Cours
Apprentissage supervisé en R : Classification
4 h
100.4K
La classification est une méthode d'apprentissage automatique supervisée dans laquelle le modèle tente de prédire l'étiquette correcte d'une donnée d'entrée. Dans la classification, le modèle est entièrement formé à l'aide des données d'apprentissage, puis il est évalué sur des données de test avant d'être utilisé pour effectuer des prédictions sur de nouvelles données inédites.
Par exemple, un algorithme peut apprendre à prédire si un courriel donné est du spam ou du ham (pas de spam), comme illustré ci-dessous.
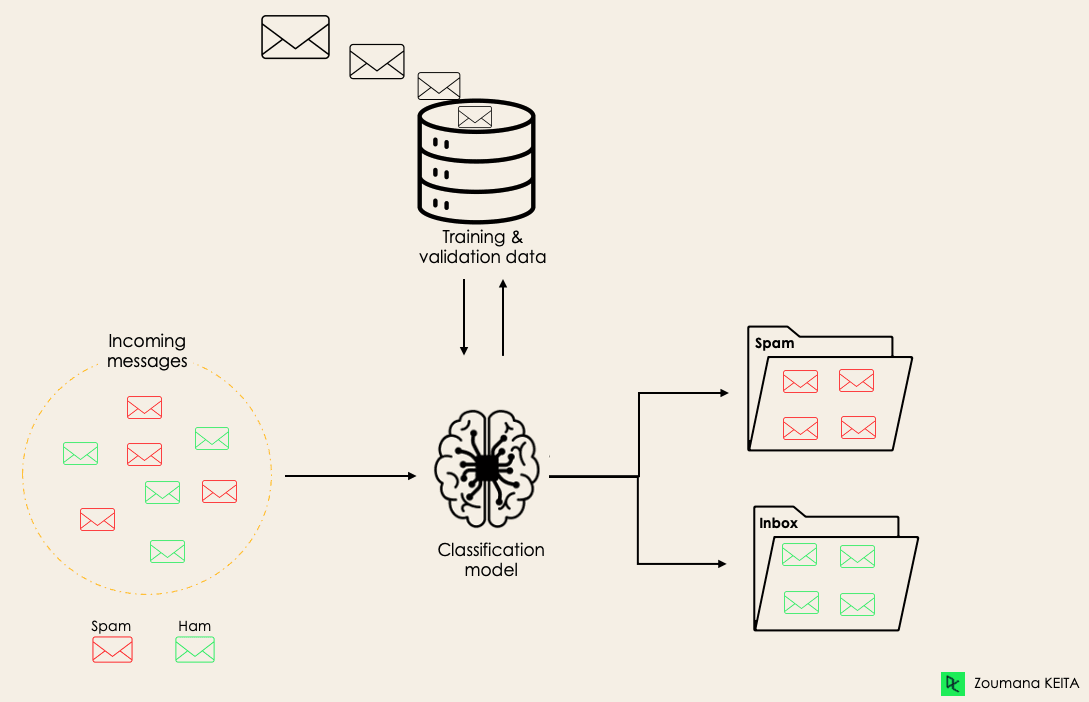 Avant de nous plonger dans le concept de classification, nous allons d'abord comprendre la différence entre les deux types d'apprenants dans la classification : les apprenants paresseux et les apprenants enthousiastes. Nous clarifierons ensuite l'erreur de conception entre la classification et la régression.
Avant de nous plonger dans le concept de classification, nous allons d'abord comprendre la différence entre les deux types d'apprenants dans la classification : les apprenants paresseux et les apprenants enthousiastes. Nous clarifierons ensuite l'erreur de conception entre la classification et la régression.
Il existe deux types d'apprenants dans la classification de l'apprentissage automatique : les apprenants paresseux et les apprenants enthousiastes.
Les apprenants enthousiastes sont des algorithmes d'apprentissage automatique qui construisent d'abord un modèle à partir de l'ensemble de données d'apprentissage avant de faire des prédictions sur les futurs ensembles de données. Ils passent plus de temps au cours du processus de formation en raison de leur volonté d'obtenir une meilleure généralisation au cours de la formation grâce à l'apprentissage des poids, mais ils ont besoin de moins de temps pour faire des prédictions.
La plupart des algorithmes d'apprentissage automatique sont des apprenants enthousiastes, dont voici quelques exemples :
Les apprenants paresseux ou les apprenants basés sur les instances, en revanche, ne créent pas de modèle immédiatement à partir des données d'apprentissage, et c'est de là que vient l'aspect paresseux. Ils se contentent de mémoriser les données d'apprentissage et, à chaque fois qu'il est nécessaire de faire une prédiction, ils recherchent le plus proche voisin à partir de l'ensemble des données d'apprentissage, ce qui les rend très lents lors de la prédiction. En voici quelques exemples :
Toutefois, certains algorithmes, tels que BallTrees et KDTrees, peuvent être utilisés pour améliorer la latence de prédiction.
Il existe quatre grandes catégories d'algorithmes d'apprentissage automatique : supervisé, non supervisé, semi-supervisé et par renforcement.
Bien que la classification et la régression appartiennent toutes deux à la catégorie de l'apprentissage supervisé, elles ne sont pas identiques.
Si vous souhaitez en savoir plus sur la classification, des cours sur l' apprentissage supervisé avec scikit-learn et l'apprentissage supervisé en R pourraient vous être utiles. Ils vous permettent de mieux comprendre comment chaque algorithme aborde les tâches et les fonctions Python et R nécessaires à leur mise en œuvre.
En ce qui concerne la régression, Introduction à la régression en R et Introduction à la régression avec statsmodels en Python vous aideront à explorer différents types de modèles de régression ainsi que leur mise en œuvre en R et en Python.
 classification par apprentissage automatique dans la vie réelle
classification par apprentissage automatique dans la vie réelle Apprentissage automatique supervisé La classification a différentes applications dans de multiples domaines de notre vie quotidienne. Vous trouverez ci-dessous quelques exemples.
La formation d'un modèle d'apprentissage automatique sur les données historiques des patients peut aider les spécialistes de la santé à analyser avec précision leurs diagnostics :
L'éducation est l'un des domaines où l'on trouve le plus de données textuelles, vidéo et audio. Ces informations non structurées peuvent être analysées à l'aide des technologies du langage naturel afin d'effectuer différentes tâches telles que :
Le transport est l'élément clé du développement économique de nombreux pays. En conséquence, les industries utilisent des modèles de machine et d'apprentissage profond :
L'agriculture est l'un des piliers les plus précieux de la survie de l'humanité. L'introduction de la durabilité peut contribuer à améliorer la productivité des agriculteurs à un niveau différent sans nuire à l'environnement :
L'apprentissage automatique comporte quatre tâches principales de classification : les classifications binaires, multi-classes, multi-labels et déséquilibrées.
Dans une tâche de classification binaire, l'objectif est de classer les données d'entrée dans deux catégories qui s'excluent mutuellement. Dans ce cas, les données d'apprentissage sont étiquetées dans un format binaire : vrai et faux ; positif et négatif ; O et 1 ; spam et non spam, etc. en fonction du problème abordé. Par exemple, nous pourrions vouloir détecter si une image donnée est un camion ou un bateau.
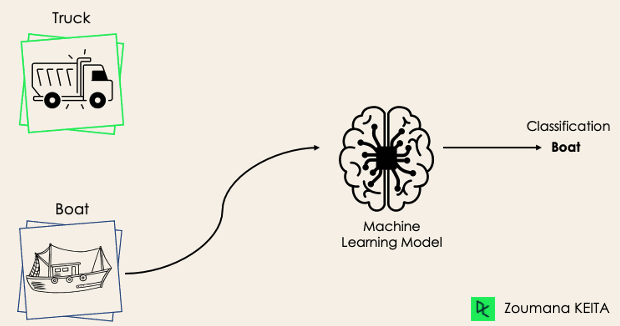
Les algorithmes de régression logistique et de machines à vecteurs de support sont conçus à l'origine pour les classifications binaires. Toutefois, d'autres algorithmes tels que les K-voisins les plus proches et les arbres de décision peuvent également être utilisés pour la classification binaire.
La classification multi-classes, quant à elle, comporte au moins deux étiquettes de classe mutuellement exclusives, l'objectif étant de prédire à quelle classe appartient un exemple d'entrée donné. Dans le cas suivant, le modèle a correctement classé l'image comme étant un avion.
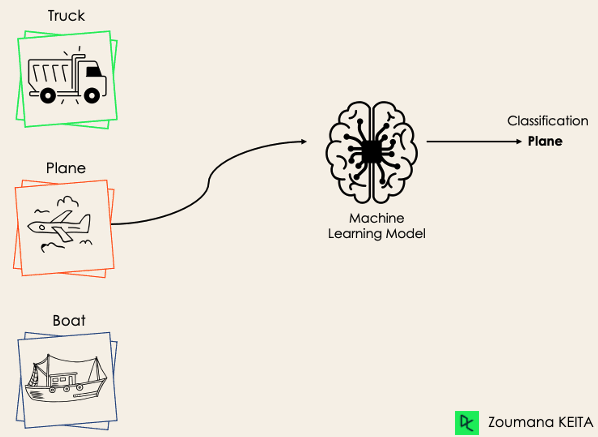
La plupart des algorithmes de classification binaire peuvent également être utilisés pour la classification multi-classes. Ces algorithmes comprennent, sans s'y limiter, les éléments suivants
Mais attendez ! N'avez-vous pas dit que les SVM et la régression logistique ne prennent pas en charge la classification multi-classe par défaut ?
→ C'est exact. Cependant, nous pouvons appliquer des approches de transformation binaire telles que "un contre un" et "un contre tous" pour adapter les algorithmes de classification binaire natifs aux tâches de classification multi-classes.
Un contre un: cette stratégie permet de former autant de classificateurs qu'il y a de paires d'étiquettes. Si nous avons une classification à trois classes, nous aurons trois paires d'étiquettes, donc trois classificateurs, comme indiqué ci-dessous.
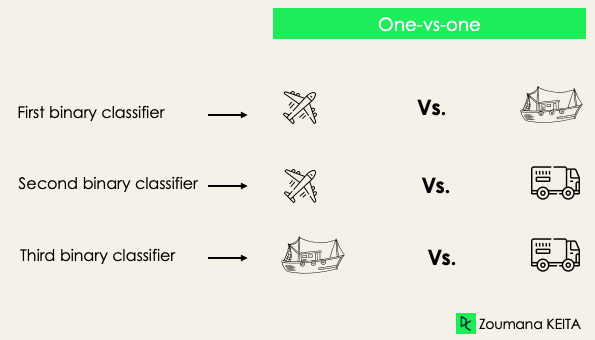
En général, pour N étiquettes, nous aurons Nx(N-1)/2 classificateurs. Chaque classificateur est formé sur un seul ensemble de données binaires et la classe finale est prédite par un vote majoritaire entre tous les classificateurs. L'approche un-vers-un fonctionne mieux pour les SVM et les autres algorithmes à noyau.
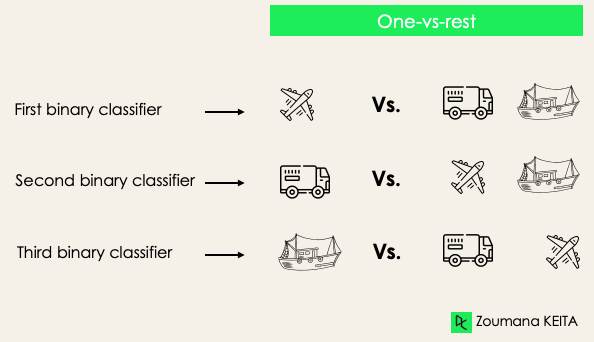
Un contre le reste: à ce stade, nous commençons par considérer chaque étiquette comme une étiquette indépendante et nous considérons le reste combiné comme une seule étiquette. Avec 3 classes, nous aurons trois classificateurs.
En général, pour N étiquettes, nous aurons N classificateurs binaires.
Dans les tâches de classification multi-labels, nous essayons de prédire 0 ou plusieurs classes pour chaque exemple d'entrée. Dans ce cas, il n'y a pas d'exclusion mutuelle car l'exemple d'entrée peut avoir plus d'une étiquette.
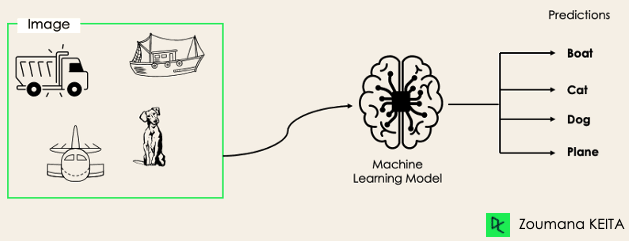
Un tel scénario peut être observé dans différents domaines, tels que l'étiquetage automatique dans le traitement du langage naturel, où un texte donné peut contenir plusieurs sujets. Comme dans le cas de la vision par ordinateur, une image peut contenir plusieurs objets, comme illustré ci-dessous : le modèle prédit que l'image contient : un avion, un bateau, un camion et un chien.
Il n'est pas possible d'utiliser des modèles de classification multi-classes ou binaires pour effectuer une classification multi-labels. Cependant, la plupart des algorithmes utilisés pour ces tâches de classification standard ont leurs versions spécialisées pour la classification multi-labels. Nous pouvons citer :
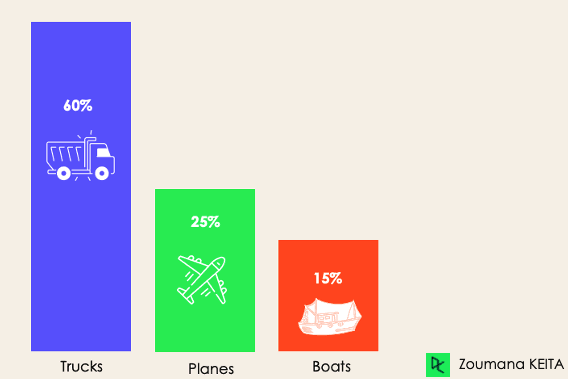
Pour la classification déséquilibrée, le nombre d'exemples est réparti de manière inégale dans chaque classe, ce qui signifie que les données d'apprentissage peuvent contenir plus d'exemples d'une classe que des autres. Considérons le scénario de classification à 3 classes suivant, dans lequel les données d'apprentissage contiennent : 60 % des camions, 25 % des avions et 15 % des bateaux.
Le problème de classification déséquilibrée peut se produire dans le scénario suivant :
L'utilisation de modèles prédictifs conventionnels tels que les arbres de décision, la régression logistique, etc. pourrait ne pas être efficace dans le cas d'un ensemble de données déséquilibré, parce qu'ils pourraient être biaisés en prédisant la classe avec le plus grand nombre d'observations, et en considérant les classes avec moins d'observations comme du bruit.
Cela signifie-t-il que ces problèmes ne se posent plus ?
Bien sûr que non ! Nous pouvons utiliser plusieurs approches pour résoudre le problème du déséquilibre dans un ensemble de données. Les approches les plus couramment utilisées comprennent les techniques d'échantillonnage ou l'exploitation de la puissance des algorithmes sensibles aux coûts.
Ces techniques visent à équilibrer la distribution de l'original par :
Ces algorithmes prennent en compte le coût des erreurs de classification. Ils visent à minimiser le coût total généré par les modèles.
Maintenant que nous avons une idée des différents types de modèles de classification, il est crucial de choisir les bonnes mesures d'évaluation pour ces modèles. Dans cette section, nous aborderons les mesures les plus couramment utilisées : exactitude, précision, rappel, score F1, aire sous la courbe ROC (Receiver Operating Characteristic) et AUC (Area Under the Curve).



Nous avons maintenant tous les outils en main pour procéder à la mise en œuvre de certains algorithmes. Cette section présente quatre algorithmes et leur mise en œuvre sur l' ensemble de données des prêts afin d'illustrer certains des concepts abordés précédemment, en particulier pour les ensembles de données déséquilibrés utilisant une tâche de classification binaire. Par souci de simplicité, nous nous concentrerons sur quatre algorithmes seulement.
L'objectif n'est pas d'obtenir le meilleur modèle possible, mais d'illustrer la manière d'entraîner chacun des algorithmes suivants. Le code source est disponible sur DataLab, où vous pouvez tout exécuter en un seul clic.
import pandas as pd
loan_data = pd.read_csv("loan_data.csv")
loan_data.head()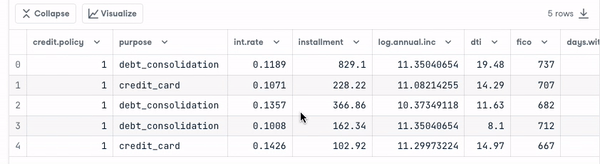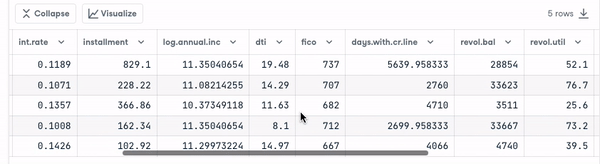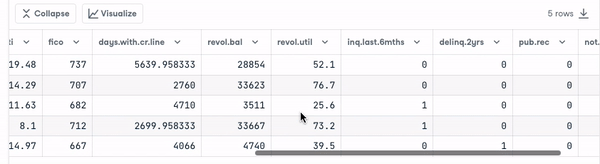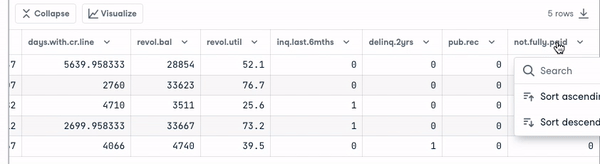
import matplotlib.pyplot as plt
# Helper function for data distribution
# Visualize the proportion of borrowers
def show_loan_distrib(data):
count = ""
if isinstance(data, pd.DataFrame):
count = data["not.fully.paid"].value_counts()
else:
count = data.value_counts()
count.plot(kind = 'pie', explode = [0, 0.1],
figsize = (6, 6), autopct = '%1.1f%%', shadow = True)
plt.ylabel("Loan: Fully Paid Vs. Not Fully Paid")
plt.legend(["Fully Paid", "Not Fully Paid"])
plt.show()
# Visualize the proportion of borrowers
show_loan_distrib(loan_data)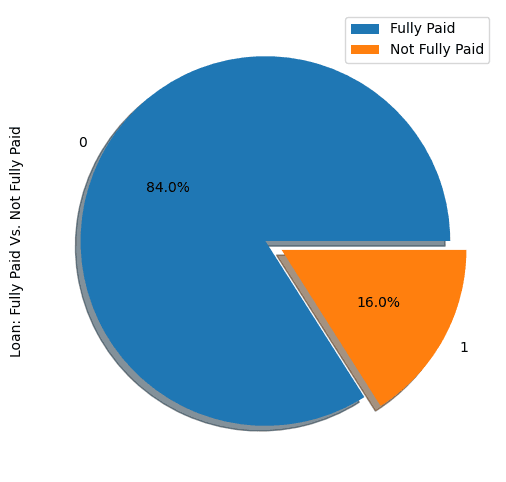
Le graphique ci-dessus montre que 84 % des emprunteurs ont remboursé leur prêt et que seuls 16 % ne l'ont pas remboursé, ce qui rend l'ensemble des données vraiment déséquilibré.
Avant d'aller plus loin, nous devons vérifier le type des variables afin d'encoder celles qui doivent l'être.
Nous remarquons que toutes les colonnes sont des variables continues, à l'exception de l'attribut " objet", qui doit être codé.

# Check column types
print(loan_data.dtypes)
encoded_loan_data = pd.get_dummies(loan_data, prefix="purpose",
drop_first=True)
print(encoded_loan_data.dtypes)X = encoded_loan_data.drop('not.fully.paid', axis = 1)
y = encoded_loan_data['not.fully.paid']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.30,
stratify = y, random_state=2022)Nous étudierons ici deux stratégies d'échantillonnage : le sous-échantillonnage aléatoire et le suréchantillonnage SMOTE.
Nous sous-échantillonnerons la classe majoritaire, qui correspond à la classe "entièrement payée" (classe 0).
X_train_cp = X_train.copy()
X_train_cp['not.fully.paid'] = y_train
y_0 = X_train_cp[X_train_cp['not.fully.paid'] == 0]
y_1 = X_train_cp[X_train_cp['not.fully.paid'] == 1]
y_0_undersample = y_0.sample(y_1.shape[0])
loan_data_undersample = pd.concat([y_0_undersample, y_1], axis = 0)
# Visualize the proportion of borrowers
show_loan_distrib(loan_data_undersample)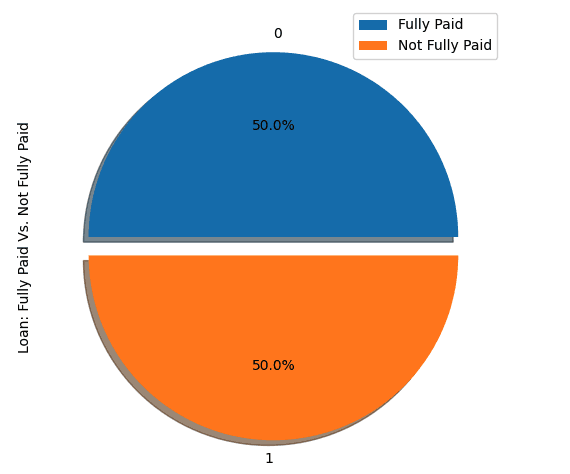
Effectuer un suréchantillonnage sur la classe minoritaire
smote = SMOTE(sampling_strategy='minority')
X_train_SMOTE, y_train_SMOTE = smote.fit_resample(X_train,y_train)
# Visualize the proportion of borrowers
show_loan_distrib(y_train_SMOTE)Après avoir appliqué les stratégies d'échantillonnage, nous observons que l'ensemble des données est réparti de manière égale entre les différents types d'emprunteurs.
Cette section applique ces deux algorithmes de classification à l'ensemble de données échantillonnées SMOTE smote. La même approche de formation peut être appliquée aux données sous-échantillonnées.
Il s'agit d'un algorithme explicable. Il classe un point de données en modélisant sa probabilité d'appartenance à une classe donnée à l'aide de la fonction sigmoïde.
X = loan_data_undersample.drop('not.fully.paid', axis = 1)
y = loan_data_undersample['not.fully.paid']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.15, stratify = y, random_state=2022)
logistic_classifier = LogisticRegression()
logistic_classifier.fit(X_train, y_train)
y_pred = logistic_classifier.predict(X_test)
print(confusion_matrix(y_test,y_pred))
print(classification_report(y_test,y_pred))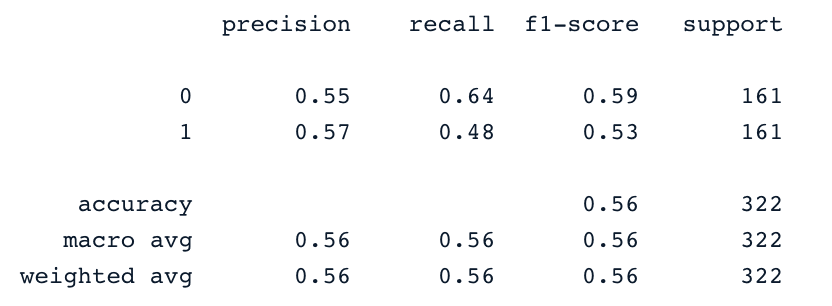
Cet algorithme peut être utilisé pour la classification et la régression. Il apprend à dessiner l'hyperplan (frontière de décision) en utilisant le principe de maximisation de la marge. Cette limite de décision est tracée à travers les deux vecteurs de soutien les plus proches.
Les SVM proposent une stratégie de transformation appelée "kernel tricks", utilisée pour projeter des données séparables non apprenantes dans un espace de dimension supérieure afin de les rendre linéairement séparables.
from sklearn.svm import SVC
svc_classifier = SVC(kernel='linear')
svc_classifier.fit(X_train, y_train)
# Make Prediction & print the result
y_pred = svc_classifier.predict(X_test)
print(classification_report(y_test,y_pred))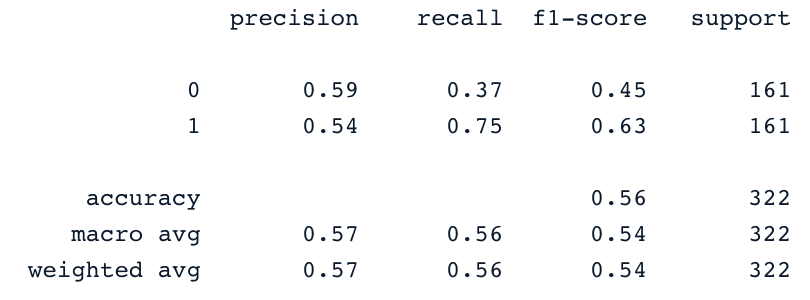
Ces résultats peuvent bien sûr être améliorés grâce à une ingénierie des caractéristiques plus poussée et à un réglage plus fin. Mais elles sont meilleures que l'utilisation des données déséquilibrées d'origine.
Cet algorithme est une extension d'un algorithme bien connu appelé arbres boostés par le gradient. Il s'agit d'un excellent candidat, non seulement pour lutter contre l'overfitting, mais aussi pour la vitesse et la performance.
Pour ne pas allonger le texte, vous pouvez vous référer à Machine Learning with Tree-Based Models in Python et Machine Learning with Tree-Based Models in R. Grâce à ces cours, vous apprendrez à utiliser Python et R pour mettre en œuvre des modèles basés sur les arbres.
Au fur et à mesure de l'évolution de l'apprentissage automatique, de nouveaux algorithmes et techniques de classification sont apparus, offrant de meilleures performances, une plus grande évolutivité et une plus grande facilité d'interprétation. Nous examinerons ici certaines des avancées les plus notables qui ont gagné en popularité depuis 2022, notamment les transformateurs, les méthodes d'ensemble profondes et les techniques d'IA explicable (XAI).
Les transformateurs, conçus à l'origine pour des tâches de traitement du langage naturel telles que la traduction et la génération de textes, ont récemment été adaptés à diverses tâches de classification dans différents domaines. La principale innovation des transformateurs réside dans l'utilisation de mécanismes d'auto-attention, qui permettent aux modèles d'évaluer efficacement l'importance des différentes parties des données d'entrée.
Les transformateurs excellent dans le traitement de grands ensembles de données complexes et ont été largement adoptés dans des secteurs tels que les soins de santé, la finance et le commerce électronique pour des tâches telles que la reconnaissance d'images, la détection de la fraude et les systèmes de recommandation.
Les méthodes d'ensemble profond combinent les prévisions de plusieurs modèles pour améliorer la robustesse, la précision et l'estimation de l'incertitude. En exploitant les points forts de différents modèles, ces méthodes peuvent souvent être plus performantes que les modèles individuels, en particulier dans les tâches de classification complexes.
Les modèles d'apprentissage automatique devenant de plus en plus complexes, le besoin d'interprétabilité et de transparence s'est accru. Des techniques d'IA explicable (XAI) ont été développées pour rendre le processus décisionnel des modèles de classification plus compréhensible pour les humains, ce qui est crucial pour gagner la confiance des systèmes d'IA, en particulier dans les domaines à fort enjeu tels que les soins de santé et la finance.
Ces techniques XAI sont de plus en plus intégrées dans les modèles de classification non seulement pour améliorer la transparence, mais aussi pour se conformer aux exigences réglementaires, telles que le règlement général sur la protection des données (RGPD) en Europe, qui impose des explications pour les décisions automatisées.
Ce blog conceptuel a couvert l'aspect principal des classifications dans l'apprentissage automatique et vous a également fourni quelques exemples de différents domaines auxquels elles sont appliquées. Enfin, il couvre la mise en œuvre de la régression logistique et de la machine à vecteurs de support après avoir exécuté les stratégies de sous-échantillonnage et de suréchantillonnage SMOTE afin de générer un ensemble de données équilibré pour l'entraînement des modèles.
Nous espérons que cela vous a aidé à mieux comprendre le sujet de la classification dans l'apprentissage automatique. Vous pouvez approfondir votre apprentissage en suivant la filière Machine Learning Scientist with Python, qui couvre à la fois l'apprentissage supervisé, l'apprentissage non supervisé et l'apprentissage profond. Il constitue également une bonne introduction au traitement du langage naturel, au traitement des images, à Spark et à Keras.
Cours sur l'apprentissage automatique
Cours
Cours
Cours
blog
Tutoriel
Samuel Shaibu
Tutoriel
Tutoriel
Derrick Mwiti
Tutoriel
Mark Pedigo
Tutoriel
Sejal Jaiswal

