Courses
Python中級
4時間
1.4M
基本的なデータ構造を理解していることを示すには、中核となる構造とその実装に強い自信が必要です。次のような質問は、これらの考え方を説明し、知識を示す力を試します。
データ構造は次のように分類されます。
配列と連結リストは、要素の集合を格納する二つの方法ですが、動作が異なります。主な違いは次のとおりです。
スタックは、末端(トップ)で要素の追加と削除を行う順序付きリストです。後入れ先出し(LIFO)の原則に従い、最後に追加した要素が最初に取り出されます。
スタックは、式の評価、バックトラッキング、メモリ管理、関数の呼び出しと復帰など、さまざまな用途に使われます。
Pythonでは、リストをそのままスタックとして使えます。append()がプッシュ、pop()がトップの取り出しです。
my_stack = []
item = 1
my_stack.append(item)
my_stack.pop()トップの位置をインデックスで管理することで、これらの操作を素早く効率的に実行できます。
キューは先入れ先出し(FIFO)の構造です。店の行列のように、後ろから入り、前から出ていきます。
Pythonでは、次のような方法でキューを実装できます。
配列(リスト)を使い、append()とpop()を活用する方法:
my_queue = []
item = 1
# Enqueue
my_queue.append(item)
# Dequeue
my_queue.pop(0)collectionsライブラリのdeque()を使う方法。append()やpop()がリストより高速です:
from collections import deque
my_queue = deque()
item = 1
# Enqueue
my_queue.append(item)
# Dequeue
my_queue.popleft()組み込みモジュールqueue.Queueを使う方法:
from queue import Queue
my_queue = Queue(maxsize = 3)
# Enqueue
my_queue.put(item)
# Dequeue
my_queue.get()二分木は各ノードが最大で二つの子(左と右)を持つデータ構造です。二分探索木(BST)は、その中でも特定の順序性を持つものです。各ノードについて、左部分木のすべてのキーは小さく、右部分木のすべてのキーは大きく、両部分木もBSTになっています。
これらの性質により、検索・挿入・削除といった操作を効率的に行え、平衡が保たれていれば一般に計算量はO(log n)になります。
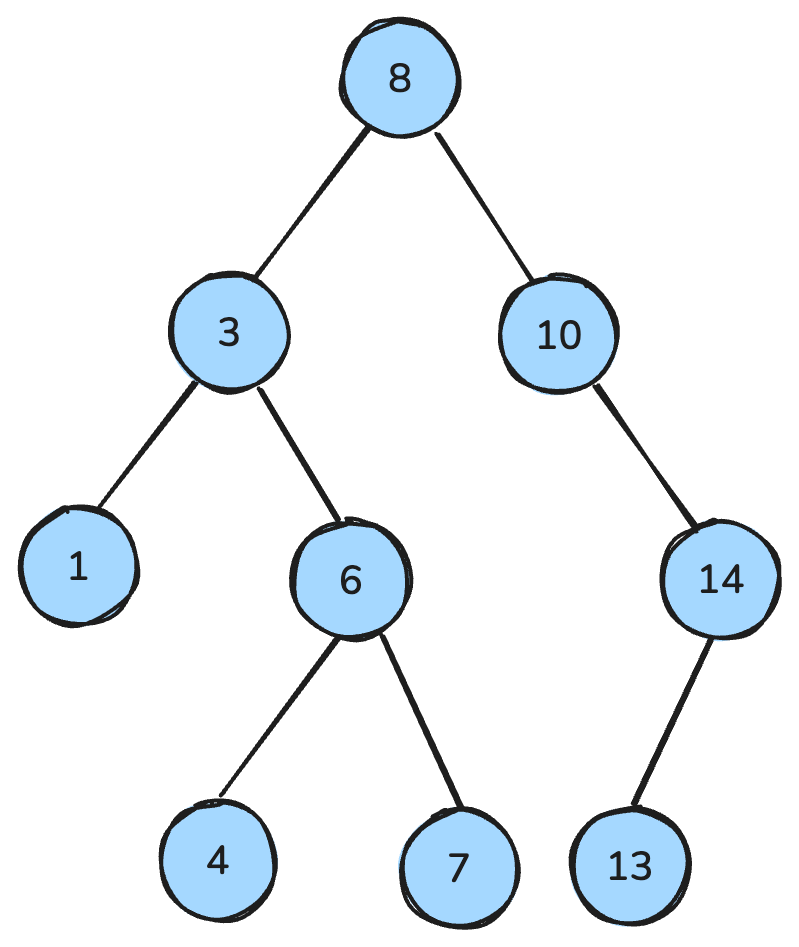
二分探索木。画像:著者作成。
ハッシュ化は、任意の大きさのデータを、ハッシュ関数を用いて固定長の値(ハッシュ値)に変換する手法です。
一般的な用途の一つがハッシュテーブルで、配列内の特定位置にキーを対応づけ、データの高速な検索・取得を可能にします。暗号におけるパスワードの保護から、重複排除によるデータの整理まで、多様な応用があります。
ヒープは木に似たデータ構造で、特別な規則に従います。
最大ヒープでは各親がその子以上の値を持ち、最小ヒープでは各親がその子以下の値を持ちます。
ヒープは優先度付きキューの実装にしばしば使われ、重要度や値に基づいて要素を並べ替えます。ヒープソートの基盤としても重要で、効率的なデータ整列手法です。
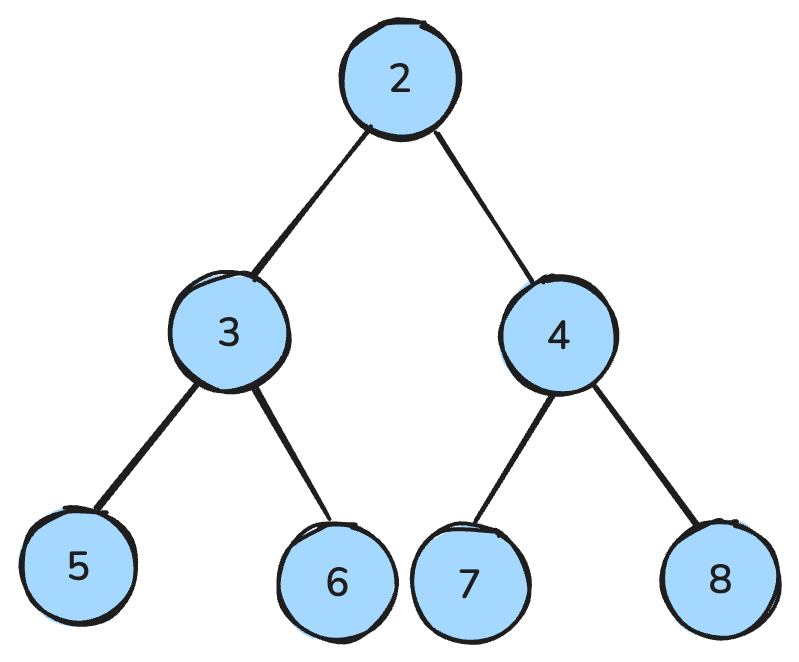
最小ヒープでは、すべての親ノードが子ノードより小さくなります——画像:著者作成。
基礎を押さえたら、次は実装や活用の技術力を問う中級レベルの質問に進みましょう。
平衡二分探索木は、左右の部分木の高さが概ね等しく保たれます。BSTの平衡化は、検索・挿入・削除を効率的に保つために非常に重要です。
AVL木や赤黒木といった手法が自己平衡化に広く用いられます。AVL木は任意のノードで左右部分木の高さ差を最大1に保ち、赤黒木はより厳密なバランス制約を持ちます。
最小ヒープは通常リストで裏付けられます。主要な操作はinsert(要素を追加してヒープ性を回復するため上方へバブルアップ)とextract_min(根を削除して順序を回復するため下方へシフト)です。
class MinHeap:
def __init__(self):
self.heap = []
def __len__(self): # Get the size of the heap
return len(self.heap)
def __parent(self, i): # Get the parent index
return (i - 1) // 2
def __left(self, i): # Get the left child index
return 2 * i + 1
def __right(self, i): # Get the right child index
return 2 * i + 2
def __swap(self, i, j): # Swap two elements
self.heap[i], self.heap[j] = self.heap[j], self.heap[i]
def __heapify_up(self, i): # Restore min-heap property after insertion
while i > 0 and self.heap[i] < self.heap[self.__parent(i)]:
self.__swap(i, self.__parent(i))
i = self.__parent(i)
def __heapify_down(self, i): # Restore min-heap property after extraction
while True:
smallest = i
left = self.__left(i)
right = self.__right(i)
if left < len(self) and self.heap[left] < self.heap[smallest]:
smallest = left
if right < len(self) and self.heap[right] < self.heap[smallest]:
smallest = right
if smallest != i:
self.__swap(i, smallest)
i = smallest
else:
break
def insert(self, val): # Insert a value into the heap
self.heap.append(val)
self.__heapify_up(len(self) - 1)
def extract_min(self): # Extract the minimum value from the heap
if not self.heap:
return None
min_val = self.heap[0]
self.heap[0] = self.heap[-1]
self.heap.pop()
self.__heapify_down(0)
return min_valトライ(prefix treeとも)は、文字列の検索や接頭辞一致を効率化するための木構造です。
各ノードが1文字を表し、根からノードへの経路が完全な文字列に対応します。オートコンプリート、スペルチェック、辞書の実装などで広く用いられます。
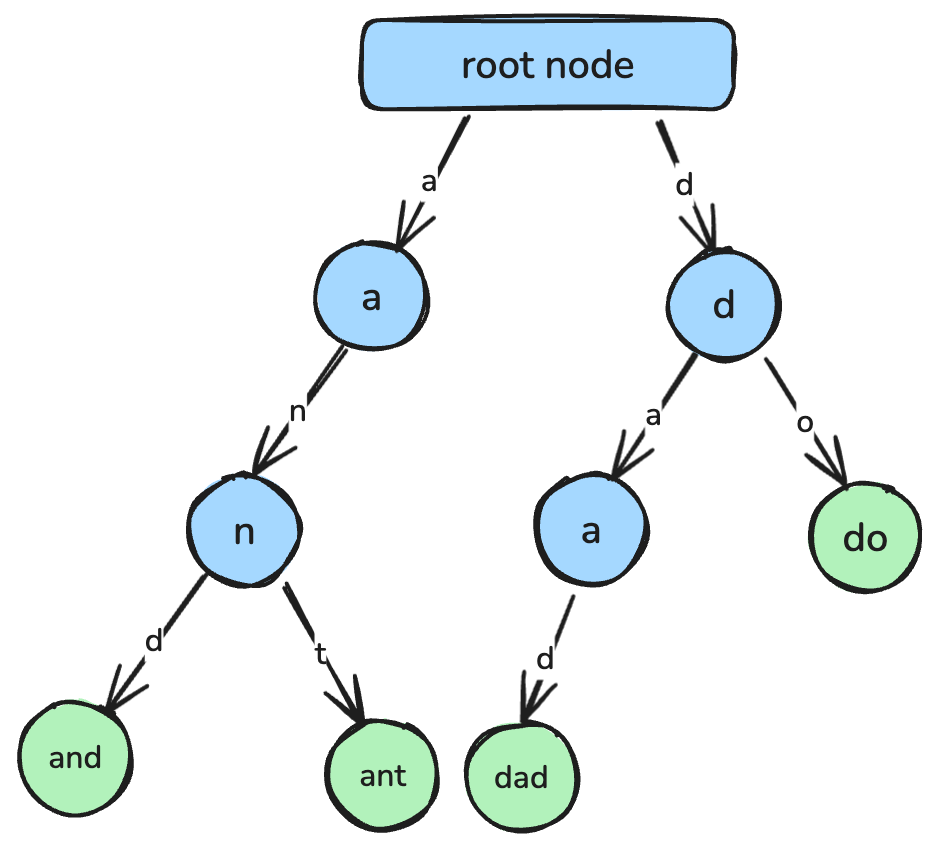
各ノードが1文字で、連結して文字列を形成するトライ。画像:著者作成。
衝突とは、異なる二つのキーが同じインデックスにハッシュされることです。
解決方法として、チエイニング(該当インデックスに連結リストで格納)や、オープンアドレッシング(線形探索、二次探索、ダブルハッシュなどで配列内の次の空きスロットを探す)があります。
グラフは、頂点(ノード)とそれらを結ぶ辺から成るデータ構造です。さまざまな実体間の関係や接続を表現するのに有用です。
深さ優先探索(DFS)は、バックトラックする前に各分岐を深くまで辿るアルゴリズムです。明示的なスタックか再帰で実装できます。計算量はO(V + E)で、頂点数Vと辺数Eに対して全てを調べる可能性があります。
幅優先探索(BFS)は、現在の深さのノードをすべて探索してから次のレベルに進みます。非重み付きグラフで最短経路を見つけるのに有効で、通常はキューで実装します。DFS同様に計算量はO(V + E)です。
ソートアルゴリズムは効率的なデータ処理に不可欠です。検索の高速化、データ分析の向上、可視化の容易化をもたらします。選択時には、次のような主要なトレードオフを念頭に置きましょう。
それぞれのクリーンなPython実装は次のとおりです。
# Bubble sort — sorts in place
def bubble_sort(arr):
n = len(arr)
for i in range(n):
for j in range(0, n - i - 1):
if arr[j] > arr[j + 1]:
arr[j], arr[j + 1] = arr[j + 1], arr[j]
# Quick sort — sorts in place
def partition(arr, low, high):
pivot = arr[high]
i = low - 1
for j in range(low, high):
if arr[j] <= pivot:
i += 1
arr[i], arr[j] = arr[j], arr[i]
arr[i + 1], arr[high] = arr[high], arr[i + 1]
return i + 1
def quick_sort(arr, low, high):
if low < high:
pi = partition(arr, low, high)
quick_sort(arr, low, pi - 1)
quick_sort(arr, pi + 1, high)
# Merge sort — returns a new sorted list
def merge(left, right):
result = []
i = j = 0
while i < len(left) and j < len(right):
if left[i] <= right[j]:
result.append(left[i])
i += 1
else:
result.append(right[j])
j += 1
result.extend(left[i:])
result.extend(right[j:])
return result
def merge_sort(arr):
if len(arr) <= 1:
return arr
mid = len(arr) // 2
left_half = merge_sort(arr[:mid])
right_half = merge_sort(arr[mid:])
return merge(left_half, right_half)nums = [3, 1, 4, 1, 5, 9, 2, 6]
bubble_sort(nums) # sorts nums in place
quick_sort(nums, 0, len(nums) - 1) # also in place
sorted_nums = merge_sort(nums) # returns a new list面接では、上の回答で十分です。さらに一歩進めるなら、Pythonの組み込みsorted()とlist.sort()がTimsort(マージソートと挿入ソートのハイブリッド)を用いている点に触れましょう。実務のPythonで一からソートを書くことがほとんどない理由です。
グラフの最短経路問題には複数のアルゴリズムが使えます。
非重み付きグラフでは、幅優先探索が層ごとにノードを効果的に探索します。 非負重みのあるグラフでは、ダイクストラ法が最も近い頂点から調べて最短経路を見つけます。
A*探索はヒューリスティクスで残りコストを見積もり、効率を高めます。どのアルゴリズムを選ぶかは、グラフの特性と要件に依存します。
よりシニアな役割を目指す方や、専門的・複雑なデータ構造の深い知識を示したい方のために、上級の質問を見ていきます。
動的計画法は、複雑な問題を重複する小問題に分割して解く手法です。毎回最初から計算するのではなく、小問題の解を記録して再利用し、同じ計算の繰り返しを避けます。
二つの文字列の最長共通部分列の算出や、グリッド上で特定地点に到達する最小コストの算出などで非常に有用です。
B木は、ディスクアクセスを効率化するために設計された平衡木のデータ構造です。主な特徴は次のとおりです。
二分探索木に対する利点は次のとおりです。
トポロジカルソートは、有向非巡回グラフ(DAG)の頂点を、頂点uから頂点vへの辺があるなら、順序においてuがvより先に現れるように並べるアルゴリズムです。依存関係を尊重したタスクの実行順序決定(スケジューリング)、ビルドシステム、パッケージマネージャ、履修必修関係の計画などで用いられます。
最小ヒープは優先度付きキューの一実装で、完全二分木として定義され、各ノードの値がその子の値以下であるため、最小要素の探索・抽出が効率的です。
一方、優先度付きキューは抽象データ構造で、優先度付きで要素を挿入し、優先度順に取り出します。最小ヒープは、これらの操作を効率的に扱えるため、優先度付きキューの実装として一般的です。
互いに素な集合データ構造(ユニオンファインドとも)は、互いに交わらない集合の集まりを管理します。主な操作は二つです。
代表的な応用には、グラフの最小全域木を求めるクラスカル法や、ネットワークフロー問題における連結成分の判定などがあります。
セグメント木は、配列に対する範囲クエリや更新を効率化するためのデータ構造です。配列内の特定範囲について、合計、最小、最大、最大公約数などの演算を繰り返し行う場面で有用です。
二分木として構築され、各ノードが配列の一つの区間を表します。葉は個々の要素に対応し、内部ノードは子ノードの値を対象の演算に応じて集約した情報を保持します。更新とクエリのいずれも計算量はO(log n)を達成します。
サフィックスツリーは文字列の全ての接尾辞を格納し、テキスト長ではなくパターン長に比例した時間での照合を可能にします。真のサフィックスツリーは辺の圧縮でO(n)空間を実現し、通常はUkkonenのアルゴリズムで構築しますが、45分の面接で一からの実装を期待されることはまれです。
一般的な折衷案は、より単純なサフィックストライです。各ノードに1文字を格納し、空間はO(n²)ですが、はるかに書きやすく説明もしやすいです。面接では、このトレードオフを理解し、明確に伝えることが肝要です。
以下は簡潔なPython実装です。
class SuffixTrieNode:
def __init__(self):
self.children = {} # Map of character -> child node
self.indices = [] # Starting positions of suffixes passing through this node
class SuffixTrie:
def __init__(self, text):
self.root = SuffixTrieNode()
self.text = text + "$" # Append a unique terminator
self._build()
def _build(self):
"""Insert every suffix of the text into the trie."""
for i in range(len(self.text)):
self._insert_suffix(i)
def _insert_suffix(self, index):
node = self.root
for i in range(index, len(self.text)):
c = self.text[i]
if c not in node.children:
node.children[c] = SuffixTrieNode()
node = node.children[c]
node.indices.append(index)
def search(self, pattern):
"""Return all starting positions where `pattern` appears in the text."""
node = self.root
for c in pattern:
if c not in node.children:
return []
node = node.children[c]
return node.indices四分木は、二次元空間を四つの等しい象限に再帰的に分割する階層的な木構造です。この空間分割手法は、画像処理、ゲームにおける衝突判定、地理情報システムでの空間データの効率的な格納・検索などに非常に有効です。
データ構造の知識を示すことも重要ですが、適切に使い分けられることを示せれば面接で一歩抜きん出ます。本セクションでは、実践的な状況にデータ構造の知識をどう適用するかを見ていきます。
問題がリアルタイム性を持つため、効率的なデータ構造が必要です。
私なら、地理データには四分木、距離や緊急度に基づく候補の順位付けには優先度付きキュー、ドライバーやライダーの位置情報の高速ルックアップにはハッシュテーブルを使います。
ユーザー行動に基づく推薦には、複数のデータ構造を組み合わせると効果的です。
ユーザー–アイテムの疎行列で相互作用を保持し、ハッシュテーブルでユーザーやアイテムを効率的にマッピングします。優先度付きキューで推薦を順位付けし、グラフ構造でユーザー–アイテム関係をモデル化して、コミュニティ検出のような高度な分析に活用します。
グラフデータ構造が非常に有効です。ユーザーをノード、つながりをエッジとしてネットワークのトポロジーを分析します。高密度クラスター、孤立ノード、活動の急増を特定することで、不審アカウントを検知できます。
リアルタイムチャットでは複数のデータ構造を組み合わせます。
ハッシュテーブルでユーザーIDと対応する接続リストを保持し、宛先ユーザーの高速ルックアップを実現します。各ユーザーにキューを用意してメッセージ順序を維持し、送信順に配信します。加えて、AVL木などの木構造でオンライン/オフライン状態を効率的に管理し、可用性をリアルタイムに更新します。
スペルチェッカーでは単語の高速検索が非常に重要です。トライが理想的です。各ノードが文字を表し、経路が単語を形成します。接頭辞に基づく高速検索が可能になり、誤綴りの候補提示を迅速に行えます。
このシナリオではセグメント木が優れた選択肢です。範囲クエリと更新を効率的に処理できます。ゲームマップを1次元配列として表し、各要素をグリッドセルに対応づけ、構造物の有無などの情報を格納します。
データ構造の面接準備は大変に思えるかもしれませんが、体系的に取り組めばずっと取り組みやすくなります。
配列、連結リスト、スタック、キュー、木、グラフ、ハッシュテーブルなど、データ構造の基本概念をしっかり身につけてください。原理、データの扱い方、挿入・削除・検索といった操作の計算量を理解しましょう。
概念の理解だけでは十分ではありません。これらのデータ構造を一から実装できることが重要です。 DataCampのコースで、問題解決力を鍛えるコーディング課題に取り組んでみてください。
データ構造間のトレードオフを理解することが鍵です。例えば、配列は高速アクセスが可能な一方、挿入や削除は高コストになりがちです。連結リストは変更が効率的ですが、アクセスには走査が必要です。面接では、これらのトレードオフについて説明できるように準備してください。
また、コードと同じくらいコミュニケーションも重要です。面接官は、相手に合わせて説明を調整できる人を重視します。データ職の将来について議論したDataFramedポッドキャストでも触れられているとおりです。
どんな種類のインサイトでも、6歳の子どもにわかるように伝えることも、私やさらに技術に精通した人を満足させる形でも伝えられなければなりません。本当に理解していれば、平易にも、そして正直言って高度な専門家だけが理解できるほど複雑にも説明できます。
Mo Chen, Data & Analytics Manager at NatWest Group
次のコースでデータ構造とPythonの基礎をさらに学びましょう!
Courses
Courses
Courses