
Curso
Introducción a la ingeniería de datos
4 h
127.7K
Tradicionalmente, los almacenes de datos han sido la solución para los datos estructurados y la inteligencia empresarial. Sin embargo, con el auge de los macrodatos, la IA y el aprendizaje automático, hasurgido una nueva arquitectura, el lago de datos, que combina los puntos fuertes de los almacenes y los lagos de datos.
En esta guía, exploraremos:
¡Vamos a sumergirnos!
Un almacén de datos es un sistema centralizado que almacena, organiza y analiza datos para inteligencia empresarial (BI), elaboración de informes y análisis. Integra datos estructurados de múltiples fuentes y sigue un esquema muy organizado, garantizando coherencia y fiabilidad. Los almacenes de datos desempeñan un papel fundamental para ayudar a las empresas a tomar decisiones basadas en datos de forma eficiente.
Un lago de datos es una arquitectura de datos moderna que combina la escalabilidad y flexibilidad de un lago de datos con el rendimiento estructurado y la fiabilidad de un almacén de datos. Permite a las organizaciones almacenar, gestionar y analizar datos estructurados, semiestructurados y no estructurados en un único sistema.
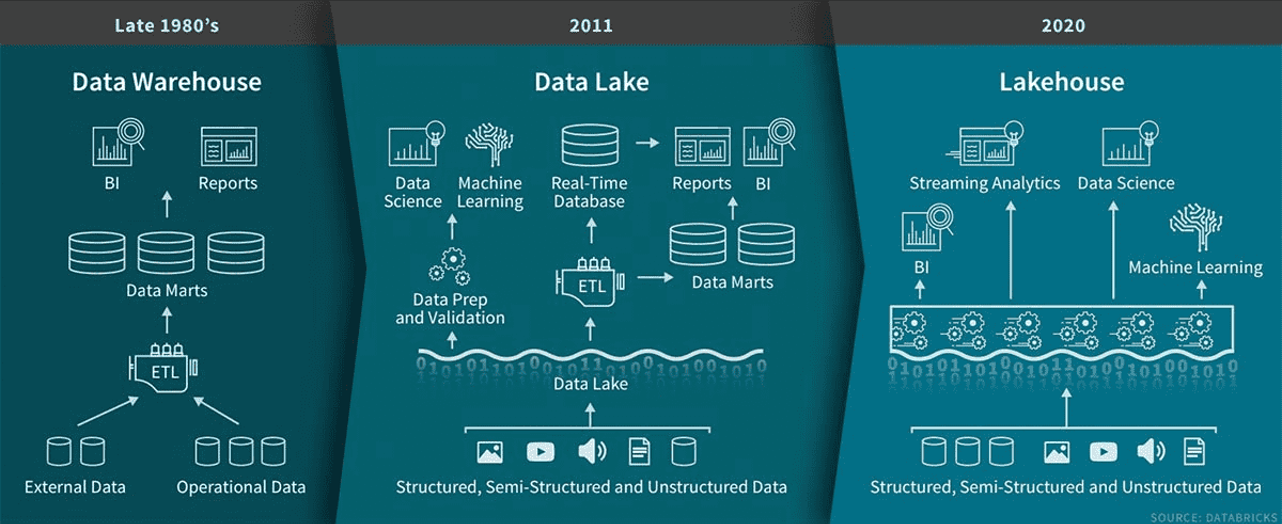
La evolución de la arquitectura de datos desde los almacenes de datos a finales de los años 80 a los lagos de datos en 2011 y, finalmente, a los lakehouses en 2020. Fuente de la imagen: Databricks.
¡Aprende más sobre ingeniería de datos con estos cursos!
Curso
Curso
Curso
blog
Gus Frazer
14 min
blog
Tim Lu
11 min
blog
Karlijn Willems
11 min
blog
Kurtis Pykes
12 min
blog
Matt Crabtree
10 min
blog
Mike Shakhomirov
11 min
