
Curso
Introdução à Engenharia de Dados
4 h
127.7K
Tradicionalmente, os data warehouses têm sido a solução ideal para dados estruturados e business intelligence. No entanto, com o surgimento do big data, da IA e do aprendizado de máquina, surgiu uma nova arquitetura - o data lakehouse -que combina os pontos fortes dos data warehouses e dos data lakes.
Neste guia, exploraremos:
Vamos mergulhar de cabeça!
Um data warehouse é um sistema centralizado que armazena, organiza e analisa dados para business intelligence (BI), relatórios e análises. Ele integra dados estruturados de várias fontes e segue um esquema altamente organizado, garantindo consistência e confiabilidade. Os data warehouses desempenham um papel central para ajudar as empresas a tomar decisões orientadas por dados de forma eficiente.
Um data lakehouse é uma arquitetura de dados moderna que combina a escalabilidade e a flexibilidade de um data lake com o desempenho estruturado e a confiabilidade de um data warehouse. Ele permite que as organizações armazenem, gerenciem e analisem dados estruturados, semiestruturados e não estruturados em um único sistema.
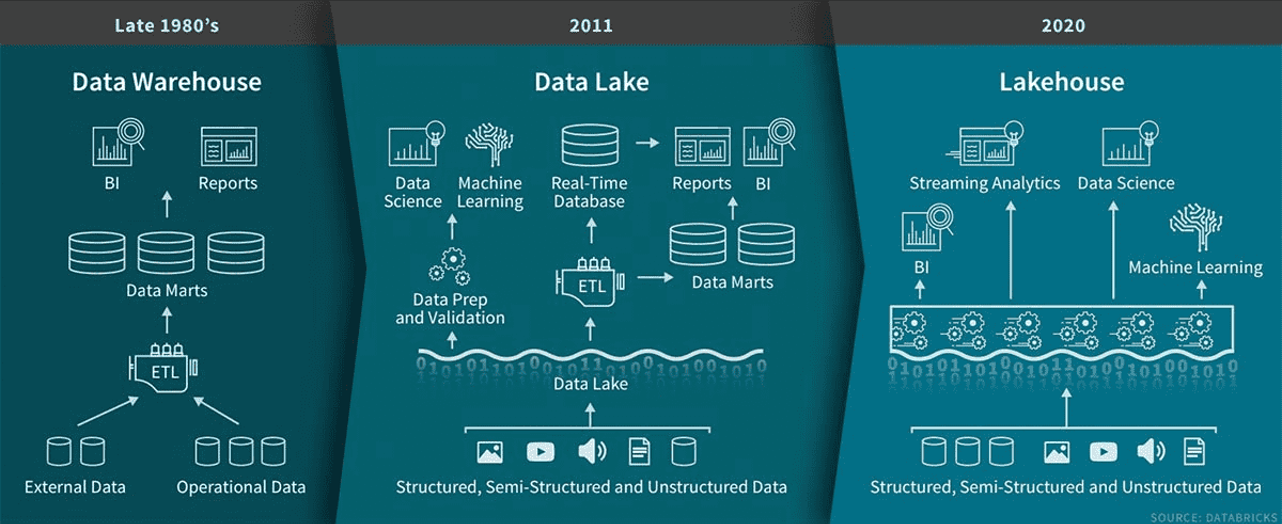
A evolução da arquitetura de dados de data warehouses no final da década de 1980 para data lakes em 2011 e, finalmente, para lakehouses em 2020. Fonte da imagem: Databricks.
Saiba mais sobre engenharia de dados com estes cursos!
Curso
Curso
Curso
blog
Austin Chia
8 min
blog
Tim Lu
11 min
blog
Joleen Bothma
9 min
blog
Moez Ali
11 min
blog
Joleen Bothma
11 min
Tutorial
Zoumana Keita

