Corso
Apprendimento supervisionato in R: Classificazione
4 h
100.7K
La classificazione è un metodo di machine learning supervisionato in cui il modello cerca di prevedere l'etichetta corretta per un determinato dato in input. Nella classificazione, il modello viene addestrato completamente sui dati di training e poi valutato sui dati di test, prima di essere usato per fare previsioni su nuovi dati non visti.
Per esempio, un algoritmo può imparare a prevedere se una certa email è spam o ham (non spam), come illustrato qui sotto.
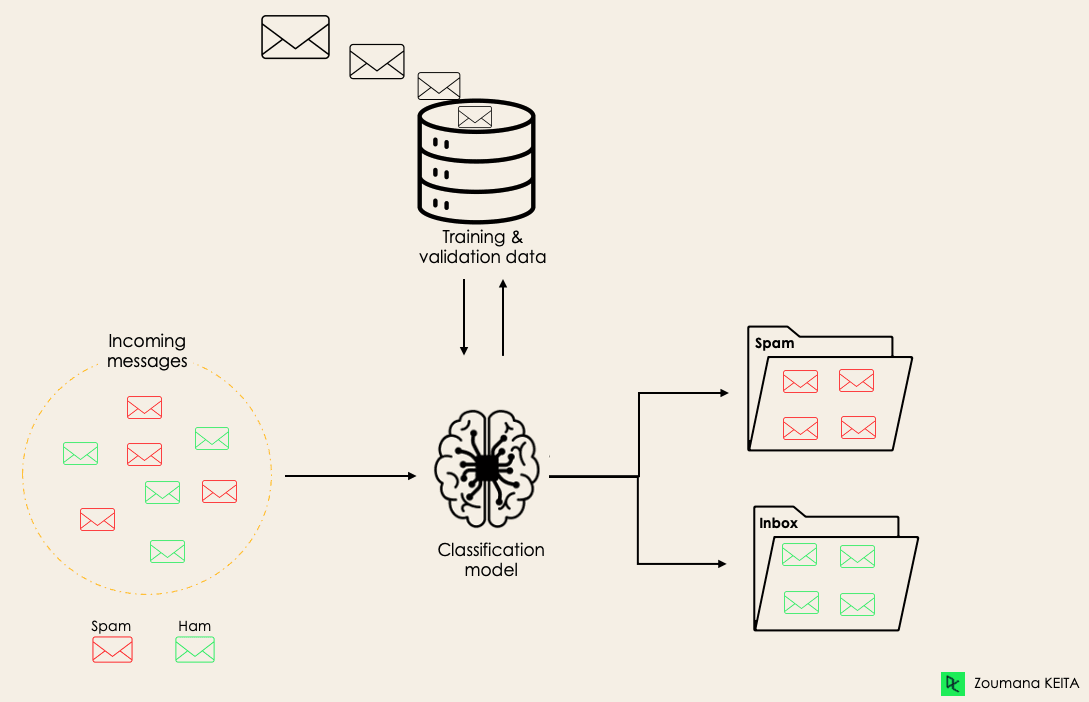 Prima di addentrarci nel concetto di classificazione, capiremo innanzitutto la differenza tra i due tipi di learner nella classificazione: lazy ed eager. Poi chiariremo il fraintendimento tra classificazione e regressione.
Prima di addentrarci nel concetto di classificazione, capiremo innanzitutto la differenza tra i due tipi di learner nella classificazione: lazy ed eager. Poi chiariremo il fraintendimento tra classificazione e regressione.
Esistono due tipi di learner nella classificazione di machine learning: lazy ed eager.
Gli eager learner sono algoritmi di machine learning che prima costruiscono un modello dal dataset di training e solo dopo effettuano previsioni su dataset futuri. Impiegano più tempo durante l'addestramento perché puntano a una migliore generalizzazione imparando i pesi, ma richiedono meno tempo per fare previsioni.
La maggior parte degli algoritmi di machine learning sono eager learner; ecco alcuni esempi:
I lazy learner o instance-based learner, invece, non creano subito un modello a partire dai dati di training, ed è da qui che deriva il termine “lazy”. Si limitano a memorizzare i dati di training e, ogni volta che devono fare una previsione, cercano i vicini più prossimi in tutto il training set, risultando molto lenti in fase di predizione. Alcuni esempi sono:
Tuttavia, alcuni algoritmi, come BallTrees e KDTrees, possono essere usati per migliorare la latenza in predizione.
Ci sono quattro categorie principali di algoritmi di Machine Learning: supervisionato, non supervisionato, semi-supervisionato e apprendimento per rinforzo.
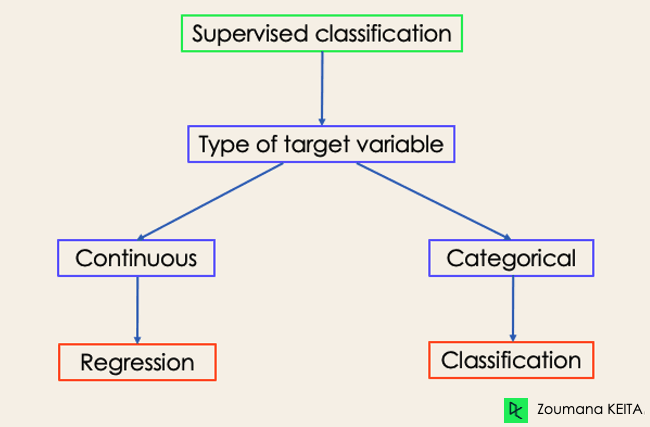
Anche se classificazione e regressione rientrano entrambe nel learning supervisionato, non sono la stessa cosa.
Se vuoi saperne di più sulla classificazione, i corsi su Supervised Learning con scikit-learn e Supervised Learning in R possono esserti utili. Ti aiutano a capire meglio come ciascun algoritmo affronta i compiti e quali funzioni di Python e R servono per implementarli.
Per la regressione, Introduction to Regression in R e Introduction to Regression with statsmodels in Python ti aiuteranno a esplorare diversi tipi di modelli di regressione e la loro implementazione in R e Python.
 Esempi di classificazione nel Machine Learning nella vita reale
Esempi di classificazione nel Machine Learning nella vita reale La classificazione supervisionata nel Machine Learning ha applicazioni diverse in molti ambiti della vita quotidiana. Ecco alcuni esempi.
Addestrare un modello di machine learning su dati storici dei pazienti può aiutare gli specialisti sanitari ad analizzare con precisione le diagnosi:
L'istruzione è uno degli ambiti che trattano più dati testuali, video e audio. Queste informazioni non strutturate possono essere analizzate con l'aiuto delle tecnologie di elaborazione del linguaggio naturale per svolgere diverse attività, come:
I trasporti sono un elemento chiave dello sviluppo economico di molti paesi. Di conseguenza, le industrie usano modelli di machine e deep learning:
L'agricoltura è uno dei pilastri più preziosi per la sopravvivenza umana. Introdurre la sostenibilità può aiutare a migliorare la produttività degli agricoltori a vari livelli senza danneggiare l'ambiente:
Ci sono quattro principali compiti di classificazione nel Machine Learning: binaria, multi-classe, multi-etichetta e classificazione sbilanciata.
In un compito di classificazione binaria, l'obiettivo è classificare i dati in input in due categorie mutuamente esclusive. I dati di training in questo caso sono etichettati in formato binario: vero e falso; positivo e negativo; 0 e 1; spam e non spam, ecc., a seconda del problema affrontato. Per esempio, potremmo voler rilevare se un'immagine è un camion o una barca.
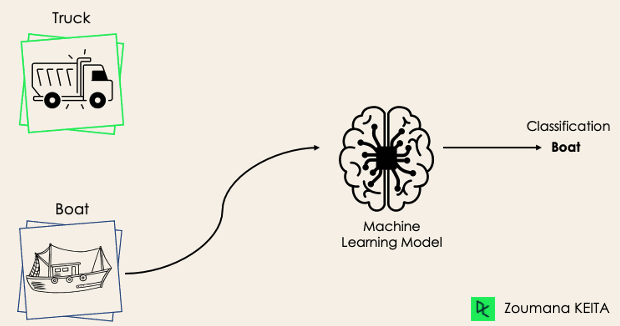
Gli algoritmi di Regressione logistica e Support Vector Machines sono progettati nativamente per la classificazione binaria. Tuttavia, anche altri algoritmi come K-Nearest Neighbors e Decision Trees possono essere usati per la classificazione binaria.
La classificazione multi-classe, invece, prevede almeno due etichette di classe mutuamente esclusive, e l'obiettivo è prevedere a quale classe appartiene un dato esempio in input. Nel caso seguente, il modello ha classificato correttamente l'immagine come un aereo.
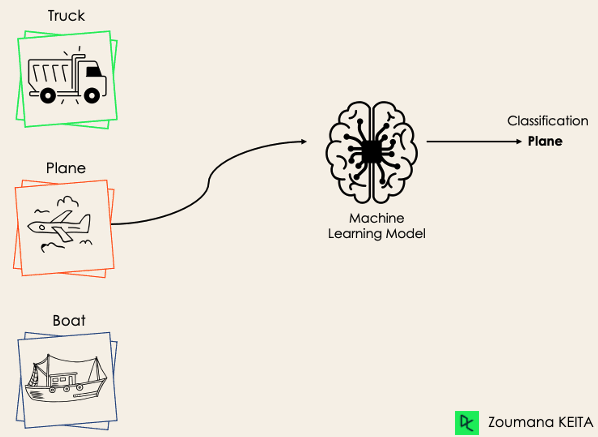
La maggior parte degli algoritmi per la classificazione binaria può essere usata anche per la classificazione multi-classe. Tra questi algoritmi ci sono, ma non solo:
Un attimo! Non hai detto che SVM e Regressione logistica non supportano la multi-classe di default?
→ Esatto. Tuttavia, possiamo applicare approcci di trasformazione binaria come one-versus-one e one-versus-all per adattare gli algoritmi nativi binari ai compiti di classificazione multi-classe.
One-versus-one: questa strategia allena tanti classificatori quante sono le coppie di etichette. Se abbiamo una classificazione a 3 classi, avremo tre coppie di etichette e quindi tre classificatori, come mostrato sotto.
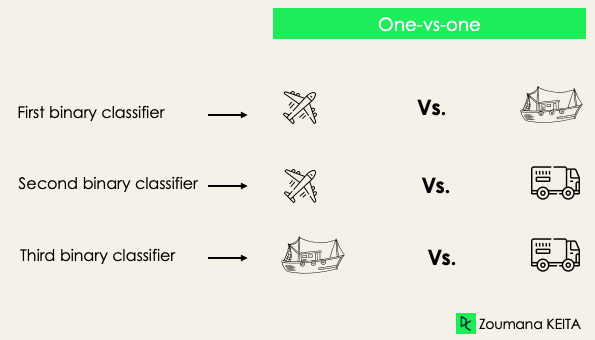
In generale, per N etichette avremo N×(N-1)/2 classificatori. Ogni classificatore è addestrato su un singolo dataset binario e la classe finale è prevista tramite voto di maggioranza tra tutti i classificatori. L'approccio one-vs-one funziona al meglio per SVM e altri algoritmi basati su kernel.
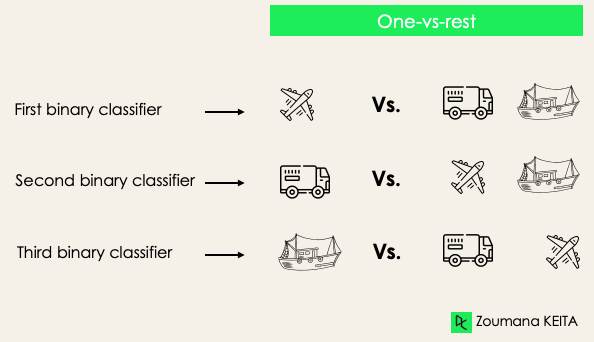
One-versus-rest: qui si inizia considerando ciascuna etichetta come indipendente e si raggruppa il resto come un'unica etichetta. Con 3 classi, avremo tre classificatori.
In generale, per N etichette avremo N classificatori binari.
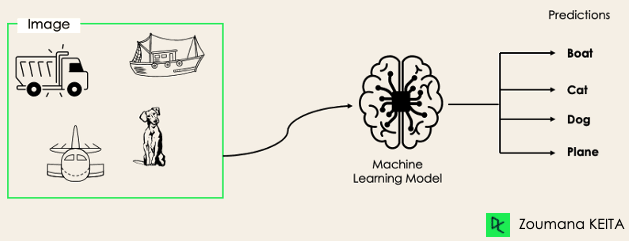
Nei compiti di classificazione multi-etichetta, cerchiamo di prevedere 0 o più classi per ogni esempio in input. In questo caso non c'è esclusione reciproca, perché l'esempio può avere più di un'etichetta.
Uno scenario del genere si osserva in diversi ambiti, come l'auto-tagging nell'elaborazione del linguaggio naturale, dove un testo può contenere più argomenti. Analogamente, in computer vision, un'immagine può contenere più oggetti, come illustrato sotto: il modello ha previsto che l'immagine contiene: un aereo, una barca, un camion e un cane.
Non è possibile usare modelli di classificazione binaria o multi-classe per eseguire la classificazione multi-etichetta. Tuttavia, la maggior parte degli algoritmi usati per quei compiti standard ha versioni specializzate per la multi-etichetta. Possiamo citare:
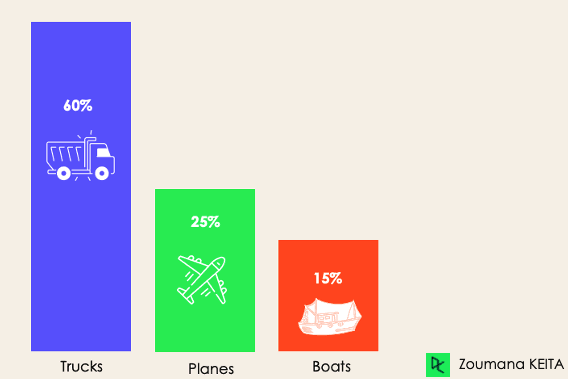
Nella classificazione sbilanciata, il numero di esempi è distribuito in modo disomogeneo tra le classi: possiamo quindi avere molte più osservazioni di una classe rispetto alle altre nei dati di training. Consideriamo il seguente scenario a 3 classi in cui il training set contiene: 60% camion, 25% aerei e 15% barche.
Il problema della classificazione sbilanciata può verificarsi nei seguenti scenari:
Usare modelli predittivi convenzionali come Decision Trees, Regressione logistica, ecc. può non essere efficace con un dataset sbilanciato, perché potrebbero essere portati a prevedere la classe con il maggior numero di osservazioni, considerando quelle meno numerose come rumore.
Quindi, significa che questi problemi restano irrisolti?
Certo che no! Possiamo usare diverse strategie per affrontare lo sbilanciamento in un dataset. Gli approcci più comuni includono tecniche di campionamento o l'uso di algoritmi sensibili al costo.
Queste tecniche mirano a bilanciare la distribuzione dell'originale tramite:
Questi algoritmi tengono conto del costo della misclassificazione. Puntano a minimizzare il costo totale generato dai modelli.
Ora che abbiamo un'idea dei diversi tipi di modelli di classificazione, è fondamentale scegliere le metriche di valutazione giuste. In questa sezione tratteremo le metriche più comuni: accuracy, precision, recall, F1 score e area sotto la curva ROC (Receiver Operating Characteristic) e AUC (Area Under the Curve).



Ora abbiamo tutti gli strumenti per procedere con l'implementazione di alcuni algoritmi. Questa sezione tratterà quattro algoritmi e la loro implementazione sul loans dataset per illustrare alcuni dei concetti visti prima, in particolare per i dataset sbilanciati usando un compito di classificazione binaria. Per semplicità, ci concentreremo su soli quattro algoritmi.
L'obiettivo non è ottenere il miglior modello possibile, ma illustrare come addestrare ciascuno dei seguenti algoritmi. Il codice sorgente è disponibile su DataLab, dove puoi eseguire tutto con un clic.
import pandas as pd
loan_data = pd.read_csv("loan_data.csv")
loan_data.head()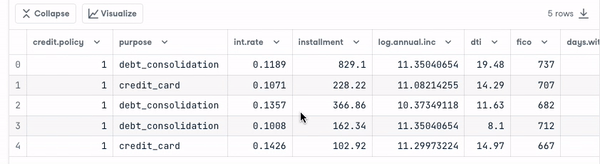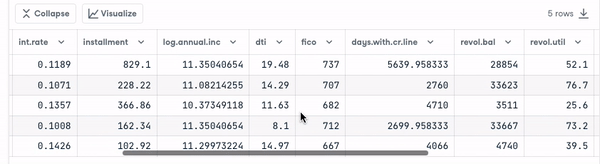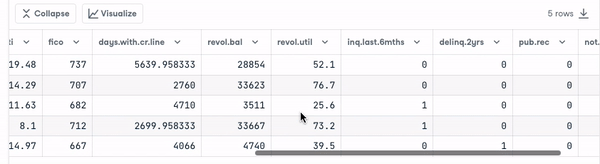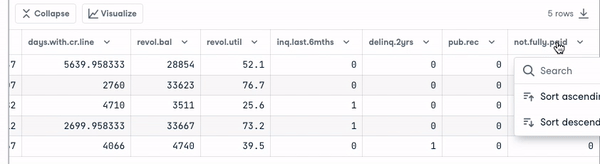
import matplotlib.pyplot as plt
# Helper function for data distribution
# Visualize the proportion of borrowers
def show_loan_distrib(data):
count = ""
if isinstance(data, pd.DataFrame):
count = data["not.fully.paid"].value_counts()
else:
count = data.value_counts()
count.plot(kind = 'pie', explode = [0, 0.1],
figsize = (6, 6), autopct = '%1.1f%%', shadow = True)
plt.ylabel("Loan: Fully Paid Vs. Not Fully Paid")
plt.legend(["Fully Paid", "Not Fully Paid"])
plt.show()
# Visualize the proportion of borrowers
show_loan_distrib(loan_data)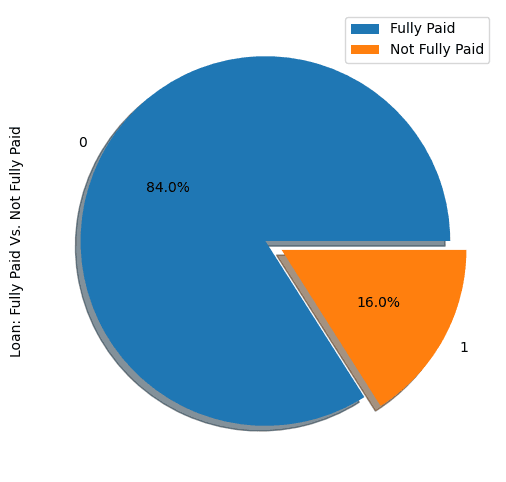
Dal grafico sopra, notiamo che l'84% dei mutuatari ha rimborsato il prestito e solo il 16% non lo ha fatto, il che rende il dataset molto sbilanciato.
Prima di procedere, dobbiamo controllare il tipo delle variabili in modo da codificare quelle che lo richiedono.
Notiamo che tutte le colonne sono variabili continue, tranne l'attributo purpose, che va codificato.

# Check column types
print(loan_data.dtypes)
encoded_loan_data = pd.get_dummies(loan_data, prefix="purpose",
drop_first=True)
print(encoded_loan_data.dtypes)X = encoded_loan_data.drop('not.fully.paid', axis = 1)
y = encoded_loan_data['not.fully.paid']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.30,
stratify = y, random_state=2022)Esploreremo due strategie di campionamento: undersampling casuale e SMOTE oversampling.
Eseguiremo l'undersampling della classe maggioritaria, che corrisponde a “fully paid” (classe 0).
X_train_cp = X_train.copy()
X_train_cp['not.fully.paid'] = y_train
y_0 = X_train_cp[X_train_cp['not.fully.paid'] == 0]
y_1 = X_train_cp[X_train_cp['not.fully.paid'] == 1]
y_0_undersample = y_0.sample(y_1.shape[0])
loan_data_undersample = pd.concat([y_0_undersample, y_1], axis = 0)
# Visualize the proportion of borrowers
show_loan_distrib(loan_data_undersample)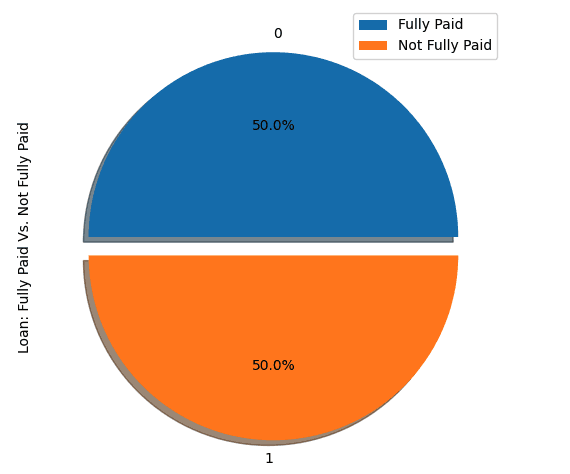
Esegui l'oversampling sulla classe minoritaria
smote = SMOTE(sampling_strategy='minority')
X_train_SMOTE, y_train_SMOTE = smote.fit_resample(X_train,y_train)
# Visualize the proportion of borrowers
show_loan_distrib(y_train_SMOTE)Dopo aver applicato le strategie di campionamento, osserviamo che il dataset è distribuito equamente tra i diversi tipi di mutuatari.
In questa sezione applicheremo due algoritmi di classificazione al dataset campionato con SMOTE. Lo stesso approccio di training può essere applicato anche ai dati sottocampionati.
È un algoritmo interpretabile. Classifica un punto dati modellando la probabilità che appartenga a una data classe usando la funzione sigmoide.
X = loan_data_undersample.drop('not.fully.paid', axis = 1)
y = loan_data_undersample['not.fully.paid']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.15, stratify = y, random_state=2022)
logistic_classifier = LogisticRegression()
logistic_classifier.fit(X_train, y_train)
y_pred = logistic_classifier.predict(X_test)
print(confusion_matrix(y_test,y_pred))
print(classification_report(y_test,y_pred))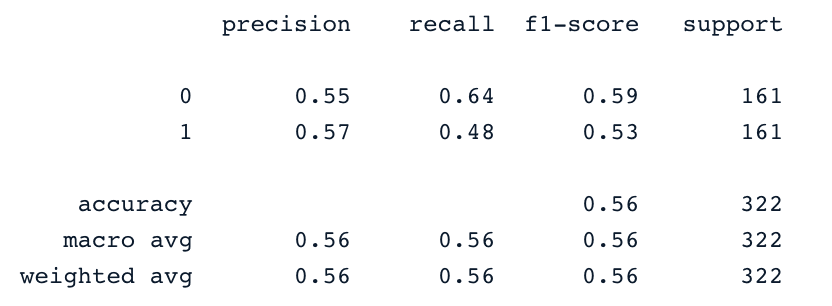
Questo algoritmo può essere usato sia per classificazione sia per regressione. Impara a tracciare l'iperpiano (frontiera di decisione) usando il principio di massimizzazione del margine. Questa frontiera è tracciata attraverso i due support vector più vicini.
Le SVM forniscono una strategia di trasformazione chiamata kernel trick, usata per proiettare dati non linearmente separabili in uno spazio a dimensione maggiore per renderli linearmente separabili.
from sklearn.svm import SVC
svc_classifier = SVC(kernel='linear')
svc_classifier.fit(X_train, y_train)
# Make Prediction & print the result
y_pred = svc_classifier.predict(X_test)
print(classification_report(y_test,y_pred))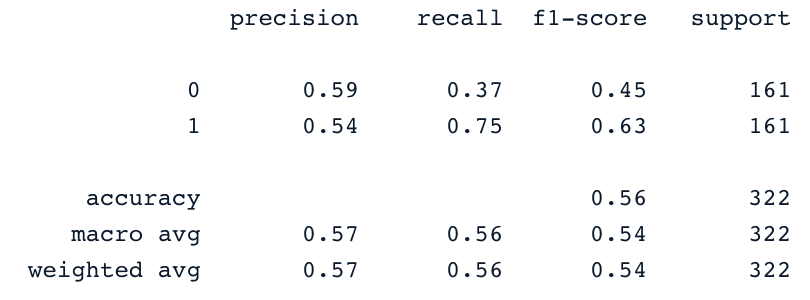
Questi risultati possono ovviamente essere migliorati con più feature engineering e fine-tuning. Ma sono migliori rispetto all'uso dei dati originali sbilanciati.
Questo algoritmo è un'estensione di un noto algoritmo chiamato gradient-boosted trees. È un'ottima scelta non solo per contrastare l'overfitting, ma anche per velocità e prestazioni.
Per non dilungarci, puoi fare riferimento a Machine Learning with Tree-Based Models in Python e Machine Learning with Tree-Based Models in R. Da questi corsi imparerai a usare sia Python sia R per implementare modelli basati su alberi.
Con l'evoluzione continua del machine learning, sono emersi nuovi algoritmi e tecniche di classificazione che offrono migliori prestazioni, scalabilità e interpretabilità. Qui esploreremo alcuni degli avanzamenti più rilevanti che hanno guadagnato popolarità dal 2022, inclusi i transformer, i metodi di deep ensemble e le tecniche di Explainable AI (XAI).
I Transformer, originariamente progettati per compiti di elaborazione del linguaggio naturale come traduzione e generazione di testo, sono stati recentemente adattati a vari compiti di classificazione in diversi domini. L'innovazione chiave dei transformer è l'uso dei meccanismi di self-attention, che permettono ai modelli di pesare in modo efficace l'importanza delle diverse parti dei dati in input.
I transformer eccellono nella gestione di dataset grandi e complessi e sono stati ampiamente adottati in settori come sanità, finanza ed e-commerce per compiti come il riconoscimento di immagini, il rilevamento di frodi e i sistemi di raccomandazione.
I metodi di deep ensemble combinano le previsioni di più modelli per migliorare robustezza, accuratezza e stima dell'incertezza. Sfruttando i punti di forza di modelli diversi, spesso superano le prestazioni dei singoli modelli, soprattutto in compiti di classificazione complessi.
Con l'aumentare della complessità dei modelli di machine learning, cresce l'esigenza di interpretabilità e trasparenza. Le tecniche di Explainable AI (XAI) sono state sviluppate per rendere più comprensibile agli esseri umani il processo decisionale dei modelli di classificazione, aspetto cruciale per ottenere fiducia nei sistemi di IA, specialmente in settori critici come sanità e finanza.
Queste tecniche XAI vengono integrate sempre più spesso nei modelli di classificazione non solo per migliorare la trasparenza, ma anche per rispettare requisiti normativi come il GDPR in Europa, che impone spiegazioni per le decisioni automatizzate.
Questo blog concettuale ha trattato gli aspetti principali della classificazione nel Machine Learning e ti ha fornito alcuni esempi dei diversi domini in cui viene applicata. Infine, ha mostrato l'implementazione di Regressione logistica e Support Vector Machine dopo aver eseguito strategie di undersampling e SMOTE oversampling per generare un dataset bilanciato per l'addestramento dei modelli.
Speriamo ti abbia aiutato a comprendere meglio il tema della classificazione nel Machine Learning. Puoi proseguire l'apprendimento seguendo il percorso Machine Learning Scientist with Python, che copre supervisionato, non supervisionato e deep learning. Offre anche una buona introduzione a elaborazione del linguaggio naturale, elaborazione di immagini, Spark e Keras.
Corsi di Machine Learning
Corso
Corso
Corso
blog
Abid Ali Awan
10 min
blog
Tim Lu
12 min
blog
Abid Ali Awan
15 min

