
Course
Introduction to Data Engineering
4 hr
127.6K
Traditionally, data warehouses have been the go-to solution for structured data and business intelligence. However, with the rise of big data, AI, and machine learning, a newer architecture—the data lakehouse—has emerged, combining the strengths of both data warehouses and data lakes.
In this guide, we’ll explore:
Let’s dive in!
A data warehouse is a centralized system that stores, organizes, and analyzes data for business intelligence (BI), reporting, and analytics. It integrates structured data from multiple sources and follows a highly organized schema, ensuring consistency and reliability. Data warehouses play a central role in helping businesses make data-driven decisions efficiently.
A data lakehouse is a modern data architecture that combines the scalability and flexibility of a data lake with the structured performance and reliability of a data warehouse. It allows organizations to store, manage, and analyze structured, semi-structured, and unstructured data in a single system.
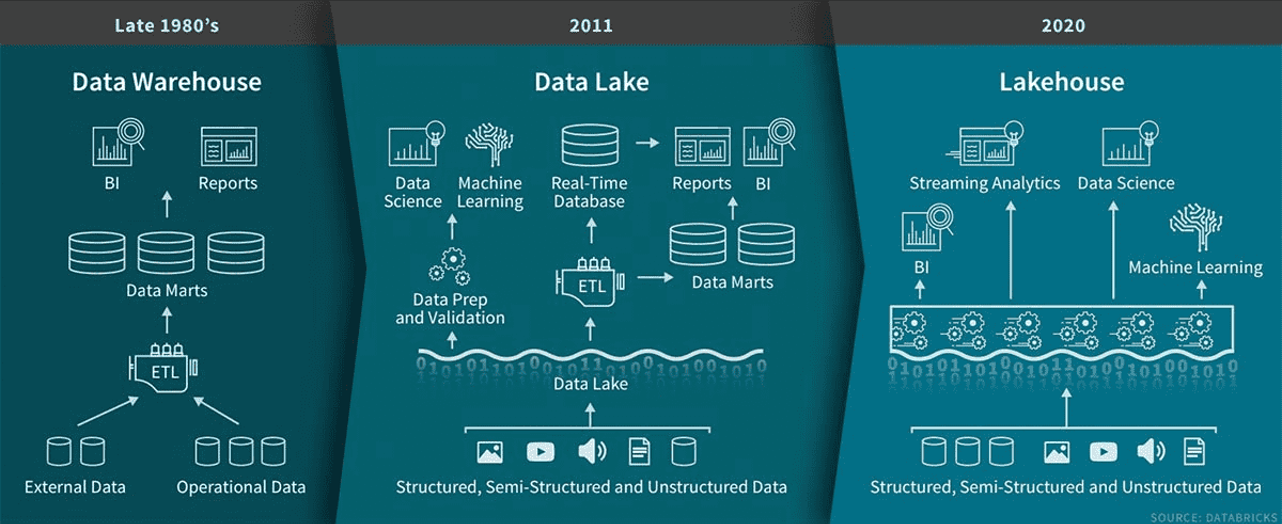
The evolution of data architecture from data warehouses in the late 1980s to data lakes in 2011 and finally to lakehouses in 2020. Image source: Databricks.
Learn more about data engineering with these courses!
Course
Course
Course
blog
DataCamp Team
4 min
blog
Moez Ali
15 min
blog
Tim Lu
13 min
blog
Patrick Brus
14 min
blog
Laiba Siddiqui
11 min
blog
Kurtis Pykes
15 min