Curso
Aprendizagem supervisionada em R: Classificação
4 h
100.4K
A classificação é um método de aprendizado de máquina supervisionado em que o modelo tenta prever o rótulo correto de um determinado dado de entrada. Na classificação, o modelo é totalmente treinado usando os dados de treinamento e, em seguida, é avaliado nos dados de teste antes de ser usado para realizar a previsão em novos dados não vistos.
Por exemplo, um algoritmo pode aprender a prever se um determinado e-mail é spam ou ham (sem spam), conforme ilustrado abaixo.
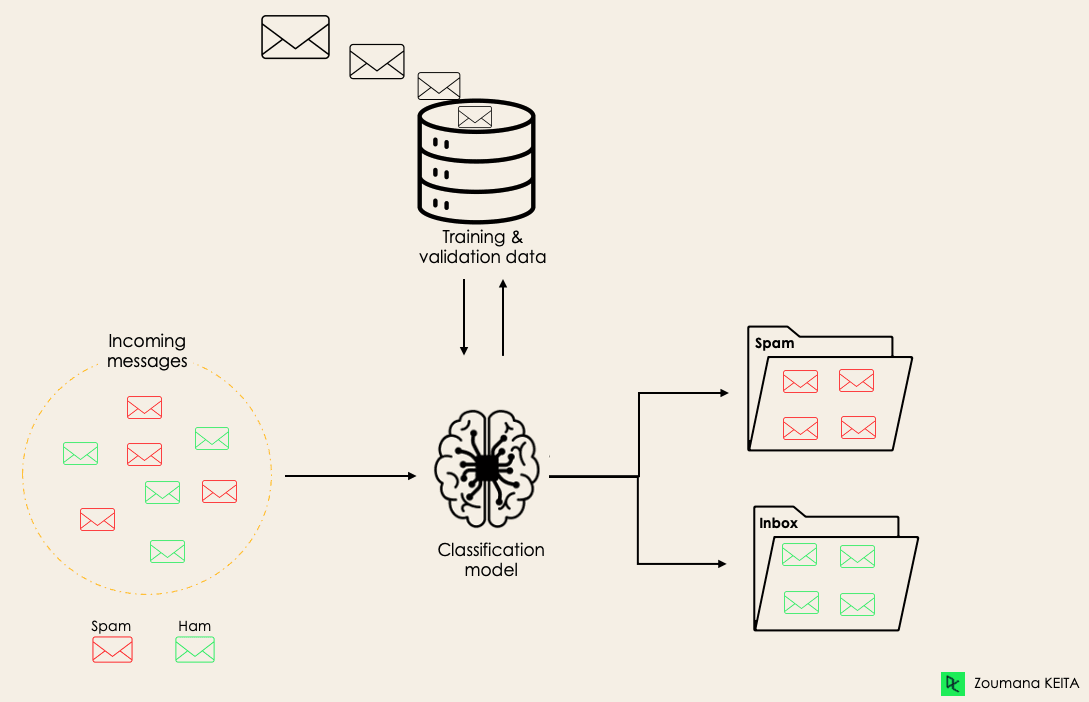 Antes de mergulhar no conceito de classificação, primeiro entenderemos a diferença entre os dois tipos de alunos na classificação: alunos preguiçosos e ansiosos. Em seguida, esclareceremos o equívoco entre classificação e regressão.
Antes de mergulhar no conceito de classificação, primeiro entenderemos a diferença entre os dois tipos de alunos na classificação: alunos preguiçosos e ansiosos. Em seguida, esclareceremos o equívoco entre classificação e regressão.
Há dois tipos de alunos na classificação de aprendizado de máquina: alunos preguiçosos e ansiosos.
Os Eager learners são algoritmos de aprendizado de máquina que primeiro criam um modelo a partir do conjunto de dados de treinamento antes de fazer qualquer previsão em conjuntos de dados futuros. Eles gastam mais tempo durante o processo de treinamento devido à sua ânsia de obter uma melhor generalização durante o treinamento a partir do aprendizado dos pesos, mas precisam de menos tempo para fazer previsões.
A maioria dos algoritmos de aprendizado de máquina são aprendizes ávidos, e abaixo estão alguns exemplos:
Os alunos preguiçosos ou baseados em instâncias, por outro lado, não criam nenhum modelo imediatamente a partir dos dados de treinamento, e é daí que vem o aspecto preguiçoso. Eles apenas memorizam os dados de treinamento e, sempre que há necessidade de fazer uma previsão, procuram o vizinho mais próximo de todos os dados de treinamento, o que os torna muito lentos durante a previsão. Alguns exemplos desse tipo são:
No entanto, alguns algoritmos, como o BallTrees e o KDTrees, podem ser usados para melhorar a latência da previsão.
Há quatro categorias principais de algoritmos de aprendizado de máquina: supervisionado, não supervisionado, semissupervisionado e aprendizado por reforço.
Embora a classificação e a regressão sejam ambas da categoria de aprendizado supervisionado, elas não são a mesma coisa.
Se você estiver interessado em saber mais sobre classificação, os cursos sobre Aprendizagem supervisionada com scikit-learn e Aprendizagem supervisionada em R podem ser úteis. Eles fornecem a você uma melhor compreensão de como cada algoritmo aborda as tarefas e as funções Python e R necessárias para implementá-las.
Em relação à regressão, Introduction to Regression in R e Introduction to Regression with statsmodels in Python ajudarão você a explorar diferentes tipos de modelos de regressão, bem como sua implementação em R e Python.
 de classificação de aprendizado de máquina na vida real
de classificação de aprendizado de máquina na vida real A classificação supervisionada do aprendizado de máquina tem diferentes aplicações em vários domínios da nossa vida cotidiana. Abaixo estão alguns exemplos.
O treinamento de um modelo de aprendizado de máquina em dados históricos de pacientes pode ajudar os especialistas em saúde a analisar com precisão seus diagnósticos:
A educação é um dos domínios que mais lidam com dados textuais, de vídeo e de áudio. Essas informações não estruturadas podem ser analisadas com a ajuda de tecnologias de linguagem natural para realizar diferentes tarefas, como:
O transporte é o principal componente do desenvolvimento econômico de muitos países. Como resultado, os setores estão usando modelos de aprendizado profundo e de máquina:
A agricultura é um dos pilares mais valiosos da sobrevivência humana. A introdução da sustentabilidade pode ajudar a melhorar a produtividade dos agricultores em um nível diferente, sem prejudicar o meio ambiente:
Há quatro tarefas principais de classificação no aprendizado de máquina: classificações binárias, de várias classes, de vários rótulos e desequilibradas.
Em uma tarefa de classificação binária, o objetivo é classificar os dados de entrada em duas categorias mutuamente exclusivas. Os dados de treinamento em tal situação são rotulados em um formato binário: verdadeiro e falso; positivo e negativo; O e 1; spam e não spam etc., dependendo do problema que está sendo abordado. Por exemplo, podemos querer detectar se uma determinada imagem é um caminhão ou um barco.
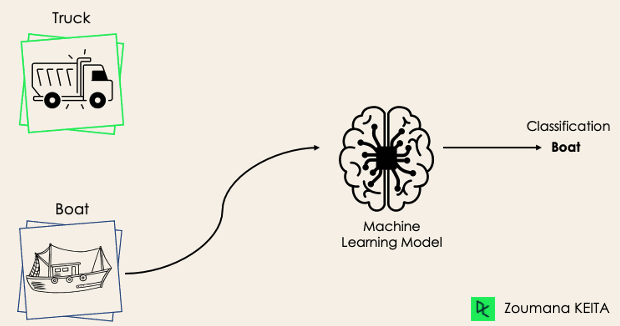
Os algoritmos Logistic Regression e Support Vector Machines são projetados nativamente para classificações binárias. No entanto, outros algoritmos, como K-Nearest Neighbors e Decision Trees, também podem ser usados para classificação binária.
A classificação multiclasse, por outro lado, tem pelo menos dois rótulos de classe mutuamente exclusivos, em que o objetivo é prever a qual classe um determinado exemplo de entrada pertence. No caso a seguir, o modelo classificou corretamente a imagem como sendo um plano.
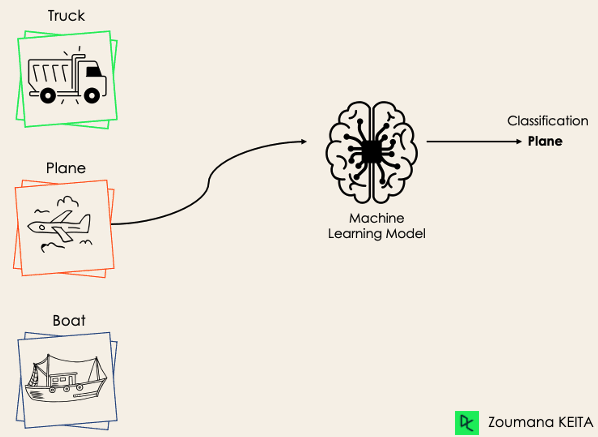
A maioria dos algoritmos de classificação binária também pode ser usada para classificação multiclasse. Esses algoritmos incluem, mas não se limitam a:
Mas espere! Você não disse que o SVM e a regressão logística não oferecem suporte à classificação multiclasse por padrão?
→ Você está certo. No entanto, podemos aplicar abordagens de transformação binária, como um-versus-um e um-versus-tudo, para adaptar algoritmos de classificação binária nativa para tarefas de classificação multiclasse.
Um contra um: essa estratégia treina tantos classificadores quanto o número de pares de rótulos. Se tivermos uma classificação de 3 classes, teremos três pares de rótulos e, portanto, três classificadores, conforme mostrado abaixo.
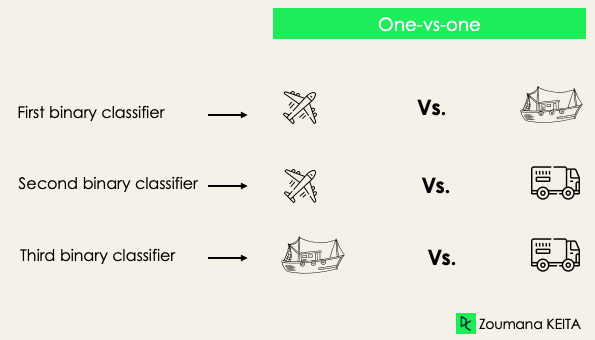
Em geral, para N rótulos, teremos Nx(N-1)/2 classificadores. Cada classificador é treinado em um único conjunto de dados binários, e a classe final é prevista por um voto majoritário entre todos os classificadores. A abordagem um contra um funciona melhor para SVM e outros algoritmos baseados em kernel.
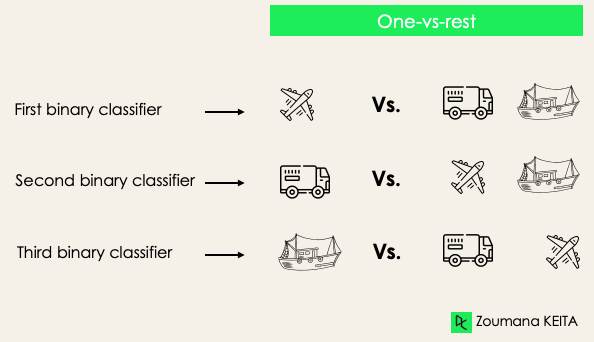
Um contra o restante: nesse estágio, começamos considerando cada rótulo como um rótulo independente e consideramos o restante combinado como apenas um rótulo. Com 3 classes, teremos três classificadores.
Em geral, para N rótulos, teremos N classificadores binários.
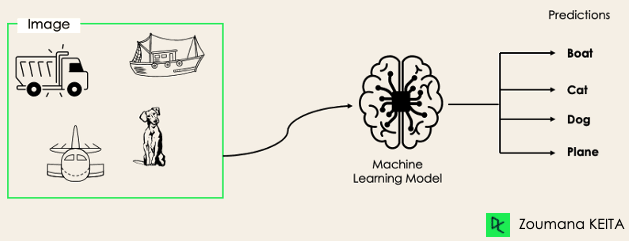
Em tarefas de classificação com vários rótulos, tentamos prever 0 ou mais classes para cada exemplo de entrada. Nesse caso, não há exclusão mútua porque o exemplo de entrada pode ter mais de um rótulo.
Esse cenário pode ser observado em diferentes domínios, como a marcação automática no processamento de idiomas naturais, em que um determinado texto pode conter vários tópicos. Da mesma forma que a visão computacional, uma imagem pode conter vários objetos, conforme ilustrado abaixo: o modelo previu que a imagem contém: um avião, um barco, um caminhão e um cachorro.
Não é possível usar modelos de classificação binária ou de várias classes para realizar a classificação com vários rótulos. No entanto, a maioria dos algoritmos usados para essas tarefas de classificação padrão tem suas versões especializadas para classificação com vários rótulos. Podemos citar:
Para a classificação desequilibrada, o número de exemplos é distribuído de forma desigual em cada classe, o que significa que podemos ter mais de uma classe do que de outras nos dados de treinamento. Vamos considerar o seguinte cenário de classificação de 3 classes em que os dados de treinamento contêm: 60% dos caminhões, 25% dos aviões e 15% dos barcos.
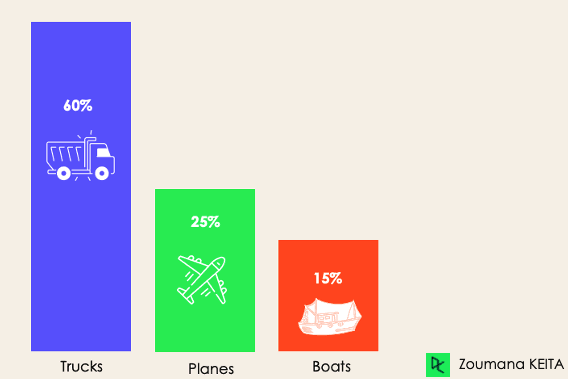
O problema de classificação desequilibrada pode ocorrer no seguinte cenário:
O uso de modelos preditivos convencionais, como Árvores de decisão, Regressão logística etc., pode não ser eficaz ao lidar com um conjunto de dados desequilibrado, porque eles podem ser tendenciosos para prever a classe com o maior número de observações e considerar aquelas com menos números como ruído.
Então, isso significa que esses problemas foram deixados para trás?
É claro que não! Podemos usar várias abordagens para lidar com o problema de desequilíbrio em um conjunto de dados. As abordagens mais comumente usadas incluem técnicas de amostragem ou o aproveitamento do poder dos algoritmos sensíveis ao custo.
Essas técnicas visam equilibrar a distribuição do by original:
Esses algoritmos levam em consideração o custo da classificação incorreta. Seu objetivo é minimizar o custo total gerado pelos modelos.
Agora que temos uma ideia dos diferentes tipos de modelos de classificação, é fundamental escolher as métricas de avaliação corretas para esses modelos. Nesta seção, abordaremos as métricas mais comumente usadas: exatidão, precisão, recuperação, pontuação F1 e área sob a curva ROC (Receiver Operating Characteristic) e AUC (Area Under the Curve).



Agora temos todas as ferramentas em mãos para prosseguir com a implementação de alguns algoritmos. Esta seção abordará quatro algoritmos e sua implementação no conjunto de dados de empréstimos para ilustrar alguns dos conceitos abordados anteriormente, especialmente para os conjuntos de dados desequilibrados que usam uma tarefa de classificação binária. Para simplificar, vamos nos concentrar em apenas quatro algoritmos.
O objetivo não é ter o melhor modelo possível, mas ilustrar como treinar cada um dos algoritmos a seguir. O código-fonte está disponível no DataLab, onde você pode executar tudo com um clique.
import pandas as pd
loan_data = pd.read_csv("loan_data.csv")
loan_data.head()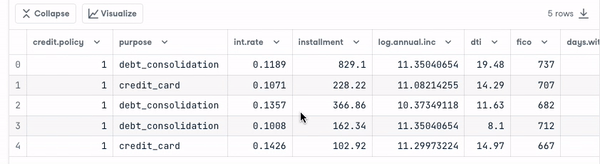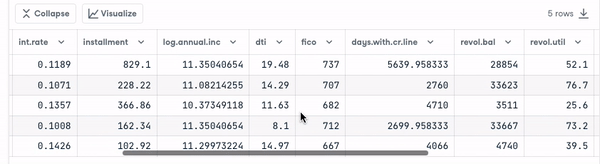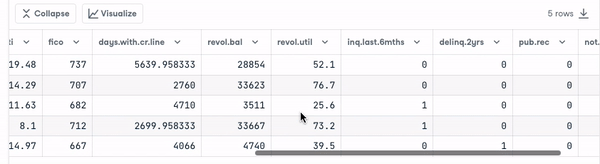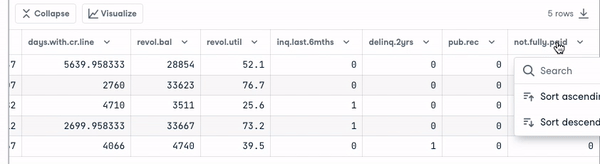
import matplotlib.pyplot as plt
# Helper function for data distribution
# Visualize the proportion of borrowers
def show_loan_distrib(data):
count = ""
if isinstance(data, pd.DataFrame):
count = data["not.fully.paid"].value_counts()
else:
count = data.value_counts()
count.plot(kind = 'pie', explode = [0, 0.1],
figsize = (6, 6), autopct = '%1.1f%%', shadow = True)
plt.ylabel("Loan: Fully Paid Vs. Not Fully Paid")
plt.legend(["Fully Paid", "Not Fully Paid"])
plt.show()
# Visualize the proportion of borrowers
show_loan_distrib(loan_data)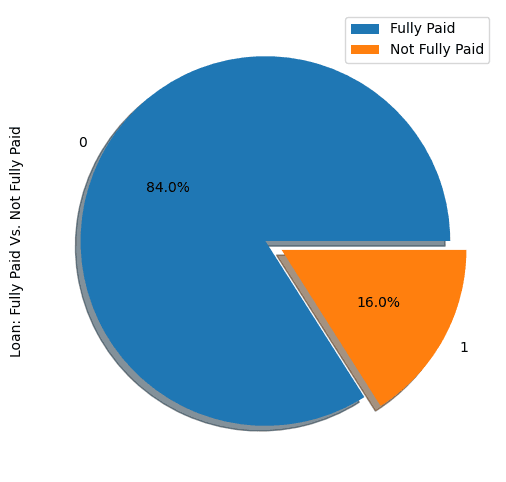
No gráfico acima, notamos que 84% dos mutuários pagaram seus empréstimos e apenas 16% não os pagaram, o que torna o conjunto de dados realmente desequilibrado.
Antes de continuar, precisamos verificar o tipo das variáveis para que possamos codificar aquelas que precisam ser codificadas.
Observamos que todas as colunas são variáveis contínuas, exceto o atributo purpose, que precisa ser codificado.

# Check column types
print(loan_data.dtypes)
encoded_loan_data = pd.get_dummies(loan_data, prefix="purpose",
drop_first=True)
print(encoded_loan_data.dtypes)X = encoded_loan_data.drop('not.fully.paid', axis = 1)
y = encoded_loan_data['not.fully.paid']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.30,
stratify = y, random_state=2022)Exploraremos duas estratégias de amostragem aqui: subamostragem aleatória e sobreamostragem SMOTE.
Vamos subamostrar a classe majoritária, que corresponde à "totalmente paga" (classe 0).
X_train_cp = X_train.copy()
X_train_cp['not.fully.paid'] = y_train
y_0 = X_train_cp[X_train_cp['not.fully.paid'] == 0]
y_1 = X_train_cp[X_train_cp['not.fully.paid'] == 1]
y_0_undersample = y_0.sample(y_1.shape[0])
loan_data_undersample = pd.concat([y_0_undersample, y_1], axis = 0)
# Visualize the proportion of borrowers
show_loan_distrib(loan_data_undersample)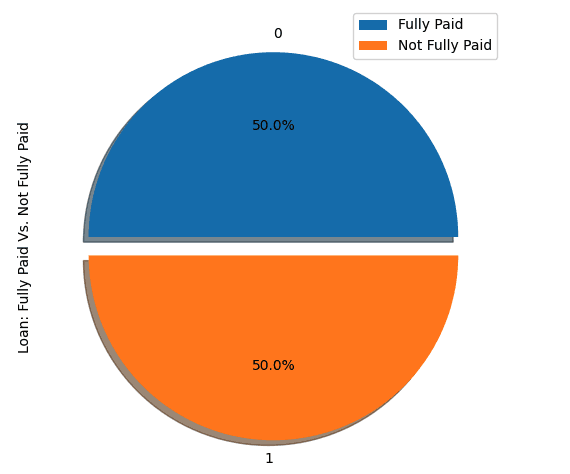
Realizar uma superamostragem na classe minoritária
smote = SMOTE(sampling_strategy='minority')
X_train_SMOTE, y_train_SMOTE = smote.fit_resample(X_train,y_train)
# Visualize the proportion of borrowers
show_loan_distrib(y_train_SMOTE)Após aplicar as estratégias de amostragem, observamos que o conjunto de dados está igualmente distribuído entre os diferentes tipos de mutuários.
Esta seção aplicará esses dois algoritmos de classificação ao conjunto de dados de amostragem SMOTE smote. A mesma abordagem de treinamento também pode ser aplicada a dados com amostragem insuficiente.
Esse é um algoritmo explicável. Ele classifica um ponto de dados modelando sua probabilidade de pertencer a uma determinada classe usando a função sigmoide.
X = loan_data_undersample.drop('not.fully.paid', axis = 1)
y = loan_data_undersample['not.fully.paid']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.15, stratify = y, random_state=2022)
logistic_classifier = LogisticRegression()
logistic_classifier.fit(X_train, y_train)
y_pred = logistic_classifier.predict(X_test)
print(confusion_matrix(y_test,y_pred))
print(classification_report(y_test,y_pred))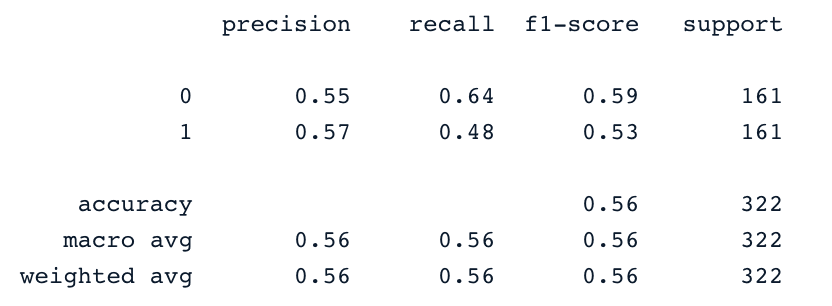
Esse algoritmo pode ser usado tanto para classificação quanto para regressão. Ele aprende a desenhar o hiperplano (limite de decisão) usando o princípio de maximização da margem. Esse limite de decisão é traçado por meio dos dois vetores de suporte mais próximos.
O SVM oferece uma estratégia de transformação chamada de truques de kernel usados para projetar dados separáveis não aprendidos em um espaço de dimensão mais alta para torná-los linearmente separáveis.
from sklearn.svm import SVC
svc_classifier = SVC(kernel='linear')
svc_classifier.fit(X_train, y_train)
# Make Prediction & print the result
y_pred = svc_classifier.predict(X_test)
print(classification_report(y_test,y_pred))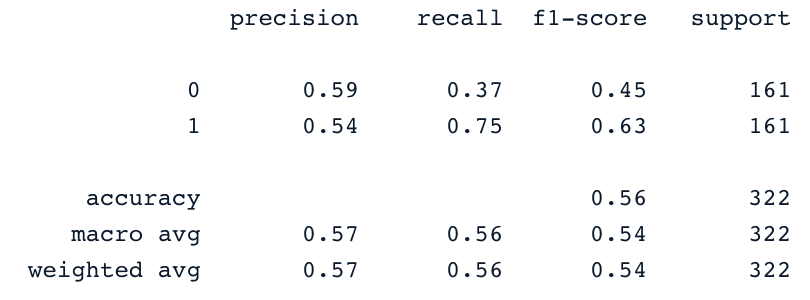
É claro que esses resultados podem ser aprimorados com mais engenharia de recursos e ajuste fino. Mas eles são melhores do que usar os dados originais desequilibrados.
Esse algoritmo é uma extensão de um algoritmo bem conhecido chamado de árvores com reforço de gradiente. Ele é um ótimo candidato não apenas para combater o excesso de ajuste, mas também para velocidade e desempenho.
Para não ficar mais longo, você pode consultar Aprendizado de máquina com modelos baseados em árvores em Python e Aprendizado de máquina com modelos baseados em árvores em R. Com esses cursos, você aprenderá a usar Python e R para implementar modelos baseados em árvores.
Como o aprendizado de máquina continua a evoluir, surgiram novos algoritmos e técnicas de classificação que oferecem melhor desempenho, escalabilidade e interpretabilidade. Aqui, exploraremos alguns dos avanços mais notáveis que ganharam popularidade desde 2022, incluindo transformadores, métodos de conjunto profundo e técnicas de IA explicável (XAI).
Os transformadores, originalmente projetados para tarefas de processamento de linguagem natural, como tradução e geração de texto, foram recentemente adaptados para várias tarefas de classificação em diferentes domínios. A principal inovação dos transformadores é o uso de mecanismos de autoatenção, que permitem que os modelos avaliem a importância de diferentes partes dos dados de entrada de forma eficaz.
Os transformadores são excelentes para lidar com conjuntos de dados grandes e complexos e foram amplamente adotados em setores como saúde, finanças e comércio eletrônico para tarefas como reconhecimento de imagens, detecção de fraudes e sistemas de recomendação.
Os métodos de conjunto profundo combinam as previsões de vários modelos para melhorar a robustez, a precisão e a estimativa de incerteza. Ao aproveitar os pontos fortes de diferentes modelos, esses métodos podem, muitas vezes, superar os modelos individuais, especialmente em tarefas de classificação complexas.
À medida que os modelos de aprendizado de máquina se tornam mais complexos, aumenta a necessidade de interpretabilidade e transparência. As técnicas de IA explicável (XAI) foram desenvolvidas para tornar o processo de tomada de decisão dos modelos de classificação mais compreensível para os seres humanos, o que é fundamental para ganhar confiança nos sistemas de IA, especialmente em domínios de alto risco, como saúde e finanças.
Essas técnicas de XAI estão sendo cada vez mais integradas aos modelos de classificação não apenas para melhorar a transparência, mas também para atender aos requisitos regulamentares, como o Regulamento Geral de Proteção de Dados (GDPR) na Europa, que exige explicações para decisões automatizadas.
Este blog conceitual abordou o aspecto principal das classificações no aprendizado de máquina e também forneceu a você alguns exemplos de diferentes domínios aos quais elas são aplicadas. Por fim, abordou a implementação da Regressão Logística e da Máquina de Vetor de Suporte após a execução das estratégias de subamostragem e superamostragem SMOTE para gerar um conjunto de dados equilibrado para o treinamento dos modelos.
Esperamos que isso tenha ajudado você a entender melhor esse tópico de classificação no aprendizado de máquina. Você pode aprofundar seu aprendizado seguindo o curso Machine Learning Scientist with Python, que abrange o aprendizado supervisionado, não supervisionado e profundo. Ele também oferece uma boa introdução ao processamento de linguagem natural, processamento de imagens, Spark e Keras.
Cursos de aprendizado de máquina
Curso
Curso
Curso
blog
Moez Ali
15 min
blog
Matt Crabtree
14 min
blog
Natassha Selvaraj
15 min
blog
DataCamp Team
11 min
blog
Abid Ali Awan
5 min
Tutorial
Moez Ali


