
Corso
Introduzione al Data Engineering
4 h
128.3K
Tradizionalmente, i data warehouse sono stati la soluzione di riferimento per i dati strutturati e la business intelligence. Tuttavia, con l’ascesa di big data, AI e machine learning, è emersa un’architettura più recente — il data lakehouse — che combina i punti di forza sia dei data warehouse sia dei data lake.
In questa guida esploreremo:
Iniziamo!
Un data warehouse è un sistema centralizzato che archivia, organizza e analizza i dati per business intelligence (BI), reporting e analytics. Integra dati strutturati da più fonti e segue uno schema altamente organizzato, garantendo coerenza e affidabilità. I data warehouse svolgono un ruolo centrale nell’aiutare le aziende a prendere decisioni data-driven in modo efficiente.
Un data lakehouse è un’architettura dati moderna che combina la scalabilità e la flessibilità di un data lake con le prestazioni strutturate e l’affidabilità di un data warehouse. Consente alle organizzazioni di archiviare, gestire e analizzare dati strutturati, semi-strutturati e non strutturati in un unico sistema.
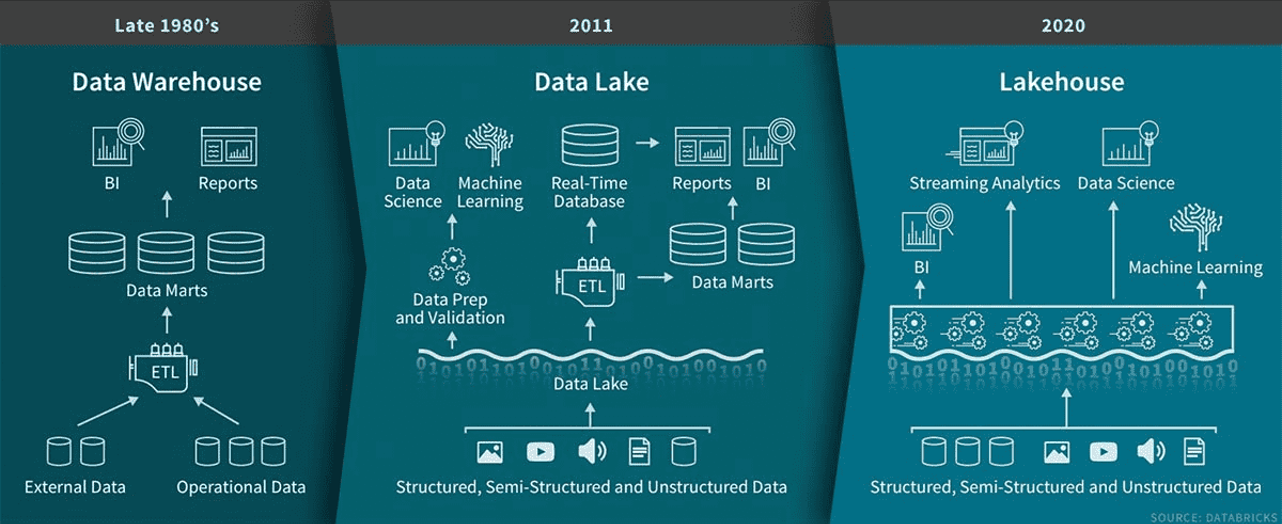
L’evoluzione dell’architettura dei dati dai data warehouse alla fine degli anni ’80 ai data lake nel 2011 e infine ai lakehouse nel 2020. Fonte immagine: Databricks.
Scopri di più sulla data engineering con questi corsi!
Corso
Corso
Corso
blog
Tim Lu
12 min
blog
Abid Ali Awan
10 min
blog
Abid Ali Awan
15 min

