Course
Supervised Learning in R: Classification
4 hr
100.4K
Classification is a supervised machine learning method where the model tries to predict the correct label of a given input data. In classification, the model is fully trained using the training data, and then it is evaluated on test data before being used to perform prediction on new unseen data.
For instance, an algorithm can learn to predict whether a given email is spam or ham (no spam), as illustrated below.
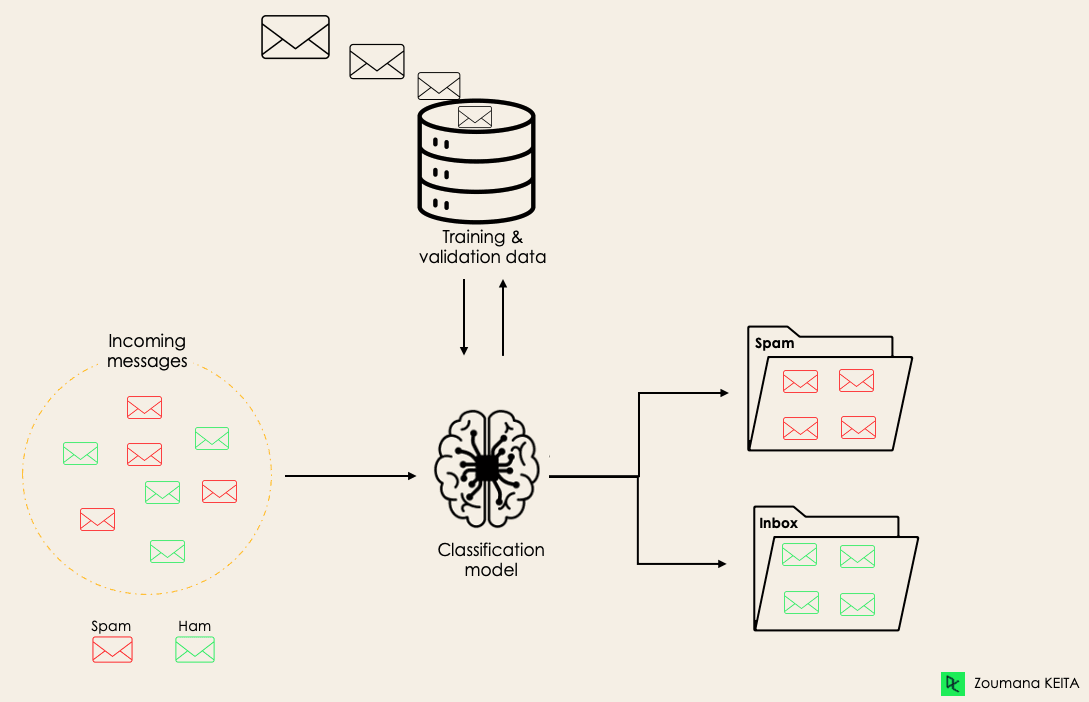 Before diving into the classification concept, we will first understand the difference between the two types of learners in classification: lazy and eager learners. Then we will clarify the misconception between classification and regression.
Before diving into the classification concept, we will first understand the difference between the two types of learners in classification: lazy and eager learners. Then we will clarify the misconception between classification and regression.
There are two types of learners in machine learning classification: lazy and eager learners.
Eager learners are machine learning algorithms that first build a model from the training dataset before making any prediction on future datasets. They spend more time during the training process because of their eagerness to have a better generalization during the training from learning the weights, but they require less time to make predictions.
Most machine learning algorithms are eager learners, and below are some examples:
Lazy learners or instance-based learners, on the other hand, do not create any model immediately from the training data, and this is where the lazy aspect comes from. They just memorize the training data, and each time there is a need to make a prediction, they search for the nearest neighbor from the whole training data, which makes them very slow during prediction. Some examples of this kind are:
However, some algorithms, such as BallTrees and KDTrees, can be used to improve the prediction latency.
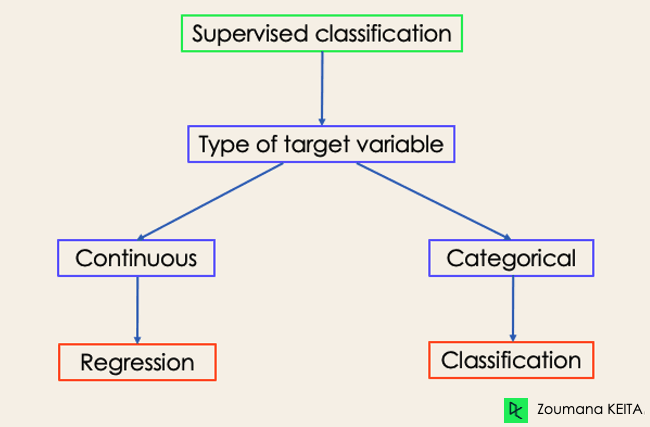
There are four main categories of Machine Learning algorithms: supervised, unsupervised, semi-supervised, and reinforcement learning.
Even though classification and regression are both from the category of supervised learning, they are not the same.
If you are interested in knowing more about classification, courses on Supervised Learning with scikit-learn and Supervised Learning in R might be helpful. They provide you with a better understanding of how each algorithm approaches tasks and the Python and R functions required to implement them.
Regarding regression, Introduction to Regression in R and Introduction to Regression with statsmodels in Python will help you explore different types of regression models as well as their implementation in R and Python.
 Examples of Machine Learning Classification in Real Life
Examples of Machine Learning Classification in Real Life Supervised Machine Learning Classification has different applications in multiple domains of our day-to-day life. Below are some examples.
Training a machine learning model on historical patient data can help healthcare specialists accurately analyze their diagnoses:
Education is one of the domains dealing with the most textual, video, and audio data. This unstructured information can be analyzed with the help of Natural Language technologies to perform different tasks such as:
Transportation is the key component of many countries' economic development. As a result, industries are using machine and deep learning models:
Agriculture is one of the most valuable pillars of human survival. Introducing sustainability can help improve farmers' productivity at a different level without damaging the environment:
There are four main classification tasks in Machine learning: binary, multi-class, multi-label, and imbalanced classifications.
In a binary classification task, the goal is to classify the input data into two mutually exclusive categories. The training data in such a situation is labeled in a binary format: true and false; positive and negative; O and 1; spam and not spam, etc. depending on the problem being tackled. For instance, we might want to detect whether a given image is a truck or a boat.
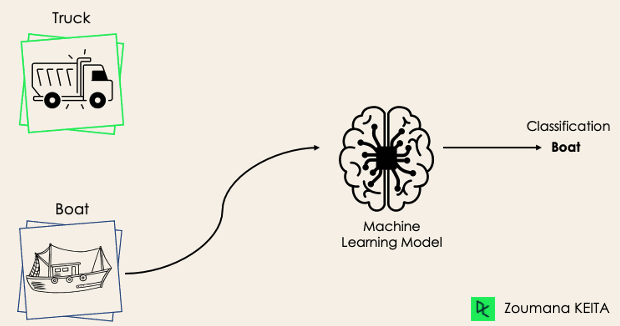
Logistic Regression and Support Vector Machines algorithms are natively designed for binary classifications. However, other algorithms such as K-Nearest Neighbors and Decision Trees can also be used for binary classification.
The multi-class classification, on the other hand, has at least two mutually exclusive class labels, where the goal is to predict to which class a given input example belongs to. In the following case, the model correctly classified the image to be a plane.
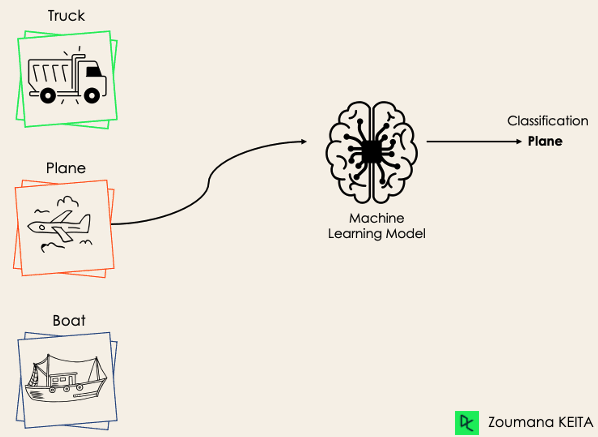
Most of the binary classification algorithms can be also used for multi-class classification. These algorithms include but are not limited to:
But wait! Didn’t you say that SVM and Logistic Regression do not support multi-class classification by default?
→ That’s correct. However, we can apply binary transformation approaches such as one-versus-one and one-versus-all to adapt native binary classification algorithms for multi-class classification tasks.
One-versus-one: this strategy trains as many classifiers as there are pairs of labels. If we have a 3-class classification, we will have three pairs of labels, thus three classifiers, as shown below.
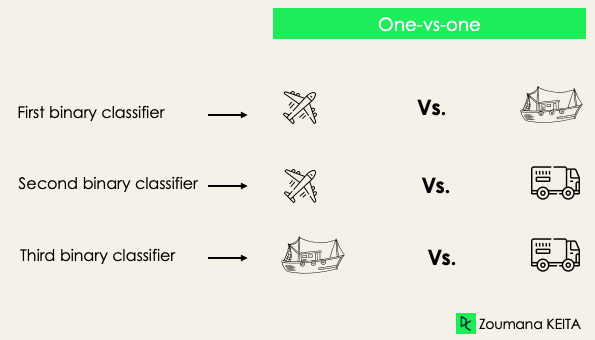
In general, for N labels, we will have Nx(N-1)/2 classifiers. Each classifier is trained on a single binary dataset, and the final class is predicted by a majority vote between all the classifiers. One-vs-one approach works best for SVM and other kernel-based algorithms.
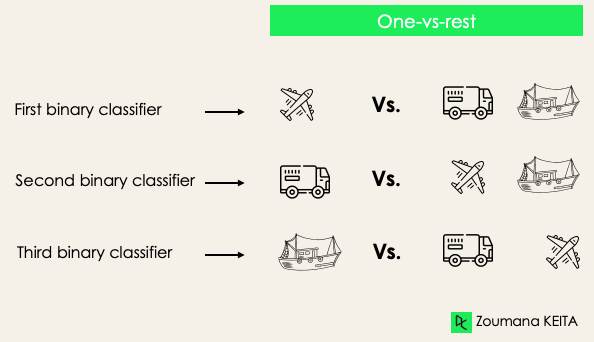
One-versus-rest: at this stage, we start by considering each label as an independent label and consider the rest combined as only one label. With 3-classes, we will have three classifiers.
In general, for N labels, we will have N binary classifiers.
In multi-label classification tasks, we try to predict 0 or more classes for each input example. In this case, there is no mutual exclusion because the input example can have more than one label.
Such a scenario can be observed in different domains, such as auto-tagging in Natural Language Processing, where a given text can contain multiple topics. Similarly to computer vision, an image can contain multiple objects, as illustrated below: the model predicted that the image contains: a plane, a boat, a truck, and a dog.
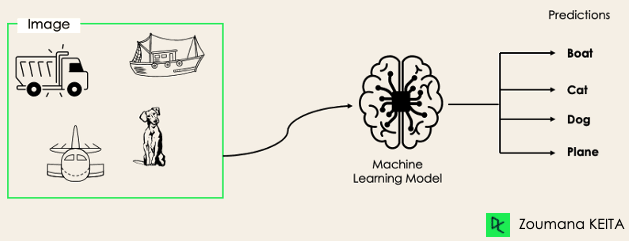
It is not possible to use multi-class or binary classification models to perform multi-label classification. However, most algorithms used for those standard classification tasks have their specialized versions for multi-label classification. We can cite:
For the imbalanced classification, the number of examples is unevenly distributed in each class, meaning that we can have more of one class than the others in the training data. Let’s consider the following 3-class classification scenario where the training data contains: 60% of trucks, 25% of planes, and 15% of boats.
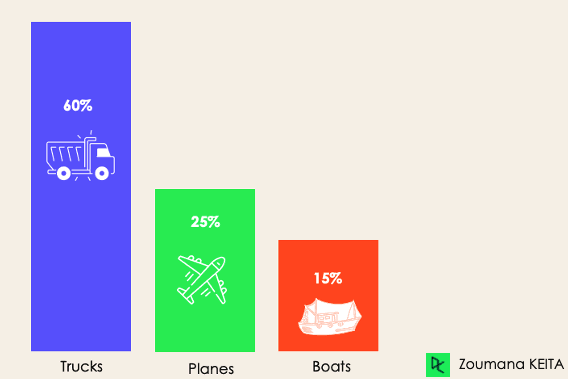
The imbalanced classification problem could occur in the following scenario:
Using conventional predictive models such as Decision Trees, Logistic Regression, etc. could not be effective when dealing with an imbalanced dataset, because they might be biased toward predicting the class with the highest number of observations, and considering those with fewer numbers as noise.
So, does that mean that such problems are left behind?
Of course not! We can use multiple approaches to tackle the imbalance problem in a dataset. The most commonly used approaches include sampling techniques or harnessing the power of cost-sensitive algorithms.
These techniques aim to balance the distribution of the original by:
These algorithms take into consideration the cost of misclassification. They aim to minimize the total cost generated by the models.
Now that we have an idea of the different types of classification models, it is crucial to choose the right evaluation metrics for those models. In this section, we will cover the most commonly used metrics: accuracy, precision, recall, F1 score, and area under the ROC (Receiver Operating Characteristic) curve and AUC (Area Under the Curve).



We now have all the tools in hand to proceed with the implementation of some algorithms. This section will cover four algorithms and their implementation on the loans dataset to illustrate some of the previously covered concepts, especially for the imbalanced datasets using a binary classification task. We will focus on only four algorithms for simplicity’s sake.
The goal is not to have the best possible model but to illustrate how to train each of the following algorithms. The source code is available on DataLab, where you can execute everything with one click.
import pandas as pd
loan_data = pd.read_csv("loan_data.csv")
loan_data.head()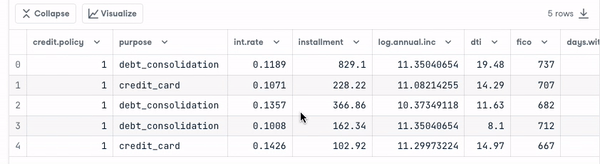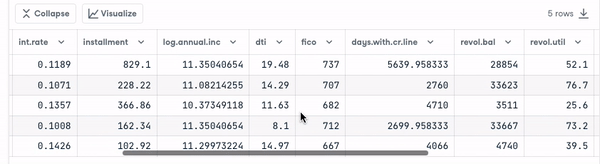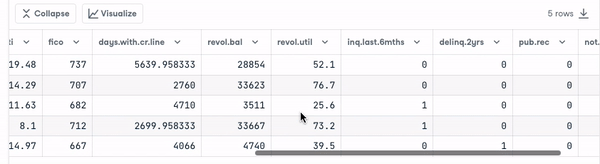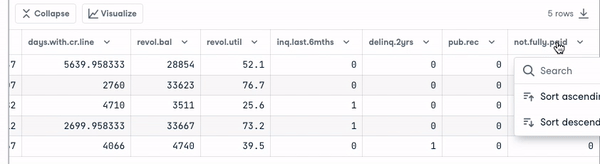
import matplotlib.pyplot as plt
# Helper function for data distribution
# Visualize the proportion of borrowers
def show_loan_distrib(data):
count = ""
if isinstance(data, pd.DataFrame):
count = data["not.fully.paid"].value_counts()
else:
count = data.value_counts()
count.plot(kind = 'pie', explode = [0, 0.1],
figsize = (6, 6), autopct = '%1.1f%%', shadow = True)
plt.ylabel("Loan: Fully Paid Vs. Not Fully Paid")
plt.legend(["Fully Paid", "Not Fully Paid"])
plt.show()
# Visualize the proportion of borrowers
show_loan_distrib(loan_data)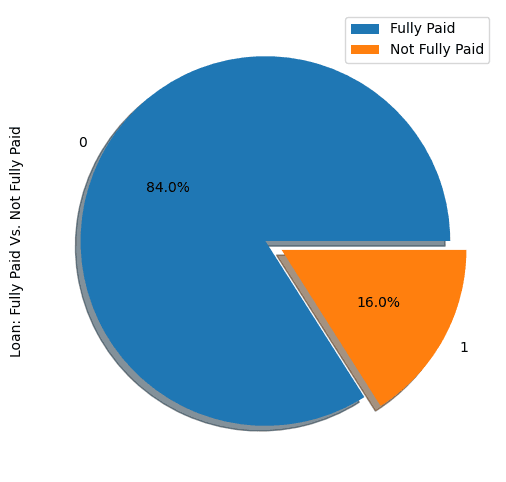
From the graphic above, we notice that 84% of the borrowers paid their loans back, and only 16% didn’t pay them back, which makes the dataset really imbalanced.
Before further, we need to check the variables’ type so that we can encode those that need to be encoded.
We notice that all the columns are continuous variables, except the purpose attribute, which needs to be encoded.

# Check column types
print(loan_data.dtypes)
encoded_loan_data = pd.get_dummies(loan_data, prefix="purpose",
drop_first=True)
print(encoded_loan_data.dtypes)X = encoded_loan_data.drop('not.fully.paid', axis = 1)
y = encoded_loan_data['not.fully.paid']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.30,
stratify = y, random_state=2022)We will explore two sampling strategies here: random undersampling, and SMOTE oversampling.
We will undersample the majority class, which corresponds to the “fully paid” (class 0).
X_train_cp = X_train.copy()
X_train_cp['not.fully.paid'] = y_train
y_0 = X_train_cp[X_train_cp['not.fully.paid'] == 0]
y_1 = X_train_cp[X_train_cp['not.fully.paid'] == 1]
y_0_undersample = y_0.sample(y_1.shape[0])
loan_data_undersample = pd.concat([y_0_undersample, y_1], axis = 0)
# Visualize the proportion of borrowers
show_loan_distrib(loan_data_undersample)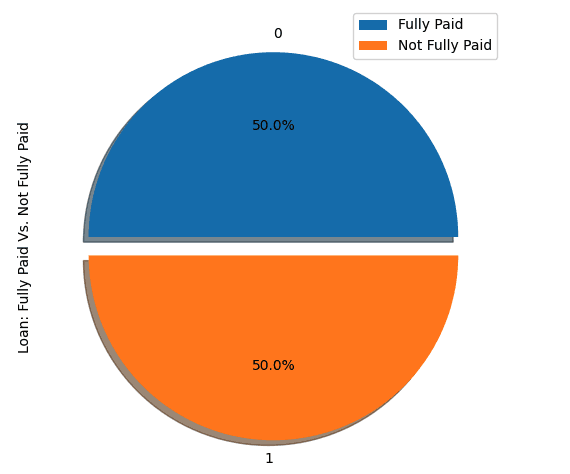
Perform oversampling on the minority class
smote = SMOTE(sampling_strategy='minority')
X_train_SMOTE, y_train_SMOTE = smote.fit_resample(X_train,y_train)
# Visualize the proportion of borrowers
show_loan_distrib(y_train_SMOTE)After applying the sampling strategies, we observe that the dataset is equally distributed across the different types of borrowers.
This section will apply these two classification algorithms to the SMOTE smote sampled dataset. The same training approach can be applied to undersampled data as well.
This is an explainable algorithm. It classifies a data point by modeling its probability of belonging to a given class using the sigmoid function.
X = loan_data_undersample.drop('not.fully.paid', axis = 1)
y = loan_data_undersample['not.fully.paid']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.15, stratify = y, random_state=2022)
logistic_classifier = LogisticRegression()
logistic_classifier.fit(X_train, y_train)
y_pred = logistic_classifier.predict(X_test)
print(confusion_matrix(y_test,y_pred))
print(classification_report(y_test,y_pred))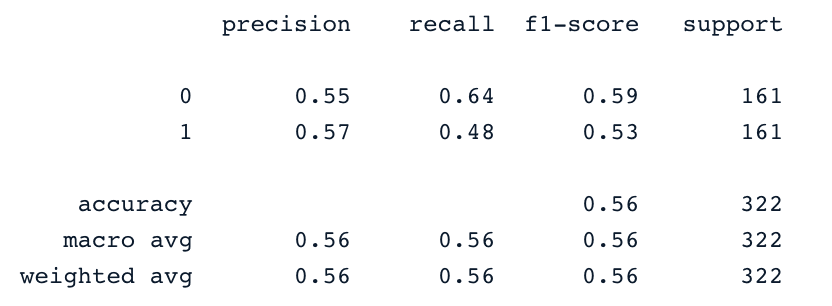
This algorithm can be used for both classification and regression. It learns to draw the hyperplane (decision boundary) by using the margin to maximization principle. This decision boundary is drawn through the two closest support vectors.
SVM provides a transformation strategy called kernel tricks used to project non-learner separable data onto a higher dimension space to make them linearly separable.
from sklearn.svm import SVC
svc_classifier = SVC(kernel='linear')
svc_classifier.fit(X_train, y_train)
# Make Prediction & print the result
y_pred = svc_classifier.predict(X_test)
print(classification_report(y_test,y_pred))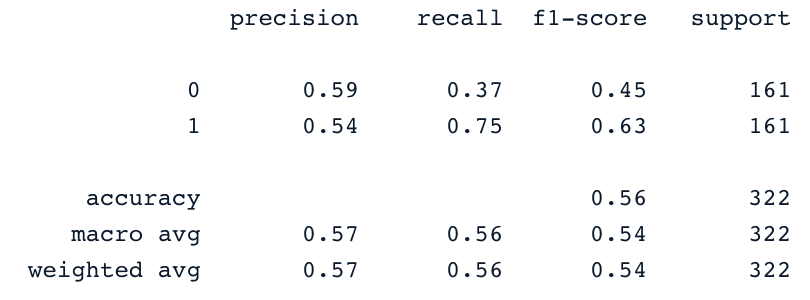
These results can be of course improved with more feature engineering and fine-tuning. But they are better than using the original imbalanced data.
This algorithm is an extension of a well-known algorithm called gradient-boosted trees. It is a great candidate not only for combating overfitting but also for speed and performance.
To not make it longer, you can refer to Machine Learning with Tree-Based Models in Python and Machine Learning with Tree-Based Models in R. From these courses, you will learn how to use both Python and R to implement tree-based models.
As machine learning continues to evolve, new classification algorithms and techniques have emerged, offering improved performance, scalability, and interpretability. Here, we will explore some of the most notable advancements that have gained popularity since 2022, including transformers, deep ensemble methods, and explainable AI (XAI) techniques.
Transformers, originally designed for natural language processing tasks like translation and text generation, have recently been adapted for various classification tasks across different domains. The key innovation of transformers is their use of self-attention mechanisms, which allow models to weigh the importance of different parts of the input data effectively.
Transformers excel in handling large, complex datasets, and they have been widely adopted in industries such as healthcare, finance, and e-commerce for tasks like image recognition, fraud detection, and recommendation systems.
Deep ensemble methods combine the predictions of multiple models to improve robustness, accuracy, and uncertainty estimation. By leveraging the strengths of different models, these methods can often outperform individual models, especially in complex classification tasks.
As machine learning models become more complex, the need for interpretability and transparency has grown. Explainable AI (XAI) techniques have been developed to make the decision-making process of classification models more understandable to humans, which is crucial for gaining trust in AI systems, especially in high-stakes domains like healthcare and finance.
These XAI techniques are increasingly being integrated into classification models to not only improve transparency but also to comply with regulatory requirements, such as the General Data Protection Regulation (GDPR) in Europe, which mandates explanations for automated decisions.
This conceptual blog covered the main aspect of classifications in Machine learning and also provided you with some examples of different domains they are applied to. Finally, it covered the implementation of Logistic Regression and Support Vector Machine after performing the undersampling and SMOTE oversampling strategies to generate a balanced dataset for the models’ training.
We hope it helped you have a better understanding of this topic of classification in Machine Learning. You can further your learning by following the Machine Learning Scientist with Python track, which covers both supervised, unsupervised and deep learning. It also provides a good introduction to natural language processing, image processing, Spark, and Keras.
Machine Learning Courses
Course
Course
Course
blog
Kurtis Pykes
12 min
blog
Moez Ali
15 min
blog
Moez Ali
8 min
blog
Matt Crabtree
14 min
blog
Zoumana Keita
10 min
blog
Natassha Selvaraj
15 min
