
Course
Intermediate Python
4 hr
1.4M
To demonstrate your understanding of basic data structures, you need to be very confident in core structures and their implementations. Questions like the following will test your ability to explain these ideas and show your knowledge.
Data structures are classified as follows:
Arrays and linked lists are two ways to store groups of items, but they work differently. Let’s see the main differences:
A stack is an ordered list where you add and remove items at one end, called the top. It follows the last-in-first-out (LIFO) principle: the most recently added element is the first one removed.
Stacks can be used for several applications, such as expression evaluation, backtracking, memory management, and function calls and returns.
In Python, a list works as a stack out of the box: append() is push, and pop() removes the top item.
my_stack = []
item = 1
my_stack.append(item)
my_stack.pop()By keeping track of the top's position with an index, you can make these operations quick and efficient.
A queue is a first-in, first-out (FIFO) structure — like a line at a store, where people enter at the back and leave from the front.
In Python, you can implement a queue using different techniques:
Using an array or list and taking advantage of the methods append() and pop():
my_queue = []
item = 1
# Enqueue
my_queue.append(item)
# Dequeue
my_queue.pop(0)Using deque() from the collections library, which performs append() and pop() functions quicker than lists:
from collections import deque
my_queue = deque()
item = 1
# Enqueue
my_queue.append(item)
# Dequeue
my_queue.popleft()Using the in-built module queue.Queue:
from queue import Queue
my_queue = Queue(maxsize = 3)
# Enqueue
my_queue.put(item)
# Dequeue
my_queue.get()A binary tree is a data structure where each node has at most two children: a left child and a right child. Then, a binary search tree (BST) is a specific type of binary tree that has distinct ordering properties: For every node, all keys in the left subtree are smaller, all keys in the right subtree are larger, and both subtrees are themselves BSTs.
These properties facilitate efficient operations such as searching, insertion, and deletion, typically achieving a time complexity of O(log n) in balanced trees.
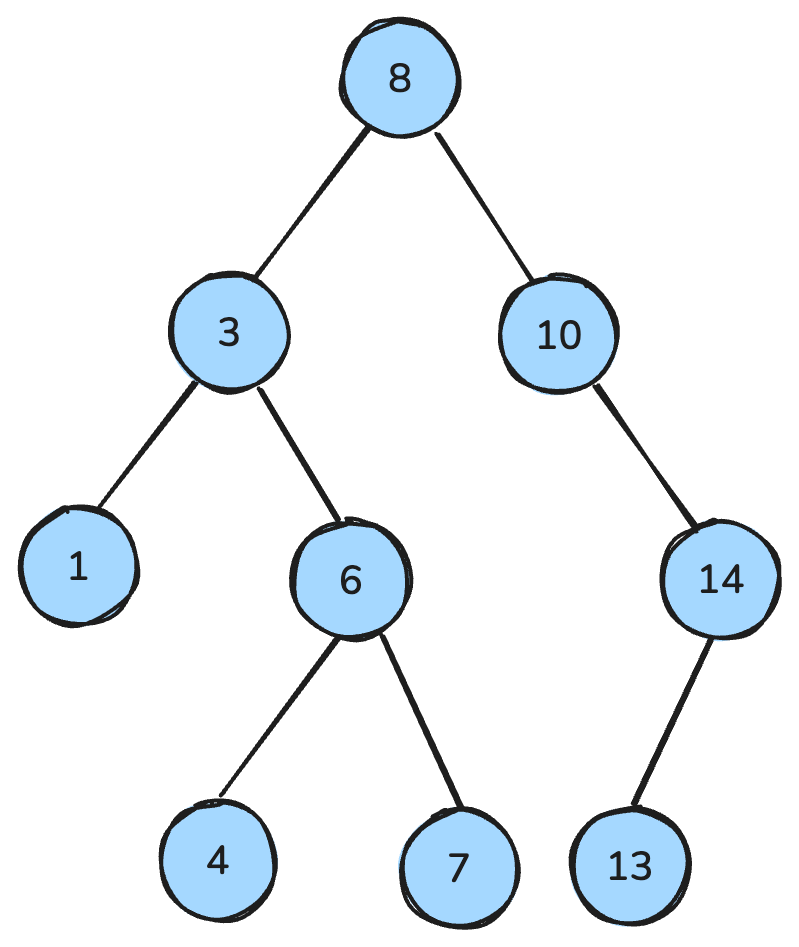
Binary search tree. Image by Author.
Hashing is a technique that takes data of any size and turns it into a fixed-size value called a hash value using a hash function.
One common use of hashing is in hash tables, where it helps match keys with specific locations in an array, making it easy to find and retrieve data quickly. Hashing can have many applications, from helping secure passwords in cryptography to keeping data organized through deduplication.
A heap is a data structure that resembles a tree and follows special rules.
In a max-heap, every parent is greater than or equal to its children; in a min-heap, every parent is smaller than or equal to its children.
Heaps are often used to create priority queues, which help sort items based on their importance or value. They are also important for heap sorting, which is a method of organizing data efficiently.
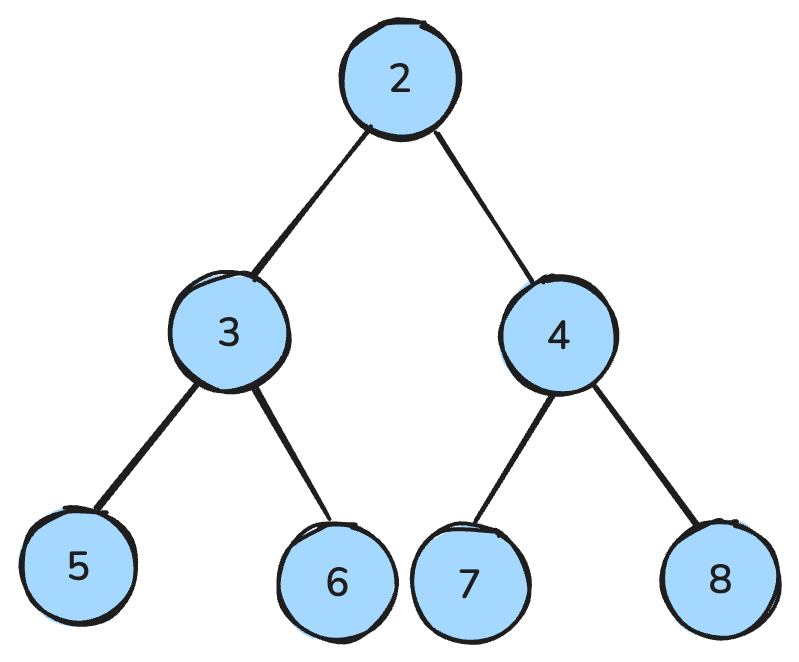
A min-heap is where all the parent nodes are smaller than the children—image by Author.
Having covered the basics, let's move on to some intermediate-level data structure interview questions that explore your technical proficiency in implementing and using these fundamental concepts.
A balanced binary search tree maintains a relatively equal height between its left and right subtrees. Balancing a BST is very important to maintain efficient search, insertion, and deletion operations.
Techniques like AVL trees and red-black trees are commonly used to achieve self-balancing. AVL trees maintain a height difference of at most 1 between the left and right subtrees of any node, while red-black trees have stricter balance constraints.
A min-hep is typically backed by a list. The two key operations are insert (which adds an element and bubbles it up to restore the heap property) and extract_min (which removes the root and sifts down to restore order):
class MinHeap:
def __init__(self):
self.heap = []
def __len__(self): # Get the size of the heap
return len(self.heap)
def __parent(self, i): # Get the parent index
return (i - 1) // 2
def __left(self, i): # Get the left child index
return 2 * i + 1
def __right(self, i): # Get the right child index
return 2 * i + 2
def __swap(self, i, j): # Swap two elements
self.heap[i], self.heap[j] = self.heap[j], self.heap[i]
def __heapify_up(self, i): # Restore min-heap property after insertion
while i > 0 and self.heap[i] < self.heap[self.__parent(i)]:
self.__swap(i, self.__parent(i))
i = self.__parent(i)
def __heapify_down(self, i): # Restore min-heap property after extraction
while True:
smallest = i
left = self.__left(i)
right = self.__right(i)
if left < len(self) and self.heap[left] < self.heap[smallest]:
smallest = left
if right < len(self) and self.heap[right] < self.heap[smallest]:
smallest = right
if smallest != i:
self.__swap(i, smallest)
i = smallest
else:
break
def insert(self, val): # Insert a value into the heap
self.heap.append(val)
self.__heapify_up(len(self) - 1)
def extract_min(self): # Extract the minimum value from the heap
if not self.heap:
return None
min_val = self.heap[0]
self.heap[0] = self.heap[-1]
self.heap.pop()
self.__heapify_down(0)
return min_valA trie, also known as a prefix tree, is a tree-based data structure designed for efficient string retrieval and prefix matching.
In a trie, each node represents a single character, and the paths from the root to the nodes correspond to complete strings. Tries are commonly used in various applications, such as autocomplete features, spell-checking tools, and the implementation of dictionaries.
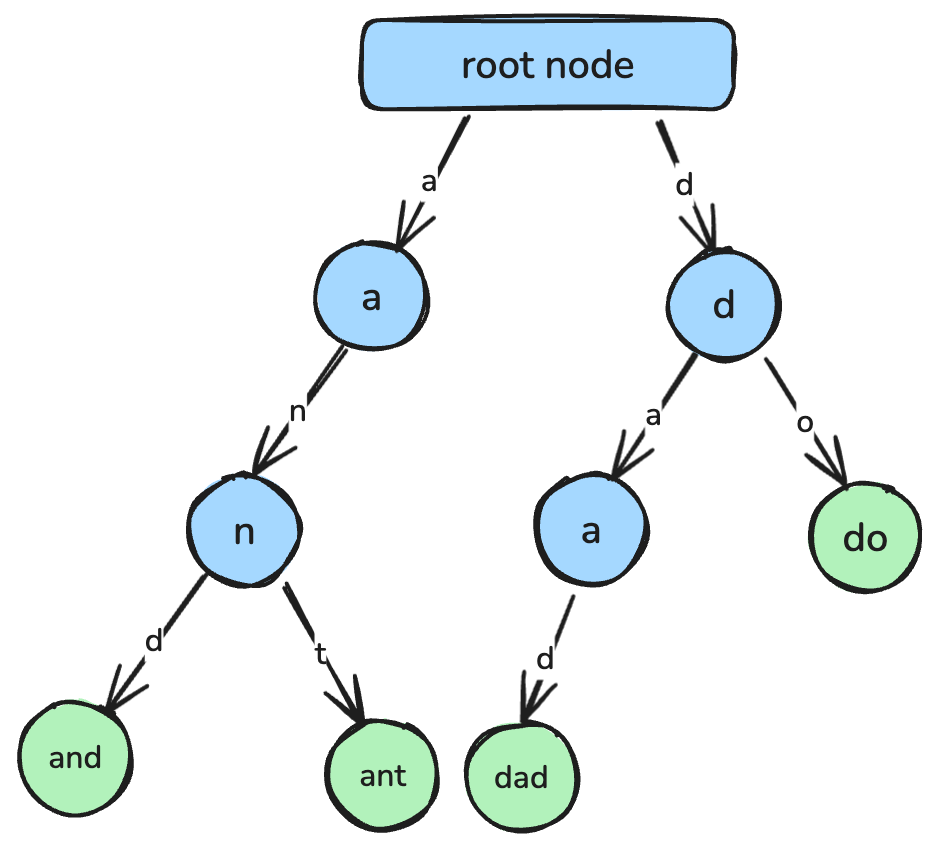
A trie, where each node represents a single character that connects to form a string. Image By Author.
A collision occurs when two different keys hash to the same index.
There are several methods for resolving collisions, including chaining, where colliding elements are stored in a linked list at the corresponding index, and open addressing, which involves finding the next available slot in the array through probing methods such as linear probing, quadratic probing, or double hashing.
A graph is a data structure consisting of a collection of vertices, also known as nodes, interconnected by edges. This structure is useful for illustrating relationships and connections between various entities.
Depth-first search (DFS) is an algorithm that explores a graph or tree by diving deep into each branch before backtracking. It can be implemented using an explicit stack or through recursion. The time complexity is O(V + E), where V is the number of vertices and E is the number of edges, meaning it may need to examine all vertices and edges.
Breadth-first search (BFS) systematically explores all nodes at the current depth level before moving to the next level. It is effective for finding the shortest path in unweighted graphs and is typically implemented using a queue. Like DFS, BFS has a time complexity of O(V + E), requiring a review of all vertices and edges.
Sorting algorithms are essential for efficient data processing — they enable faster searching, improved data analysis, and easier data visualization. When choosing between them, there are a few key trade-offs to keep in mind:
Here are clean Python implementations of each:
# Bubble sort — sorts in place
def bubble_sort(arr):
n = len(arr)
for i in range(n):
for j in range(0, n - i - 1):
if arr[j] > arr[j + 1]:
arr[j], arr[j + 1] = arr[j + 1], arr[j]
# Quick sort — sorts in place
def partition(arr, low, high):
pivot = arr[high]
i = low - 1
for j in range(low, high):
if arr[j] <= pivot:
i += 1
arr[i], arr[j] = arr[j], arr[i]
arr[i + 1], arr[high] = arr[high], arr[i + 1]
return i + 1
def quick_sort(arr, low, high):
if low < high:
pi = partition(arr, low, high)
quick_sort(arr, low, pi - 1)
quick_sort(arr, pi + 1, high)
# Merge sort — returns a new sorted list
def merge(left, right):
result = []
i = j = 0
while i < len(left) and j < len(right):
if left[i] <= right[j]:
result.append(left[i])
i += 1
else:
result.append(right[j])
j += 1
result.extend(left[i:])
result.extend(right[j:])
return result
def merge_sort(arr):
if len(arr) <= 1:
return arr
mid = len(arr) // 2
left_half = merge_sort(arr[:mid])
right_half = merge_sort(arr[mid:])
return merge(left_half, right_half)nums = [3, 1, 4, 1, 5, 9, 2, 6]
bubble_sort(nums) # sorts nums in place
quick_sort(nums, 0, len(nums) - 1) # also in place
sorted_nums = merge_sort(nums) # returns a new listIn an interview, the answer above is enough. But if you want to stand out, mention that Python's built-in sorted() and list.sort() use Timsort, a hybrid of merge sort and insertion sort. That's why you almost never write a sort from scratch in production Python.
Several algorithms can be used to find the shortest path in graphs.
For unweighted graphs, breadth-first search effectively explores nodes layer by layer. In weighted graphs with non-negative edges, Dijkstra's algorithm identifies the shortest path by examining the nearest vertex first.
The A* search algorithm improves efficiency by using heuristics to estimate remaining costs. The choice of algorithm depends on the graph's characteristics and the specific problem requirements.
Let's explore some advanced interview questions for those seeking more senior roles or aiming to demonstrate a deep knowledge of specialized or complex data structures.
Dynamic programming is a method used to solve complex problems by dividing them into smaller overlapping subproblems. Instead of starting from scratch each time, you keep track of the solutions to those smaller parts, which means you don’t have to do the same calculations repeatedly.
This method is very useful for finding the longest common subsequence between two strings or finding the minimum cost to reach a specific point on a grid.
B-trees are balanced tree data structures designed for efficient disk access. Some of its features are:
They offer several advantages over binary search trees:
Topological sorting is an algorithm used for ordering the vertices of a directed acyclic graph (DAG) such that if there is an edge from vertex u to vertex v, then u appears before v in the order. It's commonly used in task scheduling — determining the order tasks must run in to respect their dependencies — and in build systems, package managers, and course prerequisite planning.
A min-heap is a specific implementation of a priority queue and is defined as a complete binary tree where the value of each node is less than or equal to the values of its children, allowing for efficient operations when finding and extracting the minimum element.
On the other hand, a priority queue is an abstract data structure that permits the insertion of elements with an associated priority, with elements being dequeued in order of their priority. Min-heaps are a common way to implement priority queues due to their ability to manage these operations efficiently.
A disjoint-set data structure, also known as a union-find data structure, maintains a collection of disjoint sets. This data structure supports two primary operations:
There are many applications of disjoint sets, but the most common ones are Kruskal's algorithm for finding the minimum spanning tree of a graph and the network flow problem for determining connected components within a graph.
A segment tree is a data structure designed to facilitate efficient range queries and updates on an array. It is particularly useful for scenarios where we need to repeatedly perform operations such as finding the sum, minimum, maximum, or greatest common divisor over a specific range of elements in the array.
It is constructed as a binary tree, where each node represents a segment of the array. The leaves of the tree correspond to individual elements of the array, while internal nodes store information that aggregates the values of their child nodes according to the operation being performed. They achieve O(log n) time complexity for both updates and queries.
A suffix tree stores every suffix of a string so that pattern queries can be answered in time proportional to the pattern length, not the length of the text. A true suffix tree uses edge compression to achieve O(n) space and is typically built with Ukkonen's algorithm — but that's complex enough that interviewers rarely expect you to code it from scratch in 45 minutes.
A common compromise is the simpler suffix trie, which stores one character per node. It uses O(n²) space but is much easier to write and explain. The trick in an interview is to know the tradeoff and signal it explicitly.
Here's a clean Python implementation:
class SuffixTrieNode:
def __init__(self):
self.children = {} # Map of character -> child node
self.indices = [] # Starting positions of suffixes passing through this node
class SuffixTrie:
def __init__(self, text):
self.root = SuffixTrieNode()
self.text = text + "$" # Append a unique terminator
self._build()
def _build(self):
"""Insert every suffix of the text into the trie."""
for i in range(len(self.text)):
self._insert_suffix(i)
def _insert_suffix(self, index):
node = self.root
for i in range(index, len(self.text)):
c = self.text[i]
if c not in node.children:
node.children[c] = SuffixTrieNode()
node = node.children[c]
node.indices.append(index)
def search(self, pattern):
"""Return all starting positions where `pattern` appears in the text."""
node = self.root
for c in pattern:
if c not in node.children:
return []
node = node.children[c]
return node.indicesQuadtrees are a hierarchical tree data structure that recursively subdivides a two-dimensional space into four equal quadrants. This spatial partitioning technique is highly effective for applications like image processing, collision detection in games, and geographic information systems for efficient spatial data storage and retrieval.
Demonstrating your data structure knowledge is important, but showcasing that you know when to use them properly will make you stand out in your interview. In this section, we’ll review how to apply your data structure knowledge to practical situations.
Due to the problem's real-time nature, this challenge will require efficient data structures.
In my experience, I’d use quadtrees for geographical data, priority queues to rank potential matches based on distance and rider urgency, and hash tables for efficient lookups of driver and rider locations.
We can leverage a combination of data structures to effectively recommend products based on user behavior.
A sparse user-item matrix would store user-product interactions, while hash tables would efficiently map users and items. Priority queues would rank recommendations, and graph structures could model user-item relationships for more sophisticated analyses like community detection.
A graph data structure can be highly effective for detecting and removing spam accounts on a social networking platform. You can analyze the network topology by representing users as nodes and their connections as edges. Identifying densely connected clusters, isolated nodes, and sudden spikes in activity can help flag suspicious accounts.
I would use a combination of data structures in a real-time chat application.
Hash tables would store user IDs and their corresponding connection lists, enabling quick lookups of users to send messages to. Queues would be implemented for each user to maintain the order of messages, ensuring they are delivered in the sequence they were sent. Additionally, trees, such as AVL trees, could be used to efficiently store and retrieve users' online/offline status, allowing for real-time updates on user availability.
For a spell checker, efficient word lookup is very important. A trie would be an ideal data structure. Each node in the trie would represent a letter, and paths through the trie would form words. This allows for fast prefix-based searches, enabling the spell checker to suggest corrections for misspelled words quickly.
In this particular scenario, segment trees stand out as an excellent choice. They are very good at handling range queries and updates efficiently. We can represent the game map as a 1D array, where each element corresponds to a grid cell. Each cell can store information about the presence or absence of a structure.
I know that preparing for a data structures interview can be challenging, but a structured approach can help you make it more manageable!
Focus on mastering the fundamental concepts behind data structures, such as arrays, linked lists, stacks, queues, trees, graphs, and hash tables. Understand their principles, how they manage data, and the time complexities associated with operations like insertion, deletion, and search.
Knowing the concepts is good but not enough. You should know how to implement these data structures from scratch. You can engage with DataCamp courses to take advantage of coding challenges that sharpen your problem-solving skills.
Understanding the trade-offs between data structures is key. For example, arrays allow quick access but can be costly for insertions and deletions, while linked lists offer efficient modifications but require traversal for access. Be prepared to discuss these trade-offs during your interview.
Remember, communication is just as important as code. Interviewers look for candidates who can adapt their explanations to the audience. As discussed in the DataFramed podcast regarding the future of data roles:
You need to be able to deliver any type of insight in a way that a six-year-old could understand and in a way that would satisfy me or even someone even more technical. So if you really know your stuff, you can really dumb it down, but you can also make it so complicated that, honestly, only the people who are really, really up there in terms of technical expertise can understand.
Mo Chen, Data & Analytics Manager at NatWest Group
Supercharge your career as a professional data scientist.

Learn more about data structures and the basics of Python with these courses!
Course
Course
Course
blog
Maria Eugenia Inzaugarat
15 min
blog
Abid Ali Awan
15 min
blog
Kevin Babitz
14 min
blog
Kurtis Pykes
15 min
blog
Vikash Singh
15 min
blog
Abid Ali Awan
15 min
