Courses
Học có giám sát trong R: Phân loại
4 giờ
100.7K
Phân loại là một phương pháp học có giám sát, trong đó mô hình cố gắng dự đoán nhãn đúng cho dữ liệu đầu vào. Ở bài toán phân loại, mô hình được huấn luyện đầy đủ bằng dữ liệu huấn luyện, sau đó được đánh giá trên dữ liệu kiểm tra trước khi dùng để dự đoán dữ liệu mới chưa từng thấy.
Ví dụ, một thuật toán có thể học cách dự đoán liệu một email là spam hay ham (không spam), như minh họa bên dưới.
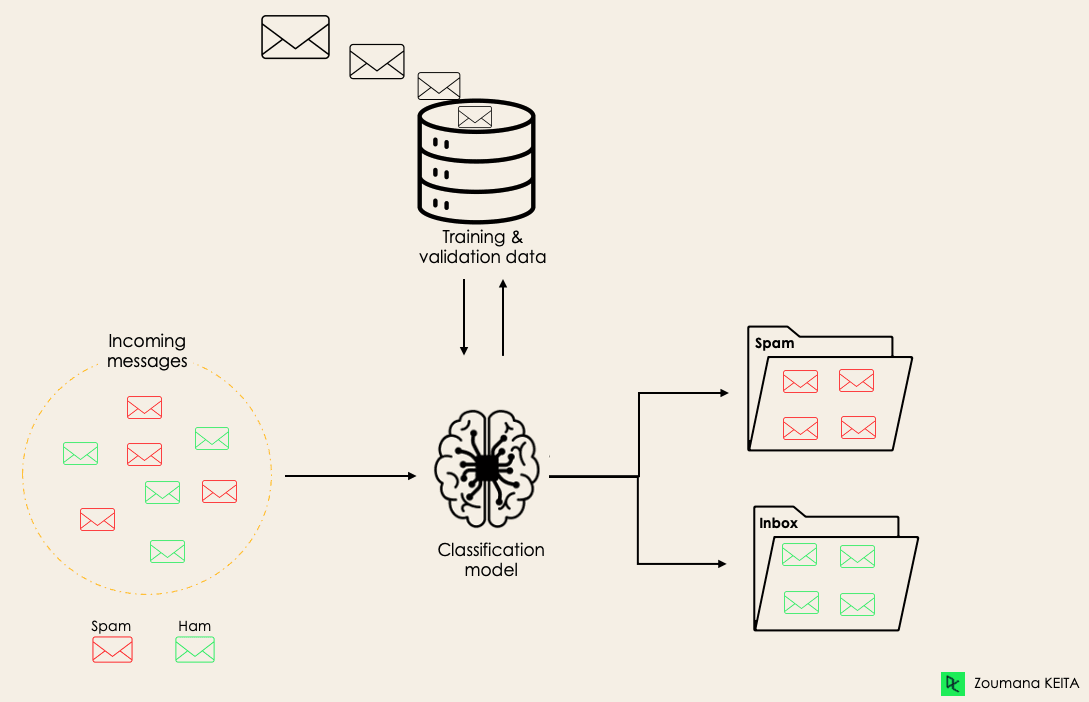 Trước khi đi sâu vào khái niệm phân loại, chúng ta sẽ tìm hiểu sự khác nhau giữa hai kiểu learner trong phân loại: lazy và eager. Sau đó làm rõ những nhầm lẫn giữa phân loại và hồi quy.
Trước khi đi sâu vào khái niệm phân loại, chúng ta sẽ tìm hiểu sự khác nhau giữa hai kiểu learner trong phân loại: lazy và eager. Sau đó làm rõ những nhầm lẫn giữa phân loại và hồi quy.
Trong phân loại bằng machine learning có hai kiểu learner: lazy và eager.
Eager learners là các thuật toán machine learning xây dựng mô hình từ tập dữ liệu huấn luyện trước khi đưa ra bất kỳ dự đoán nào trên dữ liệu tương lai. Chúng tốn nhiều thời gian hơn trong quá trình huấn luyện do “nhiệt tình” tối ưu khả năng khái quát hóa thông qua việc học trọng số, nhưng cần ít thời gian hơn để dự đoán.
Hầu hết các thuật toán machine learning là eager learners, ví dụ như:
Lazy learners hay còn gọi là instance-based learners thì ngược lại: không tạo ra mô hình ngay từ dữ liệu huấn luyện, đây chính là điểm “lười”. Chúng chỉ ghi nhớ dữ liệu huấn luyện và mỗi khi cần dự đoán, chúng tìm hàng xóm gần nhất từ toàn bộ dữ liệu huấn luyện, khiến quá trình suy luận rất chậm. Một số ví dụ:
Tuy nhiên, một số thuật toán như BallTrees và KDTrees có thể được dùng để cải thiện độ trễ khi dự đoán.
Có bốn nhóm chính của thuật toán Machine Learning: học có giám sát, không giám sát, bán giám sát và học tăng cường.
Mặc dù phân loại và hồi quy đều thuộc nhóm học có giám sát, chúng không giống nhau.
Nếu bạn muốn biết thêm về phân loại, các khóa học Supervised Learning với scikit-learn và Supervised Learning trong R có thể hữu ích. Chúng giúp bạn hiểu rõ cách mỗi thuật toán tiếp cận bài toán cũng như các hàm trong Python và R để triển khai.
Về hồi quy, Introduction to Regression in R và Introduction to Regression with statsmodels in Python sẽ giúp bạn khám phá các loại mô hình hồi quy khác nhau và cách triển khai chúng trong R và Python.
 Ví dụ về Phân loại trong Machine Learning trong đời sống
Ví dụ về Phân loại trong Machine Learning trong đời sống Phân loại trong học có giám sát có nhiều ứng dụng trong các lĩnh vực khác nhau của đời sống thường nhật. Dưới đây là một số ví dụ.
Huấn luyện mô hình machine learning trên dữ liệu bệnh nhân trong quá khứ có thể giúp chuyên gia y tế phân tích chẩn đoán chính xác hơn:
Giáo dục là một trong những lĩnh vực xử lý nhiều dữ liệu văn bản, video và âm thanh nhất. Thông tin phi cấu trúc này có thể được phân tích với sự trợ giúp của công nghệ Xử lý Ngôn ngữ Tự nhiên để thực hiện các tác vụ như:
Giao thông vận tải là thành phần then chốt của sự phát triển kinh tế ở nhiều quốc gia. Do đó, các ngành đang sử dụng các mô hình machine learning và deep learning:
Nông nghiệp là một trong những trụ cột quan trọng của sự sống con người. Áp dụng tính bền vững có thể giúp nâng cao năng suất của nông dân ở nhiều cấp độ mà không làm tổn hại môi trường:
Có bốn dạng bài toán phân loại chính trong Machine Learning: nhị phân, đa lớp, đa nhãn và phân lớp mất cân bằng.
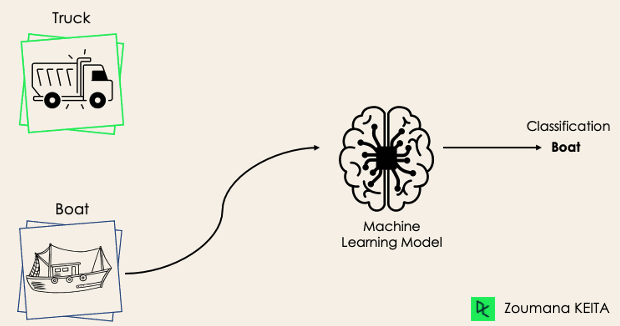
Trong bài toán phân loại nhị phân, mục tiêu là phân loại dữ liệu đầu vào vào hai nhóm loại loại trừ lẫn nhau. Dữ liệu huấn luyện được gán nhãn ở dạng nhị phân: đúng và sai; dương và âm; 0 và 1; spam và không spam, v.v., tùy bài toán. Ví dụ, ta có thể muốn phát hiện một ảnh là xe tải hay thuyền.
Hồi quy Logistic và SVM được thiết kế nguyên bản cho bài toán phân loại nhị phân. Tuy vậy, các thuật toán khác như K-Nearest Neighbors và Cây quyết định cũng có thể dùng cho phân loại nhị phân.
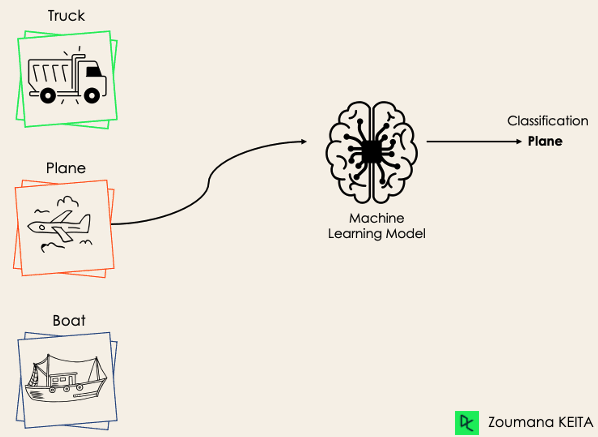
Phân loại đa lớp có ít nhất hai nhãn lớp loại trừ nhau, nơi mục tiêu là dự đoán một mẫu đầu vào thuộc lớp nào. Trong ví dụ sau, mô hình đã phân loại chính xác ảnh là máy bay.
Phần lớn thuật toán phân loại nhị phân cũng có thể dùng cho phân loại đa lớp. Các thuật toán này bao gồm nhưng không giới hạn ở:
Khoan đã! Chẳng phải bạn nói SVM và Hồi quy Logistic không hỗ trợ đa lớp theo mặc định sao?
→ Đúng vậy. Tuy nhiên, ta có thể áp dụng các cách chuyển đổi nhị phân như one-versus-one và one-versus-all để thích nghi các thuật toán phân loại nhị phân cho bài toán đa lớp.
One-versus-one: chiến lược này huấn luyện số lượng bộ phân loại tương ứng với số cặp nhãn. Nếu có phân loại 3 lớp, ta sẽ có ba cặp nhãn, do đó ba bộ phân loại, như minh họa bên dưới.
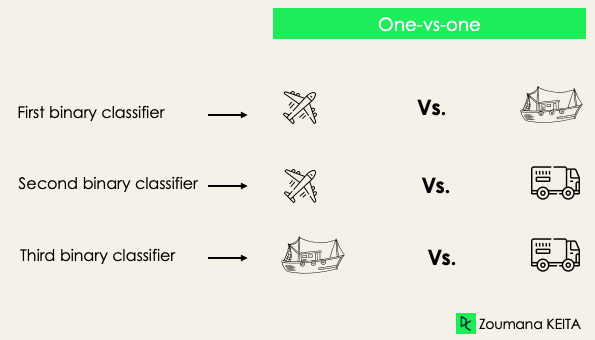
Nói chung, với N nhãn, ta sẽ có Nx(N-1)/2 bộ phân loại. Mỗi bộ phân loại được huấn luyện trên một tập dữ liệu nhị phân, và lớp cuối cùng được dự đoán bằng cách bỏ phiếu đa số giữa tất cả các bộ phân loại. One-vs-one hoạt động tốt nhất với SVM và các thuật toán dựa trên kernel.
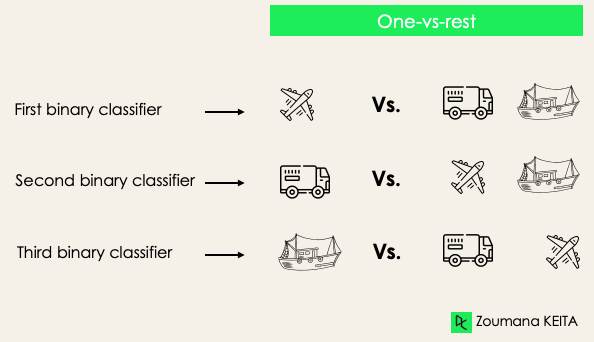
One-versus-rest: ở chiến lược này, ta lần lượt coi mỗi nhãn là một nhãn độc lập và gộp phần còn lại thành một nhãn duy nhất. Với 3 lớp, ta sẽ có ba bộ phân loại.
Nhìn chung, với N nhãn, ta sẽ có N bộ phân loại nhị phân.
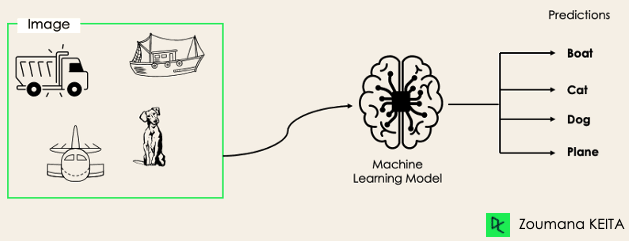
Trong bài toán phân loại đa nhãn, ta cố gắng dự đoán 0 hoặc nhiều lớp cho mỗi mẫu đầu vào. Trong trường hợp này không có tính loại trừ lẫn nhau vì một mẫu đầu vào có thể mang nhiều nhãn.
Trường hợp này có thể quan sát thấy trong nhiều lĩnh vực, như tự động gắn thẻ trong Xử lý Ngôn ngữ Tự nhiên, nơi một văn bản có thể chứa nhiều chủ đề. Tương tự trong thị giác máy tính, một ảnh có thể chứa nhiều đối tượng, như minh họa bên dưới: mô hình dự đoán ảnh chứa: máy bay, thuyền, xe tải và chó.
Không thể dùng mô hình phân loại đa lớp hay nhị phân thông thường để thực hiện phân loại đa nhãn. Tuy nhiên, hầu hết các thuật toán dùng cho các bài toán phân loại chuẩn đều có phiên bản chuyên biệt cho phân loại đa nhãn. Có thể kể đến:
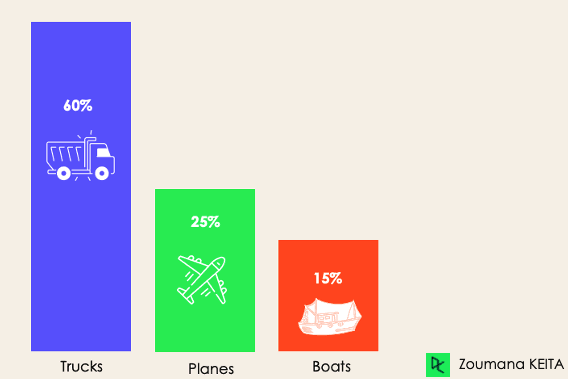
Với phân loại mất cân bằng, số lượng mẫu phân bố không đều giữa các lớp, nghĩa là có thể có nhiều mẫu của một lớp hơn các lớp khác trong dữ liệu huấn luyện. Xét kịch bản phân loại 3 lớp sau, dữ liệu huấn luyện gồm: 60% xe tải, 25% máy bay và 15% thuyền.
Bài toán phân loại mất cân bằng có thể xuất hiện trong các trường hợp sau:
Sử dụng các mô hình dự đoán thông thường như Cây quyết định, Hồi quy Logistic, v.v. có thể không hiệu quả khi xử lý dữ liệu mất cân bằng, vì chúng có xu hướng thiên lệch dự đoán về lớp có nhiều quan sát nhất, coi những lớp ít dữ liệu là nhiễu.
Vậy điều đó có nghĩa là những bài toán như vậy bị bỏ ngỏ?
Hoàn toàn không! Ta có thể dùng nhiều cách tiếp cận để xử lý vấn đề mất cân bằng trong dữ liệu. Những cách phổ biến nhất gồm các kỹ thuật lấy mẫu hoặc tận dụng sức mạnh của các thuật toán nhạy chi phí (cost-sensitive).
Mục tiêu của các kỹ thuật này là cân bằng lại phân phối ban đầu bằng cách:
Các thuật toán này tính đến chi phí của việc phân loại sai. Chúng nhằm mục tiêu tối thiểu hóa tổng chi phí do mô hình tạo ra.
Giờ đây khi đã có cái nhìn về các loại mô hình phân loại khác nhau, việc chọn đúng chỉ số đánh giá cho các mô hình đó là rất quan trọng. Phần này sẽ đề cập đến các chỉ số phổ biến nhất: độ chính xác (accuracy), độ chính xác dự đoán dương (precision), khả năng thu hồi (recall), điểm F1, và diện tích dưới đường cong ROC (Receiver Operating Characteristic) và AUC (Area Under the Curve).



Chúng ta đã có đủ công cụ để tiến hành triển khai một số thuật toán. Phần này sẽ đề cập bốn thuật toán và cách triển khai trên bộ dữ liệu khoản vay để minh họa một số khái niệm đã nêu, đặc biệt là với dữ liệu mất cân bằng trong một bài toán phân loại nhị phân. Vì đơn giản, chúng ta sẽ chỉ tập trung vào bốn thuật toán.
Mục tiêu không phải là có mô hình tốt nhất có thể, mà là minh họa cách huấn luyện từng thuật toán sau đây. Mã nguồn có sẵn trên DataLab, nơi bạn có thể chạy mọi thứ chỉ với một cú nhấp.
import pandas as pd
loan_data = pd.read_csv("loan_data.csv")
loan_data.head()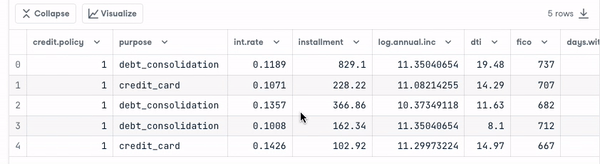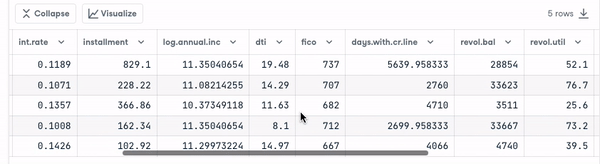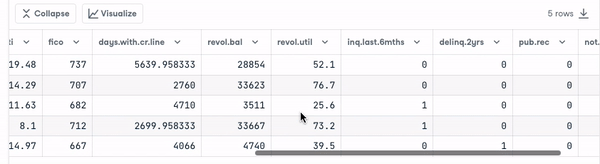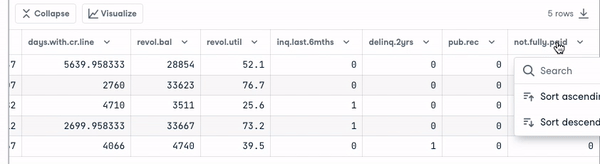
import matplotlib.pyplot as plt
# Helper function for data distribution
# Visualize the proportion of borrowers
def show_loan_distrib(data):
count = ""
if isinstance(data, pd.DataFrame):
count = data["not.fully.paid"].value_counts()
else:
count = data.value_counts()
count.plot(kind = 'pie', explode = [0, 0.1],
figsize = (6, 6), autopct = '%1.1f%%', shadow = True)
plt.ylabel("Loan: Fully Paid Vs. Not Fully Paid")
plt.legend(["Fully Paid", "Not Fully Paid"])
plt.show()
# Visualize the proportion of borrowers
show_loan_distrib(loan_data)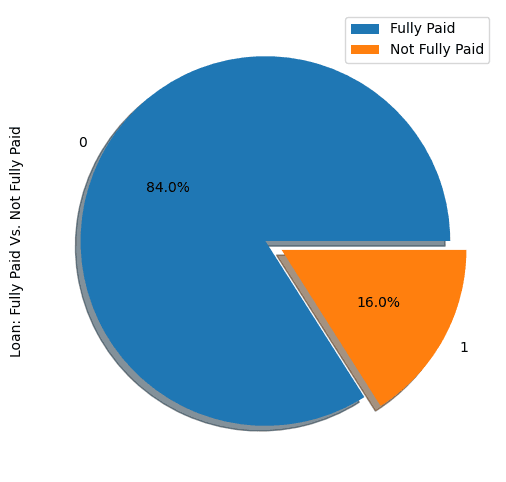
Từ biểu đồ trên, ta thấy 84% người vay đã trả đầy đủ khoản vay, chỉ 16% không trả, khiến bộ dữ liệu mất cân bằng rõ rệt.
Trước khi đi tiếp, chúng ta cần kiểm tra kiểu của các biến để mã hóa những biến cần mã hóa.
Ta nhận thấy tất cả các cột đều là biến liên tục, ngoại trừ thuộc tính purpose, cần được mã hóa.

# Check column types
print(loan_data.dtypes)
encoded_loan_data = pd.get_dummies(loan_data, prefix="purpose",
drop_first=True)
print(encoded_loan_data.dtypes)X = encoded_loan_data.drop('not.fully.paid', axis = 1)
y = encoded_loan_data['not.fully.paid']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.30,
stratify = y, random_state=2022)Chúng ta sẽ thử hai chiến lược lấy mẫu: undersampling ngẫu nhiên và oversampling SMOTE.
Chúng ta sẽ undersample lớp đa số, tương ứng với “trả đủ” (lớp 0).
X_train_cp = X_train.copy()
X_train_cp['not.fully.paid'] = y_train
y_0 = X_train_cp[X_train_cp['not.fully.paid'] == 0]
y_1 = X_train_cp[X_train_cp['not.fully.paid'] == 1]
y_0_undersample = y_0.sample(y_1.shape[0])
loan_data_undersample = pd.concat([y_0_undersample, y_1], axis = 0)
# Visualize the proportion of borrowers
show_loan_distrib(loan_data_undersample)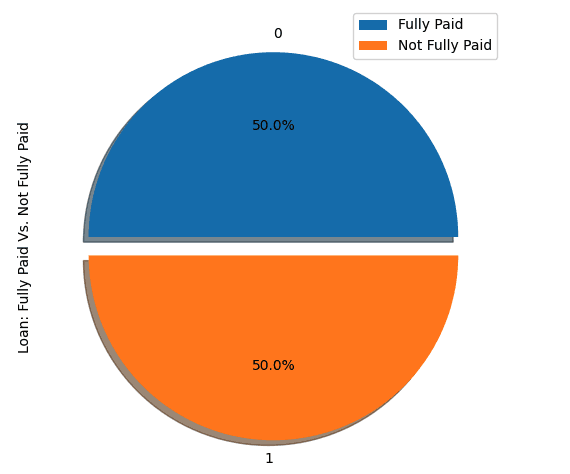
Thực hiện oversampling trên lớp thiểu số
smote = SMOTE(sampling_strategy='minority')
X_train_SMOTE, y_train_SMOTE = smote.fit_resample(X_train,y_train)
# Visualize the proportion of borrowers
show_loan_distrib(y_train_SMOTE)Sau khi áp dụng các chiến lược lấy mẫu, ta quan sát thấy bộ dữ liệu được phân phối đồng đều giữa các nhóm người vay.
Phần này sẽ áp dụng hai thuật toán phân loại lên bộ dữ liệu đã lấy mẫu bằng SMOTE. Cùng cách huấn luyện này cũng có thể áp dụng cho dữ liệu đã undersample.
Đây là một thuật toán có khả năng diễn giải. Nó phân loại một điểm dữ liệu bằng cách mô hình hóa xác suất thuộc về một lớp nhất định thông qua hàm sigmoid.
X = loan_data_undersample.drop('not.fully.paid', axis = 1)
y = loan_data_undersample['not.fully.paid']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.15, stratify = y, random_state=2022)
logistic_classifier = LogisticRegression()
logistic_classifier.fit(X_train, y_train)
y_pred = logistic_classifier.predict(X_test)
print(confusion_matrix(y_test,y_pred))
print(classification_report(y_test,y_pred))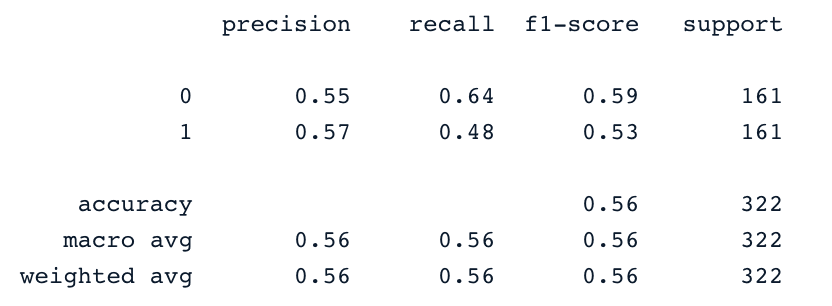
Thuật toán này có thể dùng cho cả phân loại và hồi quy. Nó học cách vẽ siêu phẳng (ranh giới quyết định) dựa trên nguyên lý tối đa hóa biên. Ranh giới này được xác định thông qua hai vectơ hỗ trợ gần nhất.
SVM cung cấp chiến lược biến đổi gọi là kernel trick, dùng để chiếu dữ liệu không thể phân tách tuyến tính lên không gian chiều cao hơn để chúng trở nên tuyến tính.
from sklearn.svm import SVC
svc_classifier = SVC(kernel='linear')
svc_classifier.fit(X_train, y_train)
# Make Prediction & print the result
y_pred = svc_classifier.predict(X_test)
print(classification_report(y_test,y_pred))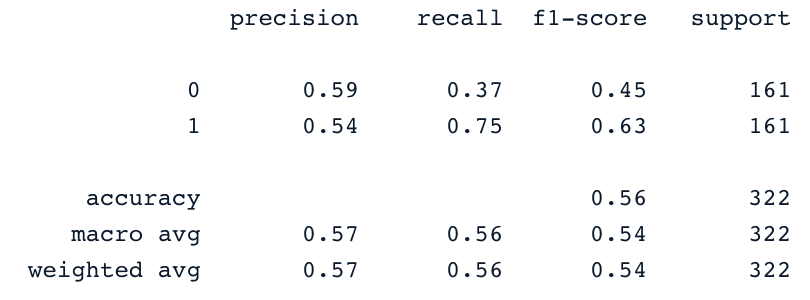
Dĩ nhiên, các kết quả này có thể được cải thiện với kỹ thuật làm giàu đặc trưng và tinh chỉnh siêu tham số. Nhưng chúng đã tốt hơn so với việc dùng dữ liệu gốc bị mất cân bằng.
Thuật toán này là phần mở rộng của thuật toán cây tăng cường theo gradient (gradient-boosted trees) nổi tiếng. Nó là ứng viên tuyệt vời không chỉ để chống overfitting mà còn về tốc độ và hiệu năng.
Để tránh kéo dài, bạn có thể tham khảo Machine Learning với mô hình dựa trên cây trong Python và Machine Learning với mô hình dựa trên cây trong R. Từ các khóa học này, bạn sẽ học cách dùng cả Python và R để triển khai các mô hình dựa trên cây.
Khi machine learning tiếp tục phát triển, các thuật toán và kỹ thuật phân loại mới đã xuất hiện, mang lại hiệu năng, khả năng mở rộng và tính diễn giải tốt hơn. Dưới đây, chúng ta sẽ khám phá một số tiến bộ đáng chú ý đã phổ biến kể từ năm 2022, bao gồm transformers, các phương pháp ensemble sâu và các kỹ thuật AI có thể giải thích (XAI).
Transformers, vốn được thiết kế cho các tác vụ xử lý ngôn ngữ tự nhiên như dịch và sinh văn bản, gần đây đã được điều chỉnh cho nhiều bài toán phân loại ở các lĩnh vực khác nhau. Đổi mới then chốt của transformers là cơ chế tự chú ý (self-attention), cho phép mô hình cân nhắc hiệu quả tầm quan trọng của các phần khác nhau trong dữ liệu đầu vào.
Transformers vượt trội khi xử lý những bộ dữ liệu lớn, phức tạp, và đã được áp dụng rộng rãi trong các ngành như y tế, tài chính và thương mại điện tử cho các tác vụ như nhận dạng ảnh, phát hiện gian lận và hệ thống gợi ý.
Các phương pháp ensemble sâu kết hợp dự đoán của nhiều mô hình để cải thiện độ vững, độ chính xác và ước lượng bất định. Bằng cách tận dụng điểm mạnh của các mô hình khác nhau, những phương pháp này thường vượt trội so với từng mô hình riêng lẻ, đặc biệt ở các bài toán phân loại phức tạp.
Khi các mô hình machine learning trở nên phức tạp hơn, nhu cầu về khả năng diễn giải và minh bạch gia tăng. Các kỹ thuật XAI được phát triển nhằm giúp quá trình ra quyết định của mô hình phân loại trở nên dễ hiểu hơn với con người, điều này rất quan trọng để xây dựng niềm tin vào hệ thống AI, đặc biệt trong các lĩnh vực nhạy cảm như y tế và tài chính.
Các kỹ thuật XAI này ngày càng được tích hợp vào mô hình phân loại không chỉ để tăng tính minh bạch mà còn nhằm tuân thủ yêu cầu pháp lý, như GDPR ở châu Âu, quy định cung cấp giải thích cho các quyết định tự động.
Bài viết khái niệm này đã đề cập những khía cạnh chính của phân loại trong Machine Learning và đưa ra ví dụ về các lĩnh vực ứng dụng. Cuối cùng, bài viết trình bày cách triển khai Hồi quy Logistic và Máy Vectơ Hỗ trợ sau khi thực hiện chiến lược undersampling và oversampling SMOTE để tạo bộ dữ liệu cân bằng cho việc huấn luyện mô hình.
Chúng tôi hy vọng bài viết giúp bạn hiểu rõ hơn về chủ đề phân loại trong Machine Learning. Bạn có thể tiếp tục học với lộ trình Machine Learning Scientist với Python, bao quát cả học có giám sát, không giám sát và học sâu. Lộ trình cũng giới thiệu tốt về xử lý ngôn ngữ tự nhiên, xử lý ảnh, Spark và Keras.
Khóa học Machine Learning
Courses
Courses
Courses