
Programa
Engenheiro de dados profissional Em Python
40 h
O dbt (ferramenta de construção de dados) virou uma estrutura de desenvolvimento super usada nos fluxos de trabalho modernos de engenharia e análise de dados. Os analistas de dados geralmente contam com os engenheiros de dados para escrever transformações em SQL. Mas com o dbt, eles podem escrever transformações e ter mais controle sobre os dados. Ele também permite a integração com sistemas populares de controle de versão, como o Git, o que melhora a colaboração em equipe.
Se você está se preparando para uma função em warehouse, como engenheiro de dados, analista de dados ou cientista de dados, você deve estar bem versado em questões básicas e avançadas de dbt!
Neste artigo, eu mostrei as perguntas mais comuns em entrevistas pra você entender os conceitos básicos e desenvolver habilidades avançadas de resolução de problemas.
O dbt é uma estrutura de transformação de dados de código aberto que permite transformar dados, testar sua precisão e acompanhar as alterações em uma única plataforma. Diferente de outras ferramentas ETL (extrair, transformar, carregar), o dbt só faz a parte da transformação (o T).
Outras ferramentas ETL pegam os dados de várias fontes, transformam fora do warehouse e depois colocam de volta. Isso geralmente precisa de conhecimento especializado em programação e ferramentas extras. Mas o dbt facilita isso — ele permite transformações no warehouse usando só SQL.
Mais de 40.000 grandes empresas usam o dbt para otimizar dados — por isso, os recrutadores o listam como uma das habilidades mais importantes para funções relacionadas a dados. Então, se você dominar isso mesmo sendo um profissional iniciante na área de dados, isso pode abrir muitas oportunidades de carreira!
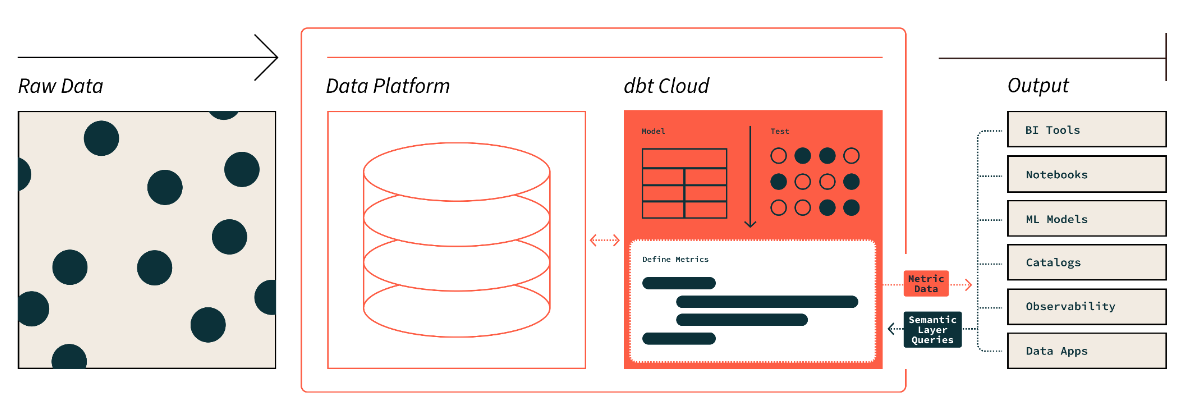
A camada semântica do dbt. Fonte da imagem: dbt
O entrevistador vai testar seus conhecimentos básicos no começo do processo de entrevista. Para isso, eles podem fazer algumas perguntas básicas como estas:
O dbt reúne uma equipe de dados em uma única página, onde eles podem transformar, documentar e testar seus dados. Isso ajuda a garantir que os dados sejam confiáveis e fáceis de entender. Os usos comuns do dbt incluem:
Não, dbt não é uma linguagem de programação. É uma ferramenta que ajuda nas tarefas de transformação de dados no warehouse. Se você sabe escrever SQL, pode trabalhar facilmente com o dbt. Também começou a dar suporte ao Python para tarefas específicas. Mas, no fundo, ele gerencia e executa transformações baseadas em SQL.
O dbt e o Spark têm finalidades diferentes e visam tipos diferentes de fluxos de trabalho. Aqui está uma comparação do papel de cada um na infraestrutura de dados:
|
Recurso |
dbt |
Spark |
|
Função |
Transformações e modelagem de dados baseadas em SQL |
Processamento e análise de dados distribuídos |
|
Linguagem principal |
SQL em primeiro lugar, com suporte limitado a Python |
Suporta SQL, Python, Scala, Java, R |
|
Governança de dados |
Documentação e suporte à linhagem |
Oferece controle de acesso, auditoria e linhagem de dados |
|
Público-alvo |
Usuários, analistas e equipes de SQL sem habilidades de engenharia |
Engenheiros de dados, cientistas de dados, desenvolvedores |
|
Complexidade da transformação |
Foca só em transformações e modelagem SQL |
Também consegue lidar com transformações complexas em outras linguagens. |
|
Testes e validação |
Tem recursos de teste integrados |
Precisa de estratégias de teste personalizadas (unidade e integração) |
Embora o dbt traga muito valor para as equipes de dados, ele também pode apresentar alguns desafios, principalmente quando a escala e a complexidade aumentam. Então, alguns dos desafios mais comuns são:
Saber como lidar com os desafios potenciais acima é algo que os empregadores procuram, então não subestime a importância dessa questão.
Tem duas versões principais do dbt:
O dbt Core é a versão gratuita e de código aberto do dbt que permite aos usuários escrever, executar e gerenciar transformações baseadas em SQL localmente. Ele oferece uma interface de linha de comando (CLI) pra executar projetos dbt, testar modelos e criar pipelines de dados. Como é um software de código aberto, o dbt Core exige que os usuários cuidem da própria implantação, orquestração e configuração da infraestrutura, geralmente em umegrando com ferramentas como Airflow ou Kubernetes para automação.
Por outro lado, o dbt Nuvem é um serviço gerenciado oferecido pelos criadores do dbt (Fishtown Analytics). Ele oferece todos os recursos do dbt Core, além de funcionalidades extras, como uma interface baseada na web, agendamento integrado, gerenciamento de tarefas e ferramentas de colaboração. A nuvem dbt também inclui recursos integrados de CI/CD (integração e implantação contínuas), acesso à API e conformidade de segurança aprimorada, como SOC 2 e HIPAA, para organizações com necessidades de segurança mais rigorosas.
Agora que já falamos sobre as perguntas básicas sobre o dbt, aqui vão algumas perguntas de nível intermediário. Eles se concentram em aspectos técnicos e conceitos específicos.
No dbt, as fontes são as tabelas de dados brutos. Não escrevemos consultas SQL diretamente nessas tabelas brutas — especificamos o esquema e o nome da tabela e os definimos como fontes. Isso facilita a referência a objetos de dados em tabelas.
Imagina que você tem uma tabela de dados brutos no seu banco de dados chamada orders no esquema sales. Em vez de consultar essa tabela diretamente, você a definiria como uma fonte no dbt assim:
Defina a fonte no seu arquivo sources.yml:
version: 2
sources:
- name: sales
tables:
- name: ordersUse a fonte nos seus modelos dbt:
Depois de definir, você pode usar a tabela bruta orders nas suas transformações assim:
SELECT *
FROM {{ source('sales', 'orders') }}Essa abordagem abstrai a definição bruta da tabela, facilitando o gerenciamento e garantindo que, se a estrutura da tabela subjacente mudar, você possa atualizá-la em um único lugar (a definição de origem), em vez de em cada consulta.
Vantagens de usar fontes no dbt:
Um modelo dbt é basicamente um arquivo SQL ou Python que define a lógica de transformação dos dados brutos. No dbt, os modelos são o componente principal onde você escreve suas transformações, sejam elas agregações, junções ou qualquer tipo de manipulação de dados.
SELECT ` para definir transformações e são salvos como arquivos `.sql `..py e permitem que você use bibliotecas Python, como pandas, para mexer nos dados.Exemplo de modelo SQL:
Um modelo SQL transforma dados brutos usando consultas SQL. Por exemplo, para criar um resumo dos pedidos a partir de uma tabela orders:
--orders_summary.sql
WITH orders_cte AS (
SELECT
customer_id,
COUNT(order_id) AS total_orders,
SUM(order_amount) AS total_revenue
FROM {{ ref('orders') }}
GROUP BY customer_id
)
SELECT *
FROM orders_cteNeste exemplo:
orders_summary.sql faz um resumo do total de pedidos e receitas de cada cliente usando SQL.orders (já definida como um modelo ou fonte dbt).Exemplo de modelo Python:
Um modelo Python mexe nos dados brutos usando código Python. Isso pode ser especialmente útil para lógicas complexas que podem ser complicadas em SQL.
# orders_summary.py
import pandas as pd
def model(dbt, session):
# Load the source data
orders = dbt.ref("orders").to_pandas()
# Perform transformations using pandas
orders_summary = orders.groupby('customer_id').agg(
total_orders=('order_id', 'count'),
total_revenue=('order_amount', 'sum')
).reset_index()
return orders_summaryNeste exemplo:
Veja como criar um modelo dbt:
models do projeto dbt. .sql dentro do diretório (ou .py se for um modelo Python).dbt run para aplicar a transformação e criar o modelo.O dbt gerencia as dependências dos modelos usando a função ` ref() `, que cria uma cadeia de dependências clara entre os modelos.
Quando você define uma transformação no dbt, em vez de referenciar diretamente as tabelas no seu warehouse, você referencia outros modelos dbt usando a função ` ref() `. Isso garante que o dbt crie os modelos na ordem certa, identificando quais modelos dependem de outros.
Por exemplo, se você tem um modelo orders_summary que depende do modelo orders, você o definiria assim:
WITH orders AS (
SELECT * FROM {{ ref('orders') }}
)
SELECT
customer_id,
COUNT(order_id) AS total_orders,
SUM(order_amount) AS total_revenue
FROM orders
GROUP BY customer_idNeste exemplo, a função ` {{ ref('orders') }} ` garante que o modelo ` orders ` seja construído antes de ` orders_summary`, já que ` orders_summary ` depende dos dadosdo modelo ` orders ` .
As macros no dbt são blocos reutilizáveis de código SQL escritos usando o mecanismo de modelagem Jinja. Eles permitem automatizar tarefas repetitivas, abstrair lógicas complexas e reutilizar código SQL em vários modelos, tornando seu projeto dbt mais eficiente e fácil de manter.
As macros podem ser definidas em arquivos .sql dentro do diretório macros do seu projeto dbt.
As macros são super úteis quando você precisa fazer transformações parecidas em vários modelos ou precisa de uma lógica específica do ambiente, tipo usar esquemas diferentes ou mudar formatos de data com base nos ambientes de implantação (por exemplo, desenvolvimento, teste ou produção).
Exemplo de como criar macros:
-- macros/date_format.sql
{% macro format_date(column) %}
FORMAT_TIMESTAMP('%Y-%m-%d', {{ column }})
{% endmacro %}Como usar num modelo:
SELECT
customer_id,
{{ format_date('order_date') }} AS formatted_order_date
FROM {{ ref('orders') }}Neste exemplo, a macro ` format_date ` é usada para padronizar o formato da coluna ` order_date ` em qualquer modelo em que ela for chamada.
-- macros/custom_schema.sql
{% macro custom_schema_name() %}
{% if target.name == 'prod' %}
'production_schema'
{% else %}
'dev_schema'
{% endif %}
{% endmacro %}Como usar num modelo:
SELECT *
FROM {{ custom_schema_name() }}.ordersAqui, a macro verifica se o ambiente (target.name) é “prod” e retorna o nome do esquema correto com base nisso.
Como executar macros:
As macros não são executadas diretamente como os modelos SQL. Em vez disso, elas são referenciadas em seus modelos ou outras macros e executadas quando o projeto dbt é executado. Por exemplo, se você usar uma macro dentro de um modelo, ela vai rodar quando você executar o comando “ dbt run ”.
dbt run-operation. Isso geralmente é usado para tarefas pontuais, como inserir dados ou fazer operações de manutenção.Testes singulares e testes genéricos são os dois tipos de teste no dbt:
Exemplo: Digamos que você queira garantir que nenhum pedido tenha um valor negativo order_amount. Você pode escrever um teste único no diretório tests assim:
-- tests/no_negative_order_amount.sql
SELECT *
FROM {{ ref('orders') }}
WHERE order_amount < 0Se esse teste falhar, o dbt vai devolver todas as linhas da tabela ` orders ` onde ` order_amount ` for negativo.
|
Testes genéricos |
Definição |
|
Único |
Verifica se tem valores únicos na coluna. |
|
Não nulo |
Verifica se há campos em branco. |
|
Valores disponíveis |
Verifica se os valores da coluna correspondem a uma lista de valores esperados para manter a padronização. |
|
Relacionamentos |
Verifica a integridade referencial entre tabelas para remover quaisquer dados inconsistentes. |
Exemplo: Você pode facilmente aplicar um teste genérico para garantir que customer_id na tabela customers seja única e não nula, definindo-o no seu arquivo schema.yml:
version: 2
models:
- name: customers
columns:
- name: customer_id
tests:
- unique
- not_nullNeste exemplo:
customer_id na tabela customers é único.customer_id está faltando ou nulo.Conforme você avança, pode encontrar cenários mais complexos e conceitos avançados. Então, aqui estão algumas perguntas desafiadoras para entrevistas que vão te ajudar a avaliar sua experiência e se preparar para cargos de engenharia de dados de nível sênior.
Os modelos incrementais no dbt são usados para processar apenas dados novos ou alterados, em vez de reprocessar todo o conjunto de dados a cada vez. Isso é super útil quando você tá trabalhando com conjuntos de dados grandes, onde reconstruir o modelo inteiro do zero seria demorado e exigiria muitos recursos.
Um modelo incremental permite que o dbt acrescente só novos dados (ou atualize os dados alterados) com base numa condição, normalmente uma coluna de carimbo de data/hora (como updated_at).
Como criar um modelo incremental:
1. Defina o modelo como incremental especificando isso na configuração do modelo:
{{ config(
materialized='incremental',
unique_key='id' -- or another unique column
) }}2. Use a função ` is_incremental() ` para filtrar linhas novas ou alteradas:
SELECT *
FROM source_table
{% if is_incremental() %}
WHERE updated_at > (SELECT MAX(updated_at) FROM {{ this }})
{% endif %}3. Quando o dbt executa esse modelo pela primeira vez, ele processa todos os dados. Para execuções posteriores, ele só vai processar linhas onde updated_at for maior que o valor mais recente que já está no modelo.
Quando usar modelos incrementais:
O Jinja deixa nosso código SQL mais flexível. Com o Jinja, a gente pode definir modelos reutilizáveis para padrões SQL comuns. E como os requisitos estão sempre mudando, a gente pode usar as instruções Jinja if pra ajustar nossas consultas SQL dependendo das condições. Isso geralmente melhora o código SQL, dividindo a lógica complexa, o que o torna mais fácil de entender.
Por exemplo, se você quiser mudar o formato da data de “AAAA-MM-DD” para “MM/DD/AAAA”, aqui vai um exemplo de macro dbt pra isso, que vimos numa pergunta anterior:
{% macro change_date_format(column_name) %}
to_char({{ column_name }}::date, 'MM/DD/YYYY')
{% endmacro %}Neste exemplo de código, {{ column_name }} é onde o Jinja coloca o nome real da coluna quando você usa a macro. Ele vai ser substituído pelo nome real da coluna durante a execução. Como vimos nos exemplos anteriores, o Jinja usa {{ }} para mostrar onde a substituição vai rolar.
Veja como criar uma materialização personalizada no dbt:
materialization_name: {% materialization materialization_name, default -%}adapter.get_relation para configurar a tabela de destino. É aqui que os dados serão carregados. {% set sql %}
SELECT * FROM {{ ref('your_source_table') }}
WHERE your_conditions = true
{% endset %}
{{ adapter.execute(sql) }}{{ return(target_relation) }}
{% endmaterialization %}Aqui estão duas maneiras de depurar nossos modelos dbt:
1. Acesse os arquivos SQL compilados na pasta de destino para identificar e programar erros.
Quando você executa um projeto dbt, o dbt compila seus modelos (escritos usando o modelo Jinja) em consultas SQL brutas e os salva no diretório ` target `. Esse SQL compilado é exatamente o que o dbt executa na sua plataforma de dados, então dar uma olhada nesses arquivos pode te ajudar a descobrir onde estão os problemas:
dbt run ou dbt test).target/compiled/ ` no diretório do seu projeto dbt.2. Usea extensão dbt Power User Extension para VS Code para ver os resultados das consultas direto.
A extensão dbt Power User para Visual Studio Code (VS Code) é uma ferramenta útil para depurar modelos dbt. Essa extensão permite que você revise e teste suas consultas diretamente no seu IDE, reduzindo a necessidade de alternar entre o dbt, o terminal e seu banco de dados.
O dbt compila consultas através das seguintes etapas:
target/compiled.dbt run, as consultas são preparadas para execução, possivelmente com encapsulamento adicional.Esse processo transforma SQL modular e baseado em modelos em consultas executáveis específicas para o seu warehouse. A gente pode usar o dbt compile ou dar uma olhada no diretório target/compiled pra ver e depurar o SQL final de cada modelo.
A maioria dos trabalhos dos engenheiros de dados gira em torno da construção e integração de warehouse com o dbt. Perguntas relacionadas a esses cenários são bem comuns em entrevistas — por isso, compilei as mais frequentes:
Integrar o dbt com o Airflow ajuda a criar um pipeline de dados mais eficiente. Aqui estão algumas das vantagens:
A camada semântica do dbt nos permite traduzir dados brutos para a linguagem que entendemos. Também podemos definir métricas e consultá-las com uma interface de linha de comando (CLI).
Isso nos permite otimizar o custo, já que a preparação dos dados leva menos tempo. Além disso, todo mundo trabalha com as mesmas definições de dados, porque isso deixa as métricas consistentes em toda a organização.
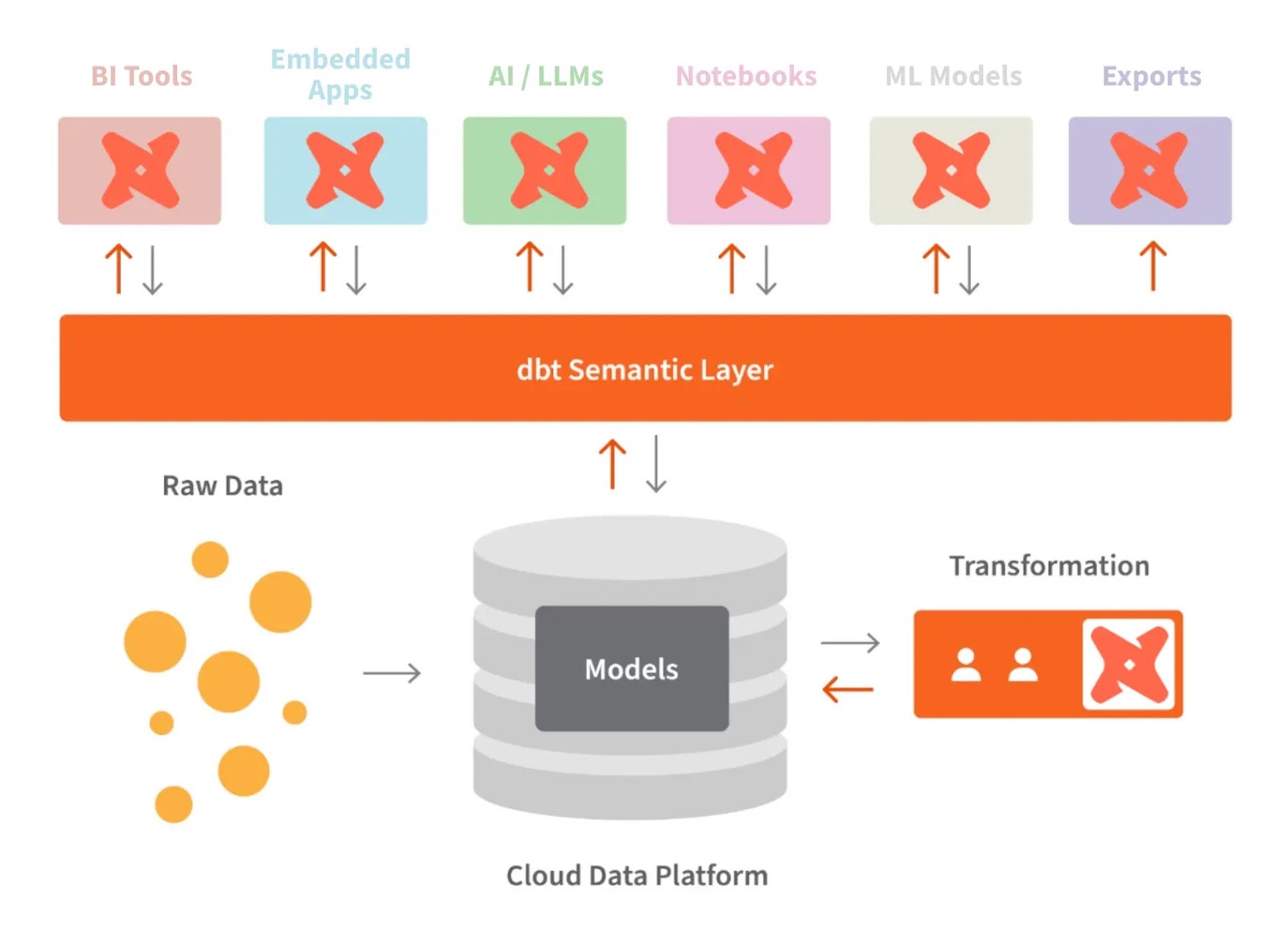
dbt e a camada semântica. Fonte da imagem: dbt
Embora o BigQuery seja bem útil e consiga lidar com várias transformações de forma nativa, o dbt ainda pode ser necessário. Eis o motivo:
ref() ` do dbt permitem um código SQL mais modular e reutilizável.O dbt vem em duas versões: dbt Core e dbt Nuvem, como vimos em uma pergunta anterior. O dbt Core é open source e funciona como uma versão gratuita. É por isso que ele não oferece nenhum recurso de segurança integrado, e os usuários são responsáveis pela sua implantação e segurança.
Mas, o dbt Nuvem foi feito pra garantir segurança total. Ele segue a HIPAA e outras estruturas comuns para garantir que a privacidade não seja prejudicada. Então, dependendo do que a gente precisa, temos que escolher uma versão do dbt que combine com as nossas necessidades de conformidade comercial.
Otimizar as transformações do dbt para grandes conjuntos de dados é essencial para melhorar o desempenho e reduzir custos, principalmente quando se lida com warehouse baseados em nuvem, como Snowflake, BigQuery ou Redshift. Aqui estão algumas técnicas importantes para otimizar o desempenho do dbt:
1. Use modelos incrementais
Os modelos incrementais permitem que o dbt processe apenas dados novos ou atualizados, em vez de reprocessar todo o conjunto de dados todas as vezes. Isso pode reduzir bastante o tempo de execução para conjuntos de dados grandes. Esse processo limita a quantidade de dados processados, acelerando os tempos de transformação.
2. Aproveite o particionamento e o agrupamento (para bancos de dados como Snowflake e BigQuery)
Particionar e agrupar tabelas grandes em bancos de dados como Snowflake ou BigQuery ajuda a melhorar o desempenho das consultas, organizando os dados de forma eficiente e reduzindo a quantidade de dados verificados durante as consultas.
A partição garante que só as partes relevantes de um conjunto de dados sejam consultadas, enquanto o agrupamento otimiza o layout físico dos dados para uma recuperação mais rápida.
3. Otimize materializações (tabela, visualização, incremental)
Use materializações adequadas para otimizar o desempenho:
4. Use LIMIT durante o desenvolvimento
Ao desenvolver transformações, adicionar uma cláusula “ LIMIT ” às consultas é útil para limitar o número de linhas processadas. Isso acelera os ciclos de desenvolvimento e evita trabalhar com conjuntos de dados enormes durante os testes.
5. Executar consultas em paralelo
Aproveite a capacidade do seu warehouse de fazer consultas em paralelo. Por exemplo, o dbt Nuvem suporta paralelismo, que pode ser ajustado com base na sua infraestrutura.
6. Use recursos de otimização específicos do banco de dados
Muitos warehouse em nuvem oferecem recursos de otimização de desempenho, como:
Pra otimizar as execuções do dbt no Snowflake:
1. Use agrupamento de tabelas:
{{ config(
cluster_by = ["date_column", "category_column"]
) }}
SELECT ...2. Aproveite os warehouses multicluster do Snowflake para a execução paralela de modelos:
models:
my_project:
materialized: table
snowflake_warehouse: transforming_wh3. Use modelos incrementais quando for o caso:
{{ config(materialized='incremental', unique_key='id') }}
SELECT *
FROM source_table
{% if is_incremental() %}
WHERE updated_at > (SELECT MAX(updated_at) FROM {{ this }})
{% endif %}Essas otimizações podem melhorar o desempenho e a relação custo-benefício das execuções do dbt no Snowflake.
No final do processo de entrevista, os entrevistadores geralmente testam suas habilidades de resolução de problemas. Eles podem fazer perguntas para ver como você reage a situações da vida real. Então, aqui vão algumas perguntas sobre comportamento e resolução de problemas:
Veja como você pode gerenciar a implantação do dbt em diferentes ambientes:
1. Configurações específicas do ambiente
O dbt permite que você defina diferentes configurações para cada ambiente (desenvolvimento, teste e produção) no arquivo dbt_project.yml. Você pode definir configurações diferentes para coisas como esquema, banco de dados e configurações de data warehouse.
Exemplo em dbt_project.yml:
models:
my_project:
dev:
schema: dev_schema
staging:
schema: staging_schema
prod:
schema: prod_schemaNeste exemplo, o dbt escolhe automaticamente o esquema certo com base no ambiente de destino (dev, staging ou prod) ao rodar o projeto.
2. Usando a variável-alvo
A variável ` target ` no dbt é usada pra definir em qual ambiente você tá trabalhando (dev, staging, produção). Você pode usar essa variável nos seus modelos ou macros pra personalizar o comportamento de acordo com o ambiente.
Exemplo em um modelo:
{% if target.name == 'prod' %}
SELECT * FROM production_table
{% else %}
SELECT * FROM {{ ref('staging_table') }}
{% endif %}Essa lógica garante que diferentes tabelas ou esquemas sejam usados dependendo do ambiente.
3. Controle de ramificação e versão
Cada ambiente deve ter seu próprio ramo no controle de versão (por exemplo, Git). Os desenvolvedores trabalhamnok no ramo dev, os testadores e analistas usam o staging e só as alterações aprovadas são mescladas no ramo prod.
4. Integração contínua (CI) e implantação contínua (CD)
Na produção, é importante ter um pipeline de implantação automatizado que execute testes e validações antes de implantar modelos. No dbt Nuvem, você pode configurar agendas de tarefas para executar tarefas específicas com base no ambiente. Para o dbt Core, isso pode ser feito com ferramentas de CI/CD, como GitHub Actions ou Jenkins.
O controle de versão é essencial quando se trabalha em projetos dbt, especialmente em um ambiente de equipe onde várias pessoas contribuem para a mesma base de código. Veja como eu lido com o controle de versão no dbt:
1. Use o Git para controlar as versões
Usamos o Git como a principal ferramenta de controle de versão nos nossos projetos dbt. Cada membro da equipe trabalha em seu próprio ramo para quaisquer alterações ou recursos que esteja implementando. Isso permite um desenvolvimento isolado e evita conflitos entre os membros da equipe que estão trabalhando em tarefas diferentes ao mesmo tempo.
Exemplo: Eu crio um novo branch de recurso como feature/customer_order_transformation quando estou trabalhando em um novo modelo dbt.
2. Estratégia de ramificação
A gente segue uma estratégia de ramificação Git onde:
dev ” é usada para desenvolvimento e testes contínuos.staging ” é usado pra preparar as mudanças pra produção.main ou prodé reservado para o ambiente de produção.Os membros da equipe enviam suas alterações para o branch dev e abrem pull requests (PRs) para revisões de código. Depois que as mudanças forem revisadas e aprovadas, elas serão mescladas em staging para mais testes e, em seguida, promovidas para production.
3. Integração contínua (CI)
Integramos um pipeline de CI (por exemplo, GitHub Actions, CircleCI) que executa automaticamente testes dbt em cada solicitação pull. Isso garante que qualquer código novo passe nos testes necessários antes de ser incorporado ao ramo principal.
O processo de CI usa o dbt run para criar modelos e o dbt test para validar os dados e verificar se há erros ou inconsistências.
4. Resolva os conflitos de mesclagem
Quando vários membros da equipe fazem alterações no mesmo modelo ou arquivo, podem ocorrer conflitos de mesclagem. Para resolver isso, primeiro eu vejo os marcadores de conflito no código e decido quais alterações manter:
Depois de resolver o conflito, eu faço testes localmente para ter certeza de que a resolução do conflito não trouxe nenhum erro novo. Depois de confirmar, eu coloco as alterações resolvidas de volta no branch.
5. Documentação e colaboração
A gente garante que cada solicitação de mesclagem ou pull inclua a documentação adequada das alterações feitas. A gente atualiza a documentação gerada automaticamente pelo dbt pra que todo mundo da equipe entenda bem os modelos novos ou atualizados.
Veja como eu implementaria o dbt em um pipeline já existente:
Quando você vê um erro “relação não existe” no dbt, geralmente quer dizer que o modelo está tentando referenciar uma tabela ou modelo que ainda não foi criado ou está com um erro de digitação. Veja como eu faria a depuração:
ref() ` e se a tabela ou o modelo correto está sendo referenciado.SELECT * FROM {{ ref('orders') }} -- Ensure 'orders' is the correct model namedbt debug e dê uma olhada nos registros pra ver informações detalhadas sobre o que o dbt tentou fazer e por que deu errado.dbt run --models orders) para ver se eles existem e estão construídos corretamente antes do modelo com falha.O dbt é uma nova estrutura que está melhorando aos poucos. Pode ser meio complicado acompanhar as novas atualizações enquanto ainda tá aprendendo o material antigo. É por isso que você deve adotar uma abordagem equilibrada e começar com os recursos essenciais. Depois de dominá-los, dá uma olhada nas novidades pra entender o que mudou.
Sei que as entrevistas podem ser estressantes, principalmente para uma ferramenta especializada como o dbt. Mas não se preocupe — eu reuni algumas dicas para ajudá-lo a se preparar e se sentir confiante:
Não consigo enfatizar isso o suficiente — familiarize-se com os conceitos básicos do dbt, incluindo modelos, testes, documentação e como tudo isso se encaixa. Entender bem esses conceitos básicos vai te ajudar bastante nas conversas técnicas.
O DataCamp tem o curso perfeito pra isso: Introdução ao dbt
O DataCamp também tem uns cursos bem legais para quem tá começando, que falam sobre outros assuntos de engenharia de dados:
Ler sobre algo é bom, mas fazer é ainda melhor. Essa é uma das maneiras mais eficazes de dominar as habilidades de TDC. Você pode encontrar uma lista enorme de conjuntos de dados brutos online para fazer transformações e executar testes. Crie seu próprio projeto dbt e experimente os diferentes recursos. Isso vai fazer você se sentir muito mais confiante pra falar sobre o dbt quando você realmente tiver usado.
Os entrevistadores adoram ouvir sobre aplicações práticas. Você consegue pensar em algum problema que resolveu usando o dbt ou em como poderia usá-lo em um cenário hipotético? Tenha alguns desses exemplos prontos para compartilhar. Para reunir alguns exemplos, você pode até mesmo estudar vários estudos de caso no site oficial do dbt ou obter ideias de projetos públicos do dbt no Git.
A gente falou sobre várias perguntas básicas e avançadas de entrevistas sobre DBT que vão te ajudar na sua busca por um emprego. Ao entender como integrar o dbt com warehouse em nuvem, você vai ficar bem preparado com habilidades avançadas de transformação de dados, que são o ponto principal de qualquer processo de integração de dados.
Mas, aprender DBT e SQL é tipo a mesma coisa. Então, se você é novo no SQL, dá uma olhada nos cursos de SQL do DataCamp.
Aprenda mais sobre engenharia de dados com esses cursos!
Programa
Curso
Curso
blog
Javier Canales Luna
15 min
blog
Javier Canales Luna
15 min
blog
Chloe Lubin
15 min
blog
Austin Chia
15 min
blog
Tim Lu
9 min

