Cursus
Supervised Learning in R: Classificatie
4 Hr
100.7K
Classificatie is een supervised machine learning-methode waarbij het model probeert het juiste label van een gegeven input te voorspellen. Bij classificatie wordt het model volledig getraind met trainingsdata en vervolgens geëvalueerd op testdata, voordat het wordt gebruikt om voorspellingen te doen op nieuwe, ongeziene data.
Zo kan een algoritme bijvoorbeeld leren voorspellen of een e-mail spam is of ham (geen spam), zoals hieronder geïllustreerd.
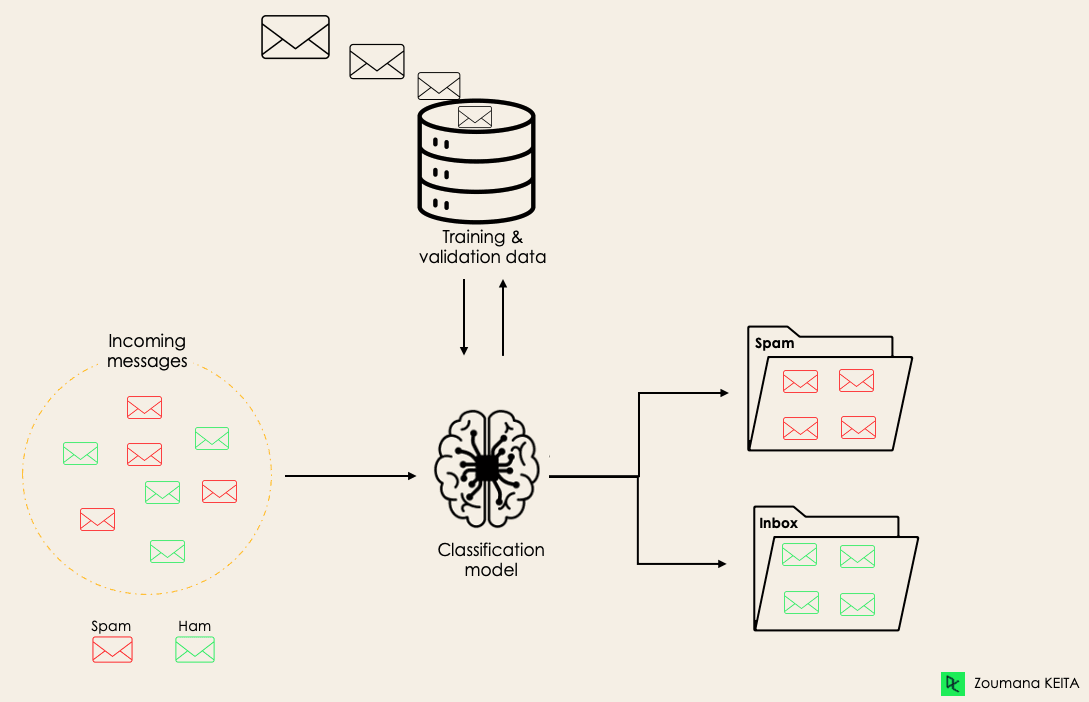 Voordat we in het classificatieconcept duiken, bekijken we eerst het verschil tussen de twee typen learners in classificatie: lazy en eager learners. Daarna verduidelijken we het misverstand tussen classificatie en regressie.
Voordat we in het classificatieconcept duiken, bekijken we eerst het verschil tussen de twee typen learners in classificatie: lazy en eager learners. Daarna verduidelijken we het misverstand tussen classificatie en regressie.
Er zijn twee typen learners bij machine learning-classificatie: lazy en eager learners.
Eager learners zijn machine learning-algoritmen die eerst een model opbouwen op basis van de trainingsdataset voordat ze voorspellingen doen op toekomstige datasets. Ze besteden meer tijd aan het trainingsproces omdat ze tijdens het leren van de gewichten streven naar een betere generalisatie, maar hebben minder tijd nodig om voorspellingen te doen.
De meeste machine learning-algoritmen zijn eager learners. Enkele voorbeelden:
Lazy learners of instance-based learners daarentegen creëren niet direct een model uit de trainingsdata—vandaar het “luie” aspect. Ze onthouden de trainingsdata, en telkens wanneer er een voorspelling nodig is, zoeken ze naar de dichtstbijzijnde buur in de complete trainingsset, wat ze tijdens voorspellen erg traag maakt. Voorbeelden hiervan zijn:
Sommige algoritmen, zoals BallTrees en KDTrees, kunnen echter worden gebruikt om de voorspellatentie te verbeteren.
Er zijn vier hoofdcategorieën machine learning-algoritmen: supervised, unsupervised, semi-supervised en reinforcement learning.
Hoewel classificatie en regressie beide onder supervised learning vallen, zijn ze niet hetzelfde.
Als je meer wilt weten over classificatie, zijn de cursussen Supervised Learning met scikit-learn en Supervised Learning in R wellicht nuttig. Ze geven je een beter begrip van hoe elk algoritme taken benadert en welke Python- en R-functies je nodig hebt om ze te implementeren.
Voor regressie bieden Introduction to Regression in R en Introduction to Regression with statsmodels in Python een verkenning van verschillende regressiemodellen en hun implementatie in R en Python.
 Voorbeelden van machine learning-classificatie in het echte leven
Voorbeelden van machine learning-classificatie in het echte leven Supervised machine learning-classificatie kent verschillende toepassingen in tal van domeinen uit ons dagelijks leven. Enkele voorbeelden:
Het trainen van een machine learning-model op historische patiëntgegevens kan zorgprofessionals helpen hun diagnoses nauwkeuriger te analyseren:
Onderwijs is een domein met veel tekst-, video- en audiodata. Deze ongestructureerde informatie kan met Natural Language-technologieën worden geanalyseerd voor taken zoals:
Vervoer is een sleutelcomponent in de economische ontwikkeling van veel landen. Daarom gebruiken bedrijven machine- en deep learning-modellen:
Landbouw is een van de waardevolste pijlers van menselijk voortbestaan. Duurzaamheid invoeren kan de productiviteit van boeren op verschillende niveaus verbeteren zonder het milieu te schaden:
Er zijn vier hoofdtypen classificatietaken in machine learning: binaire, multi-class, multi-label en onevenwichtige classificaties.
Bij een binaire classificatietaak is het doel om inputdata in twee elkaar uitsluitende categorieën in te delen. De trainingsdata zijn in zo’n geval binair gelabeld: waar en onwaar; positief en negatief; 0 en 1; spam en niet-spam, enz., afhankelijk van het probleem. Zo willen we bijvoorbeeld detecteren of een bepaalde afbeelding een vrachtwagen of een boot is.
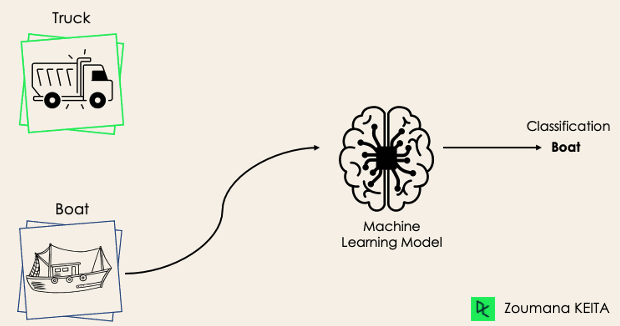
Algoritmen als logistische regressie en Support Vector Machines zijn van nature ontworpen voor binaire classificaties. Andere algoritmen, zoals K-Nearest Neighbors en beslisbomen, kunnen echter ook worden gebruikt voor binaire classificatie.
Bij multi-class classificatie zijn er daarentegen minstens twee elkaar uitsluitende klasselabels, en is het doel te voorspellen tot welke klasse een inputvoorbeeld behoort. In het volgende geval classificeerde het model de afbeelding correct als een vliegtuig.
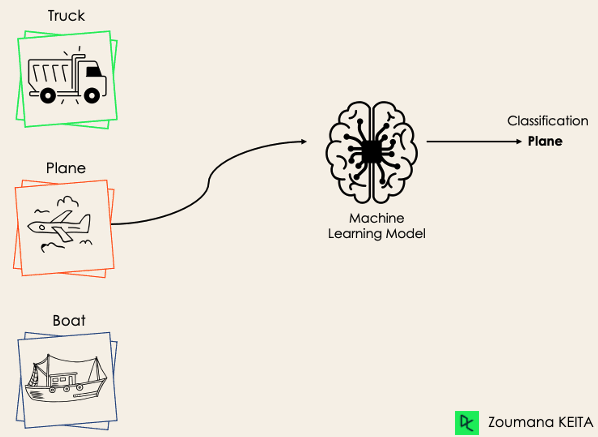
De meeste binaire classificatie-algoritmen kunnen ook worden gebruikt voor multi-class classificatie. Deze algoritmen omvatten onder meer:
Maar wacht! Zei je niet dat SVM en logistische regressie standaard geen multi-class classificatie ondersteunen?
→ Klopt. Maar we kunnen binaire transformatiestrategieën toepassen, zoals one-versus-one en one-versus-all, om native binaire classificatie-algoritmen aan te passen voor multi-class classificatietaken.
One-versus-one: deze strategie traint evenveel classifiers als er labelparen zijn. Bij een 3-klasseclassificatie hebben we drie labelparen en dus drie classifiers, zoals hieronder te zien is.
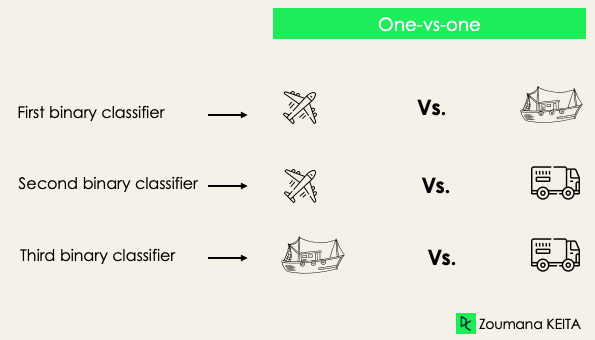
In het algemeen hebben we voor N labels Nx(N-1)/2 classifiers. Elke classifier wordt getraind op een enkel binair datasetje en de uiteindelijke klasse wordt voorspeld via een meerderheidsstemming tussen alle classifiers. De one-vs-one-benadering werkt het beste voor SVM en andere kernel-gebaseerde algoritmen.
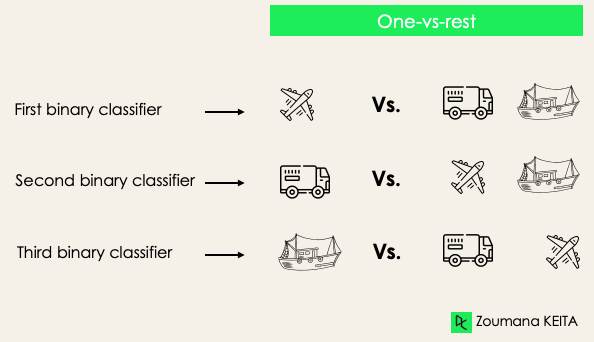
One-versus-rest: hierbij beschouwen we elk label als een onafhankelijk label en voegen we de rest samen als één label. Bij 3 klassen krijgen we drie classifiers.
In het algemeen hebben we voor N labels N binaire classifiers.
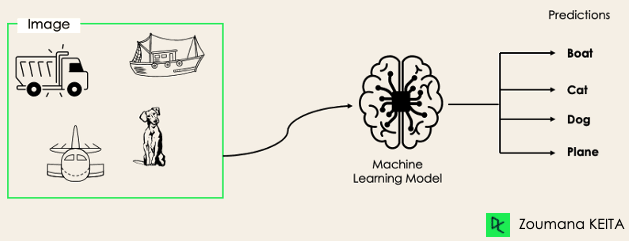
Bij multi-label classificatietaken proberen we 0 of meer klassen te voorspellen voor elk inputvoorbeeld. Er is in dit geval geen wederzijdse uitsluiting, omdat het inputvoorbeeld meer dan één label kan hebben.
Zo’n scenario komt voor in verschillende domeinen, zoals autotagging in Natural Language Processing, waarbij een tekst meerdere onderwerpen kan bevatten. Vergelijkbaar in computervisie: een afbeelding kan meerdere objecten bevatten, zoals hieronder geïllustreerd: het model voorspelde dat de afbeelding bevat: een vliegtuig, een boot, een vrachtwagen en een hond.
Het is niet mogelijk om multi-class of binaire classificatiemodellen te gebruiken voor multi-label classificatie. De meeste algoritmen voor die standaard classificatietaken hebben echter gespecialiseerde varianten voor multi-label classificatie. Denk aan:
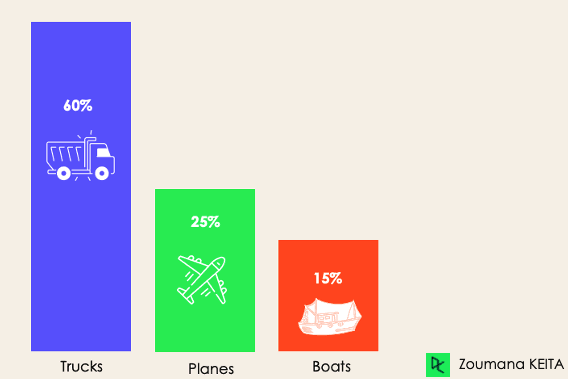
Bij onevenwichtige classificatie is het aantal voorbeelden ongelijk verdeeld over de klassen: er kunnen in de trainingsdata meer voorbeelden van de ene klasse zijn dan van de andere. Neem het volgende 3-klasse scenario, waarin de trainingsdata bevatten: 60% vrachtwagens, 25% vliegtuigen en 15% boten.
Het probleem van onevenwichtige classificatie kan zich voordoen in de volgende scenario’s:
Het gebruik van conventionele voorspellende modellen zoals beslisbomen, logistische regressie, enz. is bij onevenwichtige datasets mogelijk niet effectief, omdat ze geneigd kunnen zijn te sturen op de klasse met de meeste observaties en de klasse met minder observaties als ruis te beschouwen.
Betekent dit dan dat zulke problemen onopgelost blijven?
Natuurlijk niet! We kunnen meerdere benaderingen gebruiken om het onevenwichtsprobleem in een dataset aan te pakken. De meest gebruikte benaderingen zijn samplingtechnieken of het benutten van kosten-sensitieve algoritmen.
Deze technieken zijn erop gericht de verdeling van de oorspronkelijke data in balans te brengen door:
Deze algoritmen houden rekening met de kosten van misclassificatie. Ze streven ernaar de totale kosten die de modellen genereren te minimaliseren.
Nu we een beeld hebben van de verschillende typen classificatiemodellen, is het cruciaal de juiste evaluatiemeetwaarden te kiezen. In deze sectie behandelen we de meest gebruikte metrics: accuracy, precision, recall, F1-score en area under the ROC (Receiver Operating Characteristic)-curve en AUC (Area Under the Curve).



We hebben nu alle tools in handen om over te gaan tot de implementatie van enkele algoritmen. In deze sectie behandelen we vier algoritmen en hun implementatie op de loans-dataset om een aantal eerder besproken concepten te illustreren, met name voor onevenwichtige datasets met een binaire classificatietaak. Voor de eenvoud richten we ons op slechts vier algoritmen.
Het doel is niet om het best mogelijke model te krijgen, maar om te laten zien hoe je elk van de volgende algoritmen traint. De broncode is beschikbaar in DataLab, waar je alles met één klik kunt uitvoeren.
import pandas as pd
loan_data = pd.read_csv("loan_data.csv")
loan_data.head()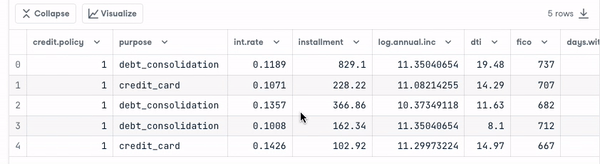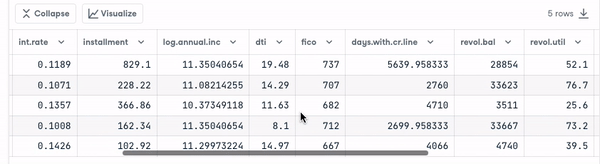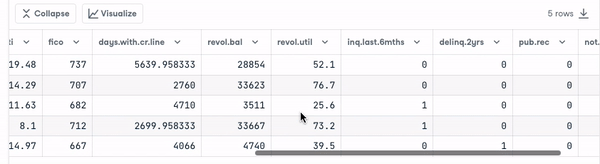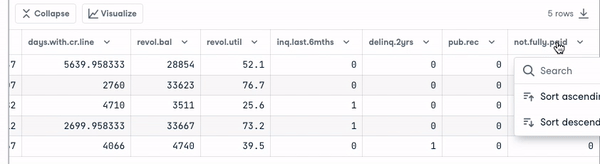
import matplotlib.pyplot as plt
# Helper function for data distribution
# Visualize the proportion of borrowers
def show_loan_distrib(data):
count = ""
if isinstance(data, pd.DataFrame):
count = data["not.fully.paid"].value_counts()
else:
count = data.value_counts()
count.plot(kind = 'pie', explode = [0, 0.1],
figsize = (6, 6), autopct = '%1.1f%%', shadow = True)
plt.ylabel("Loan: Fully Paid Vs. Not Fully Paid")
plt.legend(["Fully Paid", "Not Fully Paid"])
plt.show()
# Visualize the proportion of borrowers
show_loan_distrib(loan_data)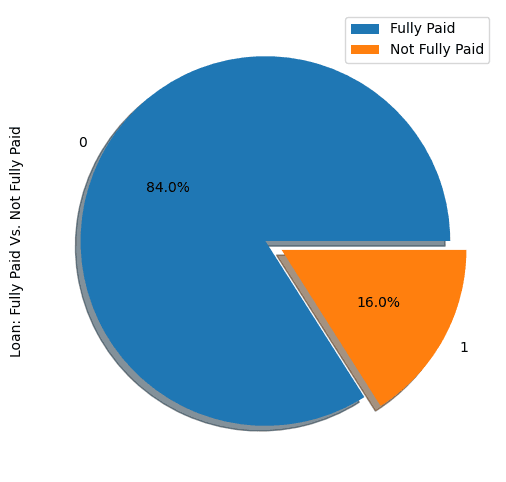
Uit de bovenstaande grafiek blijkt dat 84% van de leners hun lening terugbetaalde en slechts 16% niet, wat de dataset sterk onevenwichtig maakt.
Voordat we verder gaan, moeten we de typen variabelen controleren zodat we kunnen encoden wat nodig is.
We zien dat alle kolommen continue variabelen zijn, behalve het attribuut purpose, dat moet worden geëncodeerd.

# Check column types
print(loan_data.dtypes)
encoded_loan_data = pd.get_dummies(loan_data, prefix="purpose",
drop_first=True)
print(encoded_loan_data.dtypes)X = encoded_loan_data.drop('not.fully.paid', axis = 1)
y = encoded_loan_data['not.fully.paid']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.30,
stratify = y, random_state=2022)We verkennen hier twee samplingstrategieën: willekeurig undersamplen en SMOTE-oversamplen.
We gaan de meerderheidsklasse undersamplen, wat overeenkomt met “volledig afgelost” (klasse 0).
X_train_cp = X_train.copy()
X_train_cp['not.fully.paid'] = y_train
y_0 = X_train_cp[X_train_cp['not.fully.paid'] == 0]
y_1 = X_train_cp[X_train_cp['not.fully.paid'] == 1]
y_0_undersample = y_0.sample(y_1.shape[0])
loan_data_undersample = pd.concat([y_0_undersample, y_1], axis = 0)
# Visualize the proportion of borrowers
show_loan_distrib(loan_data_undersample)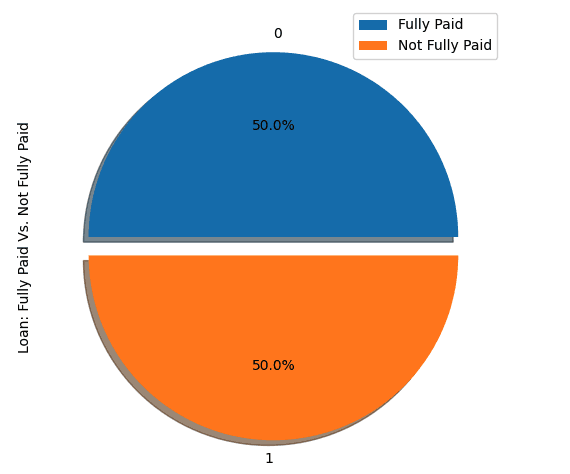
Voer oversampling uit op de minderheidsklasse
smote = SMOTE(sampling_strategy='minority')
X_train_SMOTE, y_train_SMOTE = smote.fit_resample(X_train,y_train)
# Visualize the proportion of borrowers
show_loan_distrib(y_train_SMOTE)Na toepassing van de samplingstrategieën zien we dat de dataset gelijkmatig verdeeld is over de verschillende typen leners.
In deze sectie passen we twee classificatie-algoritmen toe op de SMOTE-gesamplede dataset. Dezelfde trainingsaanpak kan ook op undersamplede data worden toegepast.
Dit is een uitlegbaar algoritme. Het classificeert een datapunt door de kans te modelleren dat het tot een bepaalde klasse behoort, met behulp van de sigmoidfunctie.
X = loan_data_undersample.drop('not.fully.paid', axis = 1)
y = loan_data_undersample['not.fully.paid']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.15, stratify = y, random_state=2022)
logistic_classifier = LogisticRegression()
logistic_classifier.fit(X_train, y_train)
y_pred = logistic_classifier.predict(X_test)
print(confusion_matrix(y_test,y_pred))
print(classification_report(y_test,y_pred))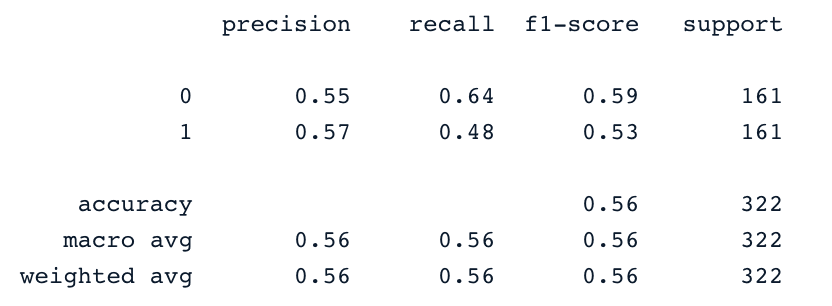
Dit algoritme kan worden gebruikt voor zowel classificatie als regressie. Het leert het hypervlak (de beslisgrens) te tekenen door het principe van margeminimalisatie—of eigenlijk marge-maximalisatie—te gebruiken. Deze beslisgrens wordt bepaald door de twee dichtstbijzijnde support vectors.
SVM biedt een transformatiestrategie, de zogeheten kernel tricks, om niet-lineair scheidbare data te projecteren naar een hoger-dimensionale ruimte zodat ze lineair scheidbaar worden.
from sklearn.svm import SVC
svc_classifier = SVC(kernel='linear')
svc_classifier.fit(X_train, y_train)
# Make Prediction & print the result
y_pred = svc_classifier.predict(X_test)
print(classification_report(y_test,y_pred))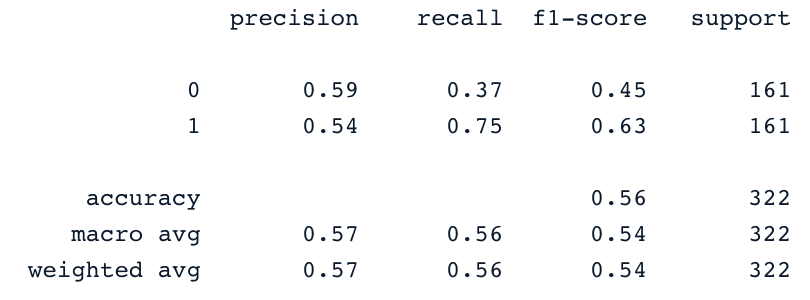
Deze resultaten kunnen natuurlijk worden verbeterd met meer feature engineering en fine-tuning. Maar ze zijn al beter dan het gebruik van de oorspronkelijke onevenwichtige data.
Dit algoritme is een uitbreiding op een bekend algoritme: gradient-boosted trees. Het is niet alleen een sterke kandidaat tegen overfitting, maar blinkt ook uit in snelheid en prestaties.
Om het kort te houden kun je terecht bij Machine Learning with Tree-Based Models in Python en Machine Learning with Tree-Based Models in R. In deze cursussen leer je hoe je zowel in Python als R boomgebaseerde modellen implementeert.
Nu machine learning blijft evolueren, zijn nieuwe classificatie-algoritmen en -technieken ontstaan die betere prestaties, schaalbaarheid en uitlegbaarheid bieden. We verkennen hier enkele opvallende ontwikkelingen die sinds 2022 aan populariteit hebben gewonnen, waaronder transformers, deep ensemble-methoden en Explainable AI (XAI)-technieken.
Transformers, oorspronkelijk ontworpen voor NLP-taken zoals vertalen en tekstgeneratie, zijn recentelijk aangepast voor uiteenlopende classificatietaken in verschillende domeinen. De kerninnovatie van transformers is het gebruik van self-attention-mechanismen, waarmee modellen effectief het belang van verschillende delen van de input kunnen wegen.
Transformers blinken uit in het verwerken van grote, complexe datasets en zijn breed omarmd in sectoren als gezondheidszorg, financiën en e-commerce voor taken als beeldherkenning, fraudedetectie en aanbevelingssystemen.
Deep ensemble-methoden combineren de voorspellingen van meerdere modellen om de robuustheid, nauwkeurigheid en onzekerheidsinschatting te verbeteren. Door de sterke punten van verschillende modellen te benutten, presteren deze methoden vaak beter dan individuele modellen, vooral bij complexe classificatietaken.
Nu machine learning-modellen complexer worden, groeit de behoefte aan uitlegbaarheid en transparantie. Explainable AI (XAI)-technieken zijn ontwikkeld om het besluitvormingsproces van classificatiemodellen begrijpelijker te maken voor mensen—cruciaal om vertrouwen te wekken in AI-systemen, vooral in risicovolle domeinen zoals gezondheidszorg en financiën.
Deze XAI-technieken worden steeds vaker geïntegreerd in classificatiemodellen om niet alleen de transparantie te verbeteren, maar ook te voldoen aan regelgeving, zoals de Algemene Verordening Gegevensbescherming (AVG) in Europa, die uitleg bij geautomatiseerde beslissingen vereist.
Deze conceptuele blog besprak de kernelementen van classificaties in machine learning en gaf voorbeelden van domeinen waarin ze worden toegepast. Tot slot behandelden we de implementatie van logistische regressie en Support Vector Machine na het uitvoeren van undersampling en SMOTE-oversampling om een gebalanceerde dataset te creëren voor het trainen van de modellen.
We hopen dat dit je heeft geholpen om dit onderwerp—classificatie in machine learning—beter te begrijpen. Je kunt je leerpad vervolgen met de Machine Learning Scientist with Python-track, die zowel supervised, unsupervised als deep learning behandelt. Ook krijg je een goede introductie tot natural language processing, beeldverwerking, Spark en Keras.
Machine learning-cursussen
Cursus
Cursus
Cursus
blog
Adel Nehme
15 min
