
Cours
Introduction au data engineering
4 h
127.6K
Traditionnellement, les entrepôts de données ont été la solution de choix pour les données structurées et l'intelligence économique. Cependant, avec l'essor du big data, de l'IA et de l'apprentissage automatique, une nouvelle architecture - le data lakehouse -est apparue, combinant les points forts des entrepôts de données et des lacs de données.
Dans ce guide, nous allons explorer :
Plongeons dans l'aventure !
Un entrepôt de données est un système centralisé qui stocke, organise et analyse les données à des fins de veille stratégique (BI), de reporting et d'analyse. Il intègre des données structurées provenant de sources multiples et suit un schéma hautement organisé, ce qui garantit la cohérence et la fiabilité. Les entrepôts de données jouent un rôle central en aidant les entreprises à prendre efficacement des décisions fondées sur des données.
Un data lakehouse est une architecture de données moderne qui combine l'évolutivité et la flexibilité d'un data lake avec la performance structurée et la fiabilité d'un data warehouse. Il permet aux organisations de stocker, de gérer et d'analyser des données structurées, semi-structurées et non structurées dans un système unique.
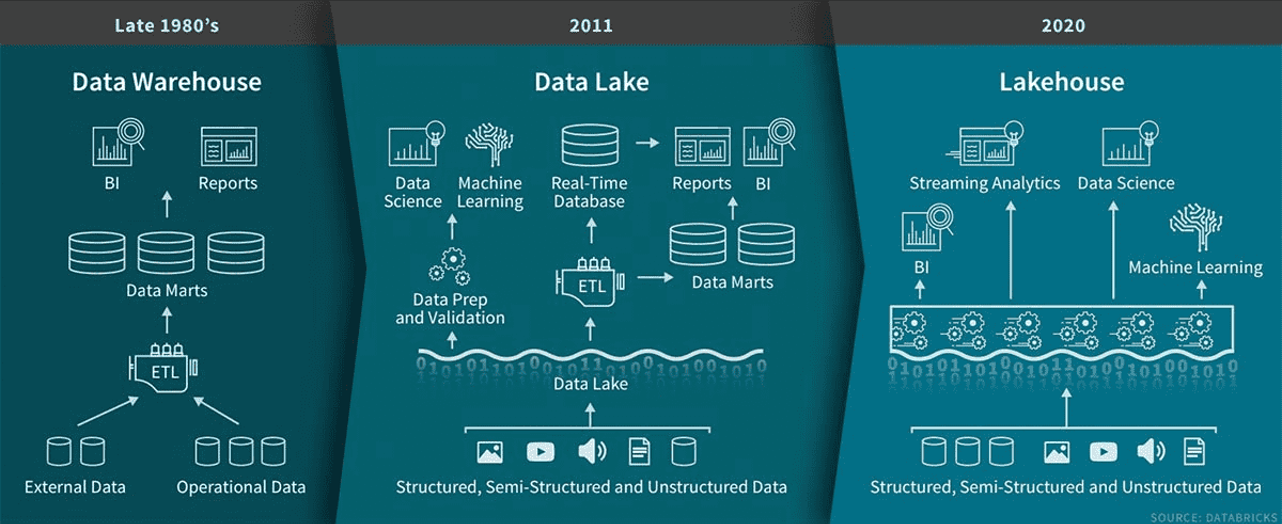
L'évolution de l'architecture des données, qui est passée des entrepôts de données à la fin des années 1980 aux lacs de données en 2011 et enfin aux entrepôts de données en 2020. Source de l'image : Databricks.
Apprenez-en plus sur l'ingénierie des données avec ces cours !
Cours
Cours
Cours
blog
Kurtis Pykes
15 min
blog
Nisha Arya Ahmed
15 min
blog
Nathaniel Taylor-Leach
8 min
Tutoriel
Samuel Shaibu
Tutoriel
Sejal Jaiswal
