
Tracks
Kỹ sư dữ liệu chuyên nghiệp trong Python
40 giờ
dbt (data build tool) đã trở thành một khung phát triển được sử dụng rộng rãi trong các quy trình kỹ thuật dữ liệu và phân tích hiện đại. Trước đây, nhà phân tích dữ liệu chủ yếu phụ thuộc vào kỹ sư dữ liệu để viết các phép biến đổi bằng SQL. Nhưng với dbt, họ có thể tự viết biến đổi và kiểm soát dữ liệu tốt hơn. Công cụ này cũng tích hợp với các hệ thống quản lý phiên bản phổ biến như Git, giúp cải thiện cộng tác trong nhóm.
Nếu bạn đang chuẩn bị cho các vị trí kho dữ liệu như kỹ sư dữ liệu, nhà phân tích dữ liệu hoặc nhà khoa học dữ liệu, bạn cần nắm vững cả câu hỏi dbt cơ bản và nâng cao!
Trong bài viết này, tôi đã tổng hợp những câu hỏi phỏng vấn thường gặp nhất để xây dựng khái niệm nền tảng và kỹ năng giải quyết vấn đề nâng cao của bạn.
dbt là một khung chuyển đổi dữ liệu mã nguồn mở cho phép bạn biến đổi dữ liệu, kiểm thử độ chính xác và theo dõi thay đổi trong cùng một nền tảng. Khác với các công cụ ETL (extract, transform, load) khác, dbt chỉ đảm nhiệm phần chuyển đổi (T).
Một số công cụ ETL khác trích xuất dữ liệu từ nhiều nguồn, biến đổi bên ngoài kho dữ liệu rồi mới nạp lại. Điều này thường đòi hỏi kiến thức lập trình chuyên biệt và công cụ bổ sung. Nhưng dbt giúp dễ dàng hơn — cho phép thực hiện chuyển đổi ngay trong kho dữ liệu chỉ với SQL.
Hơn 40.000 công ty lớn sử dụng dbt để tối ưu dữ liệu — vì vậy nhà tuyển dụng liệt kê đây là một trong những kỹ năng quan trọng cho các vai trò liên quan đến dữ liệu. Nếu bạn thành thạo công cụ này ngay cả ở cấp độ người mới, cơ hội nghề nghiệp sẽ rộng mở!
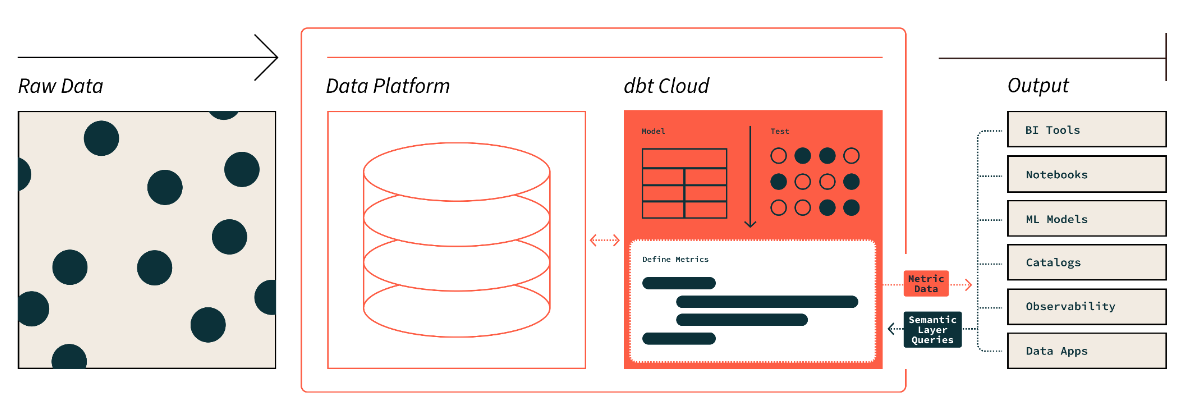
Lớp ngữ nghĩa của dbt. Nguồn ảnh: dbt
Ở đầu vòng phỏng vấn, nhà tuyển dụng sẽ kiểm tra kiến thức nền tảng của bạn. Họ có thể hỏi những câu hỏi cơ sở như sau:
dbt đưa đội ngũ dữ liệu lên cùng một mặt bằng, nơi họ có thể biến đổi, ghi chú và kiểm thử dữ liệu. Nó giúp đảm bảo dữ liệu đáng tin cậy và dễ hiểu. Các cách sử dụng phổ biến của dbt gồm:
Không, dbt không phải là ngôn ngữ lập trình. Đây là công cụ hỗ trợ các tác vụ chuyển đổi dữ liệu trong kho dữ liệu. Nếu bạn biết viết SQL, bạn có thể làm việc với dbt dễ dàng. dbt cũng đã bắt đầu hỗ trợ Python cho một số tác vụ cụ thể. Nhưng cốt lõi vẫn là quản lý và chạy các phép biến đổi dựa trên SQL.
dbt và Spark phục vụ các mục đích khác nhau và nhắm tới các loại quy trình làm việc khác nhau. Dưới đây là so sánh vai trò của chúng trong hạ tầng dữ liệu:
|
Tính năng |
dbt |
Spark |
|
Vai trò |
Biến đổi và mô hình hóa dữ liệu dựa trên SQL |
Xử lý dữ liệu phân tán và phân tích |
|
Ngôn ngữ lõi |
Ưu tiên SQL, có hỗ trợ Python hạn chế |
Hỗ trợ SQL, Python, Scala, Java, R |
|
Quản trị dữ liệu |
Hỗ trợ tài liệu hóa và truy vết nguồn gốc |
Cung cấp kiểm soát truy cập, kiểm toán và truy vết dữ liệu |
|
Người dùng mục tiêu |
Người dùng SQL, nhà phân tích, và các nhóm không chuyên kỹ thuật |
Kỹ sư dữ liệu, nhà khoa học dữ liệu, lập trình viên |
|
Độ phức tạp chuyển đổi |
Chỉ tập trung vào chuyển đổi và mô hình hóa bằng SQL |
Có thể xử lý phép biến đổi phức tạp với các ngôn ngữ khác |
|
Kiểm thử và xác thực |
Có khả năng kiểm thử tích hợp |
Cần chiến lược kiểm thử tùy chỉnh (đơn vị và tích hợp) |
Mặc dù dbt mang lại nhiều giá trị cho đội ngũ dữ liệu, nó cũng có thể phát sinh thách thức, đặc biệt khi quy mô và độ phức tạp tăng lên. Một số thách thức thường gặp gồm:
Biết cách vượt qua các thách thức tiềm ẩn trên là điều nhà tuyển dụng tìm kiếm, nên đừng xem nhẹ câu hỏi này.
Có hai phiên bản chính của dbt:
dbt Core là phiên bản miễn phí và mã nguồn mở, cho phép người dùng viết, chạy và quản lý các phép biến đổi dựa trên SQL cục bộ. Nó cung cấp giao diện dòng lệnh (CLI) để thực thi dự án dbt, kiểm thử mô hình và xây dựng pipeline dữ liệu. Vì là mã nguồn mở, dbt Core yêu cầu người dùng tự xử lý triển khai, điều phối và thiết lập hạ tầng, thường tích hợp với các công cụ như Airflow hoặc Kubernetes để tự động hóa.
dbt Cloud là dịch vụ được quản lý bởi nhà sáng lập dbt (Fishtown Analytics). Nó cung cấp toàn bộ khả năng của dbt Core, kèm các tính năng bổ sung như giao diện web, lập lịch tích hợp, quản lý job và công cụ cộng tác. dbt Cloud cũng bao gồm tính năng CI/CD (tích hợp liên tục và triển khai liên tục) tích hợp sẵn, truy cập API, và tuân thủ bảo mật nâng cao như SOC 2 và HIPAA cho các tổ chức có yêu cầu bảo mật nghiêm ngặt.
Sau khi đã qua phần cơ bản, dưới đây là một số câu hỏi dbt mức trung cấp, tập trung vào các khía cạnh và khái niệm kỹ thuật cụ thể.
Trong dbt, sources là các bảng dữ liệu thô. Ta không viết truy vấn SQL trực tiếp trên các bảng thô này — mà chỉ định schema và tên bảng rồi định nghĩa chúng là nguồn. Cách này giúp tham chiếu đối tượng dữ liệu trong bảng dễ hơn.
Giả sử bạn có bảng dữ liệu thô tên orders trong schema sales. Thay vì truy vấn trực tiếp, bạn sẽ định nghĩa nó là nguồn trong dbt như sau:
Định nghĩa source trong tệp sources.yml:
version: 2
sources:
- name: sales
tables:
- name: ordersDùng source trong các model dbt:
Khi đã định nghĩa, bạn có thể tham chiếu bảng thô orders trong các phép biến đổi như sau:
SELECT *
FROM {{ source('sales', 'orders') }}Cách tiếp cận này trừu tượng hóa định nghĩa bảng thô, giúp quản lý dễ hơn và nếu cấu trúc bảng bên dưới thay đổi, bạn chỉ cần cập nhật một nơi (định nghĩa source) thay vì mọi truy vấn.
Lợi ích khi dùng sources trong dbt:
Một model dbt về cơ bản là một tệp SQL hoặc Python định nghĩa logic biến đổi cho dữ liệu thô. Trong dbt, model là thành phần lõi nơi bạn viết các phép biến đổi, dù là tổng hợp, join hay bất kỳ thao tác xử lý dữ liệu nào.
SELECT để định nghĩa biến đổi và được lưu dưới dạng tệp .sql..py và cho phép bạn dùng các thư viện như pandas để xử lý dữ liệu.Ví dụ model SQL:
Một model SQL biến đổi dữ liệu thô bằng truy vấn SQL. Ví dụ, để tạo bản tóm tắt đơn hàng từ bảng orders:
--orders_summary.sql
WITH orders_cte AS (
SELECT
customer_id,
COUNT(order_id) AS total_orders,
SUM(order_amount) AS total_revenue
FROM {{ ref('orders') }}
GROUP BY customer_id
)
SELECT *
FROM orders_cteTrong ví dụ này:
orders_summary.sql tạo tóm tắt tổng số đơn hàng và doanh thu cho mỗi khách hàng bằng SQL.orders (đã được định nghĩa là model hoặc source trong dbt).Ví dụ model Python:
Một model Python xử lý dữ liệu thô bằng mã Python. Đặc biệt hữu ích cho logic phức tạp mà viết bằng SQL sẽ cồng kềnh.
# orders_summary.py
import pandas as pd
def model(dbt, session):
# Load the source data
orders = dbt.ref("orders").to_pandas()
# Perform transformations using pandas
orders_summary = orders.groupby('customer_id').agg(
total_orders=('order_id', 'count'),
total_revenue=('order_amount', 'sum')
).reset_index()
return orders_summaryTrong ví dụ này:
Cách tạo một model dbt:
models của dự án dbt. .sql trong thư mục (hoặc .py nếu là model Python).dbt run để áp dụng biến đổi và tạo model.dbt quản lý phụ thuộc model bằng hàm ref(), tạo chuỗi phụ thuộc rõ ràng giữa các model.
Khi định nghĩa một phép biến đổi trong dbt, thay vì tham chiếu trực tiếp các bảng trong kho dữ liệu, bạn tham chiếu các model dbt khác bằng hàm ref(). Điều này đảm bảo dbt xây các model theo đúng thứ tự, dựa trên phụ thuộc.
Ví dụ, nếu bạn có model orders_summary phụ thuộc vào model orders, bạn sẽ định nghĩa như sau:
WITH orders AS (
SELECT * FROM {{ ref('orders') }}
)
SELECT
customer_id,
COUNT(order_id) AS total_orders,
SUM(order_amount) AS total_revenue
FROM orders
GROUP BY customer_idTrong ví dụ này, hàm {{ ref('orders') }} đảm bảo model orders được xây trước orders_summary, vì orders_summary phụ thuộc vào dữ liệu trong orders .
Macro trong dbt là các khối mã SQL có thể tái sử dụng, được viết bằng Jinja templating. Chúng cho phép bạn tự động hóa tác vụ lặp lại, trừu tượng hóa logic phức tạp, và tái sử dụng mã SQL trên nhiều model, giúp dự án dbt hiệu quả và dễ bảo trì hơn.
Macro có thể được định nghĩa trong các tệp .sql nằm trong thư mục macros của dự án dbt.
Macro đặc biệt hữu ích khi bạn cần thực hiện các biến đổi tương tự trên nhiều model hoặc cần logic phụ thuộc môi trường, như dùng schema khác nhau hay thay đổi định dạng ngày theo môi trường triển khai (ví dụ: development, staging, production).
Ví dụ tạo macro:
-- macros/date_format.sql
{% macro format_date(column) %}
FORMAT_TIMESTAMP('%Y-%m-%d', {{ column }})
{% endmacro %}Cách dùng trong model:
SELECT
customer_id,
{{ format_date('order_date') }} AS formatted_order_date
FROM {{ ref('orders') }}Trong ví dụ này, macro format_date được dùng để chuẩn hóa định dạng cột order_date trong bất kỳ model nào gọi nó.
-- macros/custom_schema.sql
{% macro custom_schema_name() %}
{% if target.name == 'prod' %}
'production_schema'
{% else %}
'dev_schema'
{% endif %}
{% endmacro %}Cách dùng trong model:
SELECT *
FROM {{ custom_schema_name() }}.ordersỞ đây, macro kiểm tra nếu môi trường (target.name) là "prod" và trả về tên schema phù hợp.
Cách chạy macro:
Macro không chạy trực tiếp như model SQL. Thay vào đó, chúng được tham chiếu trong model hoặc macro khác và sẽ được thực thi khi dự án dbt chạy. Ví dụ, nếu bạn dùng macro trong một model, macro sẽ chạy khi bạn thực hiện lệnh dbt run.
dbt run-operation. Thường dùng cho tác vụ đơn lẻ như seed dữ liệu hoặc bảo trì.Singular test và generic test là hai loại kiểm thử trong dbt:
Ví dụ: Giả sử bạn muốn đảm bảo không có đơn hàng nào có order_amount âm. Bạn có thể viết singular test trong thư mục tests như sau:
-- tests/no_negative_order_amount.sql
SELECT *
FROM {{ ref('orders') }}
WHERE order_amount < 0Nếu kiểm thử này thất bại, dbt sẽ trả về tất cả các dòng trong bảng orders nơi order_amount là âm.
|
Generic tests |
Định nghĩa |
|
Unique |
Kiểm tra tính duy nhất của giá trị trong cột. |
|
Not null |
Kiểm tra các trường rỗng. |
|
Available values |
Xác minh các giá trị cột khớp với danh sách giá trị kỳ vọng để duy trì chuẩn hóa. |
|
Relationships |
Kiểm tra tính toàn vẹn tham chiếu giữa các bảng để loại bỏ dữ liệu không nhất quán. |
Ví dụ: Bạn có thể áp dụng generic test để đảm bảo customer_id trong bảng customers là duy nhất và không rỗng bằng cách định nghĩa trong tệp schema.yml:
version: 2
models:
- name: customers
columns:
- name: customer_id
tests:
- unique
- not_nullTrong ví dụ này:
customer_id trong bảng customers là duy nhất.customer_id bị thiếu hoặc null.Khi tiến xa hơn, bạn có thể gặp các tình huống phức tạp và khái niệm nâng cao. Dưới đây là một số câu hỏi thử thách để đánh giá chuyên môn và chuẩn bị cho vị trí kỹ sư dữ liệu cấp cao.
Incremental model trong dbt được dùng để chỉ xử lý dữ liệu mới hoặc đã thay đổi thay vì xử lý lại toàn bộ tập dữ liệu mỗi lần chạy. Điều này đặc biệt hữu ích với bộ dữ liệu lớn, nơi việc dựng lại model từ đầu sẽ tốn thời gian và tài nguyên.
Incremental model cho phép dbt chỉ bổ sung dữ liệu mới (hoặc cập nhật dữ liệu thay đổi) dựa trên điều kiện, thường là cột timestamp (như updated_at).
Cách tạo incremental model:
1. Định nghĩa model là incremental trong phần config của model:
{{ config(
materialized='incremental',
unique_key='id' -- hoặc một cột duy nhất khác
) }}2. Dùng hàm is_incremental() để lọc các dòng mới hoặc thay đổi:
SELECT *
FROM source_table
{% if is_incremental() %}
WHERE updated_at > (SELECT MAX(updated_at) FROM {{ this }})
{% endif %}3. Khi dbt chạy model lần đầu, nó sẽ xử lý toàn bộ dữ liệu. Các lần sau, nó chỉ xử lý những dòng có updated_at lớn hơn giá trị mới nhất đã có trong model.
Khi nào dùng incremental model:
Jinja giúp SQL linh hoạt hơn. Với Jinja, ta có thể định nghĩa mẫu tái sử dụng cho các mẫu SQL thường gặp. Và khi yêu cầu thay đổi, ta dùng câu lệnh if của Jinja để điều chỉnh truy vấn theo điều kiện. Làm vậy thường giúp chia nhỏ logic phức tạp, dễ hiểu hơn.
Ví dụ, nếu bạn muốn chuyển định dạng ngày từ "YYYY-MM-DD" sang "MM/DD/YYYY", đây là một macro dbt mẫu, chúng ta đã thấy ở câu trước:
{% macro change_date_format(column_name) %}
to_char({{ column_name }}::date, 'MM/DD/YYYY')
{% endmacro %}Trong ví dụ, {{ column_name }} là nơi Jinja chèn tên cột thực tế khi bạn dùng macro. Nó sẽ được thay thế bằng tên cột khi chạy. Như đã thấy, Jinja dùng {{ }} để hiển thị nơi diễn ra thao tác thay thế.
Cách tạo materialization tùy chỉnh trong dbt:
materialization_name: {% materialization materialization_name, default -%}adapter.get_relation để thiết lập bảng đích. Đây là nơi dữ liệu sẽ được nạp. {% set sql %}
SELECT * FROM {{ ref('your_source_table') }}
WHERE your_conditions = true
{% endset %}
{{ adapter.execute(sql) }}{{ return(target_relation) }}
{% endmaterialization %}Dưới đây là hai cách để debug model dbt:
1. Truy cập các tệp SQL đã biên dịch trong thư mục target để xác định và lần vết lỗi.
Khi bạn chạy dự án dbt, dbt biên dịch model (viết bằng Jinja) thành truy vấn SQL thuần và lưu trong thư mục target. Đây chính là SQL được chạy trên nền tảng dữ liệu, nên xem các tệp này giúp bạn xác định vấn đề ở đâu:
dbt run hoặc dbt test).target/compiled/ trong dự án dbt.2. Dùng dbt Power User Extension cho VS Code để xem kết quả truy vấn trực tiếp.
Tiện ích dbt Power User cho Visual Studio Code (VS Code) là công cụ hữu ích để debug model dbt. Tiện ích cho phép bạn xem và thử nghiệm truy vấn ngay trong IDE, giảm nhu cầu chuyển qua lại giữa dbt, terminal và cơ sở dữ liệu.
dbt biên dịch truy vấn qua các bước sau:
target/compiled.dbt run, truy vấn được chuẩn bị để thực thi, có thể với phần bao bọc bổ sung.Quy trình này chuyển SQL mô-đun, có template thành các truy vấn thực thi cụ thể cho kho dữ liệu của bạn. Ta có thể dùng dbt compile hoặc xem thư mục target/compiled để xem và debug SQL cuối cùng cho từng model.
Công việc của hầu hết kỹ sư dữ liệu xoay quanh xây dựng và tích hợp kho dữ liệu với dbt. Các câu hỏi liên quan đến kịch bản này rất phổ biến trong phỏng vấn — vì vậy tôi đã tổng hợp những câu thường gặp nhất:
Tích hợp dbt với Airflow giúp xây dựng pipeline dữ liệu trơn tru. Một vài lợi ích gồm:
Lớp ngữ nghĩa của dbt cho phép ta chuyển dữ liệu thô thành ngôn ngữ nghiệp vụ dễ hiểu. Ta có thể định nghĩa metric và truy vấn chúng bằng giao diện dòng lệnh (CLI).
Điều này giúp tối ưu chi phí vì thời gian chuẩn bị dữ liệu giảm. Ngoài ra, mọi người làm việc với cùng định nghĩa dữ liệu, giúp metric nhất quán trong toàn tổ chức.
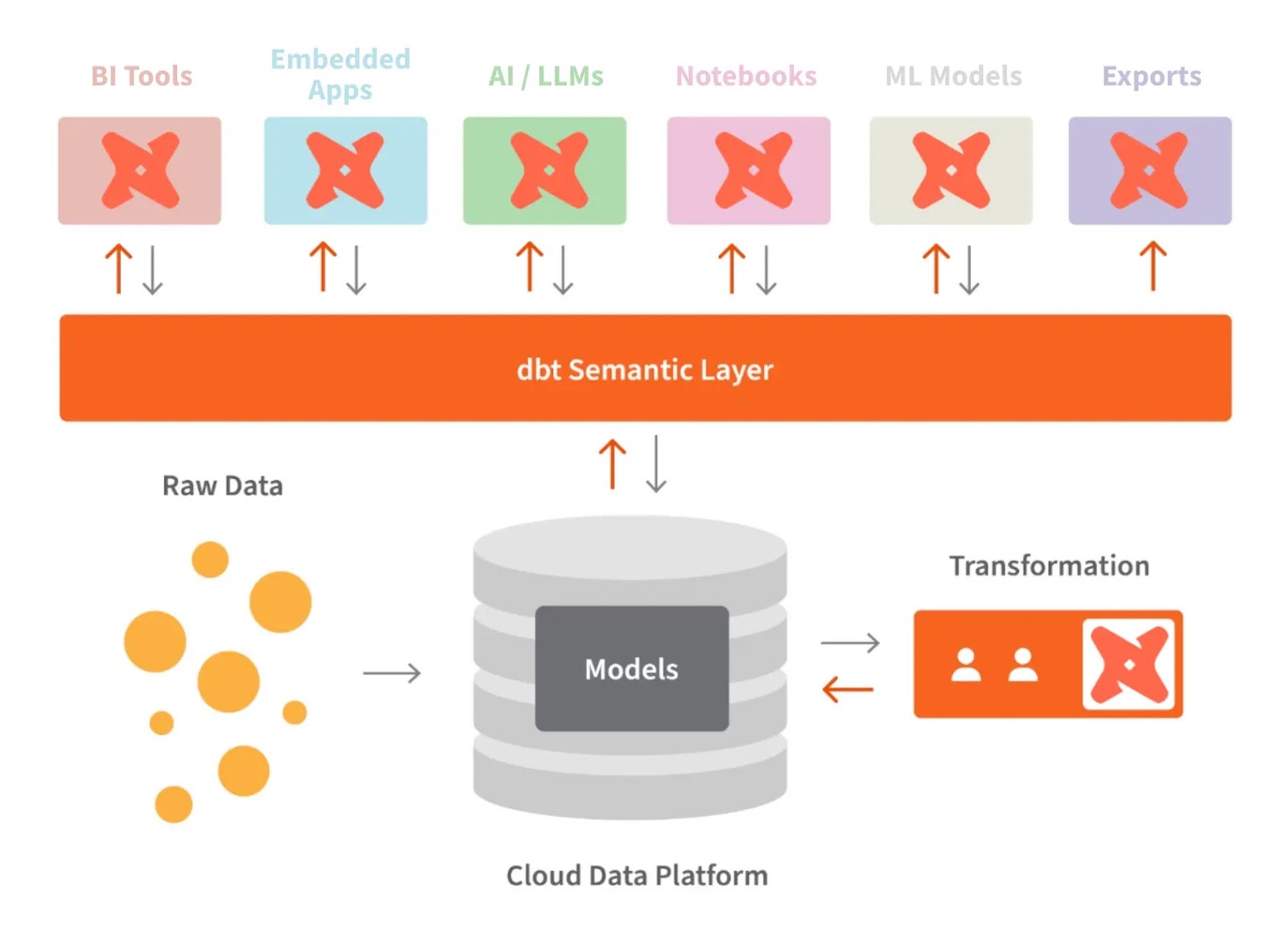
dbt và lớp ngữ nghĩa. Nguồn ảnh: dbt
Dù BigQuery rất hữu ích và xử lý được nhiều biến đổi gốc, dbt vẫn cần thiết. Lý do:
ref() và macro của dbt giúp SQL mô-đun và tái sử dụng hơn.dbt có hai phiên bản: dbt Core và dbt Cloud như đã nêu. dbt Core là mã nguồn mở và miễn phí, vì vậy không cung cấp tính năng bảo mật tích hợp; người dùng chịu trách nhiệm triển khai và bảo mật.
Trong khi đó, dbt Cloud được thiết kế để cung cấp bảo mật đầy đủ. Nó tuân thủ HIPAA và các chuẩn thông dụng khác để bảo đảm quyền riêng tư. Tùy nhu cầu, ta chọn phiên bản dbt phù hợp với yêu cầu tuân thủ của doanh nghiệp.
Tối ưu biến đổi dbt cho bộ dữ liệu lớn là điều quan trọng để cải thiện hiệu năng và giảm chi phí, đặc biệt khi làm việc với kho dữ liệu đám mây như Snowflake, BigQuery hoặc Redshift. Dưới đây là các kỹ thuật chính:
1. Dùng incremental model
Incremental model cho phép dbt chỉ xử lý dữ liệu mới/cập nhật thay vì xử lý lại toàn bộ mỗi lần. Điều này cắt giảm đáng kể thời gian chạy cho bộ dữ liệu lớn. Nó giới hạn lượng dữ liệu cần xử lý, tăng tốc biến đổi.
2. Tận dụng partitioning và clustering (cho các CSDL như Snowflake và BigQuery)
Partitioning và clustering các bảng lớn giúp cải thiện hiệu năng truy vấn bằng cách tổ chức dữ liệu hợp lý và giảm lượng dữ liệu bị quét.
Partitioning đảm bảo chỉ phân vùng liên quan được truy vấn, còn clustering tối ưu bố cục vật lý dữ liệu để truy xuất nhanh hơn.
3. Tối ưu materialization (table, view, incremental)
Chọn materialization phù hợp để tối ưu hiệu năng:
4. Dùng LIMIT trong quá trình phát triển
Khi phát triển, thêm mệnh đề LIMIT để giới hạn số dòng xử lý. Việc này tăng tốc vòng lặp phát triển và tránh làm việc với dữ liệu khổng lồ khi thử nghiệm.
5. Chạy truy vấn song song
Tận dụng khả năng chạy song song của kho dữ liệu. Ví dụ, dbt Cloud hỗ trợ parallelism có thể điều chỉnh theo hạ tầng.
6. Dùng tính năng tối ưu đặc thù của CSDL
Nhiều kho dữ liệu đám mây cung cấp tính năng tối ưu hiệu năng như:
Để tối ưu lượt chạy dbt trong Snowflake:
1. Dùng clustering cho bảng:
{{ config(
cluster_by = ["date_column", "category_column"]
) }}
SELECT ...2. Tận dụng multi-cluster warehouse của Snowflake để chạy model song song:
models:
my_project:
materialized: table
snowflake_warehouse: transforming_wh3. Dùng incremental model khi phù hợp:
{{ config(materialized='incremental', unique_key='id') }}
SELECT *
FROM source_table
{% if is_incremental() %}
WHERE updated_at > (SELECT MAX(updated_at) FROM {{ this }})
{% endif %}Các tối ưu này có thể cải thiện hiệu năng và chi phí khi chạy dbt trên Snowflake.
Ở cuối quá trình phỏng vấn, nhà tuyển dụng thường kiểm tra kỹ năng giải quyết vấn đề của bạn. Họ có thể hỏi những câu để xem bạn phản ứng thế nào với tình huống thực tế.
Hãy nhớ câu nói sau về kỹ năng mềm cần có cho vai trò này của Deepak Goyal, CEO & Nhà sáng lập Azurelib Academy, khi anh chia sẻ trên podcast DataFramed:
Là một Kỹ sư Dữ liệu, bạn cần giao tiếp tốt. Kỹ sư dữ liệu phải giao tiếp vì họ cần trao đổi với nhiều bên liên quan để hiểu họ mong muốn đầu ra hay kết quả như thế nào.
Deepak Goya, CEO & Founder at Azurelib Academy
Khám phá thêm về kỹ thuật dữ liệu với các khóa học này!
Tracks
Courses
Courses