Kurs
R'de Supervised Learning: Sınıflandırma
4 sa
100.7K
Sınıflandırma, modelin verilen bir girdi verisinin doğru etiketini tahmin etmeye çalıştığı denetimli bir makine öğrenmesi yöntemidir. Sınıflandırmada model, eğitim verisi kullanılarak tamamen eğitilir ve yeni, görülmemiş verilerde tahmin yapmadan önce test verisi üzerinde değerlendirilir.
Örneğin, bir algoritma aşağıda gösterildiği gibi, bir e-postanın spam olup olmadığını (spam değil: ham) öğrenerek tahmin edebilir.
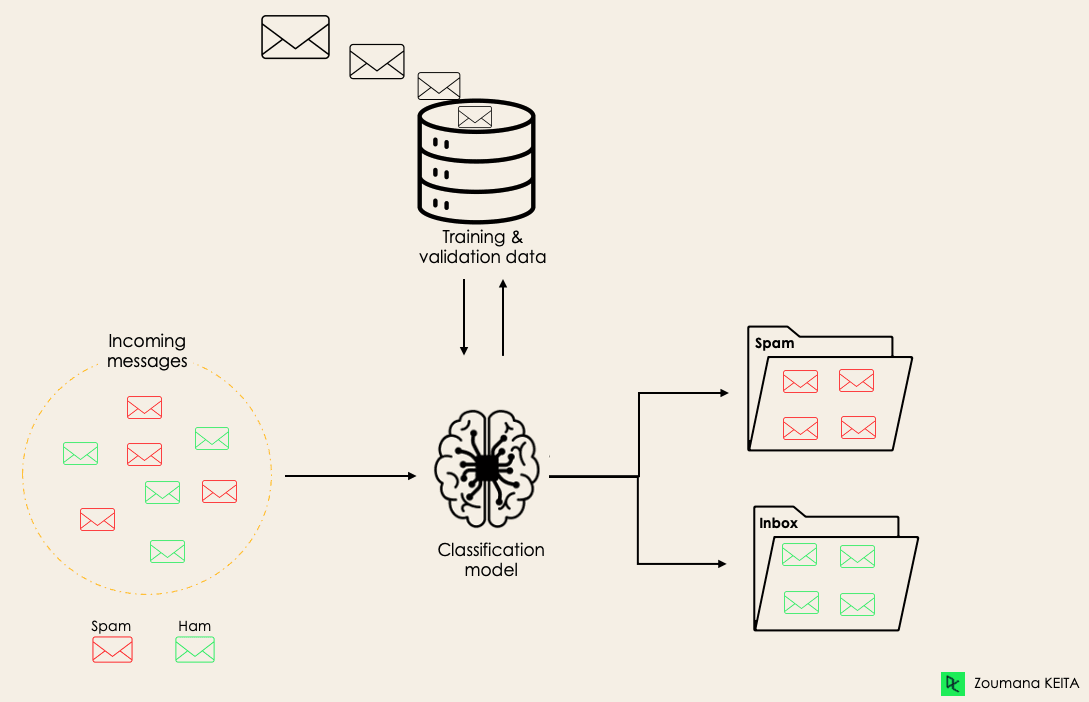 Sınıflandırma kavramına dalmadan önce, sınıflandırmadaki iki öğrenici türü olan tembel ve atak öğreniciler arasındaki farkı anlayacağız. Ardından sınıflandırma ile regresyon arasındaki yanlış anlaşılmayı netleştireceğiz.
Sınıflandırma kavramına dalmadan önce, sınıflandırmadaki iki öğrenici türü olan tembel ve atak öğreniciler arasındaki farkı anlayacağız. Ardından sınıflandırma ile regresyon arasındaki yanlış anlaşılmayı netleştireceğiz.
Makine öğrenmesi sınıflandırmasında iki tür öğrenici vardır: tembel ve atak öğreniciler.
Atak öğreniciler, gelecekteki veri kümeleri için herhangi bir tahmin yapmadan önce eğitim veri setinden bir model oluşturan makine öğrenmesi algoritmalarıdır. Ağırlıkları öğrenerek eğitim sırasında daha iyi genelleme elde etme istekliliklerinden dolayı eğitim sürecinde daha fazla zaman harcarlar, ancak tahmin yapmak için daha az zamana ihtiyaç duyarlar.
Makine öğrenmesi algoritmalarının çoğu atak öğrenicidir ve aşağıda bazı örnekler yer almaktadır:
Tembel öğreniciler veya örnek-temelli öğreniciler ise eğitim verisinden hemen bir model oluşturmaz; tembellik de buradan gelir. Eğitim verisini ezberlerler ve her tahmin gerektiğinde, tüm eğitim verisi içinden en yakın komşuları ararlar; bu da tahmin sırasında çok yavaş olmalarına neden olur. Bu türe bazı örnekler:
Ancak, BallTree ve KDTree gibi bazı algoritmalar, tahmin gecikmesini iyileştirmek için kullanılabilir.
Makine Öğrenmesi algoritmalarının dört ana kategorisi vardır: denetimli, denetimsiz, yarı denetimli ve pekiştirmeli öğrenme.
Sınıflandırma ve regresyon her ikisi de denetimli öğrenme kategorisinde yer alsa da aynı şey değillerdir.
Sınıflandırma hakkında daha fazla bilgi edinmek isterseniz, scikit-learn ile Denetimli Öğrenme ve R ile Denetimli Öğrenme kursları faydalı olabilir. Bu kurslar, her algoritmanın görevleri nasıl ele aldığını ve bunları uygulamak için gereken Python ve R fonksiyonlarını daha iyi anlamanızı sağlar.
Regresyona ilişkin olarak, R'de Regresyona Giriş ve Python'da statsmodels ile Regresyona Giriş, farklı regresyon modeli türlerini ve bunların R ve Python'daki uygulamalarını keşfetmenize yardımcı olacaktır.
 Gerçek Hayatta Makine Öğrenmesi Sınıflandırma Örnekleri
Gerçek Hayatta Makine Öğrenmesi Sınıflandırma Örnekleri Denetimli Makine Öğrenmesi Sınıflandırmasının günlük hayatımızın farklı alanlarında çeşitli uygulamaları vardır. Aşağıda bazı örnekler yer alıyor.
Makine öğrenmesi modelini geçmiş hasta verileriyle eğitmek, sağlık uzmanlarına tanılarını doğru şekilde analiz etmede yardımcı olabilir:
Eğitim, en fazla metin, video ve ses verisiyle uğraşan alanlardan biridir. Bu yapılandırılmamış bilgiler, Doğal Dil teknolojilerinin yardımıyla şu gibi farklı görevler için analiz edilebilir:
Ulaşım, birçok ülkenin ekonomik kalkınmasının kilit bileşenidir. Bu nedenle, sektörler makine ve derin öğrenme modellerini kullanıyor:
Tarım, insan yaşamının en değerli dayanaklarından biridir. Sürdürülebilirliğin entegre edilmesi, çevreye zarar vermeden çiftçilerin verimliliğini farklı bir düzeyde artırmaya yardımcı olabilir:
Makine öğrenmesinde dört ana sınıflandırma görevi vardır: ikili, çok sınıflı, çok etiketli ve dengesiz sınıflandırmalar.
İkili sınıflandırma görevinde amaç, girdi verisini birbirini dışlayan iki kategoriye ayırmaktır. Bu durumda eğitim verisi, ele alınan probleme bağlı olarak ikili biçimde etiketlenir: doğru ve yanlış; pozitif ve negatif; 0 ve 1; spam ve spam değil vb. Örneğin, bir görselin kamyon mu yoksa tekne mi olduğunu tespit etmek isteyebiliriz.
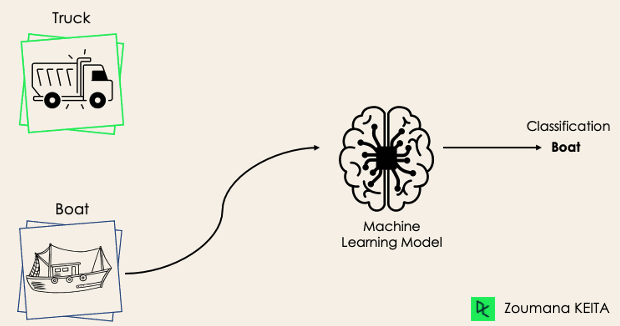
Lojistik Regresyon ve Destek Vektör Makineleri algoritmaları doğası gereği ikili sınıflandırmalar için tasarlanmıştır. Ancak K-En Yakın Komşu ve Karar Ağaçları gibi diğer algoritmalar da ikili sınıflandırma için kullanılabilir.
Çok sınıflı sınıflandırmada ise en az iki adet birbirini dışlayan sınıf etiketi vardır ve amaç, verilen bir girdi örneğinin hangi sınıfa ait olduğunu tahmin etmektir. Aşağıdaki durumda model, görseli doğru şekilde uçak olarak sınıflandırmıştır.
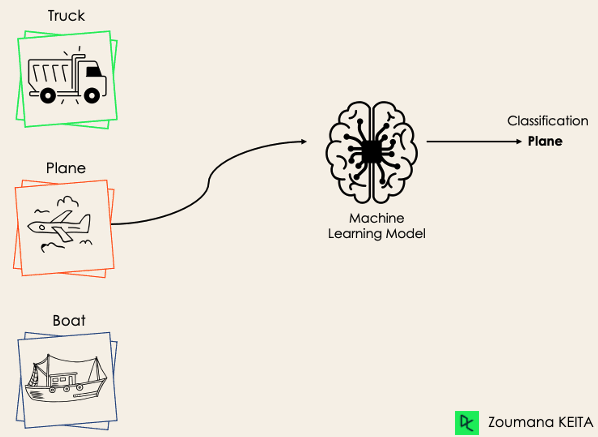
Çoğu ikili sınıflandırma algoritması çok sınıflı sınıflandırma için de kullanılabilir. Bu algoritmalar şunları içerir ancak bunlarla sınırlı değildir:
Ama durun! SVM ve Lojistik Regresyonun varsayılan olarak çok sınıflı sınıflandırmayı desteklemediğini söylememiş miydiniz?
→ Doğru. Ancak, özgün ikili sınıflandırma algoritmalarını çok sınıflı sınıflandırma görevlerine uyarlamak için birer-birine ve birer-türe (one-versus-one, one-versus-all) gibi ikili dönüştürme yaklaşımlarını uygulayabiliriz.
Birer-birine (one-versus-one): Bu strateji, etiket çiftleri sayısı kadar sınıflandırıcı eğitir. 3 sınıflı bir sınıflandırmada üç etiket çifti, dolayısıyla aşağıda gösterildiği gibi üç sınıflandırıcı olur.
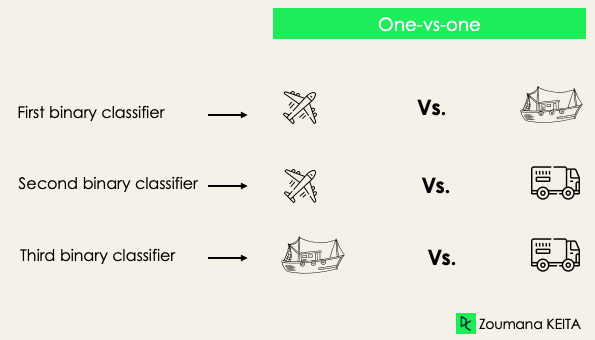
Genel olarak N etiket için Nx(N-1)/2 sınıflandırıcı olur. Her sınıflandırıcı tek bir ikili veri seti üzerinde eğitilir ve nihai sınıf, tüm sınıflandırıcılar arasındaki çoğunluk oyu ile tahmin edilir. Birer-birine yaklaşımı, SVM ve diğer çekirdek (kernel) tabanlı algoritmalar için en iyi sonucu verir.
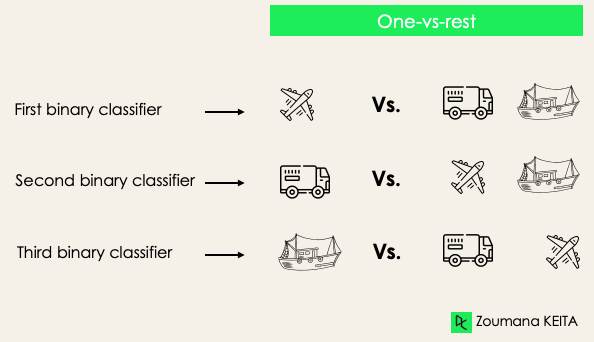
Birer-türe (one-versus-rest): Bu aşamada, her etiketi bağımsız bir etiket olarak ele alır ve geri kalanını tek bir etiket olarak birleştiririz. 3 sınıfta üç sınıflandırıcımız olur.
Genel olarak N etiket için N ikili sınıflandırıcı olur.
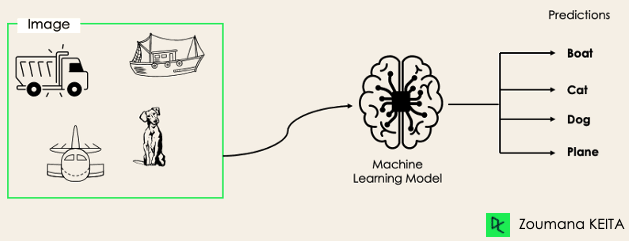
Çok etiketli sınıflandırma görevlerinde, her girdi örneği için 0 veya daha fazla sınıfı tahmin etmeye çalışırız. Bu durumda karşılıklı dışlama yoktur, çünkü girdi örneği birden fazla etikete sahip olabilir.
Böyle bir senaryo, bir metnin birden fazla konu içerebildiği Doğal Dil İşleme'de otomatik etiketleme gibi farklı alanlarda görülebilir. Benzer şekilde bilgisayarla görmede bir görsel, aşağıda gösterildiği gibi birden fazla nesne içerebilir: model görselde uçak, tekne, kamyon ve köpek olduğunu tahmin etmiştir.
Çok sınıflı veya ikili sınıflandırma modellerini kullanarak çok etiketli sınıflandırma yapmak mümkün değildir. Ancak bu standart sınıflandırma görevlerinde kullanılan çoğu algoritmanın, çok etiketli sınıflandırma için özelleştirilmiş sürümleri vardır. Örneğin:
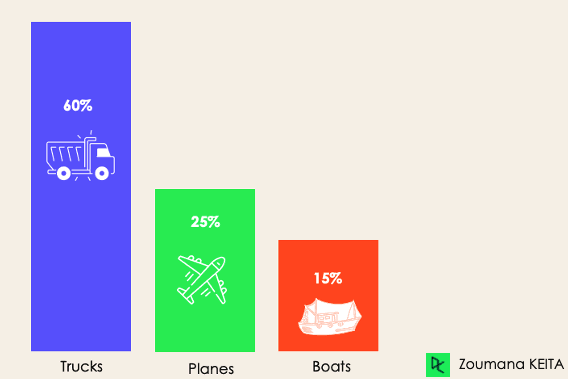
Dengesiz sınıflandırmada, her sınıftaki örnek sayısı eşit dağılmamıştır; yani eğitim verisinde bazı sınıflardan diğerlerine göre daha fazla olabilir. Aşağıdaki 3 sınıflı sınıflandırma senaryosunda eğitim verisinin %60 kamyon, %25 uçak ve %15 tekne içerdiğini düşünelim.
Dengesiz sınıflandırma problemi şu senaryolarda ortaya çıkabilir:
Karar Ağaçları, Lojistik Regresyon vb. geleneksel kestirim modellerini dengesiz bir veri kümesiyle kullanmak etkili olmayabilir; çünkü bu modeller, en fazla gözleme sahip sınıfı tahmin etmeye meyilli olup, sayısı az olanları gürültü olarak görebilirler.
Öyleyse bu tür problemler göz ardı mı ediliyor?
Elbette hayır! Bir veri kümesindeki dengesizlik problemini çözmek için birden fazla yaklaşım kullanılabilir. En yaygın yaklaşımlar arasında örnekleme teknikleri ve maliyet-duyarlı algoritmaların gücünden yararlanma yer alır.
Bu teknikler, orijinal dağılımı dengelemeyi amaçlar:
Bu algoritmalar, yanlış sınıflandırmanın maliyetini dikkate alır. Amaçları, modellerin ürettiği toplam maliyeti en aza indirmektir.
Artık farklı sınıflandırma modeli türlerine dair bir fikrimiz olduğuna göre, bu modeller için doğru değerlendirme ölçütlerini seçmek kritik öneme sahiptir. Bu bölümde en yaygın kullanılan ölçütleri ele alacağız: doğruluk, kesinlik (precision), duyarlılık (recall), F1 skoru ve ROC (Receiver Operating Characteristic) eğrisi altındaki alan ile AUC (Area Under the Curve).



Artık bazı algoritmaların uygulanmasına geçmek için gereken tüm araçlara sahibiz. Bu bölümde, daha önce ele alınan kavramları —özellikle ikili sınıflandırma göreviyle dengesiz veri kümeleri için— örneklemek üzere dört algoritmayı ve bunların kredi veri seti üzerindeki uygulamasını ele alacağız. Sadelik adına yalnızca dört algoritmaya odaklanacağız.
Amaç en iyi modeli elde etmek değil, aşağıdaki her bir algoritmanın nasıl eğitileceğini göstermektir. Kaynak kodu DataLab'de mevcuttur; tek tıkla her şeyi çalıştırabilirsiniz.
import pandas as pd
loan_data = pd.read_csv("loan_data.csv")
loan_data.head()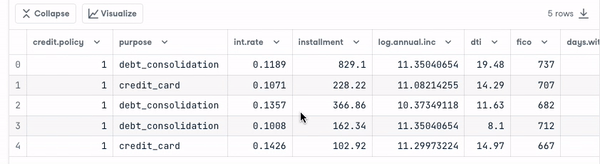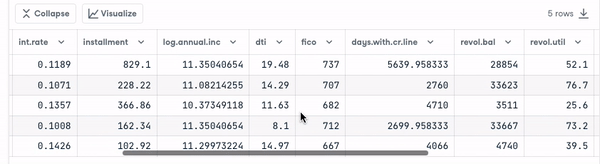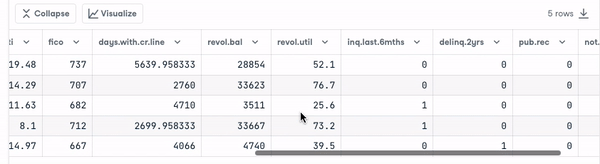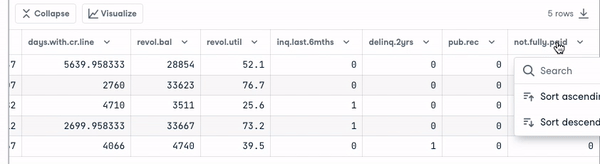
import matplotlib.pyplot as plt
# Helper function for data distribution
# Visualize the proportion of borrowers
def show_loan_distrib(data):
count = ""
if isinstance(data, pd.DataFrame):
count = data["not.fully.paid"].value_counts()
else:
count = data.value_counts()
count.plot(kind = 'pie', explode = [0, 0.1],
figsize = (6, 6), autopct = '%1.1f%%', shadow = True)
plt.ylabel("Loan: Fully Paid Vs. Not Fully Paid")
plt.legend(["Fully Paid", "Not Fully Paid"])
plt.show()
# Visualize the proportion of borrowers
show_loan_distrib(loan_data)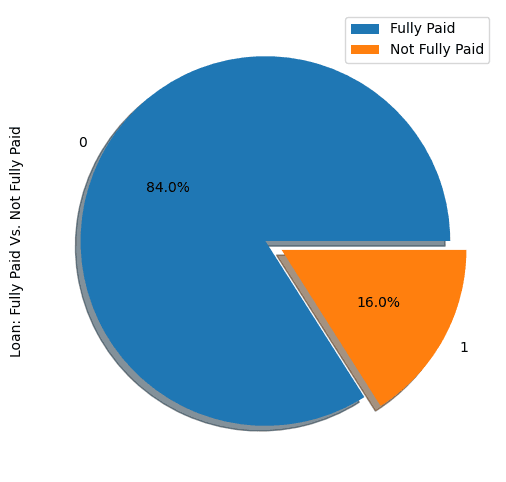
Yukarıdaki grafikten, borçluların %84'ünün kredilerini geri ödediğini, yalnızca %16'sının ödemediğini görüyoruz; bu da veri setini oldukça dengesiz kılıyor.
İlerlemeden önce, kodlanması gerekenleri kodlayabilmek için değişkenlerin türünü kontrol etmemiz gerekiyor.
Tüm sütunların sürekli değişkenler olduğunu, yalnızca kodlanması gereken purpose özniteliğinin istisna olduğunu görüyoruz.

# Check column types
print(loan_data.dtypes)
encoded_loan_data = pd.get_dummies(loan_data, prefix="purpose",
drop_first=True)
print(encoded_loan_data.dtypes)X = encoded_loan_data.drop('not.fully.paid', axis = 1)
y = encoded_loan_data['not.fully.paid']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.30,
stratify = y, random_state=2022)Burada iki örnekleme stratejisini inceleyeceğiz: rastgele az örnekleme ve SMOTE aşırı örnekleme.
Çoğunluk sınıfını —“tamamen ödendi” (sınıf 0)— az örnekleyeceğiz.
X_train_cp = X_train.copy()
X_train_cp['not.fully.paid'] = y_train
y_0 = X_train_cp[X_train_cp['not.fully.paid'] == 0]
y_1 = X_train_cp[X_train_cp['not.fully.paid'] == 1]
y_0_undersample = y_0.sample(y_1.shape[0])
loan_data_undersample = pd.concat([y_0_undersample, y_1], axis = 0)
# Visualize the proportion of borrowers
show_loan_distrib(loan_data_undersample)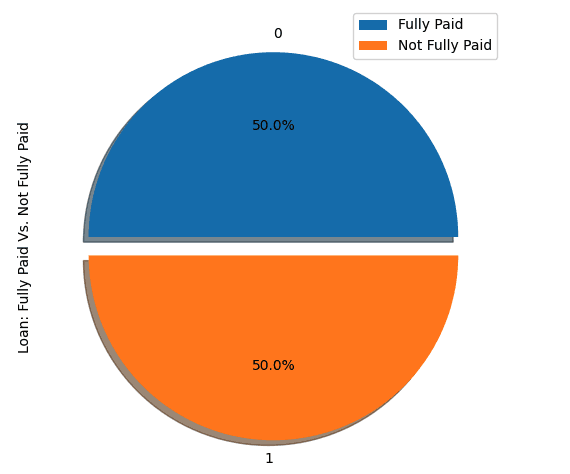
Azınlık sınıfı üzerinde aşırı örnekleme yapın
smote = SMOTE(sampling_strategy='minority')
X_train_SMOTE, y_train_SMOTE = smote.fit_resample(X_train,y_train)
# Visualize the proportion of borrowers
show_loan_distrib(y_train_SMOTE)Örnekleme stratejilerini uyguladıktan sonra, veri setinin farklı borçlu türleri arasında eşit dağıldığını gözlemliyoruz.
Bu bölümde, bu iki sınıflandırma algoritmasını SMOTE ile örneklenmiş veri setine uygulayacağız. Aynı eğitim yaklaşımı, az örneklenmiş veriye de uygulanabilir.
Bu, açıklanabilir bir algoritmadır. Bir veri noktasını, bir sınıfa ait olma olasılığını sigmoid fonksiyonu kullanarak modelleyip sınıflandırır.
X = loan_data_undersample.drop('not.fully.paid', axis = 1)
y = loan_data_undersample['not.fully.paid']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.15, stratify = y, random_state=2022)
logistic_classifier = LogisticRegression()
logistic_classifier.fit(X_train, y_train)
y_pred = logistic_classifier.predict(X_test)
print(confusion_matrix(y_test,y_pred))
print(classification_report(y_test,y_pred))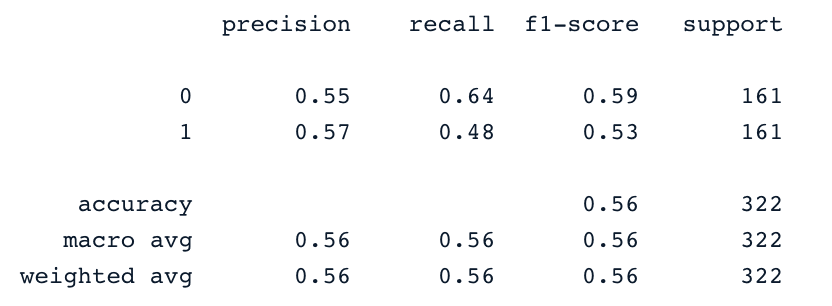
Bu algoritma hem sınıflandırma hem regresyon için kullanılabilir. Marjı ençoklama ilkesini kullanarak hiper düzlemi (karar sınırını) çizmeyi öğrenir. Bu karar sınırı, en yakın iki destek vektörü üzerinden çizilir.
SVM, doğrusal olarak ayrılamayan verileri daha yüksek boyutlu bir uzaya yansıtıp doğrusal olarak ayrılabilir hale getirmek için çekirdek numaraları (kernel tricks) adı verilen bir dönüşüm stratejisi sunar.
from sklearn.svm import SVC
svc_classifier = SVC(kernel='linear')
svc_classifier.fit(X_train, y_train)
# Make Prediction & print the result
y_pred = svc_classifier.predict(X_test)
print(classification_report(y_test,y_pred))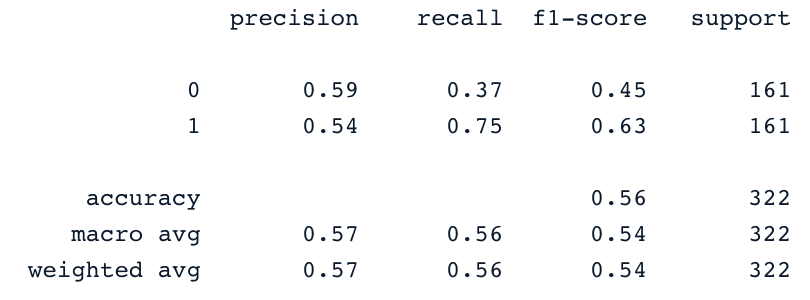
Bu sonuçlar elbette daha fazla özellik mühendisliği ve ince ayarla iyileştirilebilir. Ancak özgün dengesiz veriyi kullanmaktan daha iyidirler.
Bu algoritma, gradyanla güçlendirilmiş ağaçlar olarak bilinen bir algoritmanın uzantısıdır. Yalnızca aşırı uyumu (overfitting) önlemede değil, hız ve performans açısından da güçlü bir adaydır.
Daha fazla uzatmamak için, Python ile Ağaç Tabanlı Modellerle Makine Öğrenmesi ve R ile Ağaç Tabanlı Modellerle Makine Öğrenmesine bakabilirsiniz. Bu kurslarda, ağaç tabanlı modelleri uygulamak için hem Python hem R'ı nasıl kullanacağınızı öğreneceksiniz.
Makine öğrenmesi gelişmeye devam ettikçe, geliştirilmiş performans, ölçeklenebilirlik ve yorumlanabilirlik sunan yeni sınıflandırma algoritmaları ve teknikleri ortaya çıktı. Burada, 2022'den bu yana popülerlik kazanan dönüştürücüler (transformers), derin topluluk yöntemleri ve açıklanabilir yapay zekâ (XAI) teknikleri gibi en dikkat çekici gelişmeleri inceleyeceğiz.
Aslen çeviri ve metin üretimi gibi doğal dil işleme görevleri için tasarlanan Transformers, son dönemde farklı alanlarda çeşitli sınıflandırma görevlerine uyarlanmıştır. Transformers'ın temel yeniliği, girdinin farklı kısımlarının önemini etkili biçimde ağırlıklandırmaya olanak tanıyan öz-dikkat (self-attention) mekanizmalarını kullanmalarıdır.
Transformers, büyük ve karmaşık veri kümelerini ele almakta üstündür ve sağlık, finans ve e-ticaret gibi sektörlerde görsel tanıma, sahtekârlık tespiti ve öneri sistemleri gibi görevlerde yaygın biçimde benimsenmiştir.
Derin topluluk yöntemleri, sağlamlık, doğruluk ve belirsizlik tahminini iyileştirmek için birden fazla modelin tahminlerini birleştirir. Farklı modellerin güçlü yönlerinden yararlanarak, bu yöntemler çoğu zaman tekil modellerden daha iyi performans gösterebilir; özellikle de karmaşık sınıflandırma görevlerinde.
Makine öğrenmesi modelleri karmaşıklaştıkça, yorumlanabilirlik ve şeffaflık ihtiyacı arttı. Açıklanabilir yapay zekâ (XAI) teknikleri, özellikle sağlık ve finans gibi yüksek riskli alanlarda yapay zekâ sistemlerine güven kazanmak için kritik olan, sınıflandırma modellerinin karar verme süreçlerini insanlar için daha anlaşılır kılmak üzere geliştirildi.
Bu XAI teknikleri, yalnızca şeffaflığı artırmakla kalmayıp, Avrupa'daki Genel Veri Koruma Yönetmeliği (GDPR) gibi otomatik kararlar için açıklama zorunluluğu getiren düzenlemelere uyum sağlamak amacıyla da giderek sınıflandırma modellerine entegre edilmektedir.
Bu kavramsal blog yazısı, Makine öğrenmesinde sınıflandırmanın ana yönlerini ele aldı ve uygulandıkları farklı alanlardan örnekler sundu. Son olarak, modellerin eğitimi için dengeli bir veri seti oluşturmak amacıyla az örnekleme ve SMOTE aşırı örnekleme stratejileri uygulandıktan sonra Lojistik Regresyon ve Destek Vektör Makinesinin uygulanmasını ele aldı.
Umarız bu yazı, Makine Öğrenmesinde sınıflandırma konusunu daha iyi anlamanıza yardımcı olmuştur. Öğreniminizi, denetimli, denetimsiz ve derin öğrenmeyi kapsayan Python ile Makine Öğrenmesi Bilimcisi eğitim yolu ile ilerletebilirsiniz. Ayrıca doğal dil işleme, görüntü işleme, Spark ve Keras'a iyi bir giriş sağlar.
Makine Öğrenmesi Kursları
Kurs
Kurs
Kurs
blog
Abid Ali Awan
14 dk.
blog
Dario Radečić
15 dk.
Eğitim
Kurtis Pykes
Eğitim
Adel Nehme
