Courses
Python 中级
4小时
1.4M
要展示您对基础数据结构的理解,必须对核心结构及其实现充满信心。像下面这样的问题会考查您解释这些概念并体现所掌握知识的能力。
数据结构可分为如下两类:
数组和链表都是存储一组元素的方式,但工作机制不同。主要区别如下:
栈是有序列表,只在一端(称为栈顶)进行入栈与出栈。它遵循后进先出(LIFO)原则:最后加入的元素最先被移除。
栈可用于多种场景,如表达式求值、回溯、内存管理,以及函数调用与返回。
在 Python 中,列表可直接作为栈使用:append() 是入栈,pop() 移除栈顶元素。
my_stack = []
item = 1
my_stack.append(item)
my_stack.pop()通过用索引记录栈顶位置,您可以使这些操作快速高效。
队列是先进先出(FIFO)结构——就像商店排队,从队尾进入,从队首离开。
在 Python 中,可以用不同技术实现队列:
使用数组或列表,并利用 append() 与 pop() 方法:
my_queue = []
item = 1
# Enqueue
my_queue.append(item)
# Dequeue
my_queue.pop(0)使用 collections 库中的 deque(),其 append() 与 pop() 较列表更快:
from collections import deque
my_queue = deque()
item = 1
# Enqueue
my_queue.append(item)
# Dequeue
my_queue.popleft()使用内置模块 queue.Queue:
from queue import Queue
my_queue = Queue(maxsize = 3)
# Enqueue
my_queue.put(item)
# Dequeue
my_queue.get()二叉树是一种数据结构,每个节点最多有两个子节点:左子和右子。二叉搜索树(BST)是具有特定有序性质的二叉树:对每个节点,左子树所有键更小,右子树所有键更大,且两棵子树本身也都是 BST。
这些性质使得查找、插入与删除等操作高效,在平衡的树上通常能达到O(log n) 的时间复杂度。
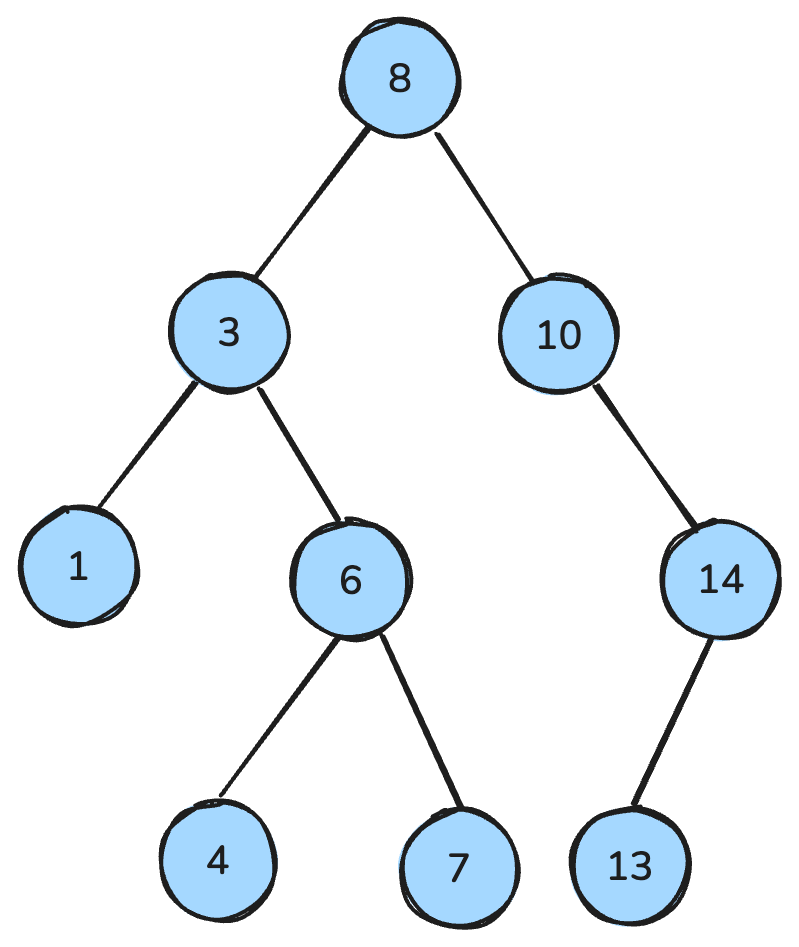
二叉搜索树。作者制图。
哈希是一种技术,它将任意大小的数据转换为固定大小的值,称为哈希值,通过哈希函数得到。
哈希最常见的用途之一是哈希表,它将键映射到数组中的特定位置,使数据能被快速定位与检索。它还广泛用于密码学中的密码保护,以及通过去重保持数据有序等应用。
堆是一种类似树的结构,并遵循特定规则。
在最大堆中,每个父节点都大于等于其子节点;在最小堆中,每个父节点都小于等于其子节点。
堆常用于实现优先队列,以元素的重要性或权值进行排序;它们也是堆排序的基础,这是一种高效的数据组织方法。
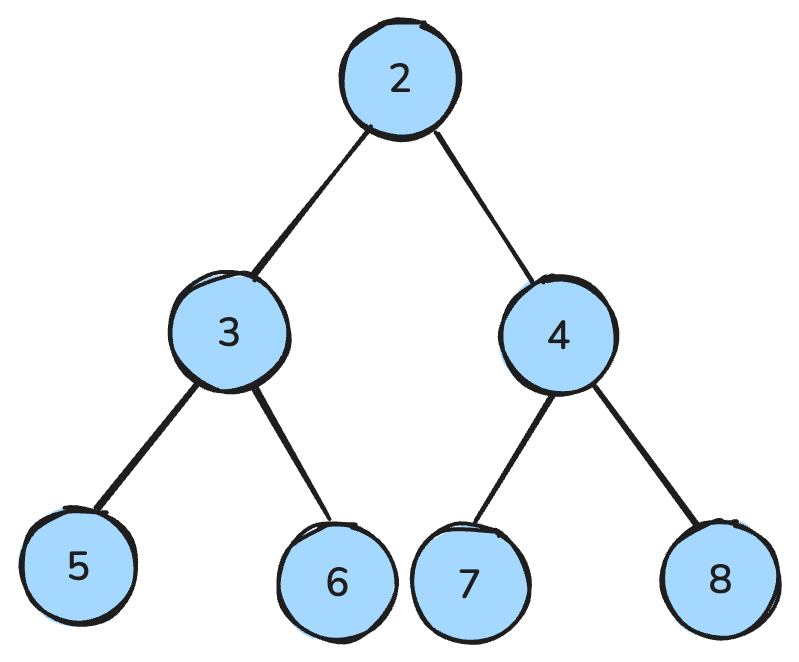
最小堆中所有父节点都小于子节点——作者制图。
在掌握基础之后,让我们转向一些中级问题,以考查您在实现与使用这些基础概念方面的技术熟练度。
平衡的二叉搜索树会使其左右子树高度相对接近。保持 BST 平衡对于维持查找、插入与删除的高效性至关重要。
常见的自平衡技术包括 AVL 树与红黑树。AVL 树确保任一节点左右子树的高度差不超过 1,而红黑树具有更严格的平衡约束。
最小堆通常由列表支撑。两个关键操作是 insert(插入元素并向上调整以恢复堆性质)与 extract_min(移除根并向下调整以恢复顺序):
class MinHeap:
def __init__(self):
self.heap = []
def __len__(self): # Get the size of the heap
return len(self.heap)
def __parent(self, i): # Get the parent index
return (i - 1) // 2
def __left(self, i): # Get the left child index
return 2 * i + 1
def __right(self, i): # Get the right child index
return 2 * i + 2
def __swap(self, i, j): # Swap two elements
self.heap[i], self.heap[j] = self.heap[j], self.heap[i]
def __heapify_up(self, i): # Restore min-heap property after insertion
while i > 0 and self.heap[i] < self.heap[self.__parent(i)]:
self.__swap(i, self.__parent(i))
i = self.__parent(i)
def __heapify_down(self, i): # Restore min-heap property after extraction
while True:
smallest = i
left = self.__left(i)
right = self.__right(i)
if left < len(self) and self.heap[left] < self.heap[smallest]:
smallest = left
if right < len(self) and self.heap[right] < self.heap[smallest]:
smallest = right
if smallest != i:
self.__swap(i, smallest)
i = smallest
else:
break
def insert(self, val): # Insert a value into the heap
self.heap.append(val)
self.__heapify_up(len(self) - 1)
def extract_min(self): # Extract the minimum value from the heap
if not self.heap:
return None
min_val = self.heap[0]
self.heap[0] = self.heap[-1]
self.heap.pop()
self.__heapify_down(0)
return min_val字典树(前缀树)是一种基于树的结构,旨在高效进行字符串检索与前缀匹配。
在 trie 中,每个节点代表一个字符,从根到节点的路径对应一个完整字符串。常见应用包括自动补全、拼写检查工具,以及词典的实现。
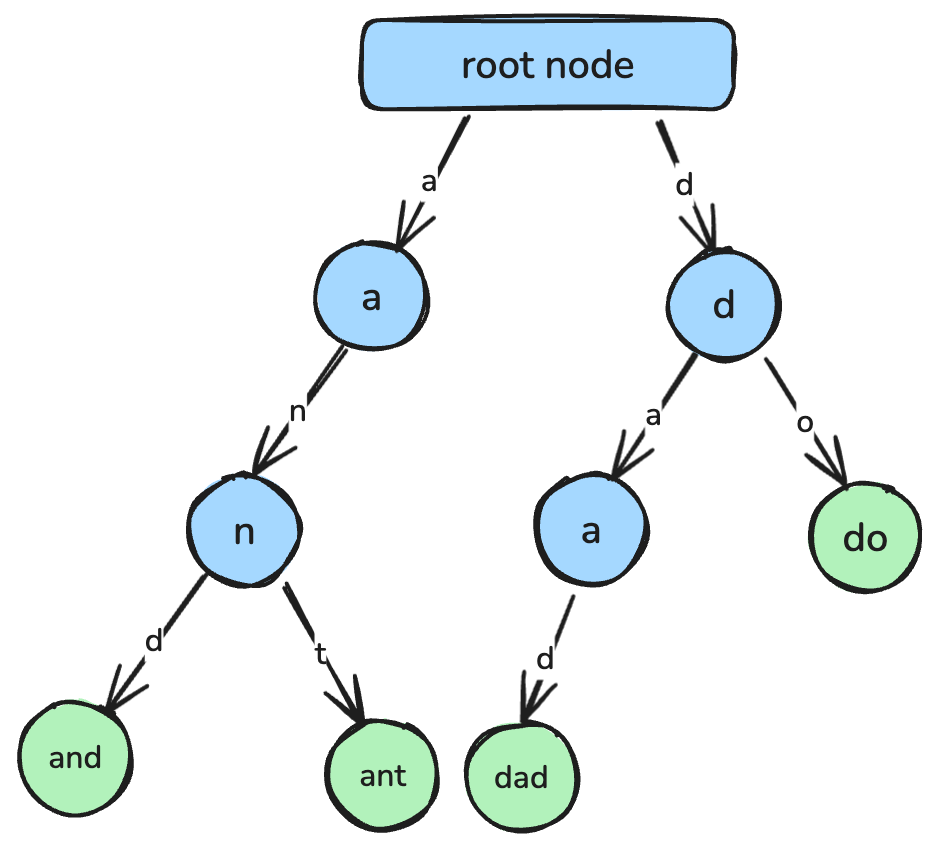
字典树中,每个节点代表一个字符,连接起来形成字符串。作者制图。
当两个不同键映射到相同索引时,就发生了冲突。
常见的解决方法包括链式法(在相应索引处用链表存储冲突元素)与开放定址法(通过线性探测、二次探测或双重哈希等方式在数组中寻找下一个可用槽)。
图是一种数据结构,由一组顶点(节点)及其间的边构成,用于表达各实体间的关系与连接。
深度优先搜索(DFS)是沿着每个分支尽可能深入再回溯的遍历算法。可用显式栈或递归实现。时间复杂度为 O(V + E),其中 V 为顶点数、E 为边数,即可能需要检查所有顶点和边。
广度优先搜索(BFS)会在进入下一层之前系统地遍历当前深度的所有节点。它适合在无权图中寻找最短路径,通常用队列实现。与 DFS 相同,BFS 的时间复杂度为 O(V + E)。
排序算法是高效数据处理的基础——它们能加快搜索、改进数据分析,并便于可视化。选择时需权衡以下要点:
以下是各自的简洁 Python 实现:
# Bubble sort — sorts in place
def bubble_sort(arr):
n = len(arr)
for i in range(n):
for j in range(0, n - i - 1):
if arr[j] > arr[j + 1]:
arr[j], arr[j + 1] = arr[j + 1], arr[j]
# Quick sort — sorts in place
def partition(arr, low, high):
pivot = arr[high]
i = low - 1
for j in range(low, high):
if arr[j] <= pivot:
i += 1
arr[i], arr[j] = arr[j], arr[i]
arr[i + 1], arr[high] = arr[high], arr[i + 1]
return i + 1
def quick_sort(arr, low, high):
if low < high:
pi = partition(arr, low, high)
quick_sort(arr, low, pi - 1)
quick_sort(arr, pi + 1, high)
# Merge sort — returns a new sorted list
def merge(left, right):
result = []
i = j = 0
while i < len(left) and j < len(right):
if left[i] <= right[j]:
result.append(left[i])
i += 1
else:
result.append(right[j])
j += 1
result.extend(left[i:])
result.extend(right[j:])
return result
def merge_sort(arr):
if len(arr) <= 1:
return arr
mid = len(arr) // 2
left_half = merge_sort(arr[:mid])
right_half = merge_sort(arr[mid:])
return merge(left_half, right_half)nums = [3, 1, 4, 1, 5, 9, 2, 6]
bubble_sort(nums) # sorts nums in place
quick_sort(nums, 0, len(nums) - 1) # also in place
sorted_nums = merge_sort(nums) # returns a new list在面试中,上述回答已足够。但若想脱颖而出,可提到 Python 内置的 sorted() 与 list.sort() 采用 Timsort,它是归并排序与插入排序的混合。这也是为什么在生产环境的 Python 中几乎不会从零实现排序。
可用多种算法在图中寻找最短路径。
对于无权图,广度优先搜索能逐层高效探索。对于非负权图,Dijkstra 算法通过优先考察最近顶点来确定最短路径。
A* 搜索算法利用启发式函数估计剩余代价以提高效率。选择何种算法取决于图的特性与具体问题需求。
下面探讨一些面向资深职位或希望展示对专业/复杂数据结构深刻理解的高级面试题。
动态规划通过将复杂问题拆分为较小且相互重叠的子问题来求解。与其每次从头开始,不如保存这些子问题的解,从而避免重复计算。
它在求解两字符串的最长公共子序列、或在网格上寻找到达某一位置的最小代价等问题中非常有用。
B-树是一种为高效磁盘访问而设计的平衡树数据结构。其特性包括:
它们相较二叉搜索树的优势包括:
拓扑排序用于对有向无环图(DAG)的顶点进行排序,使得若从顶点u指向顶点v有一条边,则u在该序列中出现在v之前。它常用于任务调度——确定满足依赖关系的执行顺序——以及构建系统、包管理器与课程先修规划等。
最小堆是优先队列的一种具体实现,定义为一棵完全二叉树,其中每个节点的值不大于其子节点的值,从而可高效地查找与提取最小元素。
而优先队列是抽象数据结构,允许插入带优先级的元素,并按优先级出队。由于其在这些操作上的高效性,最小堆是实现优先队列的常用方式。
并查集(又称 union-find)维护若干两两不相交的集合。该结构支持两种主要操作:
并查集有许多应用,其中最常见的是用于Kruskal 算法来寻找图的最小生成树,以及网络流问题中用于确定图的连通分量。
线段树是一种旨在高效支持数组区间查询与更新的数据结构。它特别适用于需要反复在特定区间上求和、最小值、最大值或最大公约数等操作的场景。
线段树构建为二叉树,每个节点表示数组的一个区间。叶子对应数组的单个元素,内部节点按所需操作聚合其子节点的信息。它对更新与查询均可实现O(log n) 的时间复杂度。
后缀树存储字符串的所有后缀,使模式查询的时间与模式长度成正比,而非文本长度。真正的后缀树通过边压缩实现 O(n) 空间,通常用 Ukkonen 算法构建——但其复杂度较高,面试中很少要求在 45 分钟内从零编码。
一个常见的折中是更简单的后缀字典树(suffix trie),每个节点存一个字符。它使用 O(n²) 空间,但更易于编写与讲解。面试中的要点是清楚取舍并明确表达。
以下是简洁的 Python 实现:
class SuffixTrieNode:
def __init__(self):
self.children = {} # Map of character -> child node
self.indices = [] # Starting positions of suffixes passing through this node
class SuffixTrie:
def __init__(self, text):
self.root = SuffixTrieNode()
self.text = text + "$" # Append a unique terminator
self._build()
def _build(self):
"""Insert every suffix of the text into the trie."""
for i in range(len(self.text)):
self._insert_suffix(i)
def _insert_suffix(self, index):
node = self.root
for i in range(index, len(self.text)):
c = self.text[i]
if c not in node.children:
node.children[c] = SuffixTrieNode()
node = node.children[c]
node.indices.append(index)
def search(self, pattern):
"""Return all starting positions where `pattern` appears in the text."""
node = self.root
for c in pattern:
if c not in node.children:
return []
node = node.children[c]
return node.indices四叉树是一种层级树结构,将二维空间递归划分为四个等分象限。这种空间划分技术在图像处理、游戏中的碰撞检测,以及地理信息系统中的空间数据高效存储与检索等场景非常有效。
展示您懂数据结构很重要,但在合适的场景中正确使用它们更能让您脱颖而出。本节将回顾如何将数据结构知识应用到实际问题中。
由于该问题具有实时性,需要高效的数据结构。
以我的经验,我会用四叉树管理地理数据,用优先队列按距离与乘客紧急程度对候选匹配进行排序,并用哈希表高效查找司机与乘客位置。
我们可以结合多种数据结构来实现高效推荐。
稀疏的用户-物品矩阵用于存储互动;哈希表高效映射用户与物品;优先队列用于对推荐结果排序;图结构可建模用户-物品关系,以进行如社区发现等更复杂分析。
图数据结构在检测和移除垃圾账号方面非常有效。将用户表示为节点、连接表示为边,通过分析网络拓扑来识别高密度簇、孤立节点和活动激增等异常,以标记可疑账号。
我会在实时聊天应用中组合使用多种数据结构。
哈希表存储用户 ID 与其连接列表,便于快速查找需发送的目标用户;为每个用户实现队列以维护消息顺序,确保按发送顺序投递;此外,可用如 AVL 树等树结构高效存取用户在线/离线状态,实现可用性的实时更新。
拼写检查的关键在于高效查词。字典树是理想选择。字典树中的每个节点代表一个字母,沿路径形成单词。这使前缀搜索很快,便于快速为拼写错误给出建议。
在该场景中,线段树是非常优秀的选择。它擅长高效处理区间查询与更新。我们可将游戏地图表示为一维数组,每个元素对应一个网格单元,并存储是否存在建筑的信息。
我知道准备数据结构面试不容易,但有条理的方法能让它更可控!
专注掌握数组、链表、栈、队列、树、图与哈希表等基础概念。理解其原理、如何管理数据,以及插入、删除、查找等操作的时间复杂度。
理解概念固然重要,但还不够。您应能从零实现这些数据结构。您可以参与 DataCamp 课程,借助编程练习提升问题求解能力。
理解数据结构之间的取舍至关重要。例如,数组访问快捷,但插入与删除成本较高;链表修改高效,但访问需遍历。面试中要准备好讨论这些取舍。
请记住,沟通与代码同样重要。面试官希望候选人能根据受众调整解释方式。正如在 DataFramed 播客中对数据岗位未来的讨论所说:
您需要能够以六岁小孩也能听懂的方式传达任何洞见,同时也能让我,甚至更资深的技术专家感到满意。如果您真的懂,既能把问题讲得通俗易懂,也能讲得足够深入复杂,以至于只有技术水平很高的人才能完全理解。
Mo Chen, Data & Analytics Manager at NatWest Group
通过以下课程进一步学习数据结构与 Python 基础!
Courses
Courses
Courses