
Courses
Introduction to Data Engineering
4 giờ
128.3K
Truyền thống, data warehouse là giải pháp ưu tiên cho dữ liệu có cấu trúc và business intelligence. Tuy nhiên, với sự trỗi dậy của big data, AI và machine learning, một kiến trúc mới — data lakehouse — đã xuất hiện, kết hợp điểm mạnh của cả data warehouse và data lake.
Trong hướng dẫn này, chúng ta sẽ khám phá:
Hãy bắt đầu!
Data warehouse là một hệ thống tập trung để lưu trữ, tổ chức và phân tích dữ liệu phục vụ business intelligence (BI), báo cáo và phân tích. Nó tích hợp dữ liệu có cấu trúc từ nhiều nguồn và tuân theo một lược đồ tổ chức chặt chẽ, đảm bảo tính nhất quán và tin cậy. Data warehouse đóng vai trò trung tâm giúp doanh nghiệp ra quyết định dựa trên dữ liệu một cách hiệu quả.
Data lakehouse là một kiến trúc dữ liệu hiện đại kết hợp khả năng mở rộng và linh hoạt của data lake với hiệu năng có cấu trúc và độ tin cậy của data warehouse. Nó cho phép tổ chức lưu trữ, quản lý và phân tích dữ liệu có cấu trúc, bán cấu trúc và phi cấu trúc trong một hệ thống duy nhất.
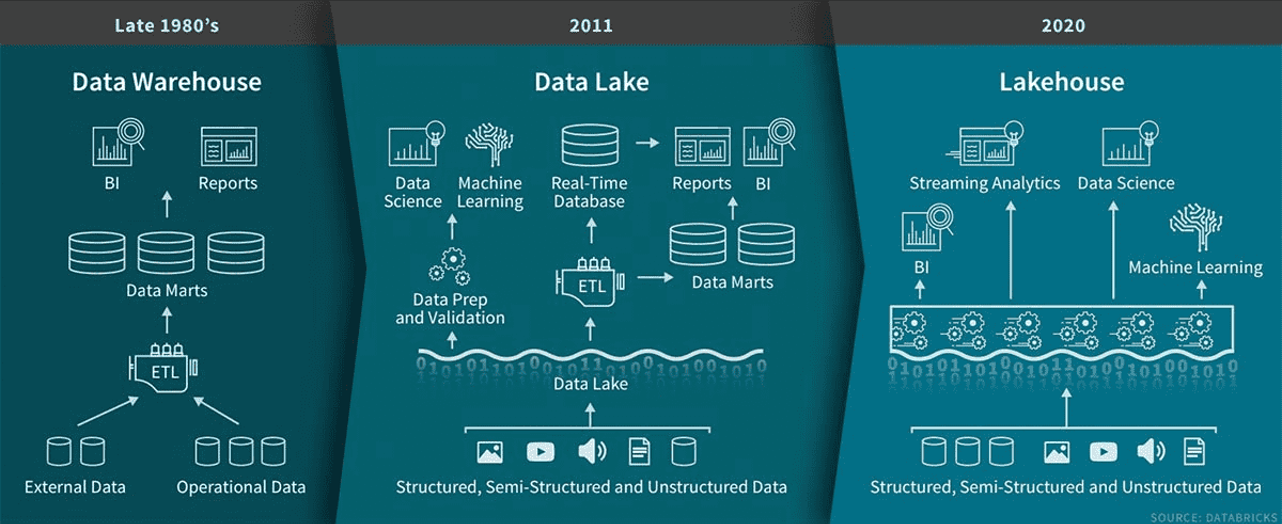
Sự phát triển của kiến trúc dữ liệu từ data warehouse cuối thập niên 1980 đến data lake năm 2011 và cuối cùng là lakehouse năm 2020. Nguồn ảnh: Databricks.
Tìm hiểu thêm về data engineering với các khóa học này!
Courses
Courses
Courses