
Programma
Ingegnere dei dati professionale in Python
40 h
dbt (data build tool) è diventato un framework di sviluppo ampiamente utilizzato nei moderni flussi di lavoro di data engineering e analytics. Di solito gli analisti dei dati si affidano ai data engineer per scrivere trasformazioni in SQL. Ma con dbt possono scrivere trasformazioni e avere un maggiore controllo sui dati. Permette anche l'integrazione con popolari sistemi di controllo versione come Git, migliorando la collaborazione del team.
Se ti stai preparando per un ruolo in un data warehouse, come data engineer, data analyst o data scientist, dovresti conoscere bene le domande su dbt, sia di base che avanzate!
In questo articolo ho raccolto le domande di colloquio più comuni per aiutarti a costruire i concetti di base e le capacità avanzate di problem-solving.
dbt è un framework open-source per la trasformazione dei dati che ti consente di trasformare i dati, testarli per verificarne l'accuratezza e tracciare le modifiche all'interno di un'unica piattaforma. A differenza di altri strumenti ETL (extract, transform, load), dbt si occupa solo della trasformazione (la T).
Altri strumenti ETL estraggono i dati da varie fonti, li trasformano fuori dal warehouse e poi li caricano di nuovo. Questo spesso richiede conoscenze specifiche di programmazione e strumenti aggiuntivi. Ma dbt semplifica il processo: consente di effettuare le trasformazioni direttamente nel warehouse usando solo SQL.
Più di 40.000 grandi aziende usano dbt per semplificare i dati — per questo i recruiter lo indicano come una delle competenze più importanti per i ruoli legati ai dati. Quindi, se lo padroneggi anche come principiante, potrebbe aprirti molte opportunità di carriera!
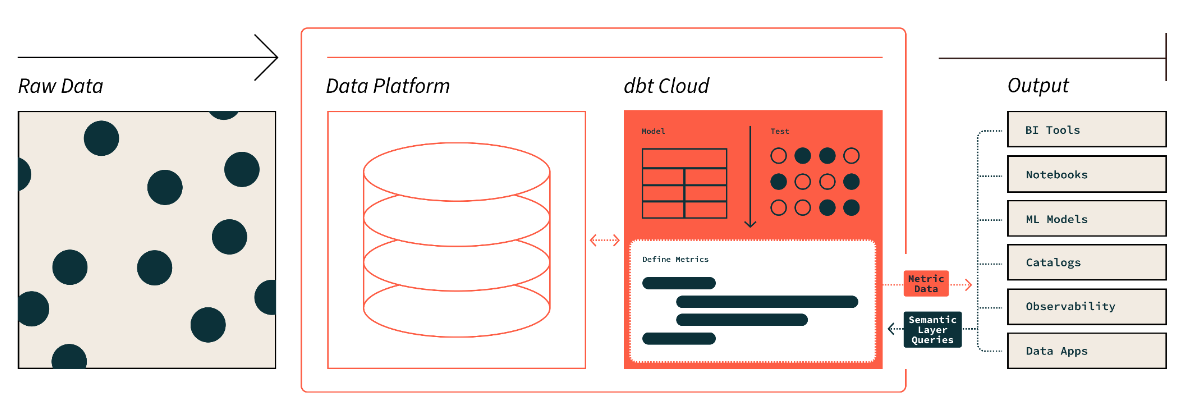
Il semantic layer di dbt. Fonte immagine: dbt
All'inizio del processo di colloquio ti verranno testate le conoscenze di base. A tal fine, potrebbero farti alcune domande fondamentali come queste:
dbt mette il team dati sulla stessa linea, dove può trasformare, documentare e testare i dati. Aiuta a garantire che i dati siano affidabili e facili da comprendere. Gli usi più comuni di dbt includono:
No, dbt non è un linguaggio di programmazione. È uno strumento che aiuta nei lavori di trasformazione dei dati nel warehouse. Se sai scrivere SQL, puoi lavorare facilmente con dbt. Ha anche iniziato a supportare Python per attività specifiche. Ma alla base gestisce ed esegue trasformazioni basate su SQL.
dbt e Spark hanno scopi diversi e mirano a flussi di lavoro differenti. Ecco un confronto del loro ruolo nell'infrastruttura dati:
|
Caratteristica |
dbt |
Spark |
|
Ruolo |
Trasformazioni e modellazione dei dati basate su SQL |
Elaborazione distribuita dei dati e analytics |
|
Linguaggio principale |
SQL al primo posto, con supporto limitato a Python |
Supporta SQL, Python, Scala, Java, R |
|
Data governance |
Documentazione e supporto alla lineage |
Fornisce controllo accessi, auditing e data lineage |
|
Utenti target |
Utenti SQL, analisti e team senza competenze ingegneristiche |
Data engineer, data scientist, sviluppatori |
|
Complessità delle trasformazioni |
Si concentra solo su trasformazioni e modellazione in SQL |
Può gestire trasformazioni complesse anche in altri linguaggi |
|
Testing e validazione |
Ha funzionalità di testing integrate |
Richiede strategie di test personalizzate (unit e integration) |
Sebbene dbt porti molto valore ai team dati, può presentare anche alcune sfide, soprattutto quando aumentano scala e complessità. Le più comuni sono:
Saper aggirare le potenziali sfide sopra è qualcosa che i datori di lavoro cercano, quindi non sottovalutare l'importanza di questa domanda.
Esistono due versioni principali di dbt:
dbt Core è la versione gratuita e open-source di dbt che permette agli utenti di scrivere, eseguire e gestire trasformazioni basate su SQL in locale. Fornisce una command-line interface (CLI) per eseguire progetti dbt, testare i modelli e costruire pipeline di dati. Essendo open-source, dbt Core richiede agli utenti di gestire autonomamente deployment, orchestrazione e setup dell'infrastruttura, di solito integrandosi con strumenti come Airflow o Kubernetes per l'automazione.
dbt Cloud, invece, è un servizio gestito fornito dai creatori di dbt (Fishtown Analytics). Offre tutte le funzionalità di dbt Core, insieme a caratteristiche aggiuntive come un'interfaccia web, schedulazione integrata, gestione dei job e strumenti di collaborazione. dbt Cloud include inoltre funzionalità CI/CD (continuous integration and deployment) integrate, accesso API e conformità di sicurezza avanzata come SOC 2 e HIPAA per le organizzazioni con esigenze di sicurezza più rigorose.
Ora che abbiamo coperto le domande di base su dbt, ecco alcune domande di livello intermedio. Si concentrano su aspetti e concetti tecnici specifici.
In dbt, le sources sono le tabelle di dati grezzi. Non scriviamo direttamente query SQL su quelle tabelle grezze — specifichiamo lo schema e il nome della tabella e le definiamo come sorgenti. Questo rende più semplice fare riferimento agli oggetti dati nelle tabelle.
Immagina di avere una tabella di dati grezzi nel tuo database chiamata orders nello schema sales. Invece di interrogare direttamente questa tabella, la definiresti come source in dbt così:
Definisci la sorgente nel tuo file sources.yml:
version: 2
sources:
- name: sales
tables:
- name: ordersUsa la source nei tuoi modelli dbt:
Una volta definita, puoi fare riferimento alla tabella grezza orders nelle tue trasformazioni così:
SELECT *
FROM {{ source('sales', 'orders') }}Questo approccio astrae la definizione della tabella grezza, facilitando la gestione e garantendo che, se la struttura sottostante cambia, tu possa aggiornarla in un solo punto (la definizione della source) invece che in ogni query.
Vantaggi dell'uso delle sources in dbt:
Un modello dbt è essenzialmente un file SQL o Python che definisce la logica di trasformazione dei dati grezzi. In dbt, i modelli sono il componente centrale in cui scrivi le trasformazioni, che si tratti di aggregazioni, join o qualsiasi tipo di manipolazione dei dati.
SELECT per definire le trasformazioni e sono salvati come file .sql..py e ti permettono di usare librerie Python come pandas per manipolare i dati.Esempio di modello SQL:
Un modello SQL trasforma i dati grezzi usando query SQL. Ad esempio, per creare un riepilogo degli ordini dalla tabella orders:
--orders_summary.sql
WITH orders_cte AS (
SELECT
customer_id,
COUNT(order_id) AS total_orders,
SUM(order_amount) AS total_revenue
FROM {{ ref('orders') }}
GROUP BY customer_id
)
SELECT *
FROM orders_cteIn questo esempio:
orders_summary.sql crea un riepilogo del numero totale di ordini e del fatturato per ciascun cliente usando SQL.orders (già definita come modello o source di dbt).Esempio di modello Python:
Un modello Python manipola i dati grezzi usando codice Python. Può essere particolarmente utile per logiche complesse che in SQL sarebbero macchinose.
# orders_summary.py
import pandas as pd
def model(dbt, session):
# Load the source data
orders = dbt.ref("orders").to_pandas()
# Perform transformations using pandas
orders_summary = orders.groupby('customer_id').agg(
total_orders=('order_id', 'count'),
total_revenue=('order_amount', 'sum')
).reset_index()
return orders_summaryIn questo esempio:
Ecco come creare un modello dbt:
models nel progetto dbt. .sql all'interno della directory (o .py se è un modello Python).dbt run per applicare la trasformazione e creare il modello.dbt gestisce le dipendenze tra modelli usando la funzione ref(), che crea una catena di dipendenze chiara tra i modelli.
Quando definisci una trasformazione in dbt, invece di fare riferimento direttamente alle tabelle nel tuo warehouse, fai riferimento ad altri modelli dbt usando la funzione ref(). Questo assicura che dbt costruisca i modelli nell'ordine corretto, identificando quali modelli dipendono da altri.
Per esempio, se hai un modello orders_summary che dipende dal modello orders, lo definiresti così:
WITH orders AS (
SELECT * FROM {{ ref('orders') }}
)
SELECT
customer_id,
COUNT(order_id) AS total_orders,
SUM(order_amount) AS total_revenue
FROM orders
GROUP BY customer_idIn questo esempio, la funzione {{ ref('orders') }} assicura che il orders modello venga costruito prima di orders_summary, poiché orders_summary dipende dai dati nel modello orders.
Le macro in dbt sono blocchi riutilizzabili di codice SQL scritti utilizzando il motore di template Jinja. Ti permettono di automatizzare attività ripetitive, astrarre logiche complesse e riutilizzare codice SQL in più modelli, rendendo il progetto dbt più efficiente e manutenibile.
Le macro possono essere definite in file .sql all'interno della directory macros del progetto dbt.
Le macro sono particolarmente utili quando devi eseguire trasformazioni simili in più modelli o quando serve logica specifica per l'ambiente, ad esempio usare schemi diversi o modificare i formati di data in base agli ambienti di deploy (sviluppo, staging o produzione).
Esempio di creazione di macro:
-- macros/date_format.sql
{% macro format_date(column) %}
FORMAT_TIMESTAMP('%Y-%m-%d', {{ column }})
{% endmacro %}Uso in un modello:
SELECT
customer_id,
{{ format_date('order_date') }} AS formatted_order_date
FROM {{ ref('orders') }}In questo esempio, la macro format_date viene usata per standardizzare il formato della colonna order_date in qualsiasi modello in cui viene richiamata.
-- macros/custom_schema.sql
{% macro custom_schema_name() %}
{% if target.name == 'prod' %}
'production_schema'
{% else %}
'dev_schema'
{% endif %}
{% endmacro %}Uso in un modello:
SELECT *
FROM {{ custom_schema_name() }}.ordersQui la macro verifica se l'ambiente (target.name) è "prod" e restituisce il nome dello schema corretto in base a questo.
Come eseguire le macro:
Le macro non vengono eseguite direttamente come i modelli SQL. Invece, vengono richiamate nei tuoi modelli o in altre macro ed eseguite quando gira il progetto dbt. Ad esempio, se usi una macro all'interno di un modello, la macro verrà eseguita quando lanci il comando dbt run.
dbt run-operation. Si usa tipicamente per attività una tantum, come fare seeding dei dati o operazioni di manutenzione.I test singolari e i test generici sono i due tipi di test in dbt:
Esempio: Diciamo che vuoi assicurarti che nessun ordine abbia un order_amount negativo. Puoi scrivere un test singolare nella directory tests come segue:
-- tests/no_negative_order_amount.sql
SELECT *
FROM {{ ref('orders') }}
WHERE order_amount < 0Se questo test fallisce, dbt restituirà tutte le righe della tabella orders in cui order_amount è negativo.
|
Test generici |
Definizione |
|
Unique |
Verifica valori univoci nella colonna. |
|
Not null |
Controlla l'assenza di campi vuoti. |
|
Available values |
Verifica che i valori di colonna corrispondano a un elenco di valori attesi per mantenere la standardizzazione. |
|
Relationships |
Controlla l'integrità referenziale tra tabelle per eliminare dati incoerenti. |
Esempio: puoi applicare facilmente un test generico per assicurarti che customer_id nella tabella customers sia univoco e non nullo definendolo nel tuo file schema.yml:
version: 2
models:
- name: customers
columns:
- name: customer_id
tests:
- unique
- not_nullIn questo esempio:
customer_id nella tabella customers sia univoco.customer_id sia mancante o nullo.Man mano che avanzi, potresti imbatterti in scenari più complessi e concetti avanzati. Ecco quindi alcune domande impegnative per aiutarti a valutare la tua esperienza e prepararti per posizioni senior di data engineering.
I modelli incrementali in dbt vengono usati per elaborare solo i dati nuovi o modificati invece di rielaborare ogni volta l'intero dataset. Questo è particolarmente utile quando si lavora con dataset di grandi dimensioni, dove ricostruire da zero l'intero modello sarebbe dispendioso in termini di tempo e risorse.
Un modello incrementale permette a dbt di aggiungere solo nuovi dati (o aggiornare i dati modificati) in base a una condizione, tipicamente una colonna timestamp (come updated_at).
Come creare un modello incrementale:
1. Definisci il modello come incrementale specificandolo nella config del modello:
{{ config(
materialized='incremental',
unique_key='id' -- o un'altra colonna univoca
) }}2. Usa la funzione is_incremental() per filtrare le righe nuove o modificate:
SELECT *
FROM source_table
{% if is_incremental() %}
WHERE updated_at > (SELECT MAX(updated_at) FROM {{ this }})
{% endif %}3. Quando dbt esegue questo modello per la prima volta, elaborerà tutti i dati. Nelle esecuzioni successive, elaborerà solo le righe in cui updated_at è maggiore del valore più recente già presente nel modello.
Quando usare i modelli incrementali:
Jinja rende il nostro SQL più flessibile. Con Jinja possiamo definire template riutilizzabili per pattern SQL comuni. E poiché i requisiti cambiano, possiamo usare le istruzioni if di Jinja per adattare le query SQL in base alle condizioni. Così facendo, di solito si migliora il codice SQL scomponendo la logica complessa, rendendola più facile da capire.
Per esempio, se vuoi convertire il formato data da "YYYY-MM-DD" a "MM/DD/YYYY", ecco una macro dbt di esempio per questo, che abbiamo visto in una domanda precedente:
{% macro change_date_format(column_name) %}
to_char({{ column_name }}::date, 'MM/DD/YYYY')
{% endmacro %}In questo esempio di codice, {{ column_name }} è dove Jinja inserisce il nome effettivo della colonna quando usi la macro. Verrà sostituito con il nome reale in fase di esecuzione. Come visto in esempi precedenti, Jinja usa {{ }} per indicare dove avverrà la sostituzione.
Ecco come creare una materializzazione personalizzata in dbt:
materialization_name: {% materialization materialization_name, default -%}adapter.get_relation per impostare la tabella di destinazione. È qui che verranno caricati i dati. {% set sql %}
SELECT * FROM {{ ref('your_source_table') }}
WHERE your_conditions = true
{% endset %}
{{ adapter.execute(sql) }}{{ return(target_relation) }}
{% endmaterialization %}Ecco due modi per fare debug dei nostri modelli dbt:
1. Accedere ai file SQL compilati nella cartella target per individuare e tracciare gli errori.
Quando esegui un progetto dbt, dbt compila i modelli (scritti usando i template Jinja) in query SQL pure e le salva nella directory target. Questo SQL compilato è esattamente ciò che dbt esegue sulla tua piattaforma dati, quindi rivedere questi file può aiutarti a identificare dove si verificano i problemi:
dbt run o dbt test).target/compiled/ nella directory del tuo progetto dbt.2. Usa l'estensione dbt Power User per VS Code per rivedere i risultati delle query direttamente.
L'estensione dbt Power User per Visual Studio Code (VS Code) è uno strumento utile per il debug dei modelli dbt. Questa estensione ti permette di rivedere e testare le query direttamente all'interno dell'IDE, riducendo la necessità di passare tra dbt, terminale e database.
dbt compila le query attraverso i seguenti passaggi:
target/compiled.dbt run, le query sono preparate per l'esecuzione, eventualmente con wrapping aggiuntivo.Questo processo trasforma SQL modulare e templato in query eseguibili specifiche per il tuo data warehouse. Possiamo usare dbt compile o controllare la directory target/compiled per visualizzare e fare debug dell'SQL finale per ciascun modello.
Il lavoro della maggior parte dei data engineer ruota attorno alla costruzione e integrazione di data warehouse con dbt. Le domande relative a questi scenari sono molto comuni ai colloqui — per questo ho raccolto le più frequenti:
Integrare dbt con Airflow aiuta a costruire una pipeline dati snella. Ecco alcuni vantaggi:
Il semantic layer di dbt ci permette di tradurre i dati grezzi in un linguaggio comprensibile. Possiamo anche definire metriche e interrogarle tramite interfaccia a riga di comando (CLI).
Questo ci permette di ottimizzare i costi poiché la preparazione dei dati richiede meno tempo. Inoltre, tutti lavorano con le stesse definizioni dei dati, perché rende le metriche coerenti in tutta l'organizzazione.
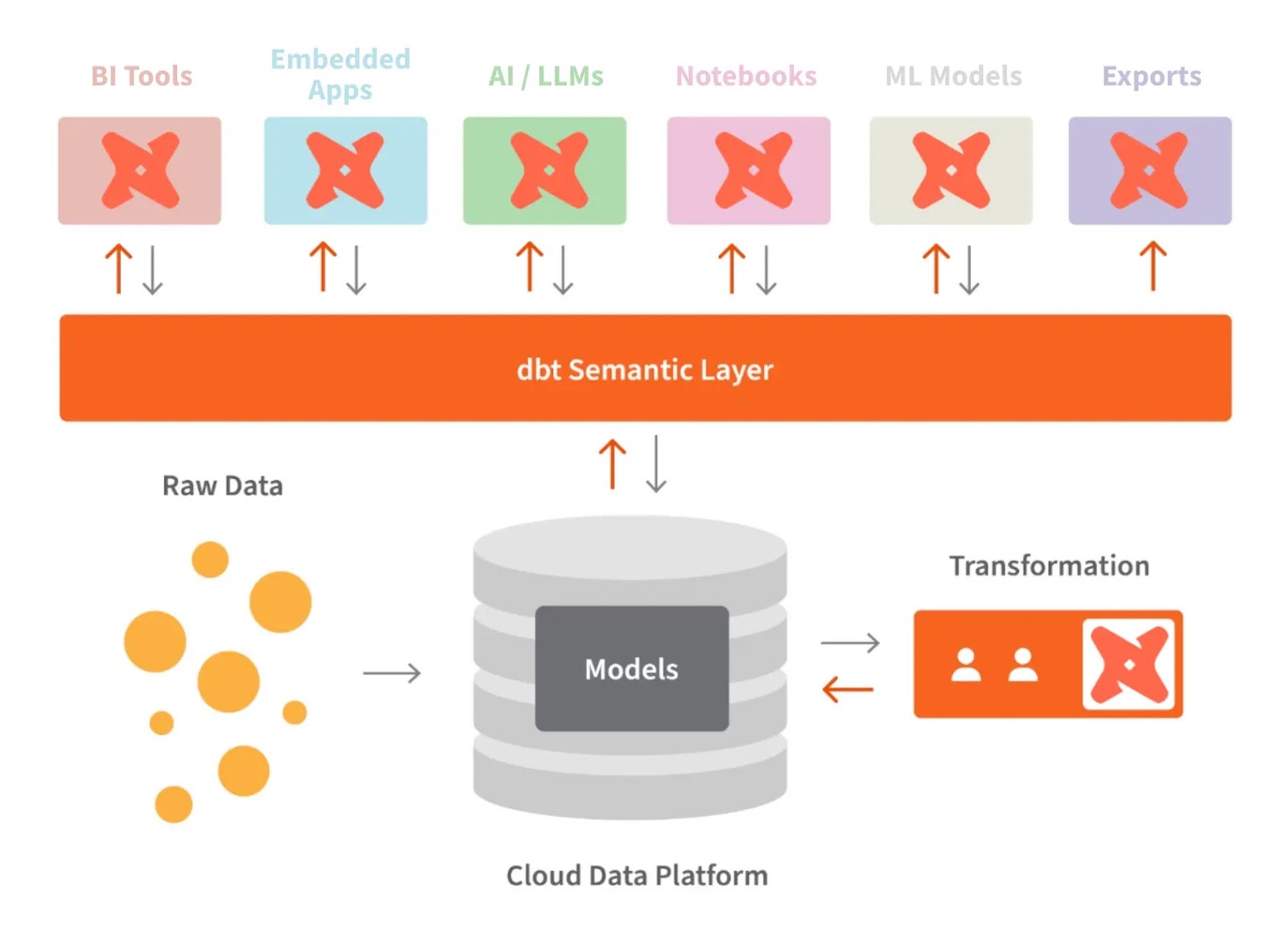
dbt e il semantic layer. Fonte immagine: dbt
Sebbene BigQuery sia molto utile e possa gestire molte trasformazioni in modo nativo, dbt può essere comunque necessario. Ecco perché:
ref() e le macro di dbt permettono SQL più modulare e riutilizzabile.dbt è disponibile in due versioni: dbt Core e dbt Cloud, come visto in una domanda precedente. dbt Core è open source e gratuito. Per questo non offre funzionalità di sicurezza integrate, e gli utenti sono responsabili del deployment e della sicurezza.
dbt Cloud, invece, è progettato per fornire sicurezza completa. È conforme a HIPAA e ad altri framework comuni per garantire la tutela della privacy. Quindi, a seconda delle esigenze, dobbiamo scegliere la versione di dbt che si adatta ai requisiti di conformità della nostra azienda.
Ottimizzare le trasformazioni dbt per grandi dataset è fondamentale per migliorare le prestazioni e ridurre i costi, soprattutto quando si lavora con data warehouse cloud come Snowflake, BigQuery o Redshift. Ecco alcune tecniche chiave per ottimizzare le prestazioni di dbt:
1. Usa modelli incrementali
I modelli incrementali permettono a dbt di elaborare solo i dati nuovi o aggiornati invece di rielaborare ogni volta l'intero dataset. Questo può ridurre notevolmente i tempi di run per dataset grandi. Questo processo limita la quantità di dati elaborati, accelerando i tempi di trasformazione.
2. Sfrutta partitioning e clustering (per database come Snowflake e BigQuery)
Partizionare e clusterizzare grandi tabelle in database come Snowflake o BigQuery aiuta a migliorare le prestazioni delle query organizzando i dati in modo efficiente e riducendo la quantità di dati scansionati durante le interrogazioni.
Il partitioning assicura che vengano interrogate solo le porzioni rilevanti di un dataset, mentre il clustering ottimizza il layout fisico dei dati per un recupero più veloce.
3. Ottimizza le materializzazioni (table, view, incremental)
Usa materializzazioni appropriate per ottimizzare le prestazioni:
4. Usa LIMIT in sviluppo
Durante lo sviluppo delle trasformazioni, aggiungere una clausola LIMIT alle query è utile per limitare il numero di righe elaborate. Questo accelera i cicli di sviluppo ed evita di lavorare con dataset enormi durante i test.
5. Esegui le query in parallelo
Sfrutta la capacità del tuo data warehouse di eseguire query in parallelo. Ad esempio, dbt Cloud supporta il parallelismo, regolabile in base alla tua infrastruttura.
6. Usa funzionalità di ottimizzazione specifiche del database
Molti data warehouse cloud forniscono funzionalità di ottimizzazione delle prestazioni come:
Per ottimizzare i run di dbt in Snowflake:
1. Usa il clustering delle tabelle:
{{ config(
cluster_by = ["date_column", "category_column"]
) }}
SELECT ...2. Sfrutta i multi-cluster warehouse di Snowflake per l'esecuzione parallela dei modelli:
models:
my_project:
materialized: table
snowflake_warehouse: transforming_wh3. Usa modelli incrementali dove opportuno:
{{ config(materialized='incremental', unique_key='id') }}
SELECT *
FROM source_table
{% if is_incremental() %}
WHERE updated_at > (SELECT MAX(updated_at) FROM {{ this }})
{% endif %}Queste ottimizzazioni possono migliorare le prestazioni e la convenienza economica dei run di dbt in Snowflake.
Alla fine del processo di colloquio, di solito vengono testate le tue capacità di problem-solving. Potrebbero farti domande per vedere come risponderesti a problemi reali.
Ricorda questa citazione riguardo alle soft skill richieste per il ruolo di Deepak Goyal, CEO e Founder di Azurelib Academy, durante il suo intervento al podcast DataFramed:
Come Data Engineer, devi saper comunicare. Un data engineer deve comunicare perché deve parlare con molti stakeholder per capire che tipo di output o risultato stanno cercando.
Deepak Goya, CEO & Founder at Azurelib Academy
Approfondisci il data engineering con questi corsi!
Programma
Corso
Corso
blog
Abid Ali Awan
15 min
blog
Abid Ali Awan
10 min
blog
Tim Lu
12 min

