
Cursus
Ingénieur professionnel en données en Python
40 h
Le dbt (data build tool) est devenu un cadre de développement largement utilisé dans les flux de travail modernes d'ingénierie et d'analyse des données. Les analystes de données dépendent principalement des ingénieurs de données pour écrire les transformations en SQL. Cependant, avec dbt, ils peuvent écrire des transformations et exercer un plus grand contrôle sur les données. Il permet également l'intégration avec des systèmes de contrôle de version populaires tels que Git, ce qui améliore la collaboration au sein de l'équipe.
Si vous vous préparez à occuper un poste dans le domaine des entrepôts de données, tel que celui d'ingénieur de données, d'analyste de données ou de scientifique de données, il est important de bien maîtriser les questions dbt de base et avancées.
Dans cet article, j'ai présenté les questions les plus fréquemment posées lors des entretiens afin de vous aider à acquérir les concepts de base et les compétences avancées en matière de résolution de problèmes.
dbt est un framework open source de transformation de données qui permet de transformer des données, de tester leur exactitude et de suivre les modifications au sein d'une seule et même plateforme. Contrairement à d'autres outils ETL (extraction, transformation, chargement), dbt ne s'occupe que de la partie transformation (le T).
D'autres outils ETL extraient les données de diverses sources, les transforment en dehors de l'entrepôt, puis les rechargent. Cela nécessite souvent des connaissances spécialisées en codage et des outils supplémentaires. Cependant, dbt simplifie ce processus : il permet d'effectuer des transformations dans l'entrepôt en utilisant uniquement SQL.
Plus de 40 000 grandes entreprises utilisent dbt pour rationaliser leurs données. Les recruteurs le considèrent donc comme l'une des compétences les plus importantes pour les postes liés aux données. Par conséquent, si vous parvenez à le maîtriser, même en tant que débutant dans le domaine des données, cela pourrait vous ouvrir de nombreuses opportunités professionnelles.
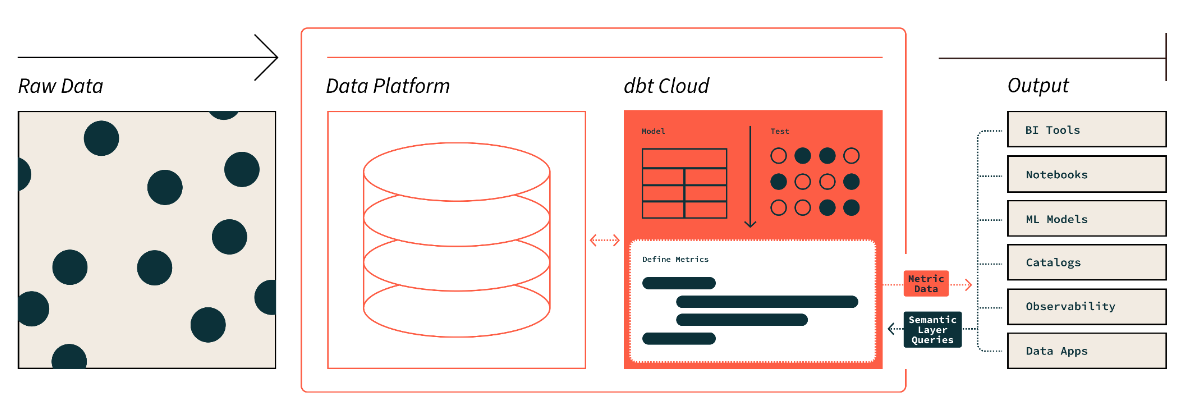
La couche sémantique dbt. Source de l'image : dbt
L'intervieweur évaluera vos connaissances de base au début du processus d'entretien. Pour cela, ils pourraient vous poser des questions fondamentales telles que celles-ci :
dbt rassemble une équipe de données sur une seule page, où elle peut transformer, documenter et tester ses données. Cela contribue à garantir la fiabilité et la clarté des données. Les utilisations courantes de dbt comprennent :
Non, dbt n'est pas un langage de programmation. Il s'agit d'un outil qui facilite les tâches de transformation des données dans l'entrepôt. Si vous maîtrisez le langage SQL, vous pouvez facilement utiliser dbt. Il a également commencé à prendre en charge Python pour des tâches spécifiques. Cependant, à la base, il gère et exécute des transformations basées sur SQL.
dbt et Spark ont des objectifs différents et ciblent différents types de flux de travail. Voici une comparaison de leur rôle dans l'infrastructure des données :
|
Caractéristique |
dbt |
Spark |
|
Rôle |
Transformations et modélisation de données basées sur SQL |
Traitement et analyse distribués des données |
|
Langage de base |
SQL en priorité, avec une prise en charge limitée de Python |
Supports SQL, Python, Scala, Java, R |
|
Gouvernance des données |
Documentation et assistance à la filiation |
Fournit un contrôle d'accès, un audit et une traçabilité des données. |
|
Utilisateurs cibles |
Utilisateurs SQL, analystes et équipes sans compétences en ingénierie |
Ingénieurs de données, scientifiques de données, développeurs |
|
Complexité de la transformation |
Se concentre uniquement sur les transformations SQL et la modélisation. |
Peut également gérer des transformations complexes dans d'autres langues. |
|
Test et validation |
Dispose de capacités de test intégrées |
Il est nécessaire de mettre en place des stratégies de test personnalisées (unitaires et d'intégration). |
Bien que le DBT apporte une grande valeur ajoutée aux équipes chargées des données, il peut également présenter certains défis, en particulier lorsque l'échelle et la complexité augmentent. Par conséquent, voici quelques-uns des défis les plus courants :
Les employeurs recherchent des candidats capables de surmonter les défis potentiels mentionnés ci-dessus, il est donc important de ne pas négliger l'importance de cette question.
Il existe deux versions principales de dbt :
dbt Core est la version gratuite et open source de dbt qui permet aux utilisateurs de rédiger, d'exécuter et de gérer localement des transformations basées sur SQL. Il fournit une interface de ligne de commande (CLI) pour exécuter des projets dbt, tester des modèles et créer des pipelines de données. Étant donné qu'il s'agit d'un logiciel libre, dbt Core exige que les utilisateurs gèrent eux-mêmes le déploiement, l'orchestration et la configuration de l'infrastructure, généralement dans un environnement d'automatisation tel qu'Airflow ou Kubernetes.
, quant à lui, est un service cloud géré fourni par les créateurs de dbt (Fishtown Analytics). Il offre toutes les fonctionnalités de dbt Core, ainsi que des fonctionnalités supplémentaires telles qu'une interface Web, une planification intégrée, une gestion des tâches et des outils de collaboration. dbt Cloud comprend également des fonctionnalités CI/CD (intégration et déploiement continus) intégrées, un accès API et une conformité de sécurité renforcée, telle que SOC 2 et HIPAA, pour les organisations ayant des besoins de sécurité plus rigoureux.
Maintenant que nous avons abordé les questions de base sur le dbt, voici quelques questions de niveau intermédiaire sur le dbt. Ces derniers se concentrent sur des aspects techniques et des concepts spécifiques.
Dans dbt, les sources sont les tableaux de données brutes. Nous n'écrivons pas directement de requêtes SQL sur ces tableaux bruts — nous spécifions le schéma et le nom de la table et les définissons comme sources. Cela facilite la référence aux objets de données dans les tableaux.
Veuillez imaginer que vous disposez d'une table de données brutes dans votre base de données nommée « orders » dans le schéma « sales ». Au lieu d'interroger directement ce tableau, vous le définiriez comme source dans dbt de la manière suivante :
Veuillez définir la source dans votre fichier sources.yml:
version: 2
sources:
- name: sales
tables:
- name: ordersVeuillez utiliser la source dans vos modèles dbt :
Une fois définie, vous pouvez vous référer au tableau d' orders s brutes dans vos transformations comme suit :
SELECT *
FROM {{ source('sales', 'orders') }}Cette approche permet d'abstraire la définition brute du tableau, ce qui facilite sa gestion et garantit que, si la structure sous-jacente du tableau change, vous pouvez le mettre à jour à un seul endroit (la définition source) plutôt que dans chaque requête.
Avantages de l'utilisation de sources dans dbt :
Un modèle DBT est essentiellement un fichier SQL ou Python qui définit la logique de transformation des données brutes. Dans dbt, les modèles constituent l'élément central dans lequel vous écrivez vos transformations, qu'il s'agisse d'agrégations, de jointures ou de tout autre type de manipulation de données.
SELECT ation pour définir les transformations et sont enregistrés sous forme de fichiers .sql..py et permettent d'utiliser des bibliothèques Python telles que pandas pour manipuler les données.Exemple de modèle SQL :
Un modèle SQL transforme les données brutes à l'aide de requêtes SQL. Par exemple, pour créer un résumé des commandes à partir d'un tableau d' orders s :
--orders_summary.sql
WITH orders_cte AS (
SELECT
customer_id,
COUNT(order_id) AS total_orders,
SUM(order_amount) AS total_revenue
FROM {{ ref('orders') }}
GROUP BY customer_id
)
SELECT *
FROM orders_cteDans cet exemple :
orders_summary.sql génère un récapitulatif du total des commandes et du chiffre d'affaires pour chaque client à l'aide de SQL.orders (déjà définie comme modèle ou source dbt).Exemple de modèle Python :
Un modèle Python traite les données brutes à l'aide de code Python. Cela peut être particulièrement utile pour les logiques complexes qui pourraient s'avérer fastidieuses en SQL.
# orders_summary.py
import pandas as pd
def model(dbt, session):
# Load the source data
orders = dbt.ref("orders").to_pandas()
# Perform transformations using pandas
orders_summary = orders.groupby('customer_id').agg(
total_orders=('order_id', 'count'),
total_revenue=('order_amount', 'sum')
).reset_index()
return orders_summaryDans cet exemple :
Voici comment créer un modèle dbt :
models du projet dbt. .sql dans le répertoire (ou .py s'il s'agit d'un modèle Python).dbt run pour appliquer la transformation et créer le modèle.dbt gère les dépendances entre les modèles à l'aide de la fonction « ref() », qui établit une chaîne de dépendances claire entre les modèles.
Lorsque vous définissez une transformation dans dbt, plutôt que de référencer directement les tableaux de votre entrepôt, vous référencez d'autres modèles dbt à l'aide de la fonction ref(). Cela garantit que dbt construit les modèles dans le bon ordre en identifiant ceux qui dépendent les uns des autres.
Par exemple, si vous disposez d'un modèle orders_summary qui dépend du modèle orders, vous le définiriez comme suit :
WITH orders AS (
SELECT * FROM {{ ref('orders') }}
)
SELECT
customer_id,
COUNT(order_id) AS total_orders,
SUM(order_amount) AS total_revenue
FROM orders
GROUP BY customer_idDans cet exemple, la fonction ` {{ ref('orders') }} ` garantit que le modèle ` orders ` est construit avant ` orders_summary`, car ` orders_summary ` dépend des donnéesdu modèle ` orders ` .
Les macros dans dbt sont des blocs réutilisables de code SQL écrits à l'aide du moteur de modèles Jinja. Ils vous permettent d'automatiser les tâches répétitives, d'abstraire la logique complexe et de réutiliser le code SQL dans plusieurs modèles, rendant ainsi votre projet dbt plus efficace et plus facile à maintenir.
Les macros peuvent être définies dans les fichiers .sql situés dans le répertoire macros de votre projet dbt.
Les macros sont particulièrement utiles lorsque vous devez effectuer des transformations similaires sur plusieurs modèles ou que vous avez besoin d'une logique spécifique à l'environnement, comme l'utilisation de schémas différents ou la modification des formats de date en fonction des environnements de déploiement (par exemple, développement, mise en scène ou production).
Exemple de création de macros :
-- macros/date_format.sql
{% macro format_date(column) %}
FORMAT_TIMESTAMP('%Y-%m-%d', {{ column }})
{% endmacro %}Utilisation dans un modèle :
SELECT
customer_id,
{{ format_date('order_date') }} AS formatted_order_date
FROM {{ ref('orders') }}Dans cet exemple, la macro ` format_date ` est utilisée pour normaliser le format de la colonne ` order_date ` dans tout modèle où elle est appelée.
-- macros/custom_schema.sql
{% macro custom_schema_name() %}
{% if target.name == 'prod' %}
'production_schema'
{% else %}
'dev_schema'
{% endif %}
{% endmacro %}Utilisation dans un modèle :
SELECT *
FROM {{ custom_schema_name() }}.ordersIci, la macro vérifie si l'environnement (target.name) est « prod » et renvoie le nom de schéma approprié en fonction de cela.
Comment exécuter des macros :
Les macros ne sont pas exécutées directement comme les modèles SQL. Ils sont plutôt référencés dans vos modèles ou autres macros et exécutés lorsque le projet dbt est lancé. Par exemple, si vous utilisez une macro dans un modèle, celle-ci s'exécutera lorsque vous lancerez la commande « dbt run ».
dbt run-operation. Ceci est généralement utilisé pour des tâches ponctuelles, telles que l'initialisation de données ou la réalisation d'opérations de maintenance.Les tests singuliers et les tests génériques sont les deux types de tests disponibles dans dbt :
Exemple : Supposons que vous souhaitiez vous assurer qu'aucune commande ne présente un order_amount négatif. Vous pouvez créer un test unique dans le répertoire tests comme suit :
-- tests/no_negative_order_amount.sql
SELECT *
FROM {{ ref('orders') }}
WHERE order_amount < 0Si ce test échoue, dbt renverra toutes les lignes de la table orders où l' order_amount est négatif.
|
Tests génériques |
Définition |
|
Unique |
Vérifie si les valeurs de la colonne sont uniques. |
|
Non nul |
Vérifie s'il y a des champs vides. |
|
Valeurs disponibles |
Vérifie que les valeurs des colonnes correspondent à une liste de valeurs attendues afin de maintenir la normalisation. |
|
Relations |
Vérifie l'intégrité référentielle entre les tableaux afin d'éliminer toute donnée incohérente. |
Exemple : Vous pouvez facilement appliquer un test générique pour vous assurer que customer_id dans le tableau customers est unique et non nul en le définissant dans votre fichier schema.yml:
version: 2
models:
- name: customers
columns:
- name: customer_id
tests:
- unique
- not_nullDans cet exemple :
customer_id Ce test unique vérifie que chaque entrée du tableau customers est unique.customer_id s n'est manquante ou nulle.Au fur et à mesure de votre progression, vous pourriez rencontrer des scénarios plus complexes et des concepts avancés. Voici donc quelques questions d'entretien complexes qui vous aideront à évaluer votre expertise et à vous préparer à des postes de haut niveau dans le domaine de l'ingénierie des données.
Les modèles incrémentiels dans dbt sont utilisés pour traiter uniquement les données nouvelles ou modifiées, au lieu de retraiter l'ensemble des données à chaque fois. Cela s'avère particulièrement utile lorsque l'on travaille avec des ensembles de données volumineux, pour lesquels la reconstruction complète du modèle à partir de zéro serait chronophage et nécessiterait d'importantes ressources.
Un modèle incrémentiel permet à dbt d'ajouter uniquement les nouvelles données (ou de mettre à jour les données modifiées) en fonction d'une condition, généralement une colonne d'horodatage (comme updated_at).
Comment créer un modèle incrémental :
1. Définissez le modèle comme incrémental en le spécifiant dans la configuration du modèle :
{{ config(
materialized='incremental',
unique_key='id' -- or another unique column
) }}2. Veuillez utiliser la fonction is_incremental() pour filtrer les lignes nouvelles ou modifiées :
SELECT *
FROM source_table
{% if is_incremental() %}
WHERE updated_at > (SELECT MAX(updated_at) FROM {{ this }})
{% endif %}3. Lorsque dbt exécute ce modèle pour la première fois, il traite l'ensemble des données. Pour les exécutions suivantes, il ne traitera que les lignes où l' updated_at est supérieure à la valeur la plus récente déjà présente dans le modèle.
Quand utiliser les modèles incrémentiels :
Jinja rend notre code SQL plus flexible. Avec Jinja, nous pouvons définir des modèles réutilisables pour les schémas SQL courants. Et comme les exigences changent constamment, nous pouvons utiliser les instructions Jinja if pour ajuster nos requêtes SQL en fonction des conditions. Cela permet généralement d'améliorer le code SQL en décomposant la logique complexe, ce qui le rend plus facile à comprendre.
Par exemple, si vous souhaitez convertir le format de date « AAAA-MM-JJ » en « MM/JJ/AAAA », voici un exemple de macro dbt pour cela, que nous avons vu dans une question précédente :
{% macro change_date_format(column_name) %}
to_char({{ column_name }}::date, 'MM/DD/YYYY')
{% endmacro %}Dans cet exemple de code, {{ column_name }} est l'endroit où Jinja insère le nom réel de la colonne lorsque vous utilisez la macro. Il sera remplacé par le nom réel de la colonne lors de l'exécution. Comme nous l'avons observé dans les exemples précédents, Jinja utilise l'{{ }} e pour indiquer où le remplacement aura lieu.
Voici comment créer une matérialisation personnalisée dans dbt :
materialization_name: {% materialization materialization_name, default -%}adapter.get_relation pour configurer la table cible. C'est ici que les données seront chargées. {% set sql %}
SELECT * FROM {{ ref('your_source_table') }}
WHERE your_conditions = true
{% endset %}
{{ adapter.execute(sql) }}{{ return(target_relation) }}
{% endmaterialization %}Voici deux méthodes pour déboguer nos modèles dbt :
1. Veuillez accéder aux fichiers SQL compilés dans le dossier cible afin d'identifier et de suivre les erreurs.
Lorsque vous exécutez un projet dbt, dbt compile vos modèles (rédigés à l'aide du système de modèles Jinja) en requêtes SQL brutes et les enregistre dans le répertoire target. Ce SQL compilé correspond exactement à ce que dbt exécute sur votre plateforme de données. Par conséquent, l'examen de ces fichiers peut vous aider à identifier les sources des problèmes :
dbt run ou dbt test).target/compiled/ » de votre répertoire de projet dbt.2. Veuillez utiliserl'extension dbt Power User Extension pour VS Code d' afin d'examiner directement les résultats des requêtes.
L'extension dbt Power User pour Visual Studio Code (VS Code) est un outil utile pour le débogage des modèles dbt. Cette extension vous permet de réviser et de tester vos requêtes directement dans votre IDE, ce qui réduit le besoin de basculer entre dbt, le terminal et votre base de données.
dbt compile les requêtes en suivant les étapes suivantes :
target/compiled.dbt run, les requêtes sont préparées pour exécution, éventuellement avec un encapsulage supplémentaire.Ce processus transforme le SQL modulaire et basé sur des modèles en requêtes exécutables spécifiques à votre entrepôt de données. Nous pouvons utiliser dbt compile ou consulter le répertoire target/compiled pour visualiser et déboguer le SQL final pour chaque modèle.
La plupart des ingénieurs de données ont pour mission de créer et d'intégrer des entrepôts de données avec dbt. Les questions relatives à ces scénarios sont fréquentes lors des entretiens. C'est pourquoi j'ai compilé les questions les plus courantes :
L'intégration de dbt à Airflow contribue à la création d'un pipeline de données rationalisé. Voici quelques-uns de ses avantages :
La couche sémantique de dbt nous permet de traduire les données brutes dans un langage que nous comprenons. Nous pouvons également définir des métriques et les interroger à l'aide d'une interface de ligne de commande (CLI).
Cela nous permet d'optimiser les coûts, car la préparation des données prend moins de temps. De plus, tous les collaborateurs utilisent les mêmes définitions de données, ce qui garantit la cohérence des indicateurs à l'échelle de l'organisation.
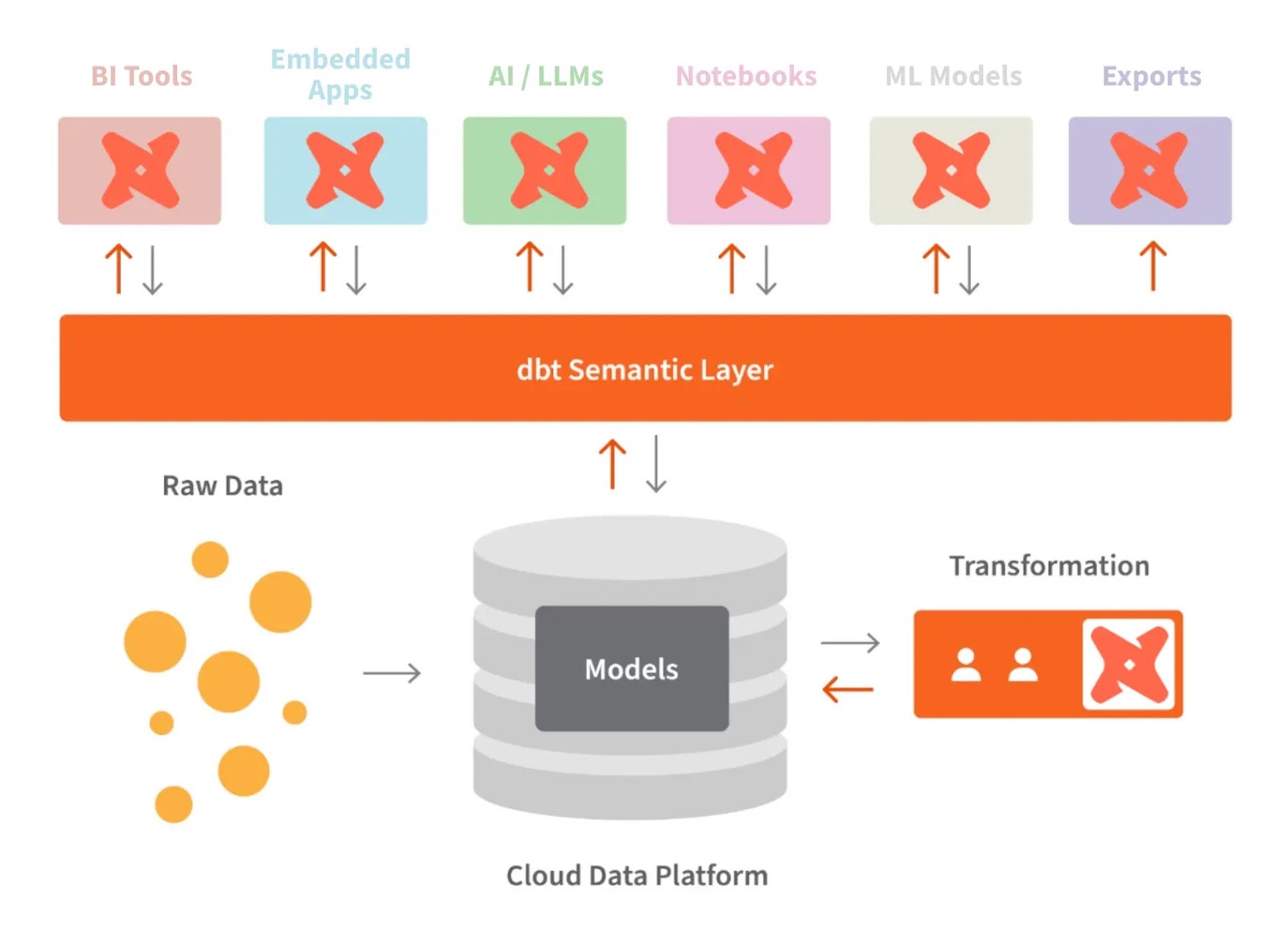
dbt et la couche sémantique. Source de l'image : dbt
Bien que BigQuery soit très utile et puisse gérer de nombreuses transformations de manière native, dbt peut encore s'avérer nécessaire. Voici pourquoi :
ref() permettent d'obtenir un code SQL plus modulaire et réutilisable.Comme indiqué dans une question précédente, dbt existe en deux versions : dbt Core et dbt Cloud. dbt Core est open source et constitue la version gratuite. C'est pourquoi il ne propose aucune fonctionnalité de sécurité intégrée, et les utilisateurs sont responsables de son déploiement et de sa sécurité.
Cependant, dbt Cloud est conçu pour offrir une sécurité totale. Il est conforme à la loi HIPAA et à d'autres cadres réglementaires courants afin de garantir la protection de la vie privée. Par conséquent, en fonction de nos besoins, il est nécessaire de sélectionner une version de DBT qui répond aux exigences de conformité de notre entreprise.
L'optimisation des transformations dbt pour les grands ensembles de données est essentielle pour améliorer les performances et réduire les coûts, en particulier lorsqu'il s'agit d'entrepôts de données basés sur le cloud tels que Snowflake, BigQuery ou Redshift. Voici quelques techniques clés pour optimiser les performances de dbt :
1. Utiliser des modèles incrémentiels
Les modèles incrémentiels permettent à dbt de traiter uniquement les données nouvelles ou mises à jour, au lieu de retraiter l'ensemble des données à chaque fois. Cela peut réduire considérablement les temps d'exécution pour les grands ensembles de données. Ce processus limite la quantité de données traitées, ce qui accélère les temps de transformation.
2. Tirez parti du partitionnement et du clustering (pour les bases de données telles que Snowflake et BigQuery).
Le partitionnement et le regroupement des grands tableaux dans des bases de données telles que Snowflake ou BigQuery contribuent à améliorer les performances des requêtes en organisant efficacement les données et en réduisant la quantité de données analysées lors des requêtes.
Le partitionnement garantit que seules les parties pertinentes d'un ensemble de données sont interrogées, tandis que le regroupement optimise la disposition physique des données pour une récupération plus rapide.
3. Optimiser les matérialisations (tableau, vue, incrémentielle)
Veuillez utiliser les matérialisations appropriées pour optimiser les performances :
4. Veuillez utiliser LIMIT pendant le développement.
Lors du développement de transformations, il est utile d'ajouter une clause d'LIMIT e aux requêtes afin de limiter le nombre de lignes traitées. Cela accélère les cycles de développement et évite de devoir manipuler des ensembles de données volumineux pendant les tests.
5. Exécutez des requêtes en parallèle
Tirez parti de la capacité de votre entrepôt de données à exécuter des requêtes en parallèle. Par exemple, dbt Cloud prend en charge le parallélisme, qui peut être ajusté en fonction de votre infrastructure.
6. Utiliser les fonctionnalités d'optimisation spécifiques à la base de données
De nombreux entrepôts de données dans le cloud offrent des fonctionnalités d'optimisation des performances telles que :
Pour optimiser les exécutions dbt dans Snowflake :
1. Veuillez utiliser le regroupement de tables :
{{ config(
cluster_by = ["date_column", "category_column"]
) }}
SELECT ...2. Tirez parti des entrepôts multi-clusters de Snowflake pour l'exécution parallèle de modèles :
models:
my_project:
materialized: table
snowflake_warehouse: transforming_wh3. Utilisez des modèles incrémentiels lorsque cela est approprié :
{{ config(materialized='incremental', unique_key='id') }}
SELECT *
FROM source_table
{% if is_incremental() %}
WHERE updated_at > (SELECT MAX(updated_at) FROM {{ this }})
{% endif %}Ces optimisations peuvent améliorer les performances et la rentabilité des exécutions dbt dans Snowflake.
À la fin du processus d'entretien, les recruteurs évaluent généralement vos capacités à résoudre des problèmes. Ils pourraient vous poser des questions afin d'évaluer votre réaction face à des situations réelles. Voici donc quelques questions relatives au comportement et à la résolution de problèmes :
Voici comment vous pouvez gérer le déploiement dbt dans différents environnements :
1. Configurations spécifiques à l'environnement
dbt vous permet de définir différentes configurations pour chaque environnement (développement, préproduction et production) dans le fichier dbt_project.yml. Vous pouvez définir différents paramètres pour des éléments tels que les configurations de schéma, de base de données et d'entrepôt de données.
Exemple dans l'dbt_project.yml:
models:
my_project:
dev:
schema: dev_schema
staging:
schema: staging_schema
prod:
schema: prod_schemaDans cet exemple, dbt sélectionne automatiquement le schéma approprié en fonction de l'environnement cible (développement, préproduction ou production) lors de l'exécution du projet.
2. Utilisation de la variable cible
La variable target dans dbt est utilisée pour définir l'environnement dans lequel vous travaillez (développement, préproduction, production). Vous pouvez référencer cette variable dans vos modèles ou macros afin de personnaliser le comportement en fonction de l'environnement.
Exemple dans un modèle :
{% if target.name == 'prod' %}
SELECT * FROM production_table
{% else %}
SELECT * FROM {{ ref('staging_table') }}
{% endif %}Cette logique garantit que différentes tables ou différents schémas sont utilisés en fonction de l'environnement.
3. Contrôle des branches et des versions
Chaque environnement devrait disposer de sa propre branche dans le contrôle de version (par exemple, Git). Les développeurs travaillentsurk dans la branche dev, les testeurs et les analystes utilisent staging, et seules les modifications approuvées sont fusionnées dans la branche prod.
4. Intégration continue (CI) et déploiement continu (CD)
En production, il est essentiel de disposer d'un pipeline de déploiement automatisé qui exécute des tests et des validations avant de déployer les modèles. Dans dbt Cloud, il est possible de configurer des calendriers de tâches pour exécuter des tâches spécifiques en fonction de l'environnement. Pour dbt Core, cela peut être réalisé à l'aide d'outils CI/CD tels que GitHub Actions ou Jenkins.
Le contrôle de version est essentiel lorsque l'on travaille sur des projets dbt, en particulier dans un environnement d'équipe où plusieurs personnes contribuent à la même base de code. Voici comment je gère le contrôle de version dans dbt :
1. Veuillez utiliser Git pour le contrôle de version.
Nous utilisons Git comme outil principal pour le contrôle de version dans nos projets dbt. Chaque membre de l'équipe travaille sur sa propre branche pour toutes les modifications ou fonctionnalités qu'il met en œuvre. Cela permet un développement isolé et évite les conflits entre les membres de l'équipe travaillant simultanément sur différentes tâches.
Exemple : Lorsque je travaille sur un nouveau modèle dbt, je crée une nouvelle branche de fonctionnalité telle que feature/customer_order_transformation.
2. Stratégie de ramification
Nous suivons une stratégie de branchement Git dans laquelle :
dev est utilisée pour le développement et les tests en cours.staging est utilisée pour préparer les modifications destinées à la production.main ou prodest réservée à l'environnement de production.Les membres de l'équipe transmettent leurs modifications à la branche d'dev s et ouvrent des demandes d'extraction (PR) pour les révisions de code. Une fois les modifications examinées et approuvées, elles sont fusionnées dans staging pour être testées plus avant, puis transférées vers production.
3. Intégration continue (CI)
Nous avons intégré un pipeline CI (par exemple, GitHub Actions, CircleCI) qui exécute automatiquement des tests dbt sur chaque pull request. Cela garantit que tout nouveau code passe les tests requis avant d'être fusionné dans la branche principale.
Le processus CI exécute dbt run pour créer des modèles et dbt test pour valider les données et vérifier s'il existe des erreurs ou des incohérences.
4. Résoudre les conflits de fusion
Lorsque plusieurs membres d'une équipe apportent des modifications au même modèle ou fichier, des conflits de fusion peuvent survenir. Pour y parvenir, j'examine d'abord les marqueurs de conflit dans le code et je détermine les modifications à conserver :
Après avoir résolu le conflit, je procède à des tests en local afin de m'assurer que la résolution du conflit n'a pas introduit de nouvelles erreurs. Une fois confirmé, je renvoie les modifications résolues vers la branche.
5. Documentation et collaboration
Nous veillons à ce que chaque demande de fusion ou d'extraction comprenne une documentation adéquate des modifications apportées. Nous mettons à jour la documentation dbt générée automatiquement afin que tous les membres de l'équipe aient une compréhension claire des modèles nouveaux ou mis à jour.
Voici comment j'implémenterais dbt dans un pipeline existant :
Lorsque vous rencontrez une erreur « relation does not exist » dans dbt, cela signifie généralement que le modèle tente de référencer une table ou un modèle qui n'a pas été créé ou qui comporte une erreur orthographique. Voici comment je procéderais pour le déboguer :
ref(), et vérifiez que le modèle ou la table correct(e) est référencé(e).SELECT * FROM {{ ref('orders') }} -- Ensure 'orders' is the correct model namedbt debug ` et examiner les journaux pour obtenir des informations détaillées sur les actions que dbt a tenté d'effectuer et les raisons de l'échec.dbt run --models orders) afin de vérifier qu'ils existent et qu'ils sont correctement construits avant le modèle défaillant.dbt est un nouveau cadre qui s'améliore progressivement. Il peut être difficile de suivre les nouvelles mises à jour tout en continuant à apprendre l'ancienne matière. C'est pourquoi il est important d'adopter une approche équilibrée et de commencer par les fonctionnalités essentielles. Une fois que vous les maîtrisez, veuillez examiner les ajouts afin de comprendre ce qui a changé.
Je comprends que les entretiens puissent être stressants, en particulier pour un outil spécialisé tel que dbt. Cependant, ne vous inquiétez pas, j'ai rassemblé quelques conseils pour vous aider à vous préparer et à vous sentir en confiance :
Je ne saurais trop insister sur ce point : familiarisez-vous avec les concepts fondamentaux de DBT, notamment les modèles, les tests, la documentation et la manière dont ils s'articulent entre eux. Une bonne maîtrise de ces notions fondamentales vous sera très utile dans les discussions techniques.
DataCamp propose le cours idéal pour cela : Introduction à dbt
DataCamp propose également des cours adaptés aux débutants qui abordent en profondeur d'autres thèmes liés à l'ingénierie des données :
Il est utile de lire sur un sujet, mais il est encore plus efficace de le mettre en pratique. Il s'agit de l'une des méthodes les plus efficaces pour acquérir les compétences en matière de thérapie comportementale dialectique. Vous pouvez trouver une liste exhaustive de jeux de données brutes en ligne pour effectuer des transformations et exécuter des tests. Veuillez configurer votre propre projet dbt et explorer ses différentes fonctionnalités. Cela vous permettra de vous sentir beaucoup plus à l'aise pour discuter de la TCD lorsque vous l'aurez réellement utilisée.
Les recruteurs apprécient particulièrement les exemples concrets. Pourriez-vous citer un problème que vous avez résolu à l'aide de dbt ou expliquer comment vous pourriez l'utiliser dans un scénario hypothétique ? Veuillez préparer quelques exemples de ce type à partager. Pour recueillir quelques exemples, vous pouvez également étudier plusieurs études de cas sur le site officiel de dbt ou vous inspirer des projets dbt publics sur Git.
Nous avons abordé un large éventail de questions d'entretien DBT, des plus basiques aux plus avancées, qui vous aideront dans votre recherche d'emploi. En comprenant comment intégrer dbt aux entrepôts de données dans le cloud, vous acquerrez des compétences avancées en matière de transformation des données, qui sont au cœur de tout processus d'intégration des données.
Cependant, l'apprentissage du DBT et du SQL sont étroitement liés. Si vous débutez avec SQL, nous vous invitons à consulter les cours SQL de DataCamp.
Veuillez approfondir vos connaissances en ingénierie des données grâce à ces cours.
Cursus
Cours
Cours
blog
Nisha Arya Ahmed
15 min
blog
Kurtis Pykes
15 min
blog
Nathaniel Taylor-Leach
blog
Kurtis Pykes
9 min
Tutoriel
Samuel Shaibu
