
Program
Profesyonel Veri Mühendisi Python'da
40 sa
dbt (data build tool), modern veri mühendisliği ve analitik iş akışlarında yaygın olarak kullanılan bir geliştirme çerçevesi haline geldi. Veri analistleri genellikle SQL ile dönüşümleri yazmak için veri mühendislerine güvenir. Ancak dbt ile dönüşümleri kendileri yazabilir ve veriler üzerinde daha fazla kontrol sahibi olabilirler. Ayrıca Git gibi popüler sürüm kontrol sistemleriyle entegrasyona izin vererek ekip iş birliğini geliştirir.
Veri mühendisi, veri analisti veya veri bilimci gibi bir veri ambarı rolüne hazırlanıyorsanız, temel ve ileri düzey dbt sorularına hâkim olmalısınız!
Bu yazıda, temel kavramlarınızı ve ileri düzey problem çözme becerilerinizi geliştirmek için en sık sorulan mülakat sorularını özetledim.
dbt, verileri dönüştürmenizi, doğruluğunu test etmenizi ve değişiklikleri tek bir platformda takip etmenizi sağlayan açık kaynaklı bir veri dönüşüm çerçevesidir. Diğer ETL (extract, transform, load) araçlarının aksine dbt yalnızca dönüşüm kısmını (T) yapar.
Bazı diğer ETL araçları verileri çeşitli kaynaklardan çıkarır, ambarın dışında dönüştürür ve sonra geri yükler. Bu çoğu zaman uzman seviyede kodlama bilgisi ve ek araçlar gerektirir. Ancak dbt bunu kolaylaştırır — yalnızca SQL kullanarak ambar içinde dönüşüm yapılmasına imkân tanır.
40.000’den fazla büyük şirket verilerini düzenlemek için dbt kullanıyor — bu nedenle işe alım uzmanları, veriyle ilgili rollerde en önemli becerilerden biri olarak listeler. Dolayısıyla, başlangıç seviyesinde bir veri uygulayıcısı olarak bile buna hâkim olursanız birçok kariyer fırsatının kapısını aralayabilirsiniz!
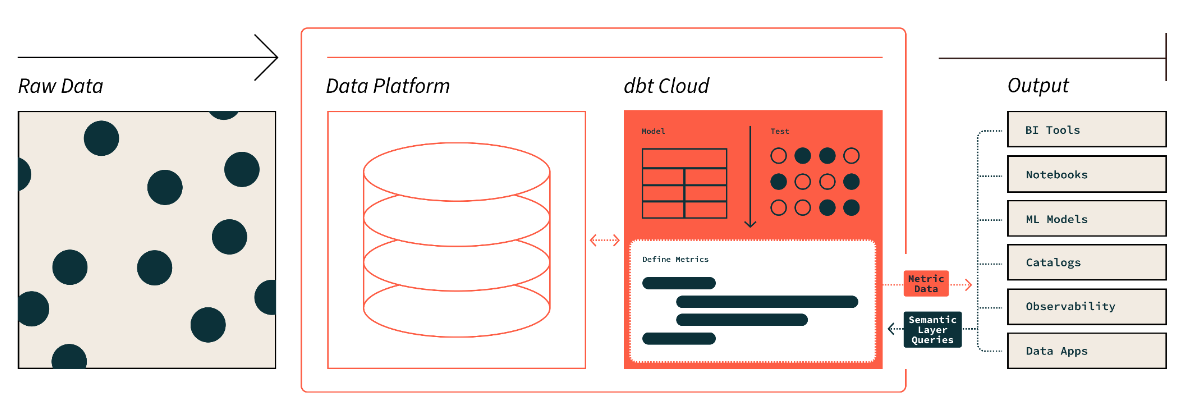
dbt anlamsal katmanı. Görsel kaynağı: dbt
Mülakat sürecinin başında görüşmeci temel bilginizi ölçer. Bunun için şu tür temel sorular sorabilir:
dbt, bir veri ekibini verileri dönüştürme, belgeleme ve test etme konusunda ortak bir zeminde buluşturur. Verilerin güvenilir ve anlaşılır olmasına yardımcı olur. dbt’nin yaygın kullanım alanları şunlardır:
Hayır, dbt bir programlama dili değildir. Ambar içindeki veri dönüşüm işlerine yardımcı olan bir araçtır. SQL yazmayı biliyorsanız, dbt ile kolayca çalışabilirsiniz. Belirli görevler için Python’u da desteklemeye başladı. Ancak özünde SQL tabanlı dönüşümleri yönetir ve çalıştırır.
dbt ve Spark farklı amaçlara hizmet eder ve farklı türde iş akışlarını hedefler. İşte veri altyapısındaki rollerine dair bir karşılaştırma:
|
Özellik |
dbt |
Spark |
|
Rol |
SQL tabanlı veri dönüşümleri ve modelleme |
Dağıtık veri işleme ve analitik |
|
Çekirdek dil |
Öncelikli SQL, sınırlı Python desteğiyle |
SQL, Python, Scala, Java, R desteği |
|
Veri yönetişimi |
Dokümantasyon ve köken (lineage) desteği |
Erişim kontrolü, denetim ve veri kökeni sağlar |
|
Hedef kullanıcılar |
SQL kullanıcıları, analistler ve mühendislik becerisi olmayan ekipler |
Veri mühendisleri, veri bilimciler, geliştiriciler |
|
Dönüşüm karmaşıklığı |
Yalnızca SQL dönüşümleri ve modellemeye odaklanır |
Diğer dillerdeki karmaşık dönüşümleri de kaldırabilir |
|
Test ve doğrulama |
Yerleşik test yetenekleri vardır |
Özel test stratejileri gerekir (birim ve entegrasyon) |
dbt veri ekiplerine büyük değer katmasına rağmen, özellikle ölçek ve karmaşıklık arttığında bazı zorluklar da doğurabilir. En yaygın zorluklardan bazıları şunlardır:
Yukarıdaki potansiyel zorlukların etrafından nasıl dolaşılacağını bilmek, işverenlerin aradığı bir yetkinliktir; bu sorunun önemini göz ardı etmeyin.
dbt’nin iki ana sürümü vardır:
dbt Core, kullanıcıların yerelde SQL tabanlı dönüşümler yazmasına, çalıştırmasına ve yönetmesine olanak tanıyan dbt’nin ücretsiz ve açık kaynaklı sürümüdür. dbt projelerini yürütmek, modelleri test etmek ve veri hatları oluşturmak için bir komut satırı arayüzü (CLI) sunar. Açık kaynak olduğundan, dbt Core kullanıcıların dağıtım, orkestrasyon ve altyapı kurulumlarını kendilerinin yönetmesini gerektirir; genellikle otomasyon için egrating with tools like Airflow or Kubernetes for automation.
dbt Cloud ise dbt’nin geliştiricileri (Fishtown Analytics) tarafından sunulan yönetilen bir hizmettir. dbt Core’un tüm yeteneklerinin yanı sıra web tabanlı bir arayüz, entegre zamanlama, iş yönetimi ve iş birliği araçları gibi ek özellikler sunar. dbt Cloud ayrıca built-in CI/CD (sürekli entegrasyon ve dağıtım) özellikleri, API erişimi ve daha sıkı güvenlik ihtiyaçları olan kuruluşlar için SOC 2 ve HIPAA gibi gelişmiş güvenlik uyumluluğu içerir.
Artık temel dbt sorularını ele aldığımıza göre, işte bazı orta düzey dbt soruları. Bunlar belirli teknik yönlere ve kavramlara odaklanır.
dbt’de kaynaklar ham veri tabakalarıdır. Bu ham tablolarda doğrudan SQL sorguları yazmayız — şema ve tablo adını belirtip bunları kaynak olarak tanımlarız. Bu, tablolardaki veri nesnelerine atıfta bulunmayı kolaylaştırır.
Veritabanınızda sales şemasında orders adlı bir ham veri tablonuz olduğunu düşünün. Bu tabloyu doğrudan sorgulamak yerine, onu dbt’de şu şekilde bir kaynak olarak tanımlarsınız:
sources.yml dosyanızda kaynağı tanımlayın:
version: 2
sources:
- name: sales
tables:
- name: ordersKaynağı dbt modellerinizde kullanın:
Bir kez tanımlandıktan sonra, ham orders tablosuna dönüşümlerinizde şu şekilde atıfta bulunabilirsiniz:
SELECT *
FROM {{ source('sales', 'orders') }}Bu yaklaşım ham tablo tanımını soyutlayarak yönetimi kolaylaştırır ve alttaki tablo yapısı değişirse her sorguyu değil, tek bir yeri (kaynak tanımını) güncelleyebilmenizi sağlar.
dbt’de kaynak kullanmanın faydaları:
Bir dbt modeli, ham veriler için dönüşüm mantığını tanımlayan bir SQL veya Python dosyasıdır. dbt’de modeller; toplulaştırmalar, join’ler veya her tür veri işleme dahil olmak üzere dönüşümleri yazdığınız temel bileşendir.
SELECT ifadelerini kullanır ve .sql dosyaları olarak kaydedilir..py dosyaları olarak kaydedilir ve pandas gibi Python kütüphanelerini kullanarak veriyi işleyebilmenizi sağlar.SQL model örneği:
Bir SQL modeli, SQL sorguları kullanarak ham verileri dönüştürür. Örneğin, bir orders tablosundan sipariş özeti oluşturmak için:
--orders_summary.sql
WITH orders_cte AS (
SELECT
customer_id,
COUNT(order_id) AS total_orders,
SUM(order_amount) AS total_revenue
FROM {{ ref('orders') }}
GROUP BY customer_id
)
SELECT *
FROM orders_cteBu örnekte:
orders_summary.sql modeli, her müşteri için toplam sipariş ve gelir özetini SQL kullanarak oluşturur.orders tablosuna (zaten bir dbt modeli veya kaynak olarak tanımlanmış) başvurur.Python model örneği:
Bir Python modeli, Python kodu kullanarak ham verileri işler. SQL’de zahmetli olabilecek karmaşık mantıklar için özellikle yararlıdır.
# orders_summary.py
import pandas as pd
def model(dbt, session):
# Load the source data
orders = dbt.ref("orders").to_pandas()
# Perform transformations using pandas
orders_summary = orders.groupby('customer_id').agg(
total_orders=('order_id', 'count'),
total_revenue=('order_amount', 'sum')
).reset_index()
return orders_summaryBu örnekte:
Bir dbt modeli şöyle oluşturulur:
models klasörü altında bir dizin oluşturun. .sql uzantılı yeni bir metin dosyası ekleyin (veya Python modeli ise .py).dbt run komutunu çalıştırarak dönüşümü uygulayın ve modeli oluşturun.dbt, modeller arası bağımlılıkları, modeller arasında net bir bağımlılık zinciri oluşturan ref() fonksiyonuyla yönetir.
dbt’de bir dönüşüm tanımladığınızda, ambarınızdaki tablolara doğrudan başvurmak yerine diğer dbt modellerine ref() ile başvurursunuz. Bu, hangi modellerin diğerlerine bağımlı olduğunu belirleyerek dbt’nin modelleri doğru sırayla inşa etmesini sağlar.
Örneğin, orders_summary adlı bir modeliniz orders modeline bağlıysa, bunu şöyle tanımlarsınız:
WITH orders AS (
SELECT * FROM {{ ref('orders') }}
)
SELECT
customer_id,
COUNT(order_id) AS total_orders,
SUM(order_amount) AS total_revenue
FROM orders
GROUP BY customer_idBu örnekte, {{ ref('orders') }} fonksiyonu, orders modelinin orders_summary’den önce inşa edilmesini sağlar; çünkü orders_summary, orders modelindeki verilere dayanır.
dbt’de makrolar, Jinja şablonlama motoru kullanılarak yazılmış, yeniden kullanılabilir SQL kod bloklarıdır. Tekrarlayan görevleri otomatikleştirmenize, karmaşık mantığı soyutlamanıza ve SQL kodunu birden fazla modelde yeniden kullanmanıza olanak tanır; böylece dbt projeniz daha verimli ve sürdürülebilir olur.
Makrolar, dbt projenizin macros dizini içindeki .sql dosyalarında tanımlanabilir.
Makrolar, birden çok modelde benzer dönüşümler yapmanız gerektiğinde veya ortam bazlı mantık (ör. farklı şemaların kullanımı ya da dağıtım ortamlarına göre tarih biçimlerinin değiştirilmesi; geliştirme, hazırlık, üretim) gerektiğinde özellikle kullanışlıdır.
Makro oluşturma örneği:
-- macros/date_format.sql
{% macro format_date(column) %}
FORMAT_TIMESTAMP('%Y-%m-%d', {{ column }})
{% endmacro %}Bir modelde kullanım:
SELECT
customer_id,
{{ format_date('order_date') }} AS formatted_order_date
FROM {{ ref('orders') }}Bu örnekte, format_date makrosu, çağrıldığı her modelde order_date sütununun biçimini standartlaştırmak için kullanılır.
-- macros/custom_schema.sql
{% macro custom_schema_name() %}
{% if target.name == 'prod' %}
'production_schema'
{% else %}
'dev_schema'
{% endif %}
{% endmacro %}Bir modelde kullanım:
SELECT *
FROM {{ custom_schema_name() }}.ordersBurada makro, ortamın (target.name) "prod" olup olmadığını kontrol eder ve buna göre doğru şema adını döndürür.
Makrolar nasıl çalıştırılır:
Makrolar SQL modelleri gibi doğrudan çalıştırılmaz. Bunun yerine, modellerinizde veya diğer makrolarda referans verilir ve dbt projesi çalıştığında yürütülür. Örneğin bir model içinde makro kullanırsanız, dbt run komutunu çalıştırdığınızda makro da çalışır.
dbt run-operation komutuyla bazı makroları manuel olarak da çalıştırabilirsiniz. Bu genellikle tek seferlik işler için kullanılır; örneğin veri tohumlama veya bakım işlemleri.dbt’de iki test türü vardır: tekil testler ve genel testler.
Örnek: Hiçbir siparişin negatif order_amount değerine sahip olmadığından emin olmak istediğinizi varsayalım. tests dizininde aşağıdaki gibi bir tekil test yazabilirsiniz:
-- tests/no_negative_order_amount.sql
SELECT *
FROM {{ ref('orders') }}
WHERE order_amount < 0Bu test başarısız olursa, dbt orders tablosundan order_amount negatif olan tüm satırları döndürür.
|
Genel testler |
Tanım |
|
Unique |
Sütundaki benzersiz değerleri kontrol eder. |
|
Not null |
Boş alan olup olmadığını kontrol eder. |
|
Available values |
Standartlaşmayı korumak için sütun değerlerinin beklenen değer listesyle eşleştiğini doğrular. |
|
Relationships |
Tutarsız verileri kaldırmak için tablolar arasındaki başvuru bütünlüğünü kontrol eder. |
Örnek: customers tablosunda customer_id’nin benzersiz ve boş olmadığından emin olmak için schema.yml dosyanızda kolayca genel bir test tanımlayabilirsiniz:
version: 2
models:
- name: customers
columns:
- name: customer_id
tests:
- unique
- not_nullBu örnekte:
customers tablosundaki her customer_id’nin benzersiz olduğunu kontrol eder.customer_id değerinin eksik veya null olmadığını kontrol eder.İlerledikçe daha karmaşık senaryolar ve ileri düzey kavramlarla karşılaşabilirsiniz. İşte uzmanlığınızı ölçmenize ve kıdemli düzey veri mühendisliği pozisyonlarına hazırlamanıza yardımcı olacak bazı zorlayıcı mülakat soruları.
dbt’de artımlı modeller, her seferinde tüm veri kümesini yeniden işlemek yerine yalnızca yeni veya değişmiş verilerin işlenmesini sağlar. Bu, özellikle büyük veri kümeleriyle çalışırken, modeli sıfırdan yeniden oluşturmanın zaman ve kaynak açısından maliyetli olduğu durumlarda faydalıdır.
Artımlı bir model, genellikle bir zaman damgası sütununa (örneğin updated_at) dayalı bir koşula göre yalnızca yeni verileri eklemeye (veya değişmiş verileri güncellemeye) imkân tanır.
Artımlı model nasıl oluşturulur:
1. Modeli, yapılandırmada artımlı olarak tanımlayın:
{{ config(
materialized='incremental',
unique_key='id' -- or another unique column
) }}2. Yeni veya değişmiş satırları filtrelemek için is_incremental() işlevini kullanın:
SELECT *
FROM source_table
{% if is_incremental() %}
WHERE updated_at > (SELECT MAX(updated_at) FROM {{ this }})
{% endif %}3. dbt bu modeli ilk kez çalıştırdığında tüm verileri işler. Sonraki çalıştırmalarda ise yalnızca updated_at değeri modelde zaten bulunan en son değerden büyük olan satırları işler.
Artımlı modeller ne zaman kullanılır:
Jinja, SQL kodumuzu daha esnek hale getirir. Jinja ile yaygın SQL kalıpları için yeniden kullanılabilir şablonlar tanımlayabiliriz. Gereksinimler sürekli değiştiği için, Jinja’nın if ifadelerini kullanarak koşullara bağlı olarak SQL sorgularımızı ayarlayabiliriz. Bu, karmaşık mantığı bölerek SQL kodunu genellikle daha anlaşılır kılar.
Örneğin, tarih biçimini "YYYY-MM-DD"den "MM/DD/YYYY"ye dönüştürmek istiyorsanız, önceki soruda gördüğümüz örnek bir dbt makrosu şöyledir:
{% macro change_date_format(column_name) %}
to_char({{ column_name }}::date, 'MM/DD/YYYY')
{% endmacro %}Bu kod örneğinde, {{ column_name }} makroyu kullandığınızda Jinja’nın gerçek sütun adını ekleyeceği yerdir. Çalışma zamanında gerçek sütun adıyla değiştirilir. Önceki örneklerde gördüğümüz gibi, Jinja değişimin nerede olacağını göstermek için {{ }} kullanır.
dbt’de özel materyalizasyon şöyle oluşturulur:
materialization_name adıyla bir materyalizasyon makrosu tanımlayın: {% materialization materialization_name, default -%}adapter.get_relation makrolarını kullanın. Verilerin yükleneceği yer burasıdır. {% set sql %}
SELECT * FROM {{ ref('your_source_table') }}
WHERE your_conditions = true
{% endset %}
{{ adapter.execute(sql) }}{{ return(target_relation) }}
{% endmaterialization %}dbt modellerimizi hata ayıklamanın iki yolu şöyledir:
1. Hataları belirlemek ve izlemek için hedef klasördeki derlenmiş SQL dosyalarına erişin.
Bir dbt projesi çalıştırdığınızda, dbt (Jinja şablonlamayla yazılmış) modellerinizi ham SQL sorgularına derler ve bunları target dizinine kaydeder. Bu derlenmiş SQL, dbt’nin veri platformunuzda çalıştırdığı sorguların aynısıdır; bu dosyaları incelemek, sorunların nerede oluştuğunu belirlemenize yardımcı olabilir:
dbt run veya dbt test).target/compiled/ klasörüne gidin.2. Sorgu sonuçlarını doğrudan incelemek için VS Code için dbt Power User Eklentisini kullanın.
Visual Studio Code (VS Code) için dbt Power User eklentisi, dbt modellerinin hata ayıklanması için yararlı bir araçtır. Bu eklenti, sorgularınızı doğrudan IDE içinde gözden geçirip test etmenize olanak tanır; dbt, terminal ve veritabanınız arasında geçiş yapma ihtiyacını azaltır.
dbt sorguları şu adımlarla derler:
target/compiled dizinine kaydedilir.dbt run için sorgular, gerekirse ek bir sarmalama ile yürütmeye hazırlanır.Bu süreç, modüler ve şablonlanmış SQL’i veri ambarınıza özgü yürütülebilir sorgulara dönüştürür. Her model için son SQL’i görüntülemek ve hata ayıklamak üzere dbt compile kullanabilir veya target/compiled dizinine bakabiliriz.
Çoğu veri mühendisinin işi, dbt ile veri ambarları inşa etmek ve entegre etmek etrafında döner. Bu senaryolara ilişkin sorular mülakatlarda çok yaygındır — bu yüzden en sık sorulanları derledim:
dbt’yi Airflow ile entegre etmek, düzenli bir veri hattı kurmayı sağlar. İşte bazı avantajları:
dbt’nin anlamsal katmanı, ham verileri anladığımız dile çevirmemize imkân tanır. Ayrıca metrikleri tanımlayıp bir komut satırı arayüzü (CLI) ile sorgulayabiliriz.
Bu, veri hazırlama süresi azaldığı için maliyeti optimize etmemizi sağlar. Ayrıca metrikleri kuruluş genelinde tutarlı kıldığı için herkes aynı veri tanımlarıyla çalışır.
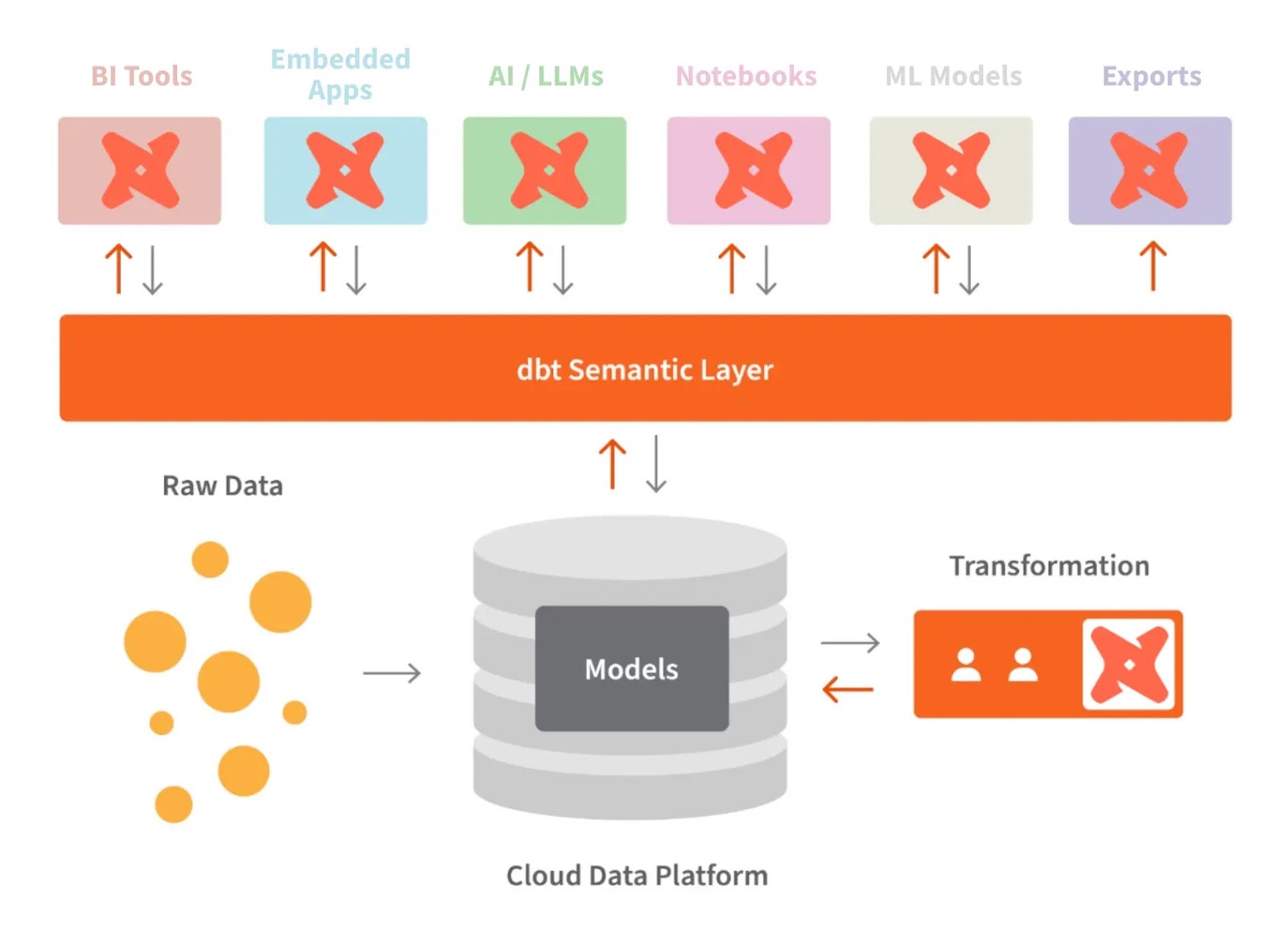
dbt ve anlamsal katman. Görsel kaynağı: dbt
BigQuery oldukça kullanışlıdır ve birçok dönüşümü yerel olarak yapabilir; yine de dbt gerekli olabilir. Nedeni şu:
ref() fonksiyonu ve makroları daha modüler ve yeniden kullanılabilir SQL koduna imkân tanır.dbt, önceki bir soruda da görüldüğü gibi iki sürümde gelir: dbt Core ve dbt Cloud. dbt Core açık kaynaklı ve ücretsiz bir sürümdür. Bu nedenle yerleşik bir güvenlik özelliği sunmaz; dağıtım ve güvenlikten kullanıcılar sorumludur.
Buna karşılık dbt Cloud, tam güvenlik sağlamak üzere tasarlanmıştır. HIPAA ve diğer yaygın çerçevelere uygundur; böylece gizliliğin ihlal edilmemesini güvence altına alır. Dolayısıyla ihtiyaçlarımıza göre, iş uyumluluğumuza uygun bir dbt sürümü seçmeliyiz.
Özellikle Snowflake, BigQuery veya Redshift gibi bulut tabanlı veri ambarlarıyla çalışırken, büyük veri kümeleri için dbt dönüşümlerini optimize etmek performansı artırmak ve maliyeti azaltmak açısından kritiktir. İşte bazı temel teknikler:
1. Artımlı modeller kullanın
Artımlı modeller, her seferinde tüm veri kümesini yeniden işlemek yerine yalnızca yeni veya güncellenen verilerin işlenmesini sağlar. Bu, büyük veri kümeleri için çalışma sürelerini önemli ölçüde azaltabilir. Bu süreç, işlenen veri miktarını sınırlandırarak dönüşüm sürelerini hızlandırır.
2. Bölümlendirme ve kümelendirmeden yararlanın (Snowflake ve BigQuery gibi veritabanlarında)
Snowflake veya BigQuery gibi veritabanlarında büyük tabloların bölümlendirilmesi ve kümelendirilmesi, verileri verimli bir şekilde düzenleyerek ve sorgular sırasında taranan veri miktarını azaltarak sorgu performansını artırır.
Bölümlendirme, yalnızca ilgili veri kısımlarının sorgulanmasını sağlarken; kümelendirme, verinin fiziksel yerleşimini daha hızlı erişim için optimize eder.
3. Materyalizasyonları optimize edin (table, view, incremental)
Performansı optimize etmek için uygun materyalizasyonları kullanın:
4. Geliştirme sırasında LIMIT kullanın
Dönüşümler geliştirilirken sorgulara LIMIT eklemek, işlenen satır sayısını sınırlamak için faydalıdır. Bu, geliştirme döngülerini hızlandırır ve test sırasında devasa veri kümeleriyle çalışmayı önler.
5. Sorguları paralel çalıştırın
Veri ambarınızın sorguları paralel yürütme yeteneğinden yararlanın. Örneğin, dbt Cloud paralelliği destekler ve altyapınıza göre ayarlanabilir.
6. Veritabanına özgü optimizasyon özelliklerini kullanın
Birçok bulut veri ambarı, performans optimizasyon özellikleri sunar:
Snowflake’te dbt çalıştırmalarını optimize etmek için:
1. Tablo kümelendirme kullanın:
{{ config(
cluster_by = ["date_column", "category_column"]
) }}
SELECT ...2. Paralel model yürütmesi için Snowflake’in çoklu küme ambarlarından yararlanın:
models:
my_project:
materialized: table
snowflake_warehouse: transforming_wh3. Uygun olduğunda artımlı modeller kullanın:
{{ config(materialized='incremental', unique_key='id') }}
SELECT *
FROM source_table
{% if is_incremental() %}
WHERE updated_at > (SELECT MAX(updated_at) FROM {{ this }})
{% endif %}Bu optimizasyonlar, Snowflake’te dbt çalıştırmalarının performansını ve maliyet etkinliğini artırabilir.
Mülakat sürecinin sonunda, görüşmeciler genellikle problem çözme becerilerinizi test eder. Gerçek hayattaki sorunlara nasıl tepki vereceğinizi görmek için sorular sorabilirler.
Bu alanda gereken sosyal becerilere dair şu alıntıyı unutmayın from Deepak Goyal, CEO & Founder at Azurelib Academy, when he spoke on the DataFramed podcast:
Bir Veri Mühendisi olarak iletişim kurabilmelisiniz. Bir veri mühendisi, ne tür bir çıktı veya sonuç istediklerini anlamak için birçok paydaşla konuşması gerektiğinden iletişim kurmak zorundadır.
Deepak Goya, CEO & Founder at Azurelib Academy
Bu kurslarla veri mühendisliği hakkında daha fazlasını öğrenin!
Program
Kurs
Kurs
blog
Dario Radečić
15 dk.
blog
Abid Ali Awan
14 dk.
Eğitim
Adel Nehme
Eğitim
Kurtis Pykes
