
Kursus
Pengantar Data Engineering
4 Hr
128.3K
Secara tradisional, data warehouse menjadi solusi andalan untuk data terstruktur dan business intelligence. Namun, seiring berkembangnya big data, AI, dan machine learning, muncul arsitektur yang lebih baru—data lakehouse—yang menggabungkan kekuatan data warehouse dan data lake.
Dalam panduan ini, kita akan membahas:
Mari kita mulai!
Data warehouse adalah sistem terpusat yang menyimpan, mengatur, dan menganalisis data untuk kebutuhan business intelligence (BI), pelaporan, dan analitik. Sistem ini mengintegrasikan data terstruktur dari berbagai sumber dan mengikuti skema yang sangat terorganisasi, sehingga memastikan konsistensi dan keandalan. Data warehouse berperan penting dalam membantu bisnis membuat keputusan berbasis data secara efisien.
Data lakehouse adalah arsitektur data modern yang menggabungkan skalabilitas dan fleksibilitas data lake dengan performa terstruktur dan keandalan data warehouse. Arsitektur ini memungkinkan organisasi menyimpan, mengelola, dan menganalisis data terstruktur, semi-terstruktur, dan tidak terstruktur dalam satu sistem.
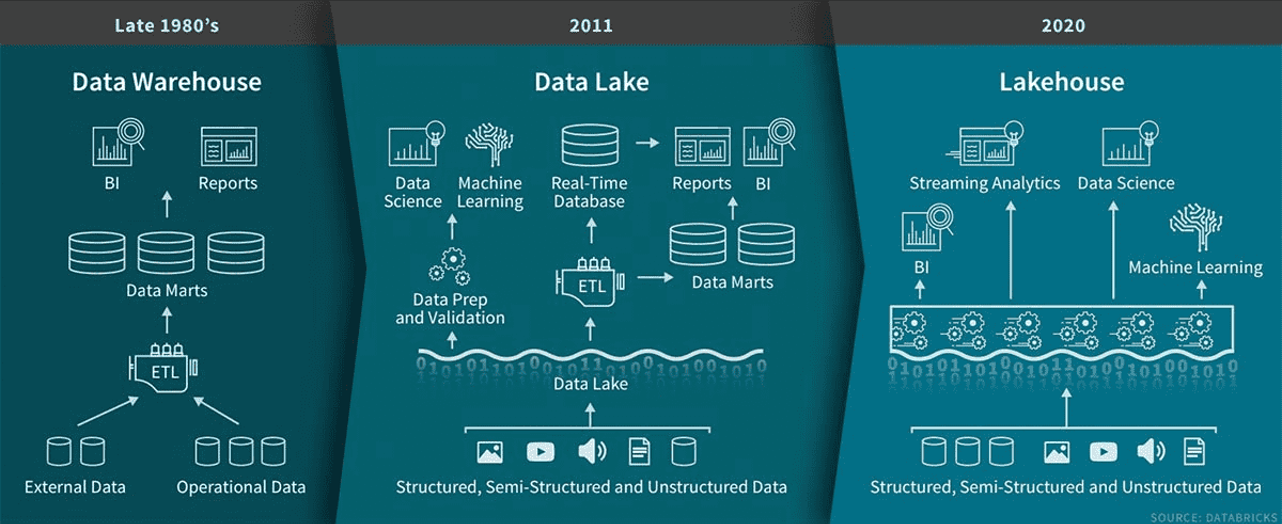
Evolusi arsitektur data dari data warehouse pada akhir 1980-an ke data lake pada 2011 dan akhirnya ke lakehouse pada 2020. Sumber gambar: Databricks.
Pelajari lebih lanjut tentang data engineering dengan kursus-kursus ini!
Kursus
Kursus
Kursus
blogs
Dario Radečić
15 mnt
blogs
Hugo Bowne-Anderson
13 mnt
blogs
David Woods
13 mnt
blogs
Javier Canales Luna
14 mnt
