quick_sort(arr, low, high):
if low < high:
pi = partition(arr, low, high)
quick_sort(arr, low, pi - 1)
quick_sort(arr, pi + 1, high)
# Merge sort — returns a new sorted list
def merge(left, right):
result = []
i = j = 0
while i < len(left) and j < len(right):
if left[i] <= right[j]:
result.append(left[i])
i += 1
else:
result.append(right[j])
j += 1
result.extend(left[i:])
result.extend(right[j:])
return result
def merge_sort(arr):
if len(arr) <= 1:
return arr
mid = len(arr) // 2
left_half = merge_sort(arr[:mid])
right_half = merge_sort(arr[mid:])
return merge(left_half, right_half)nums = [3, 1, 4, 1, 5, 9, 2, 6]
bubble_sort(nums) # sorts nums in place
quick_sort(nums, 0, len(nums) - 1) # also in place
sorted_nums = merge_sort(nums) # returns a new listIn einem Interview reicht die obige Antwort aus. Wenn du dich abheben willst, erwähne, dass Pythons eingebaute sorted() und list.sort() Timsort verwenden – einen Hybrid aus Merge Sort und Insertion Sort. Deshalb schreibst du in produktivem Python fast nie einen Sortieralgorithmus von Grund auf.
Für kürzeste Wege in Graphen gibt es mehrere Algorithmen.
Bei ungewichteten Graphen erkundet Breadth-First Search die Knoten Ebene für Ebene effektiv. In gewichteten Graphen mit nichtnegativen Kanten findet Dijkstras Algorithmus den kürzesten Pfad, indem er jeweils den nächsten Knoten zuerst betrachtet.
Der A*-Algorithmus steigert die Effizienz durch Heuristiken zur Kostenschätzung. Die Wahl hängt von den Eigenschaften des Graphen und den Anforderungen des Problems ab.
Schauen wir uns nun fortgeschrittene Fragen an – für Senior-Rollen oder um tiefes Wissen über spezialisierte bzw. komplexe Datenstrukturen zu zeigen.
Dynamic Programming löst komplexe Probleme, indem sie in überlappende Teilprobleme zerlegt und deren Lösungen gespeichert werden. So vermeidest du wiederholte Berechnungen.
Das ist z. B. nützlich, um die längste gemeinsame Teilsequenz zweier Strings zu finden oder minimale Kosten auf einem Gitter zu berechnen.
B-Bäume sind balancierte Baumstrukturen, die für effizienten Plattenzugriff entwickelt wurden. Merkmale sind:
Gegenüber Binary Search Trees bieten sie Vorteile:
Die topologische Sortierung ordnet die Knoten eines gerichteten azyklischen Graphen (DAG) so an, dass bei einer Kante von u nach v u vor v erscheint. Sie wird u. a. für Task-Scheduling eingesetzt – um die Ausführungsreihenfolge gemäß Abhängigkeiten festzulegen – sowie in Build-Systemen, Paketmanagern und der Planung von Kursvoraussetzungen.
Ein Min-Heap ist eine konkrete Implementierung einer Priority Queue und definiert als vollständiger Binärbaum, in dem der Wert jedes Knotens kleiner oder gleich dem seiner Kinder ist. So lassen sich Minimum finden und extrahieren effizient umsetzen.
Eine Priority Queue hingegen ist ein abstrakter Datentyp, in den Elemente mit Priorität eingefügt werden und in Prioritätsreihenfolge entnommen werden. Min-Heaps sind eine gängige Implementierung, da sie diese Operationen effizient unterstützen.
Ein Disjoint-Set, auch Union-Find genannt, verwaltet eine Sammlung paarweise disjunkter Mengen. Es unterstützt zwei Hauptoperationen:
Typische Anwendungen sind Kruskal’s Algorithmus zum Finden eines minimalen Spannbaums sowie Network-Flow-Probleme zur Bestimmung zusammenhängender Komponenten in Graphen.
Ein Segmentbaum unterstützt effiziente Bereichsanfragen und -updates auf Arrays. Er ist ideal, wenn wiederholt Summen, Minimum, Maximum oder der größte gemeinsame Teiler über Teilbereiche abgefragt werden.
Er wird als Binärbaum aufgebaut, wobei jeder Knoten ein Arraysegment repräsentiert. Blätter entsprechen einzelnen Elementen, innere Knoten aggregieren je nach Operation die Werte ihrer Kinder. Updates und Abfragen laufen in O(log n).
Ein Suffixbaum speichert alle Suffixe eines Strings, sodass Musterabfragen proportional zur Musterlänge beantwortet werden können – nicht zur Textlänge. Ein „echter“ Suffixbaum nutzt Kantenkompression für O(n) Speicher und wird typischerweise mit Ukkonens Algorithmus gebaut – das ist jedoch so komplex, dass Interviewer selten erwarten, dass du ihn in 45 Minuten aus dem Nichts codest.
Ein gängiger Kompromiss ist der einfachere Suffix-Trie, der ein Zeichen pro Knoten speichert. Er benötigt O(n²) Speicher, ist aber deutlich leichter zu schreiben und zu erklären. Der Trick im Interview ist, den Trade-off zu kennen und deutlich anzusprechen.
Hier ist eine saubere Python-Implementierung:
class SuffixTrieNode:
def __init__(self):
self.children = {} # Map of character -> child node
self.indices = [] # Starting positions of suffixes passing through this node
class SuffixTrie:
def __init__(self, text):
self.root = SuffixTrieNode()
self.text = text + "$" # Append a unique terminator
self._build()
def _build(self):
"""Insert every suffix of the text into the trie."""
for i in range(len(self.text)):
self._insert_suffix(i)
def _insert_suffix(self, index):
node = self.root
for i in range(index, len(self.text)):
c = self.text[i]
if c not in node.children:
node.children[c] = SuffixTrieNode()
node = node.children[c]
node.indices.append(index)
def search(self, pattern):
"""Return all starting positions where `pattern` appears in the text."""
node = self.root
for c in pattern:
if c not in node.children:
return []
node = node.children[c]
return node.indicesQuadtrees sind hierarchische Baumstrukturen, die einen zweidimensionalen Raum rekursiv in vier gleiche Quadranten unterteilen. Diese räumliche Partitionierung eignet sich hervorragend für Bildverarbeitung, Kollisionserkennung in Spielen und Geoinformationssysteme für effiziente Speicherung und Abfrage räumlicher Daten.
Dein Wissen über Datenstrukturen ist wichtig – noch besser ist es, wenn du zeigen kannst, wann du welche Struktur sinnvoll einsetzt. In diesem Abschnitt übertragen wir das Wissen in die Praxis.
Wegen des Echtzeitcharakters brauchst du hier sehr effiziente Datenstrukturen.
Ich würde Quadtrees für Geodaten nutzen, Priority Queues zur Bewertung potenzieller Matches nach Distanz und Dringlichkeit sowie Hashtabellen für schnelle Lookups von Fahrer- und Fahrgastpositionen.
Eine Kombination aus Datenstrukturen eignet sich am besten für Empfehlungen basierend auf Verhalten.
Eine dünn besetzte User-Item-Matrix speichert Interaktionen; Hashtabellen mappen Nutzer und Produkte effizient. Priority Queues ranken Empfehlungen, und Graphstrukturen modellieren User-Item-Beziehungen für Analysen wie Community Detection.
Eine Graphdatenstruktur ist hier sehr wirkungsvoll. Nutzer werden als Knoten, Verbindungen als Kanten modelliert. Die Analyse der Topologie – dichte Cluster, isolierte Knoten, Aktivitätsspitzen – hilft, verdächtige Accounts zu markieren.
Ich würde mehrere Strukturen kombinieren.
Hashtabellen speichern User-IDs und ihre Verbindungslisten für schnelle Ziel-Lookups. Für jeden Nutzer sorgen Queues für die korrekte Nachrichtenreihenfolge. Zusätzlich können Bäume wie AVL-Bäume den Online/Offline-Status effizient verwalten, um Verfügbarkeiten in Echtzeit zu aktualisieren.
Für einen Spellchecker ist schneller Wortlookup entscheidend. Ein Trie ist ideal: Jeder Knoten steht für einen Buchstaben, Pfade bilden Wörter. Dadurch sind schnelle Präfixsuchen möglich, und Korrekturvorschläge lassen sich zügig finden.
Hier bieten sich Segmentbäume an. Sie sind sehr gut in Bereichsanfragen und Updates. Die Spielkarte kann als 1D-Array modelliert werden, in dem jede Zelle die Präsenz einer Struktur abbildet.
Die Vorbereitung kann fordernd sein – mit einem strukturierten Plan wird sie machbar!
Konzentriere dich auf die Grundlagen: Arrays, verkettete Listen, Stacks, Queues, Bäume, Graphen und Hashtabellen. Verstehe ihre Prinzipien, wie sie Daten verwalten, und die Zeitkomplexitäten von Einfügen, Löschen und Suchen.
Konzepte zu kennen ist gut, reicht aber nicht. Du solltest diese Strukturen auch von Grund auf implementieren können. Du kannst mit DataCamp-Kursen an Coding-Challenges teilnehmen, die deine Problemlösung schärfen.
Das Verständnis der Trade-offs ist entscheidend. Arrays bieten schnellen Zugriff, sind aber bei Einfügen/Löschen teuer; verkettete Listen erlauben effiziente Modifikationen, benötigen jedoch Traversierung für den Zugriff. Sei bereit, diese Abwägungen zu erläutern.
Denk daran: Kommunikation ist genauso wichtig wie Code. Interviewer achten darauf, ob du deine Erklärungen an das Publikum anpassen kannst. Wie im DataFramed-Podcast zur Zukunft von Datenrollen besprochen:
Du musst jeden Insight so vermitteln können, dass ihn ein sechsjähriges Kind versteht – und zugleich so, dass er mich oder sogar jemanden mit noch mehr technischer Expertise zufriedenstellt. Wenn du dein Thema wirklich beherrschst, kannst du es stark vereinfachen, aber auch so komplex darstellen, dass es ehrlich gesagt nur die wirklich, wirklich technischen Expertinnen und Experten nachvollziehen können.
Mo Chen, Data & Analytics Manager at NatWest Group
Bringe deine Karriere als professioneller Datenwissenschaftler voran.

Lerne mehr über Datenstrukturen und die Python-Grundlagen mit diesen Kursen!
Kurs
Kurs
Kurs
Blog
Nisha Arya Ahmed
15 Min.
Blog
Hesam Sheikh Hassani
15 Min.
Tutorial
Sejal Jaiswal
Tutorial
Matt Crabtree
Tutorial
Allan Ouko
