
Cursus
Introductie tot Data Engineering
4 Hr
128.3K
Traditioneel waren datawarehouses de standaardoplossing voor gestructureerde data en business intelligence. Maar met de opkomst van big data, AI en machine learning is er een nieuwere architectuur ontstaan: de datalakehouse, die de sterke punten van zowel datawarehouses als datalakes combineert.
In deze gids behandelen we:
Laten we erin duiken!
Een datawarehouse is een gecentraliseerd systeem dat data opslaat, organiseert en analyseert voor business intelligence (BI), rapportage en analytics. Het integreert gestructureerde data uit meerdere bronnen en volgt een sterk georganiseerde schema, wat zorgt voor consistentie en betrouwbaarheid. Datawarehouses spelen een centrale rol bij het helpen van bedrijven om efficiënt datagedreven beslissingen te nemen.
Een datalakehouse is een moderne data-architectuur die de schaalbaarheid en flexibiliteit van een datalake combineert met de gestructureerde performance en betrouwbaarheid van een datawarehouse. Het stelt organisaties in staat om gestructureerde, semi-gestructureerde en ongestructureerde data op te slaan, te beheren en te analyseren in één systeem.
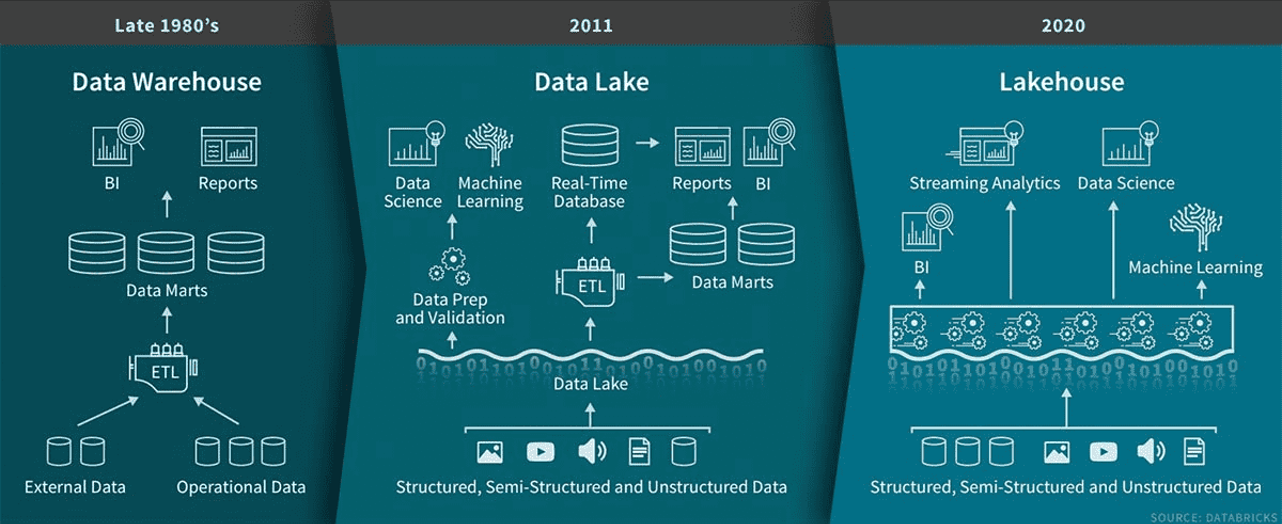
De evolutie van data-architectuur van datawarehouses in de late jaren 80 naar datalakes in 2011 en uiteindelijk lakehouses in 2020. Beeldbron: Databricks.
Leer meer over data engineering met deze cursussen!
Cursus
Cursus
Cursus
blog
Adel Nehme
15 min
