
Kurs
Einführung in das Data Engineering
4 Std.
127.7K
Traditionell sind Data Warehouses die beste Lösung für strukturierte Daten und Business Intelligence. Mit dem Aufkommen von Big Data, KI und maschinellem Lernen ist jedoch eine neuere Architektur entstanden - das Data Lakehouse -, das die Stärken von Data Warehouses und Data Lakes kombiniert.
In diesem Leitfaden erfahren wir mehr darüber:
Lass uns eintauchen!
Ein Data Warehouse ist ein zentrales System, das Daten für Business Intelligence (BI), Berichte und Analysen speichert, organisiert und analysiert. Es integriert strukturierte Daten aus verschiedenen Quellen und folgt einem hoch organisierten Schema, das Konsistenz und Zuverlässigkeit gewährleistet. Data Warehouses spielen eine zentrale Rolle dabei, dass Unternehmen datengestützte Entscheidungen effizient treffen können.
Ein Data Lakehouse ist eine moderne Datenarchitektur, die die Skalierbarkeit und Flexibilität eines Data Lakes mit der strukturierten Leistung und Zuverlässigkeit eines Data Warehouses kombiniert. Es ermöglicht Unternehmen, strukturierte, halbstrukturierte und unstrukturierte Daten in einem einzigen System zu speichern, zu verwalten und zu analysieren.
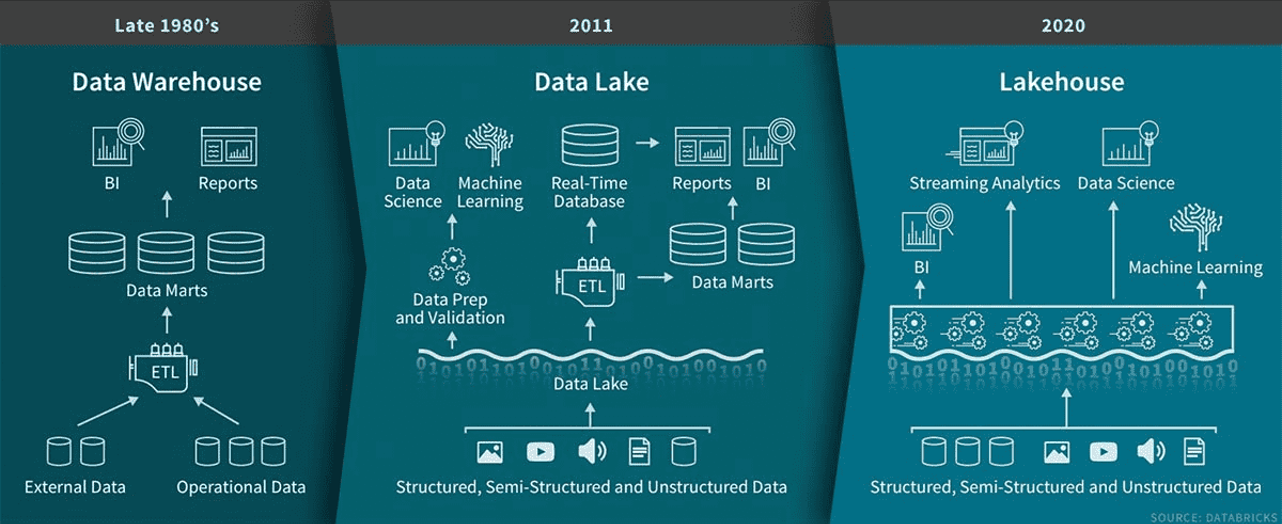
Die Entwicklung der Datenarchitektur von Data Warehouses in den späten 1980er Jahren zu Data Lakes im Jahr 2011 und schließlich zu Lakehouses im Jahr 2020. Bildquelle: Databricks.
Lerne mehr über Data Engineering mit diesen Kursen!
Kurs
Kurs
Kurs
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
4 Min.
Tutorial
Sejal Jaiswal
Tutorial
Allan Ouko
Tutorial
Matt Crabtree

