
Kurs
Data Engineering'e Giriş
4 sa
128.3K
Geleneksel olarak, veri ambarları yapılandırılmış veri ve iş zekâsı için başvurulan çözümdü. Ancak büyük veri, yapay zekâ ve makine öğreniminin yükselişiyle, hem veri ambarlarının hem de veri göllerinin güçlü yanlarını birleştiren daha yeni bir mimari—veri lakehouse—ortaya çıktı.
Bu rehberde şunları inceleyeceğiz:
Haydi başlayalım!
Veri ambarı; iş zekâsı (BI), raporlama ve analitik için verileri depolayan, düzenleyen ve analiz eden merkezi bir sistemdir. Birçok kaynaktan yapılandırılmış veriyi entegre eder ve yüksek derecede düzenli bir şema izleyerek tutarlılık ve güvenilirlik sağlar. Veri ambarları, işletmelerin veriye dayalı kararları verimli şekilde almasına yardımcı olmada merkezi bir rol oynar.
Veri lakehouse; veri gölünün ölçeklenebilirliği ve esnekliğini, veri ambarının yapılandırılmış performansı ve güvenilirliğiyle birleştiren modern bir veri mimarisidir. Kuruluşların yapılandırılmış, yarı yapılandırılmış ve yapılandırılmamış verileri tek bir sistemde depolamasına, yönetmesine ve analiz etmesine olanak tanır.
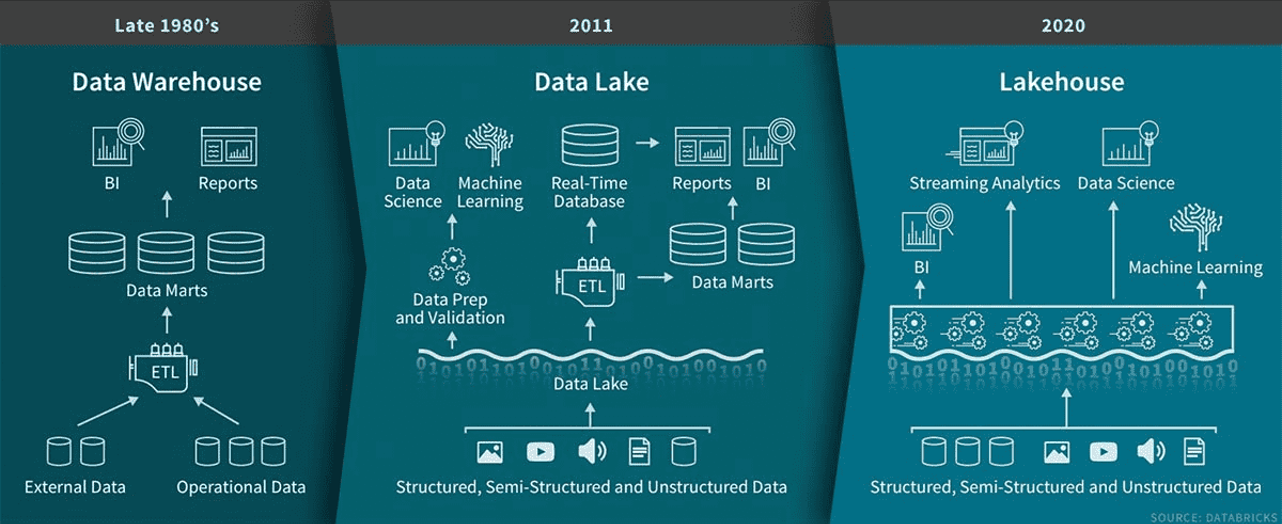
Veri mimarisinin 1980’lerin sonlarındaki veri ambarlarından 2011’de veri göllerine ve nihayet 2020’de lakehouse’lara evrimi. Görsel kaynağı: Databricks.
Bu kurslarla veri mühendisliğini daha yakından öğrenin!
Kurs
Kurs
Kurs
blog
Abid Ali Awan
14 dk.
blog
Dario Radečić
15 dk.
Eğitim
Kurtis Pykes
Eğitim
Adel Nehme
