Kursus
Supervised Learning di R: Klasifikasi
4 Hr
100.7K
Klasifikasi adalah metode machine learning terawasi (supervised) di mana model mencoba memprediksi label yang benar dari data masukan tertentu. Dalam klasifikasi, model dilatih sepenuhnya menggunakan data latih, lalu dievaluasi pada data uji sebelum digunakan untuk melakukan prediksi pada data baru yang belum pernah dilihat.
Misalnya, sebuah algoritma dapat belajar memprediksi apakah sebuah email termasuk spam atau ham (bukan spam), seperti yang diilustrasikan di bawah ini.
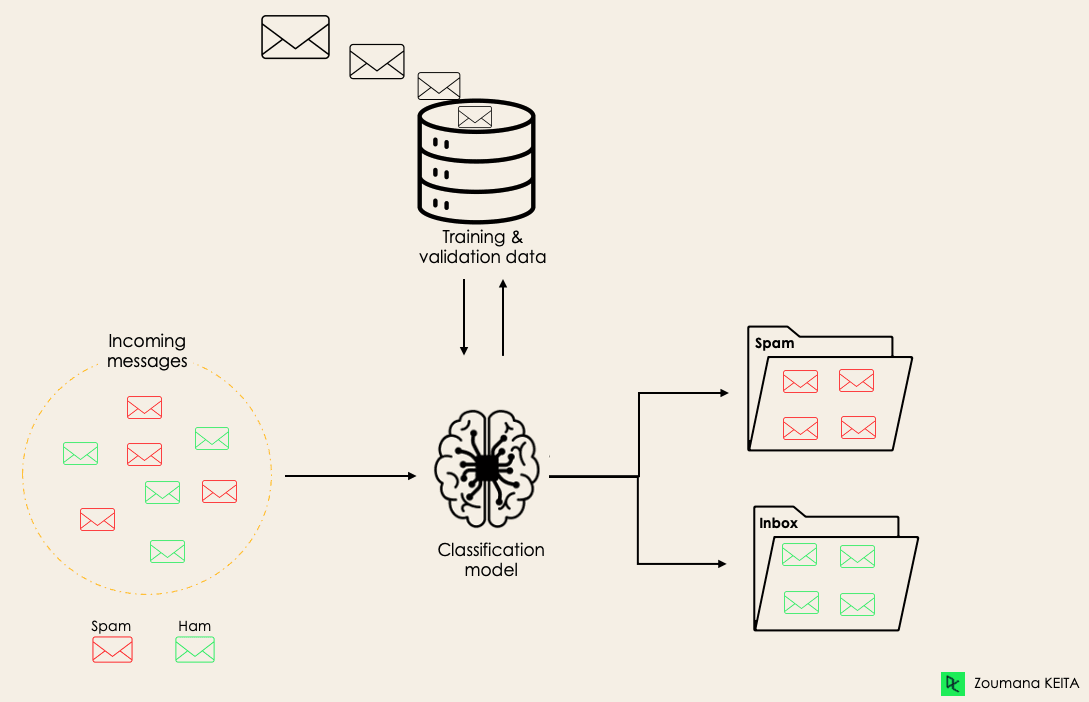 Sebelum mendalami konsep klasifikasi, kita akan terlebih dahulu memahami perbedaan antara dua tipe learner dalam klasifikasi: lazy dan eager learner. Kemudian kita akan meluruskan kesalahpahaman antara klasifikasi dan regresi.
Sebelum mendalami konsep klasifikasi, kita akan terlebih dahulu memahami perbedaan antara dua tipe learner dalam klasifikasi: lazy dan eager learner. Kemudian kita akan meluruskan kesalahpahaman antara klasifikasi dan regresi.
Ada dua tipe learner dalam klasifikasi machine learning: lazy dan eager learner.
Eager learner adalah algoritma machine learning yang terlebih dahulu membangun model dari dataset pelatihan sebelum membuat prediksi pada dataset mendatang. Mereka menghabiskan lebih banyak waktu selama proses pelatihan karena berupaya menghasilkan generalisasi yang lebih baik melalui pembelajaran bobot, tetapi membutuhkan waktu lebih sedikit untuk membuat prediksi.
Kebanyakan algoritma machine learning adalah eager learner, dan berikut beberapa contohnya:
Lazy learner atau instance-based learner, di sisi lain, tidak langsung membuat model dari data pelatihan—di sinilah letak sifat “lazy”-nya. Mereka hanya mengingat data pelatihan, dan setiap kali perlu membuat prediksi, mereka mencari tetangga terdekat dari seluruh data pelatihan, sehingga proses prediksinya menjadi sangat lambat. Beberapa contohnya adalah:
Namun, beberapa algoritma seperti BallTree dan KDTree dapat digunakan untuk meningkatkan latensi prediksi.
Ada empat kategori utama algoritma Machine Learning: supervised, unsupervised, semi-supervised, dan reinforcement learning.
Meskipun klasifikasi dan regresi sama-sama termasuk dalam pembelajaran terawasi (supervised), keduanya tidak sama.
Jika Anda tertarik mengetahui lebih jauh tentang klasifikasi, kursus Supervised Learning dengan scikit-learn dan Supervised Learning in R dapat membantu. Kursus-kursus ini memberi pemahaman yang lebih baik tentang bagaimana tiap algoritma menangani tugas dan fungsi Python serta R yang diperlukan untuk mengimplementasikannya.
Terkait regresi, Introduction to Regression in R dan Introduction to Regression with statsmodels in Python akan membantu Anda mengeksplorasi berbagai jenis model regresi serta implementasinya di R dan Python.
 Contoh Klasifikasi Machine Learning dalam Kehidupan Nyata
Contoh Klasifikasi Machine Learning dalam Kehidupan Nyata Klasifikasi Machine Learning terawasi memiliki berbagai aplikasi di banyak bidang dalam kehidupan sehari-hari. Berikut beberapa contohnya.
Melatih model machine learning pada data historis pasien dapat membantu tenaga kesehatan menganalisis diagnosis mereka secara akurat:
Pendidikan adalah salah satu bidang yang menangani paling banyak data teks, video, dan audio. Informasi tidak terstruktur ini dapat dianalisis dengan bantuan teknologi Pemrosesan Bahasa Alami untuk melakukan berbagai tugas seperti:
Transportasi merupakan komponen kunci dalam pembangunan ekonomi banyak negara. Karena itu, industri memanfaatkan model machine learning dan deep learning:
Pertanian adalah salah satu pilar paling berharga bagi kelangsungan hidup manusia. Menerapkan keberlanjutan dapat membantu meningkatkan produktivitas petani pada berbagai level tanpa merusak lingkungan:
Ada empat tugas klasifikasi utama dalam Machine Learning: biner, multi-kelas, multi-label, dan klasifikasi tidak seimbang (imbalanced).
Dalam tugas klasifikasi biner, tujuannya adalah mengklasifikasikan data masukan ke dalam dua kategori yang saling eksklusif. Data latih pada situasi ini diberi label dalam format biner: benar dan salah; positif dan negatif; 0 dan 1; spam dan bukan spam, dll., bergantung pada masalah yang dihadapi. Misalnya, kita ingin mendeteksi apakah sebuah gambar adalah truk atau perahu.
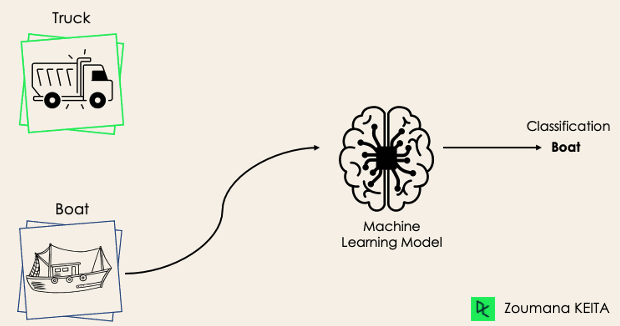
Algoritma Regresi Logistik dan Support Vector Machine dirancang secara native untuk klasifikasi biner. Namun, algoritma lain seperti K-Nearest Neighbors dan Decision Tree juga bisa digunakan untuk klasifikasi biner.
Klasifikasi multi-kelas, sebaliknya, memiliki setidaknya dua label kelas yang saling eksklusif, di mana tujuannya adalah memprediksi kelas mana yang paling sesuai untuk sebuah contoh masukan. Pada kasus berikut, model mengklasifikasikan gambar tersebut dengan benar sebagai pesawat.
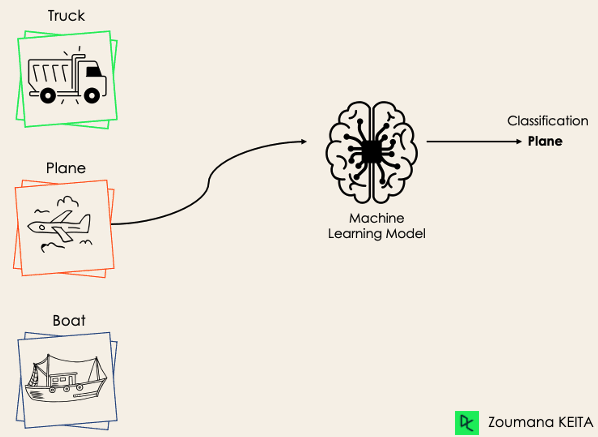
Kebanyakan algoritma klasifikasi biner juga dapat digunakan untuk klasifikasi multi-kelas. Algoritma tersebut termasuk namun tidak terbatas pada:
Tapi tunggu! Bukankah tadi dikatakan SVM dan Regresi Logistik tidak mendukung multi-kelas secara default?
→ Benar. Namun, kita dapat menerapkan pendekatan transformasi biner seperti one-versus-one dan one-versus-all untuk menyesuaikan algoritma klasifikasi biner agar dapat menangani tugas klasifikasi multi-kelas.
One-versus-one: strategi ini melatih sebanyak pasangan label yang ada. Jika kita memiliki 3 kelas, akan ada tiga pasangan label, sehingga tiga classifier, seperti ditunjukkan di bawah.
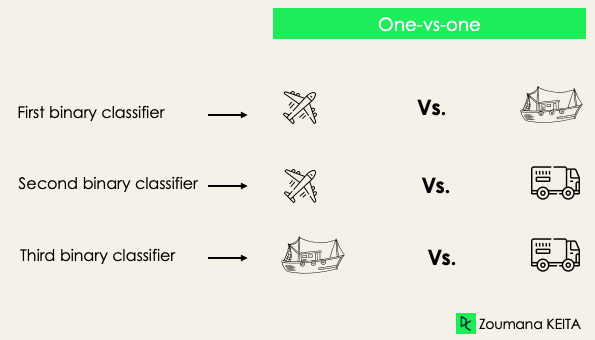
Secara umum, untuk N label, akan ada Nx(N-1)/2 classifier. Setiap classifier dilatih pada satu dataset biner, dan kelas akhir diprediksi melalui suara mayoritas di antara semua classifier. Pendekatan one-vs-one bekerja paling baik untuk SVM dan algoritma berbasis kernel lainnya.
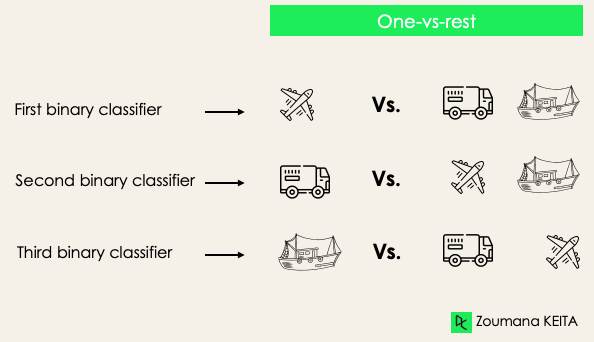
One-versus-rest: pada tahap ini, kita mulai dengan menganggap setiap label sebagai label independen dan menggabungkan sisanya menjadi satu label. Dengan 3 kelas, kita akan memiliki tiga classifier.
Secara umum, untuk N label, kita akan memiliki N classifier biner.
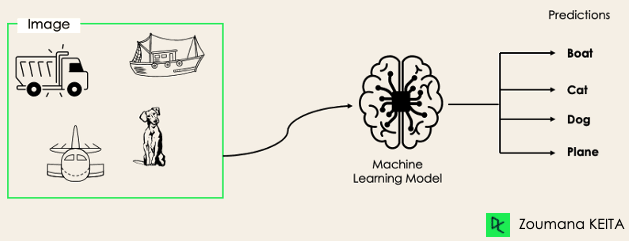
Dalam tugas klasifikasi multi-label, kita mencoba memprediksi 0 atau lebih kelas untuk setiap contoh masukan. Dalam hal ini, tidak ada saling eksklusi karena satu contoh masukan dapat memiliki lebih dari satu label.
Skenario seperti ini dapat dijumpai di berbagai bidang, misalnya penandaan otomatis (auto-tagging) dalam Pemrosesan Bahasa Alami, di mana sebuah teks dapat memuat beberapa topik. Serupa dengan visi komputer, sebuah gambar dapat memuat beberapa objek, seperti ilustrasi berikut: model memprediksi bahwa gambar tersebut berisi: pesawat, perahu, truk, dan anjing.
Tidak memungkinkan menggunakan model klasifikasi multi-kelas atau biner untuk melakukan klasifikasi multi-label. Namun, sebagian besar algoritma yang digunakan untuk tugas klasifikasi standar tersebut memiliki versi khusus untuk klasifikasi multi-label. Di antaranya:
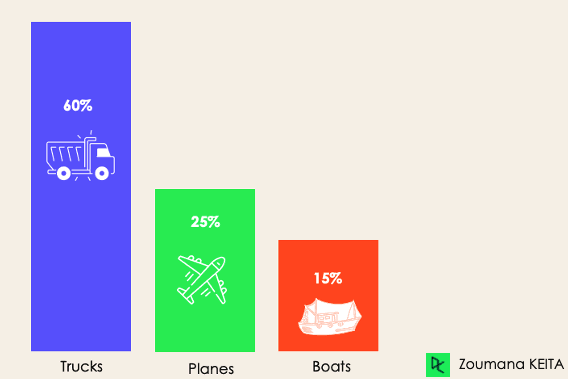
Pada klasifikasi tidak seimbang, jumlah contoh tidak terdistribusi merata pada tiap kelas, artinya kita bisa memiliki lebih banyak contoh di satu kelas dibanding kelas lainnya dalam data pelatihan. Misalkan skenario klasifikasi 3 kelas berikut, di mana data pelatihan berisi: 60% truk, 25% pesawat, dan 15% perahu.
Masalah klasifikasi tidak seimbang dapat terjadi pada skenario berikut:
Menggunakan model prediktif konvensional seperti Decision Tree, Regresi Logistik, dll., bisa kurang efektif saat menangani dataset yang tidak seimbang, karena model mungkin cenderung memprediksi kelas dengan jumlah observasi terbanyak dan menganggap kelas dengan jumlah sedikit sebagai derau.
Jadi, apakah itu berarti masalah seperti ini dibiarkan begitu saja?
Tentu tidak! Kita dapat menggunakan berbagai pendekatan untuk mengatasi ketidakseimbangan dalam dataset. Pendekatan yang paling umum digunakan meliputi teknik sampling atau memanfaatkan algoritma sensitif biaya (cost-sensitive).
Teknik-teknik ini bertujuan menyeimbangkan distribusi asli dengan cara:
Algoritma ini mempertimbangkan biaya salah klasifikasi. Tujuannya adalah meminimalkan total biaya yang dihasilkan model.
Setelah memahami berbagai jenis model klasifikasi, penting untuk memilih metrik evaluasi yang tepat. Pada bagian ini, kita akan membahas metrik yang paling umum digunakan: akurasi, presisi, recall, skor F1, serta area di bawah kurva ROC (Receiver Operating Characteristic) dan AUC (Area Under the Curve).



Sekarang kita memiliki semua alat untuk melanjutkan implementasi beberapa algoritma. Bagian ini akan membahas empat algoritma dan implementasinya pada dataset pinjaman untuk mengilustrasikan beberapa konsep yang telah dibahas sebelumnya, khususnya untuk dataset tidak seimbang menggunakan tugas klasifikasi biner. Untuk kesederhanaan, kita akan fokus pada empat algoritma saja.
Tujuannya bukan mendapatkan model terbaik, melainkan mengilustrasikan cara melatih masing-masing algoritma berikut. Kode sumber tersedia di DataLab, tempat Anda dapat mengeksekusi semuanya dengan sekali klik.
import pandas as pd
loan_data = pd.read_csv("loan_data.csv")
loan_data.head()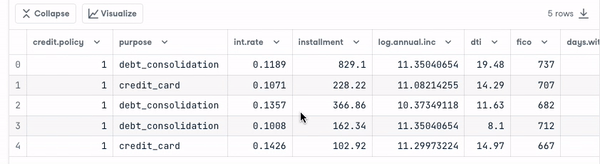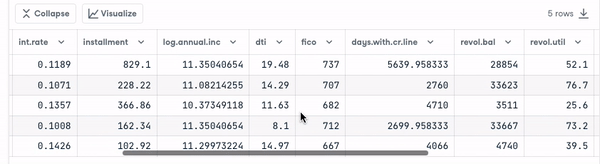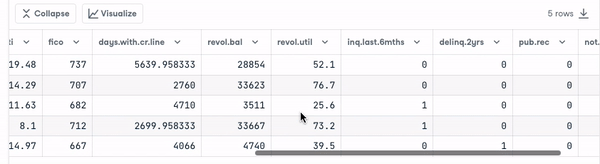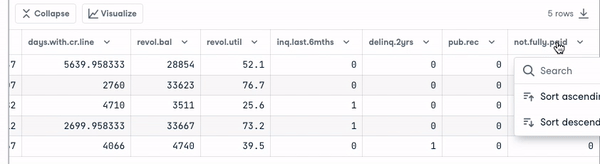
import matplotlib.pyplot as plt
# Helper function for data distribution
# Visualize the proportion of borrowers
def show_loan_distrib(data):
count = ""
if isinstance(data, pd.DataFrame):
count = data["not.fully.paid"].value_counts()
else:
count = data.value_counts()
count.plot(kind = 'pie', explode = [0, 0.1],
figsize = (6, 6), autopct = '%1.1f%%', shadow = True)
plt.ylabel("Loan: Fully Paid Vs. Not Fully Paid")
plt.legend(["Fully Paid", "Not Fully Paid"])
plt.show()
# Visualize the proportion of borrowers
show_loan_distrib(loan_data)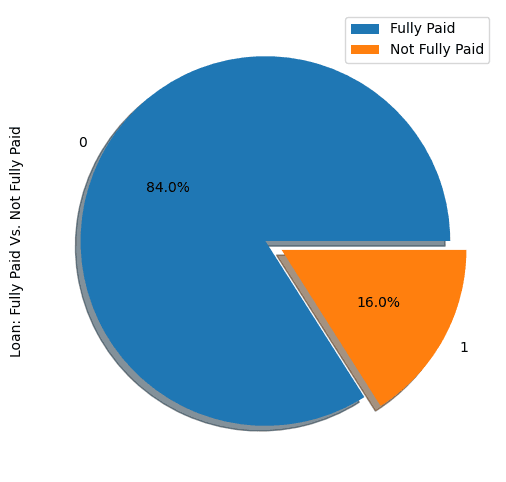
Dari grafik di atas, terlihat bahwa 84% peminjam melunasi pinjamannya, dan hanya 16% yang tidak melunasi, sehingga dataset menjadi sangat tidak seimbang.
Sebelum melangkah lebih jauh, kita perlu memeriksa tipe variabel agar dapat melakukan pengodean pada variabel yang membutuhkannya.
Kita melihat bahwa semua kolom adalah variabel kontinu, kecuali atribut purpose yang perlu dikodekan.

# Check column types
print(loan_data.dtypes)
encoded_loan_data = pd.get_dummies(loan_data, prefix="purpose",
drop_first=True)
print(encoded_loan_data.dtypes)X = encoded_loan_data.drop('not.fully.paid', axis = 1)
y = encoded_loan_data['not.fully.paid']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.30,
stratify = y, random_state=2022)Kita akan mengeksplorasi dua strategi sampling di sini: random undersampling, dan SMOTE oversampling.
Kita akan melakukan undersampling pada kelas mayoritas, yaitu “fully paid” (kelas 0).
X_train_cp = X_train.copy()
X_train_cp['not.fully.paid'] = y_train
y_0 = X_train_cp[X_train_cp['not.fully.paid'] == 0]
y_1 = X_train_cp[X_train_cp['not.fully.paid'] == 1]
y_0_undersample = y_0.sample(y_1.shape[0])
loan_data_undersample = pd.concat([y_0_undersample, y_1], axis = 0)
# Visualize the proportion of borrowers
show_loan_distrib(loan_data_undersample)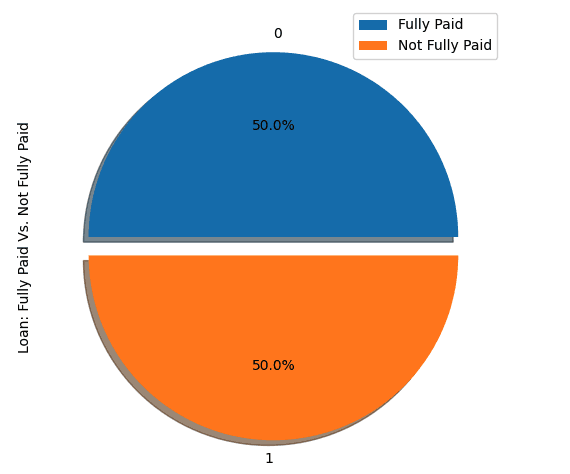
Lakukan oversampling pada kelas minoritas
smote = SMOTE(sampling_strategy='minority')
X_train_SMOTE, y_train_SMOTE = smote.fit_resample(X_train,y_train)
# Visualize the proportion of borrowers
show_loan_distrib(y_train_SMOTE)Setelah menerapkan strategi sampling, kita melihat bahwa dataset terdistribusi sama pada berbagai tipe peminjam.
Bagian ini akan menerapkan dua algoritma klasifikasi pada dataset hasil SMOTE. Pendekatan pelatihan yang sama dapat diterapkan pada data yang di-undersample.
Ini adalah algoritma yang dapat dijelaskan (explainable). Algoritma ini mengklasifikasikan titik data dengan memodelkan probabilitasnya untuk termasuk dalam sebuah kelas menggunakan fungsi sigmoid.
X = loan_data_undersample.drop('not.fully.paid', axis = 1)
y = loan_data_undersample['not.fully.paid']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.15, stratify = y, random_state=2022)
logistic_classifier = LogisticRegression()
logistic_classifier.fit(X_train, y_train)
y_pred = logistic_classifier.predict(X_test)
print(confusion_matrix(y_test,y_pred))
print(classification_report(y_test,y_pred))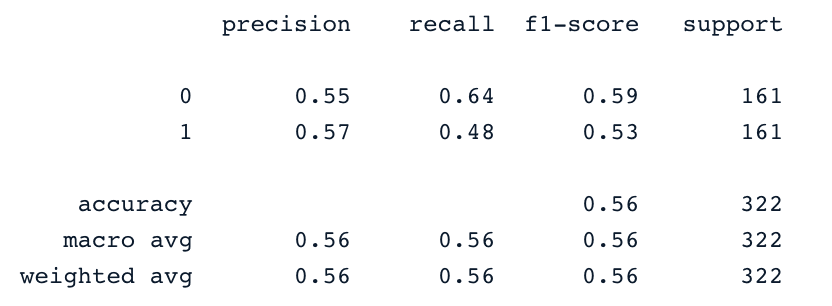
Algoritma ini dapat digunakan untuk klasifikasi maupun regresi. Ia belajar menggambar hyperplane (batas keputusan) menggunakan prinsip pemaksimalan margin. Batas keputusan ini digambar melalui dua support vector terdekat.
SVM menyediakan strategi transformasi bernama kernel trick yang digunakan untuk memproyeksikan data yang tidak dapat dipisahkan secara linear ke ruang dimensi lebih tinggi agar menjadi terpisahkan secara linear.
from sklearn.svm import SVC
svc_classifier = SVC(kernel='linear')
svc_classifier.fit(X_train, y_train)
# Make Prediction & print the result
y_pred = svc_classifier.predict(X_test)
print(classification_report(y_test,y_pred))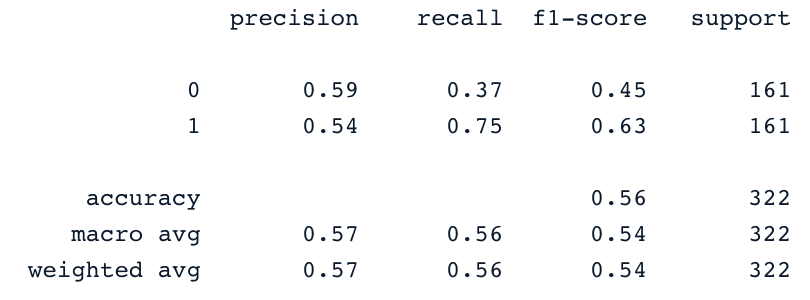
Hasil ini tentu dapat ditingkatkan dengan rekayasa fitur dan fine-tuning lebih lanjut. Namun hasilnya tetap lebih baik dibanding menggunakan data asli yang tidak seimbang.
Algoritma ini merupakan pengembangan dari algoritma yang dikenal luas bernama gradient-boosted trees. Ia merupakan kandidat yang sangat baik tidak hanya untuk mengatasi overfitting tetapi juga dalam hal kecepatan dan performa.
Untuk tidak memperpanjang, Anda dapat merujuk ke Machine Learning with Tree-Based Models in Python dan Machine Learning with Tree-Based Models in R. Dari kursus-kursus ini, Anda akan mempelajari cara menggunakan Python dan R untuk mengimplementasikan model berbasis pohon.
Seiring perkembangan machine learning, muncul algoritma dan teknik klasifikasi baru yang menawarkan peningkatan performa, skalabilitas, dan keterjelasan. Di sini, kita akan mengeksplorasi beberapa kemajuan paling menonjol yang populer sejak 2022, termasuk transformer, metode ensemble mendalam, dan teknik Explainable AI (XAI).
Transformer, yang awalnya dirancang untuk tugas pemrosesan bahasa alami seperti penerjemahan dan pembuatan teks, belakangan diadaptasi untuk berbagai tugas klasifikasi lintas domain. Inovasi kunci transformer adalah mekanisme self-attention, yang memungkinkan model menimbang pentingnya bagian-bagian berbeda dari data masukan secara efektif.
Transformer unggul dalam menangani dataset besar dan kompleks, dan telah banyak diadopsi di industri seperti kesehatan, keuangan, dan e-niaga untuk tugas seperti pengenalan gambar, deteksi penipuan, dan sistem rekomendasi.
Metode ensemble mendalam menggabungkan prediksi dari beberapa model untuk meningkatkan ketangguhan, akurasi, dan estimasi ketidakpastian. Dengan memanfaatkan kekuatan masing-masing model, metode ini sering kali melampaui performa model tunggal, terutama pada tugas klasifikasi yang kompleks.
Seiring model machine learning menjadi semakin kompleks, kebutuhan akan interpretabilitas dan transparansi meningkat. Teknik Explainable AI (XAI) dikembangkan untuk membuat proses pengambilan keputusan model klasifikasi lebih dapat dipahami manusia, yang krusial untuk membangun kepercayaan pada sistem AI, terutama pada domain berisiko tinggi seperti kesehatan dan keuangan.
Teknik XAI ini semakin banyak diintegrasikan ke dalam model klasifikasi tidak hanya untuk meningkatkan transparansi tetapi juga untuk mematuhi persyaratan regulasi, seperti General Data Protection Regulation (GDPR) di Eropa, yang mewajibkan penjelasan atas keputusan otomatis.
Blog konseptual ini membahas aspek utama klasifikasi dalam Machine Learning dan memberikan beberapa contoh bidang penerapannya. Terakhir, dibahas pula implementasi Regresi Logistik dan Support Vector Machine setelah menerapkan strategi undersampling dan SMOTE oversampling untuk menghasilkan dataset seimbang bagi pelatihan model.
Semoga ini membantu Anda memahami topik klasifikasi dalam Machine Learning dengan lebih baik. Anda dapat melanjutkan pembelajaran melalui Machine Learning Scientist with Python track, yang mencakup supervised, unsupervised, dan deep learning. Trek ini juga memberikan pengantar yang baik untuk pemrosesan bahasa alami, pengolahan citra, Spark, dan Keras.
Kursus Machine Learning
Kursus
Kursus
Kursus
blogs
David Woods
13 mnt
blogs
Dario Radečić
15 mnt
blogs
Hugo Bowne-Anderson
13 mnt
blogs
Javier Canales Luna
14 mnt
