
Lernpfad
Professioneller Dateningenieur in Python
40 Std.
dbt (Data Build Tool) ist mittlerweile ein echt beliebtes Entwicklungsframework in modernen Datenverarbeitungs- und Analyse-Workflows. Datenanalysten verlassen sich meistens auf Dateningenieure, um Transformationen in SQL zu schreiben. Aber mit dbt können sie Transformationen schreiben und haben mehr Kontrolle über die Daten. Außerdem kann man es mit beliebten Versionskontrollsystemen wie Git verbinden, was die Zusammenarbeit im Team echt verbessert.
Wenn du dich auf einen Job im Bereich Data Warehouse vorbereitest, wie zum Beispiel als Dateningenieur, Datenanalyst oder Datenwissenschaftler, solltest du dich mit grundlegenden und fortgeschrittenen dbt-Fragen gut auskennen!
In diesem Artikel habe ich die häufigsten Interviewfragen zusammengefasst, damit du dir grundlegende Konzepte und fortgeschrittene Problemlösungsfähigkeiten aneignen kannst.
dbt ist ein Open-Source-Framework für die Datenumwandlung, mit dem du Daten umwandeln, auf Genauigkeit prüfen und Änderungen auf einer einzigen Plattform verfolgen kannst. Anders als andere ETL-Tools (Extrahieren, Transformieren, Laden) macht dbt nur den Transformationsteil (das T).
Einige andere ETL-Tools holen Daten aus verschiedenen Quellen, machen sie außerhalb des Data Warehouse fertig und laden sie dann wieder rein. Dafür braucht man oft spezielle Programmierkenntnisse und zusätzliche Tools. Aber dbt macht das einfacher – es ermöglicht Transformationen im Warehouse nur mit SQL.
Über 40.000 große Unternehmen nutzen dbt, um ihre Daten zu optimieren – deshalb sagen Personalvermittler, dass es eine der wichtigsten Fähigkeiten für Jobs im Datenbereich ist. Wenn du das also schon als Anfänger im Bereich Daten beherrschst, kann dir das viele Karrierechancen eröffnen!
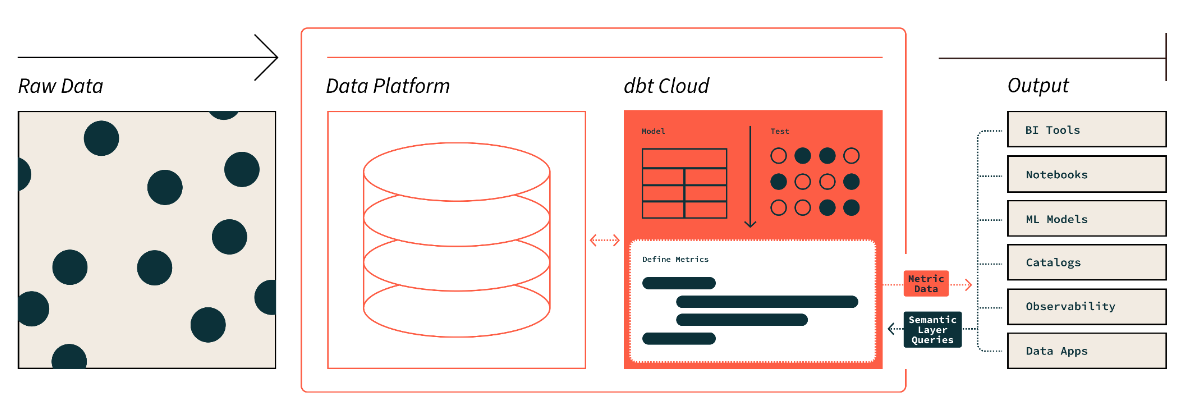
Die semantische Ebene von DBT. Bildquelle: dbt
Der Interviewer wird am Anfang des Vorstellungsgesprächs deine Grundkenntnisse checken. Dafür stellen sie dir vielleicht ein paar grundlegende Fragen wie diese:
dbt bringt ein Datenteam auf eine Seite, wo sie ihre Daten umwandeln, dokumentieren und testen können. Es hilft dabei, dass die Daten zuverlässig und leicht verständlich sind. Zu den gängigen Anwendungen von dbt gehören:
Nein, dbt ist keine Programmiersprache. Das ist ein Tool, das bei der Datenumwandlung im Lager hilft. Wenn du SQL schreiben kannst, kannst du ganz einfach mit dbt arbeiten. Es unterstützt jetzt auch Python für bestimmte Aufgaben. Aber im Grunde genommen verwaltet und führt es SQL-basierte Transformationen aus.
dbt und Spark haben unterschiedliche Aufgaben und sind für verschiedene Arten von Arbeitsabläufen gedacht. Hier ist ein Vergleich ihrer Rolle in der Dateninfrastruktur:
|
Feature |
dbt |
Spark |
|
Rolle |
SQL-basierte Datenumwandlungen und Modellierung |
Verteilte Datenverarbeitung und -analyse |
|
Kernsprache |
SQL-first, mit eingeschränkter Python-Unterstützung |
Supports SQL, Python, Scala, Java, R |
|
Datenverwaltung |
Unterstützung bei Dokumentation und Abstammung |
Bietet Zugriffskontrolle, Überwachung und Datenherkunft |
|
Zielgruppe |
SQL-Nutzer, Analysten und Teams ohne technische Kenntnisse |
Dateningenieure, Datenwissenschaftler, Entwickler |
|
Komplexität der Transformation |
Konzentriert sich nur auf SQL-Transformationen und Modellierung |
Kann auch komplexe Umwandlungen in anderen Sprachen machen. |
|
Testen und Validieren |
Hat eingebaute Testfunktionen |
Benötige maßgeschneiderte Teststrategien (Unit- und Integrationstests) |
Obwohl dbt für Datenteams echt nützlich ist, kann es auch ein paar Probleme mit sich bringen, vor allem wenn der Umfang und die Komplexität zunehmen. Einige der häufigsten Herausforderungen sind also:
Zu wissen, wie man mit den oben genannten möglichen Herausforderungen umgeht, ist etwas, worauf Arbeitgeber achten. Übersieh also nicht, wie wichtig diese Frage ist.
Es gibt zwei Hauptversionen von dbt:
dbt Core ist die kostenlose Open-Source-Version von dbt, mit der man SQL-basierte Transformationen lokal schreiben, ausführen und verwalten kann. Es bietet eine Befehlszeilenschnittstelle (CLI) zum Ausführen von dbt-Projekten, Testen von Modellen und Erstellen von Datenpipelines. Da es sich um Open Source handelt, musst du bei dbt Core selbst für die Bereitstellung, Orchestrierung und Infrastrukturkonfiguration sorgen, normalerweise in einer Umgebung wie, die mit Tools wie Airflow oder Kubernetes für die Automatisierung integriert ist.
dbt Cloud ist dagegen ein Managed Service, den die Macher von dbt (Fishtown Analytics) anbieten. Es hat alle Funktionen von dbt Core und noch mehr Sachen wie eine Web-Oberfläche, integrierte Planung, Job-Management und Tools für die Zusammenarbeit. dbt Cloud hat auch baute CI/CD-Funktionen (Continuous Integration und Deployment), API-Zugriff und verbesserte Sicherheitsstandards wie SOC 2 und HIPAA für Unternehmen mit strengeren Sicherheitsanforderungen.
Nachdem wir jetzt die grundlegenden dbt-Fragen geklärt haben, kommen wir zu ein paar dbt-Fragen für Fortgeschrittene. Die konzentrieren sich auf bestimmte technische Sachen und Konzepte.
In dbt sind Quellen die Rohdaten-Tabellen. Wir schreiben keine SQL-Abfragen direkt in diese Rohdaten-Tabellen – wir geben das Schema und den Tabellennamen an und legen sie als Quellen fest. Das macht es einfacher, auf Datenobjekte in Tabellen zu verweisen.
Stell dir vor, du hast eine Rohdaten-Tabelle namens „ orders ” in deiner Datenbank im Schema „ sales ”. Anstatt diese Tabelle direkt abzufragen, würdest du sie in dbt wie folgt als Quelle definieren:
Leg die Quelle in deiner Datei „ sources.yml “ fest:
version: 2
sources:
- name: sales
tables:
- name: ordersBenutze die Quelle in deinen dbt-Modellen:
Sobald du das gemacht hast, kannst du in deinen Transformationen wie folgt auf die Tabelle „raw- orders ” zugreifen:
SELECT *
FROM {{ source('sales', 'orders') }}Dieser Ansatz abstrahiert die Roh-Tabellendefinition, was die Verwaltung vereinfacht und sicherstellt, dass du bei Änderungen an der zugrunde liegenden Tabellenstruktur diese an einer Stelle (der Quelldefinition) aktualisieren kannst, anstatt jede Abfrage einzeln anzupassen.
Vorteile der Verwendung von Quellen in dbt:
Ein DBT-Modell ist im Grunde eine SQL- oder Python-Datei, die die Transformationslogik für Rohdaten festlegt. In dbt sind Modelle die Kernkomponente, in der du deine Transformationen schreibst, egal ob es sich um Aggregationen, Verknüpfungen oder irgendeine Art von Datenbearbeitung handelt.
SELECT “-Anweisungen, um Transformationen zu definieren, und werden als „sql “-Dateien gespeichert..py “-Dateien gespeichert und ermöglichen es dir, Python-Bibliotheken wie pandas zur Datenbearbeitung zu nutzen.Beispiel für ein SQL-Modell:
Ein SQL-Modell macht Rohdaten mit SQL-Abfragen fertig. Zum Beispiel, um eine Zusammenfassung der Bestellungen aus einer Tabelle „ orders ” zu erstellen:
--orders_summary.sql
WITH orders_cte AS (
SELECT
customer_id,
COUNT(order_id) AS total_orders,
SUM(order_amount) AS total_revenue
FROM {{ ref('orders') }}
GROUP BY customer_id
)
SELECT *
FROM orders_cteIn diesem Beispiel:
orders_summary.sql “ erstellt mit SQL eine Übersicht über die Gesamtbestellungen und den Gesamtumsatz für jeden Kunden.orders “ (die schon als dbt-Modell oder -Quelle definiert ist).Python-Modellbeispiel:
Ein Python-Modell bearbeitet Rohdaten mit Python-Code. Das kann besonders nützlich sein, wenn es um komplizierte Logik geht, die in SQL echt nervig sein kann.
# orders_summary.py
import pandas as pd
def model(dbt, session):
# Load the source data
orders = dbt.ref("orders").to_pandas()
# Perform transformations using pandas
orders_summary = orders.groupby('customer_id').agg(
total_orders=('order_id', 'count'),
total_revenue=('order_amount', 'sum')
).reset_index()
return orders_summaryIn diesem Beispiel:
So machst du ein dbt-Modell:
models “ an. .sql “ in das Verzeichnis ein (oder „ .py “, wenn es sich um ein Python-Modell handelt).dbt run “ ab,um die Transformation anzuwenden und das Modell zu erstellen.dbt regelt Modellabhängigkeiten mit der Funktion „ ref() “, die eine klare Abhängigkeitskette zwischen den Modellen aufbaut.
Wenn du eine Transformation in dbt definierst, verweist du nicht direkt auf Tabellen in deinem Warehouse, sondern auf andere dbt-Modelle mithilfe der Funktion „ ref() “. Dadurch wird sichergestellt, dass dbt die Modelle in der richtigen Reihenfolge erstellt, indem es erkennt, welche Modelle von anderen abhängig sind.
Wenn du zum Beispiel ein Modell namens „ orders_summary ” hast, das vom Modell „ orders ” abhängt, würdest du es so definieren:
WITH orders AS (
SELECT * FROM {{ ref('orders') }}
)
SELECT
customer_id,
COUNT(order_id) AS total_orders,
SUM(order_amount) AS total_revenue
FROM orders
GROUP BY customer_idIn diesem Beispiel sorgt die Funktion „ {{ ref('orders') }} ” dafür, dass das Modell „ orders ” vor „ orders_summary ” erstellt wird, weil „ orders_summary ” auf die Datenim Modell „ orders ” angewiesen ist .
Makros in dbt sind wiederverwendbare Blöcke von SQL-Code, die mit der Jinja-Template-Engine geschrieben wurden. Damit kannst du sich wiederholende Aufgaben automatisieren, komplexe Logik abstrahieren und SQL-Code in mehreren Modellen wiederverwenden, was dein dbt-Projekt effizienter und wartungsfreundlicher macht.
Makros kannst du in den Dateien „ .sql “ im Verzeichnis „ macros “ deines dbt-Projekts festlegen.
Makros sind echt praktisch, wenn du ähnliche Änderungen an mehreren Modellen vornehmen musst oder umgebungsabhängige Logik brauchst, wie zum Beispiel verschiedene Schemata verwenden oder Datumsformate je nach Einsatzumgebung (z. B. Entwicklung, Staging oder Produktion) anpassen.
Beispiel für die Erstellung von Makros:
-- macros/date_format.sql
{% macro format_date(column) %}
FORMAT_TIMESTAMP('%Y-%m-%d', {{ column }})
{% endmacro %}Verwendung in einem Modell:
SELECT
customer_id,
{{ format_date('order_date') }} AS formatted_order_date
FROM {{ ref('orders') }}In diesem Beispiel wird das Makro „ format_date “ benutzt, um das Format der Spalte „ order_date “ in jedem Modell, in dem es aufgerufen wird, zu standardisieren.
-- macros/custom_schema.sql
{% macro custom_schema_name() %}
{% if target.name == 'prod' %}
'production_schema'
{% else %}
'dev_schema'
{% endif %}
{% endmacro %}Verwendung in einem Modell:
SELECT *
FROM {{ custom_schema_name() }}.ordersHier checkt das Makro, ob die Umgebung (target.name) „prod” ist, und gibt dann den richtigen Schemanamen zurück.
So führst du Makros aus:
Makros werden nicht direkt wie SQL-Modelle ausgeführt. Stattdessen werden sie in deinen Modellen oder anderen Makros referenziert und ausgeführt, wenn das dbt-Projekt läuft. Wenn du zum Beispiel ein Makro in einem Modell benutzt, wird das Makro ausgeführt, wenn du den Befehl „ dbt run “ (Modell ausführen) startest.
dbt run-operation “ aufrufst. Das wird meistens für einmalige Aufgaben benutzt, wie zum Beispiel das Einfügen von Daten oder Wartungsarbeiten.Einzelne Tests und generische Tests sind die beiden Testtypen in dbt:
Beispiel: Angenommen, du willst sicherstellen, dass keine Bestellungen einen negativen Wert für „ order_amount “ haben. Du kannst einen einzelnen Test im Verzeichnis „ tests ” wie folgt schreiben:
-- tests/no_negative_order_amount.sql
SELECT *
FROM {{ ref('orders') }}
WHERE order_amount < 0Wenn dieser Test nicht klappt, gibt dbt alle Zeilen aus der Tabelle „ orders ” zurück, bei denen „ order_amount ” negativ ist.
|
Allgemeine Tests |
Definition |
|
Einzigartig |
Überprüft die Spalte auf eindeutige Werte. |
|
Nicht null |
Überprüft, ob irgendwelche Felder leer sind. |
|
Mögliche Werte |
Überprüft, ob die Spaltenwerte mit einer Liste erwarteter Werte übereinstimmen, um die Standardisierung aufrechtzuerhalten. |
|
Beziehungen |
Überprüft die Referenzintegrität zwischen Tabellen, um inkonsequente Daten zu entfernen. |
Beispiel: Du kannst ganz einfach einen generischen Test machen, um sicherzustellen, dass „ customer_id ” in der Tabelle „ customers ” eindeutig und nicht null ist, indem du das in deiner Datei „ schema.yml ” festlegst:
version: 2
models:
- name: customers
columns:
- name: customer_id
tests:
- unique
- not_nullIn diesem Beispiel:
customer_id ” in der Tabelle „ customers ” einzigartig ist.customer_id fehlen oder null sind.Im Laufe deiner Arbeit wirst du vielleicht auf komplexere Szenarien und fortgeschrittene Konzepte stoßen. Hier sind ein paar knifflige Interviewfragen, die dir helfen sollen, dein Fachwissen einzuschätzen und dich auf leitende Positionen im Bereich Data Engineering vorzubereiten.
Inkrementelle Modelle in dbt werden verwendet, um nur neue oder geänderte Daten zu verarbeiten, anstatt jedes Mal den gesamten Datensatz neu zu verarbeiten. Das ist besonders praktisch, wenn man mit großen Datensätzen arbeitet, bei denen es echt zeitaufwendig und ressourcenintensiv wäre, das ganze Modell von Grund auf neu zu erstellen.
Ein inkrementelles Modell lässt dbt nur neue Daten anfügen (oder geänderte Daten aktualisieren), basierend auf einer Bedingung, normalerweise einer Zeitstempel-Spalte (wie updated_at).
Wie man ein inkrementelles Modell erstellt:
1. Mach das Modell in der Modellkonfiguration als inkrementell klar:
{{ config(
materialized='incremental',
unique_key='id' -- or another unique column
) }}2. Benutz die Funktion „ is_incremental() “, um neue oder geänderte Zeilen herauszufiltern:
SELECT *
FROM source_table
{% if is_incremental() %}
WHERE updated_at > (SELECT MAX(updated_at) FROM {{ this }})
{% endif %}3. Wenn dbt dieses Modell zum ersten Mal ausführt, verarbeitet es alle Daten. Bei den nächsten Durchläufen werden nur Zeilen bearbeitet, bei denen der Wert „ updated_at “ größer ist als der aktuellste Wert, der schon im Modell ist.
Wann man inkrementelle Modelle benutzt:
Jinja macht unseren SQL-Code flexibler. Mit Jinja können wir wiederverwendbare Vorlagen für gängige SQL-Muster erstellen. Und weil sich die Anforderungen ständig ändern, können wir Jinjas Anweisungen „ if “ ( ) und „“ ( ) nutzen, um unsere SQL-Abfragen je nach den Bedingungen anzupassen. Dadurch wird der SQL-Code normalerweise verbessert, weil komplexe Logik aufgebrochen wird, was das Verständnis erleichtert.
Wenn du zum Beispiel das Datumsformat von „JJJJ-MM-TT“ in „MM/TT/JJJJ“ umwandeln willst, gibt's dafür ein Beispiel-Makro in dbt, das wir schon in einer früheren Frage gesehen haben:
{% macro change_date_format(column_name) %}
to_char({{ column_name }}::date, 'MM/DD/YYYY')
{% endmacro %}In diesem Code-Beispiel wird „ {{ column_name }} “ durch den tatsächlichen Spaltennamen ersetzt, wenn du das Makro verwendest. Es wird während der Laufzeit durch den tatsächlichen Spaltennamen ersetzt. Wie wir in den vorherigen Beispielen gesehen haben, zeigt Jinja mit „ {{ }} “ an, wo die Ersetzung stattfinden wird.
So machst du eine benutzerdefinierte Materialisierung in dbt:
materialization_name “: {% materialization materialization_name, default -%}adapter.get_relation “, um die Tabelle einzurichten. Hier werden die Daten geladen. {% set sql %}
SELECT * FROM {{ ref('your_source_table') }}
WHERE your_conditions = true
{% endset %}
{{ adapter.execute(sql) }}{{ return(target_relation) }}
{% endmaterialization %}Hier sind zwei Möglichkeiten, um unsere dbt-Modelle zu debuggen:
1. Öffne die kompilierten SQL-Dateien im Zielordner, um Fehler zu finden und zu verfolgen.
Wenn du ein dbt-Projekt ausführst, kompiliert dbt deine Modelle (die mit Jinja-Vorlagen geschrieben wurden) zu rohen SQL-Abfragen und speichert sie im Verzeichnis „ target “. Dieses kompilierte SQL ist genau das, was dbt auf deiner Datenplattform ausführt. Wenn du diese Dateien durchsiehst, kannst du herausfinden, wo Probleme auftreten:
dbt run oder dbt test).target/compiled/ ” in deinem dbt-Projektverzeichnis.2. Benutzdie dbt Power User Extension für VS Code von , um die Abfrageergebnisse direkt zu checken.
Die dbt Power User Extension für Visual Studio Code (VS Code) ist ein echt praktisches Tool zum Debuggen von dbt-Modellen. Mit dieser Erweiterung kannst du deine Abfragen direkt in deiner IDE überprüfen und testen, sodass du nicht mehr so oft zwischen dbt, dem Terminal und deiner Datenbank hin- und herwechseln musst.
dbt macht Abfragen mit den folgenden Schritten:
target/compiled “ gespeichert.dbt run “ werden Abfragen für die Ausführung vorbereitet, eventuell mit zusätzlicher Umschreibung.Dieser Prozess macht aus modularen, vorgefertigten SQL-Vorlagen Abfragen, die speziell für dein Data Warehouse funktionieren. Wir können „ dbt compile “ verwenden oder das Verzeichnis „ target/compiled “ überprüfen, um die endgültige SQL für jedes Modell anzuzeigen und zu debuggen.
Die meisten Dateningenieure beschäftigen sich hauptsächlich mit dem Aufbau und der Integration von Data Warehouses mit dbt. Fragen zu diesen Szenarien kommen in Vorstellungsgesprächen echt oft vor – deshalb hab ich die häufigsten mal zusammengestellt:
Die Integration von dbt mit Airflow hilft dabei, eine optimierte Datenpipeline aufzubauen. Hier sind ein paar Vorteile:
Die semantische Ebene von dbt lässt uns Rohdaten in eine Sprache übersetzen, die wir verstehen. Wir können auch Metriken festlegen und sie über eine Befehlszeilenschnittstelle (CLI) abfragen.
Dadurch können wir die Kosten optimieren, weil die Datenvorbereitung weniger Zeit braucht. Außerdem arbeiten alle mit denselben Datendefinitionen, weil das die Metriken im ganzen Unternehmen einheitlich macht.
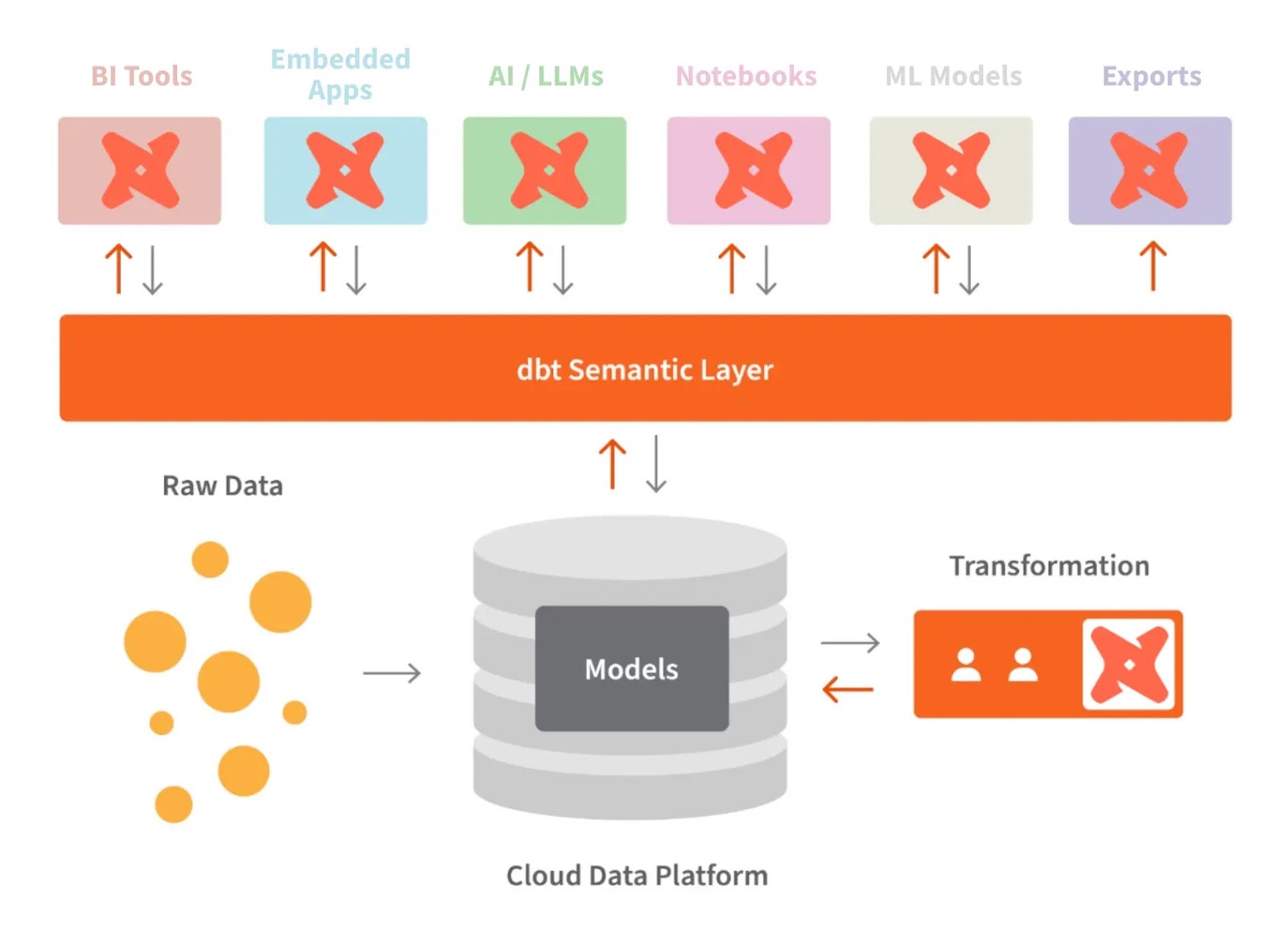
dbt und die semantische Ebene. Bildquelle: dbt
Auch wenn BigQuery echt hilfreich ist und viele Transformationen von Haus aus hinkriegt, kann dbt trotzdem noch nötig sein. Hier ist der Grund:
ref() ” und die Makros von dbt machen SQL-Code modularer und wiederverwendbarer.dbt gibt's in zwei Versionen: dbt Core und dbt Cloud, wie in einer früheren Frage erwähnt. dbt Core ist Open Source und kostenlos. Deshalb hat es keine eingebauten Sicherheitsfunktionen und die Nutzer müssen sich selbst um die Installation und Sicherheit kümmern.
Aber dbt Cloud ist so gemacht, dass es voll auf Sicherheit setzt. Es hält sich an HIPAA und andere gängige Rahmenbedingungen, um sicherzustellen, dass die Privatsphäre nicht verletzt wird. Also müssen wir je nach unseren Bedürfnissen eine DBT-Version wählen, die zu unseren Anforderungen an die Geschäftskonformität passt.
Die Optimierung von dbt-Transformationen für große Datensätze ist super wichtig, um die Leistung zu verbessern und die Kosten zu senken, vor allem bei Cloud-basierten Data Warehouses wie Snowflake, BigQuery oder Redshift. Hier sind ein paar wichtige Techniken, um die Leistung von dbt zu verbessern:
1. Inkrementelle Modelle verwenden
Mit inkrementellen Modellen kann dbt nur neue oder aktualisierte Daten verarbeiten, anstatt jedes Mal den ganzen Datensatz neu zu verarbeiten. Das kann die Laufzeiten für große Datensätze echt verkürzen. Dieser Prozess reduziert die Menge der verarbeiteten Daten und beschleunigt so die Transformationszeiten.
2. Nutze Partitionierung und Clustering (für Datenbanken wie Snowflake und BigQuery)
Das Aufteilen und Clustern großer Tabellen in Datenbanken wie Snowflake oder BigQuery hilft dabei, die Abfrageleistung zu verbessern, indem die Daten effizient organisiert und die Menge der während der Abfragen gescannten Daten reduziert werden.
Partitionierung sorgt dafür, dass nur die relevanten Teile eines Datensatzes abgefragt werden, während Clustering die physische Anordnung der Daten optimiert, um sie schneller abrufen zu können.
3. Materialisierungen optimieren (Tabelle, Ansicht, inkrementell)
Nutze die richtigen Materialisierungen, um die Leistung zu verbessern:
4. Benutze LIMIT während der Entwicklung
Beim Entwickeln von Transformationen ist es praktisch, eine „ LIMIT “-Klausel zu Abfragen hinzuzufügen, um die Anzahl der verarbeiteten Zeilen zu begrenzen. Das beschleunigt die Entwicklungszyklen und man muss beim Testen nicht mit riesigen Datensätzen rumschleppen.
5. Führe Abfragen parallel aus
Nutze die Fähigkeit deines Data Warehouse, Abfragen parallel auszuführen. Zum Beispiel unterstützt dbt Cloud Parallelität, die je nach deiner Infrastruktur angepasst werden kann.
6. Nutze die Optimierungsfunktionen, die speziell für die Datenbank gedacht sind.
Viele Cloud-Data-Warehouses bieten Funktionen zur Leistungsoptimierung, wie zum Beispiel:
Um dbt-Läufe in Snowflake zu optimieren:
1. Tabellen-Clustering verwenden:
{{ config(
cluster_by = ["date_column", "category_column"]
) }}
SELECT ...2. Nutze die Multi-Cluster-Warehouses von Snowflake für die parallele Ausführung von Modellen:
models:
my_project:
materialized: table
snowflake_warehouse: transforming_wh3. Nimm inkrementelle Modelle, wenn es passt:
{{ config(materialized='incremental', unique_key='id') }}
SELECT *
FROM source_table
{% if is_incremental() %}
WHERE updated_at > (SELECT MAX(updated_at) FROM {{ this }})
{% endif %}Diese Optimierungen können die Leistung und Kosteneffizienz von dbt-Läufen in Snowflake verbessern.
Am Ende des Vorstellungsgesprächs checken die Leute, die dich interviewen, meistens deine Fähigkeiten, Probleme zu lösen. Sie könnten dir Fragen stellen, um zu sehen, wie du auf echte Probleme reagierst. Hier sind ein paar Fragen zum Verhalten und zur Problemlösung:
So kannst du die Bereitstellung von dbt in verschiedenen Umgebungen verwalten:
1. Umgebungsspezifische Konfigurationen
Mit dbt kannst du in der Datei „ dbt_project.yml “ verschiedene Konfigurationen für jede Umgebung (Entwicklung, Staging und Produktion) festlegen. Du kannst verschiedene Einstellungen für Sachen wie Schema, Datenbank und Data Warehouse-Konfigurationen festlegen.
Beispiel in „ dbt_project.yml “:
models:
my_project:
dev:
schema: dev_schema
staging:
schema: staging_schema
prod:
schema: prod_schemaIn diesem Beispiel wählt dbt beim Ausführen des Projekts automatisch das richtige Schema basierend auf der Zielumgebung (Entwicklung, Staging oder Produktion) aus.
2. Die Zielvariable verwenden
Die Variable „ target ” in dbt wird benutzt, um festzulegen, in welcher Umgebung du arbeitest (Entwicklung, Staging, Produktion). Du kannst diese Variable in deinen Modellen oder Makros verwenden, um das Verhalten je nach Umgebung anzupassen.
Beispiel in einem Modell:
{% if target.name == 'prod' %}
SELECT * FROM production_table
{% else %}
SELECT * FROM {{ ref('staging_table') }}
{% endif %}Diese Logik sorgt dafür, dass je nach Umgebung unterschiedliche Tabellen oder Schemata verwendet werden.
3. Verzweigung und Versionskontrolle
Jede Umgebung sollte ihren eigenen Zweig in der Versionskontrolle haben (z. B. Git). Entwickler arbeitenank auf dem Zweig dev, Tester und Analysten nutzen staging, und nur genehmigte Änderungen werden in den Zweig prod übernommen.
4. Kontinuierliche Integration (CI) & Kontinuierliche Bereitstellung (CD)
In der Produktion ist es wichtig, eine automatisierte Bereitstellungspipeline zu haben, die Tests und Validierungen durchführt, bevor Modelle bereitgestellt werden. In dbt Cloud kannst du Job-Zeitpläne einrichten, um bestimmte Aufgaben je nach Umgebung auszuführen. Für dbt Core kann das mit CI/CD-Tools wie GitHub Actions oder Jenkins gemacht werden.
Versionskontrolle ist super wichtig, wenn man an dbt-Projekten arbeitet, vor allem in einem Team, wo mehrere Leute an derselben Codebasis arbeiten. So mache ich das mit der Versionskontrolle in dbt:
1. Benutz Git für die Versionskontrolle
Wir nutzen Git als Hauptwerkzeug für die Versionskontrolle in unseren dbt-Projekten. Jedes Teammitglied arbeitet an seinem eigenen Zweig, wenn es um Änderungen oder Funktionen geht, die sie umsetzen. Das ermöglicht eine isolierte Entwicklung und verhindert Konflikte zwischen Teammitgliedern, die gleichzeitig an verschiedenen Aufgaben arbeiten.
Beispiel: Ich erstelle einen neuen Feature-Zweig wie feature/customer_order_transformation, wenn ich an einem neuen dbt-Modell arbeite.
2. Verzweigungsstrategie
Wir machen eine Git-Verzweigungsstrategie, bei der:
dev “ wird für die laufende Entwicklung und das Testen genutzt.staging “ wird benutzt, um Änderungen für die Produktion vorzubereiten.main “ oder „ prod“ ist für die Produktionsumgebung reserviert.Die Teammitglieder schicken ihre Änderungen an den „ dev “-Zweig und machen Pull-Anfragen (PRs) für Code-Reviews. Sobald die Änderungen überprüft und genehmigt sind, werden sie in staging für weitere Tests zusammengeführt und dann in production verschoben.
3. Kontinuierliche Integration (CI)
Wir haben eine CI-Pipeline eingebaut (z. B. GitHub Actions, CircleCI), die bei jedem Pull-Request automatisch dbt-Tests durchführt. So wird sichergestellt, dass jeder neue Code die erforderlichen Tests besteht, bevor er in den Hauptzweig integriert wird.
Der CI-Prozess läuft über „ dbt run “, um Modelle zu erstellen, und „ dbt test “, um die Daten zu überprüfen und nach Fehlern oder Unstimmigkeiten zu suchen.
4. Merge-Konflikte lösen
Wenn mehrere Teammitglieder Änderungen am selben Modell oder an derselben Datei vornehmen, kann es zu Konflikten beim Zusammenführen kommen. Um das zu regeln, schaue ich mir erst mal die Konfliktmarkierungen im Code an und entscheide, welche Änderungen ich behalten will:
Nachdem ich den Konflikt geklärt habe, mache ich ein paar Tests auf meinem Rechner, um sicherzugehen, dass die Konfliktlösung keine neuen Fehler verursacht hat. Sobald ich alles überprüft habe, schicke ich die erledigten Änderungen zurück zum Branch.
5. Dokumentation und Zusammenarbeit
Wir sorgen dafür, dass jede Zusammenführung oder jeder Pull-Request eine ordentliche Dokumentation der vorgenommenen Änderungen enthält. Wir halten die automatisch erstellte dbt-Dokumentation auf dem neuesten Stand, damit alle im Team die neuen oder aktualisierten Modelle gut verstehen.
So würde ich dbt in einer bestehenden Pipeline einbauen:
Wenn du in dbt die Fehlermeldung „relation does not exist” (Beziehung existiert nicht) bekommst, heißt das meistens, dass das Modell versucht, auf eine Tabelle oder ein Modell zu verweisen, das noch nicht erstellt wurde oder falsch geschrieben ist. So würde ich das Problem beheben:
ref() “ richtig geschrieben ist, und überprüfe, ob auf das richtige Modell oder die richtige Tabelle verwiesen wird.SELECT * FROM {{ ref('orders') }} -- Ensure 'orders' is the correct model namedbt debug “ nach und check die Protokolle für genaue Infos darüber, was dbt versucht hat und warum es nicht geklappt hat.dbt run --models orders), um zu checken, ob sie da sind und richtig aufgebaut sind, bevor das fehlerhafte Modell kommt.dbt ist ein neues Framework, das immer besser wird. Es kann echt anstrengend sein, mit den neuen Updates Schritt zu halten und gleichzeitig noch den alten Stoff zu lernen. Deshalb solltest du einen ausgewogenen Ansatz wählen und mit den Kernfunktionen anfangen. Wenn du sie drauf hast, schau dir die Neuerungen an, um zu sehen, was sich geändert hat.
Ich weiß, dass Vorstellungsgespräche echt nervenaufreibend sein können, vor allem bei einem speziellen Tool wie dbt. Aber keine Sorge – ich hab ein paar Tipps zusammengestellt, die dir bei der Vorbereitung helfen und dir Selbstvertrauen geben:
Ich kann das gar nicht genug betonen: Mach dich mit den grundlegenden Konzepten von DBT vertraut, einschließlich Modellen, Tests, Dokumentation und wie alles zusammenpasst. Wenn du diese Grundlagen gut verstehst, bist du in technischen Gesprächen gut aufgestellt.
DataCamp hat den perfekten Kurs dafür: Einführung in dbt
DataCamp hat auch ein paar Anfängerkurse, die sich eingehend mit anderen Themen aus dem Bereich Data Engineering beschäftigen:
Über etwas zu lesen ist gut, aber es zu machen ist noch besser. Das ist eine der besten Methoden, um DBT-Fähigkeiten zu lernen. Du kannst online eine riesige Liste von Rohdatensätzen finden, um Transformationen durchzuführen und Tests zu machen. Mach dein eigenes dbt-Projekt und probier verschiedene Funktionen aus. Du wirst dich viel sicherer fühlen, wenn du über DBT redest, nachdem du es selbst benutzt hast.
Interviewer hören gerne von praktischen Anwendungen. Fällt dir ein Problem ein, das du mit dbt gelöst hast, oder wie du es in einem hypothetischen Szenario einsetzen könntest? Halte ein paar dieser Beispiele bereit, um sie zu teilen. Um ein paar Beispiele zu sammeln, kannst du dir sogar mehrere Fallstudien auf der offiziellen Website von dbt anschauen oder dir Ideen aus öffentlichen dbt-Projekten auf Git holen.
Wir haben ein breites Spektrum an grundlegenden bis fortgeschrittenen DBT-Interviewfragen abgedeckt, die dir bei deiner Jobsuche helfen werden. Wenn du weißt, wie man dbt mit Cloud-Data-Warehouses verbindet, hast du echt gute Kenntnisse in der Datenumwandlung, was der Kern jedes Datenintegrationsprozesses ist.
DBT und SQL zu lernen geht aber echt gut zusammen. Also, wenn du noch nicht so viel mit SQL zu tun hattest, schau dir mal die SQL-Kurse von DataCamp an.
Lerne mit diesen Kursen mehr über Data Engineering!
Lernpfad
Kurs
Kurs
Blog
Hesam Sheikh Hassani
15 Min.
Blog
Nisha Arya Ahmed
15 Min.
Blog
Matt Crabtree
14 Min.
Blog
Nathaniel Taylor-Leach
Blog