
Program
Insinyur Data Profesional dalam Python
40 Hr
dbt (data build tool) telah menjadi kerangka kerja pengembangan yang banyak digunakan dalam alur kerja rekayasa data dan analitik modern. Analis data umumnya bergantung pada data engineer untuk menulis transformasi dalam SQL. Namun dengan dbt, mereka dapat menulis transformasi dan memiliki kontrol lebih besar atas data. dbt juga memungkinkan integrasi dengan sistem kontrol versi populer seperti Git, yang meningkatkan kolaborasi tim.
Jika Anda sedang mempersiapkan diri untuk peran gudang data, seperti data engineer, data analyst, atau data scientist, Anda harus menguasai pertanyaan dbt dasar dan lanjutan!
Dalam artikel ini, saya merangkum pertanyaan wawancara yang paling sering diajukan untuk membangun konsep dasar dan keterampilan pemecahan masalah tingkat lanjut Anda.
dbt adalah kerangka kerja transformasi data open-source yang memungkinkan Anda mentransformasi data, mengujinya untuk akurasi, dan melacak perubahan dalam satu platform. Berbeda dengan alat ETL (extract, transform, load) lainnya, dbt hanya melakukan bagian transformasi (T).
Beberapa alat ETL lain mengekstrak data dari berbagai sumber, mentransformasikannya di luar gudang data, lalu memuatnya kembali. Ini sering membutuhkan pengetahuan pengkodean khusus dan alat tambahan. Namun dbt membuatnya lebih mudah — dbt memungkinkan transformasi di dalam gudang data hanya dengan SQL.
Lebih dari 40.000 perusahaan besar menggunakan dbt untuk merampingkan data — sehingga perekrut mencantumkannya sebagai salah satu keterampilan terpenting untuk peran terkait data. Jadi, jika Anda menguasainya bahkan sebagai praktisi data pemula, ini bisa membuka banyak peluang karier!
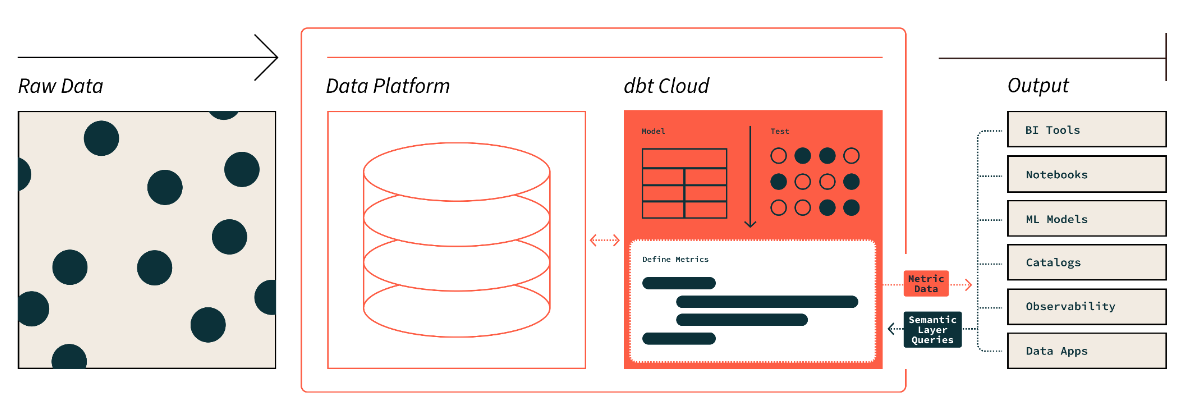
Lapisan semantik dbt. Sumber gambar: dbt
Pewawancara akan menguji pengetahuan dasar Anda di awal proses. Untuk itu, mereka mungkin menanyakan beberapa pertanyaan fondasional seperti berikut:
dbt menyatukan tim data pada satu halaman, tempat mereka dapat mentransformasi, mendokumentasikan, dan menguji data. Ini membantu memastikan data andal dan mudah dipahami. Kegunaan umum dbt meliputi:
Bukan, dbt bukan bahasa pemrograman. Ini adalah alat yang membantu pekerjaan transformasi data di dalam gudang data. Jika Anda tahu cara menulis SQL, Anda dapat dengan mudah bekerja dengan dbt. dbt juga mulai mendukung Python untuk tugas-tugas tertentu. Namun pada intinya, dbt mengelola dan menjalankan transformasi berbasis SQL.
dbt dan Spark memiliki tujuan berbeda dan menargetkan jenis alur kerja yang berbeda. Berikut perbandingan perannya dalam infrastruktur data:
|
Fitur |
dbt |
Spark |
|
Peran |
Transformasi dan pemodelan data berbasis SQL |
Pemrosesan data terdistribusi dan analitik |
|
Bahasa inti |
Utamanya SQL, dengan dukungan Python terbatas |
Mendukung SQL, Python, Scala, Java, R |
|
Tata kelola data |
Dukungan dokumentasi dan lineage |
Menyediakan kontrol akses, audit, dan data lineage |
|
Pengguna sasaran |
Pengguna SQL, analis, dan tim tanpa keahlian engineering |
Data engineer, data scientist, developer |
|
Kompleksitas transformasi |
Hanya fokus pada transformasi dan pemodelan SQL |
Dapat menangani transformasi kompleks dalam bahasa lain juga |
|
Pengujian dan validasi |
Memiliki kapabilitas pengujian bawaan |
Memerlukan strategi pengujian kustom (unit dan integrasi) |
Meskipun dbt membawa banyak nilai bagi tim data, dbt juga dapat menimbulkan tantangan, terutama saat skala dan kompleksitas meningkat. Beberapa tantangan paling umum adalah:
Mengetahui cara mengatasi tantangan potensial di atas adalah sesuatu yang dicari pemberi kerja, jadi jangan abaikan pentingnya pertanyaan ini.
Ada dua versi utama dbt:
dbt Core adalah versi dbt yang gratis dan open-source yang memungkinkan pengguna menulis, menjalankan, dan mengelola transformasi berbasis SQL secara lokal. dbt Core menyediakan antarmuka baris perintah (CLI) untuk mengeksekusi proyek dbt, menguji model, dan membangun pipeline data. Karena open-source, dbt Core mengharuskan pengguna menangani deployment, orkestrasi, dan penyiapan infrastrukturnya sendiri, biasanya mengintegrasikan dengan alat seperti Airflow atau Kubernetes untuk otomatisasi.
dbt Cloud, di sisi lain, adalah layanan terkelola yang disediakan oleh pembuat dbt (Fishtown Analytics). Ia menawarkan semua kapabilitas dbt Core, bersama fitur tambahan seperti antarmuka berbasis web, penjadwalan terintegrasi, manajemen job, dan alat kolaborasi. dbt Cloud juga mencakup fitur CI/CD bawaan (continuous integration dan deployment), akses API, serta kepatuhan keamanan yang ditingkatkan seperti SOC 2 dan HIPAA untuk organisasi dengan kebutuhan keamanan yang lebih ketat.
Setelah membahas pertanyaan dbt dasar, berikut beberapa pertanyaan dbt tingkat menengah. Pertanyaan ini berfokus pada aspek teknis dan konsep spesifik.
Dalam dbt, sources adalah tabel data mentah. Kita tidak langsung menulis kueri SQL pada tabel mentah tersebut — kita menentukan skema dan nama tabel lalu mendefinisikannya sebagai source. Ini memudahkan untuk merujuk objek data dalam tabel.
Bayangkan Anda memiliki tabel data mentah di basis data bernama orders dalam skema sales. Alih-alih mengkueri tabel ini secara langsung, Anda akan mendefinisikannya sebagai source di dbt seperti ini:
Definisikan source di file sources.yml Anda:
version: 2
sources:
- name: sales
tables:
- name: ordersGunakan source tersebut dalam model dbt Anda:
Setelah didefinisikan, Anda dapat merujuk tabel mentah orders dalam transformasi seperti ini:
SELECT *
FROM {{ source('sales', 'orders') }}Pendekatan ini mengabstraksi definisi tabel mentah, sehingga lebih mudah dikelola dan memastikan bahwa jika struktur tabel yang mendasarinya berubah, Anda dapat memperbaruinya di satu tempat (definisi source) alih-alih di setiap kueri.
Manfaat menggunakan sources di dbt:
Model dbt pada dasarnya adalah file SQL atau Python yang mendefinisikan logika transformasi untuk data mentah. Dalam dbt, model adalah komponen inti tempat Anda menulis transformasi, baik agregasi, join, maupun manipulasi data apa pun.
SELECT untuk mendefinisikan transformasi dan disimpan sebagai file .sql..py dan memungkinkan Anda menggunakan pustaka Python seperti pandas untuk memanipulasi data.Contoh model SQL:
Model SQL mentransformasi data mentah menggunakan kueri SQL. Misalnya, untuk membuat ringkasan pesanan dari tabel orders:
--orders_summary.sql
WITH orders_cte AS (
SELECT
customer_id,
COUNT(order_id) AS total_orders,
SUM(order_amount) AS total_revenue
FROM {{ ref('orders') }}
GROUP BY customer_id
)
SELECT *
FROM orders_cteDalam contoh ini:
orders_summary.sql membuat ringkasan total pesanan dan pendapatan untuk setiap pelanggan menggunakan SQL.orders (yang sudah didefinisikan sebagai model atau source dbt).Contoh model Python:
Model Python memanipulasi data mentah menggunakan kode Python. Ini sangat membantu untuk logika kompleks yang mungkin merepotkan jika ditulis dalam SQL.
# orders_summary.py
import pandas as pd
def model(dbt, session):
# Load the source data
orders = dbt.ref("orders").to_pandas()
# Perform transformations using pandas
orders_summary = orders.groupby('customer_id').agg(
total_orders=('order_id', 'count'),
total_revenue=('order_amount', 'sum')
).reset_index()
return orders_summaryDalam contoh ini:
Berikut cara membuat model dbt:
models pada proyek dbt. .sql di dalam direktori (atau .py jika model Python).dbt run untuk menerapkan transformasi dan membuat model.dbt mengelola dependensi model menggunakan fungsi ref(), yang menciptakan rantai dependensi yang jelas antar model.
Saat Anda mendefinisikan transformasi di dbt, alih-alih merujuk tabel secara langsung di gudang data, Anda merujuk model dbt lain menggunakan fungsi ref(). Ini memastikan dbt membangun model dalam urutan yang benar dengan mengidentifikasi model mana yang bergantung pada model lain.
Misalnya, jika Anda memiliki model orders_summary yang bergantung pada model orders, Anda akan mendefinisikannya seperti ini:
WITH orders AS (
SELECT * FROM {{ ref('orders') }}
)
SELECT
customer_id,
COUNT(order_id) AS total_orders,
SUM(order_amount) AS total_revenue
FROM orders
GROUP BY customer_idDalam contoh ini, fungsi {{ ref('orders') }} memastikan model orders dibangun sebelum orders_summary, karena orders_summary bergantung pada data dalam model orders tersebut.
Macro dalam dbt adalah blok kode SQL yang dapat digunakan kembali dan ditulis menggunakan mesin templating Jinja. Macro memungkinkan Anda mengotomatisasi tugas berulang, mengabstraksi logika kompleks, dan menggunakan kembali kode SQL di banyak model, sehingga proyek dbt Anda lebih efisien dan mudah dipelihara.
Macro dapat didefinisikan dalam file .sql di direktori macros proyek dbt Anda.
Macro sangat berguna saat Anda perlu melakukan transformasi serupa di banyak model atau memerlukan logika spesifik lingkungan, seperti menggunakan skema berbeda atau mengubah format tanggal berdasarkan lingkungan deployment (misalnya, development, staging, atau production).
Contoh membuat macro:
-- macros/date_format.sql
{% macro format_date(column) %}
FORMAT_TIMESTAMP('%Y-%m-%d', {{ column }})
{% endmacro %}Penggunaan dalam model:
SELECT
customer_id,
{{ format_date('order_date') }} AS formatted_order_date
FROM {{ ref('orders') }}Dalam contoh ini, macro format_date digunakan untuk menstandarkan format kolom order_date di model mana pun tempat macro tersebut dipanggil.
-- macros/custom_schema.sql
{% macro custom_schema_name() %}
{% if target.name == 'prod' %}
'production_schema'
{% else %}
'dev_schema'
{% endif %}
{% endmacro %}Penggunaan dalam model:
SELECT *
FROM {{ custom_schema_name() }}.ordersDi sini, macro memeriksa apakah lingkungan (target.name) adalah "prod" dan mengembalikan nama skema yang tepat berdasarkan hal tersebut.
Cara menjalankan macro:
Macro tidak dijalankan secara langsung seperti model SQL. Sebaliknya, macro dirujuk dalam model Anda atau macro lain dan dieksekusi saat proyek dbt dijalankan. Misalnya, jika Anda menggunakan macro dalam model, macro akan dieksekusi saat Anda menjalankan perintah dbt run.
dbt run-operation. Ini biasanya digunakan untuk tugas satu kali, seperti seeding data atau melakukan operasi pemeliharaan.Singular tests dan generic tests adalah dua jenis pengujian di dbt:
Contoh: Misalkan Anda ingin memastikan tidak ada pesanan yang memiliki order_amount negatif. Anda dapat menulis singular test di direktori tests seperti berikut:
-- tests/no_negative_order_amount.sql
SELECT *
FROM {{ ref('orders') }}
WHERE order_amount < 0Jika pengujian ini gagal, dbt akan mengembalikan semua baris dari tabel orders tempat nilai order_amount negatif.
|
Generic tests |
Definisi |
|
Unique |
Memeriksa nilai unik dalam kolom. |
|
Not null |
Memeriksa adanya kolom kosong. |
|
Available values |
Memverifikasi bahwa nilai kolom sesuai dengan daftar nilai yang diharapkan untuk menjaga standarisasi. |
|
Relationships |
Memeriksa integritas referensial antar tabel untuk menghilangkan data yang tidak konsisten. |
Contoh: Anda dapat dengan mudah menerapkan generic test untuk memastikan customer_id di tabel customers bersifat unik dan tidak null dengan mendefinisikannya di file schema.yml Anda:
version: 2
models:
- name: customers
columns:
- name: customer_id
tests:
- unique
- not_nullDalam contoh ini:
customer_id di tabel customers adalah unik.customer_id yang hilang atau null.Seiring kemajuan, Anda mungkin akan menemui skenario yang lebih kompleks dan konsep yang lebih maju. Berikut beberapa pertanyaan wawancara menantang untuk mengukur keahlian Anda dan mempersiapkan posisi data engineering tingkat senior.
Model inkremental di dbt digunakan untuk hanya memproses data baru atau yang berubah alih-alih memproses ulang seluruh dataset setiap kali. Ini sangat berguna saat bekerja dengan dataset besar di mana membangun ulang seluruh model dari nol akan memakan waktu dan sumber daya.
Model inkremental memungkinkan dbt hanya menambahkan data baru (atau memperbarui data yang berubah) berdasarkan suatu kondisi, biasanya kolom timestamp (seperti updated_at).
Cara membuat model inkremental:
1. Definisikan model sebagai inkremental dengan menentukannya di config model:
{{ config(
materialized='incremental',
unique_key='id' -- atau kolom unik lain
) }}2. Gunakan fungsi is_incremental() untuk memfilter baris baru atau yang berubah:
SELECT *
FROM source_table
{% if is_incremental() %}
WHERE updated_at > (SELECT MAX(updated_at) FROM {{ this }})
{% endif %}3. Saat dbt menjalankan model ini untuk pertama kali, dbt akan memproses semua data. Untuk run berikutnya, dbt hanya akan memproses baris di mana updated_at lebih besar dari nilai terbaru yang sudah ada di model.
Kapan menggunakan model inkremental:
Jinja membuat kode SQL kita lebih fleksibel. Dengan Jinja, kita dapat mendefinisikan template yang dapat digunakan kembali untuk pola SQL umum. Dan karena kebutuhan sering berubah, kita dapat menggunakan pernyataan if Jinja untuk menyesuaikan kueri SQL sesuai kondisi. Hal ini biasanya meningkatkan kode SQL dengan memecah logika kompleks, sehingga lebih mudah dipahami.
Misalnya, jika Anda ingin mengonversi format tanggal dari "YYYY-MM-DD" ke "MM/DD/YYYY", berikut contoh macro dbt untuk ini, yang telah kita lihat di pertanyaan sebelumnya:
{% macro change_date_format(column_name) %}
to_char({{ column_name }}::date, 'MM/DD/YYYY')
{% endmacro %}Dalam contoh kode ini, {{ column_name }} adalah tempat Jinja menyisipkan nama kolom sebenarnya saat Anda menggunakan macro. Nama ini akan diganti dengan nama kolom aktual saat runtime. Seperti yang telah kita lihat pada contoh sebelumnya, Jinja menggunakan {{ }} untuk menunjukkan tempat penggantian akan terjadi.
Berikut cara membuat materialization kustom di dbt:
materialization_name: {% materialization materialization_name, default -%}adapter.get_relation untuk menyiapkan tabel target. Di sinilah data akan dimuat. {% set sql %}
SELECT * FROM {{ ref('your_source_table') }}
WHERE your_conditions = true
{% endset %}
{{ adapter.execute(sql) }}{{ return(target_relation) }}
{% endmaterialization %}Berikut dua cara untuk melakukan debug pada model dbt kita:
1. Akses file SQL terkompilasi di folder target untuk mengidentifikasi dan melacak kesalahan.
Saat Anda menjalankan proyek dbt, dbt mengompilasi model Anda (yang ditulis menggunakan templating Jinja) menjadi kueri SQL mentah dan menyimpannya di direktori target. SQL terkompilasi inilah yang dijalankan dbt pada platform data Anda, sehingga meninjau file ini dapat membantu Anda mengidentifikasi di mana masalah terjadi:
dbt run atau dbt test).target/compiled/ di direktori proyek dbt Anda.2. Gunakan Ekstensi dbt Power User untuk VS Code untuk meninjau hasil kueri secara langsung.
Ekstensi dbt Power User untuk Visual Studio Code (VS Code) adalah alat yang membantu untuk debugging model dbt. Ekstensi ini memungkinkan Anda meninjau dan menguji kueri langsung di dalam IDE, sehingga mengurangi kebutuhan untuk berpindah antara dbt, terminal, dan basis data Anda.
dbt mengompilasi kueri melalui langkah-langkah berikut:
target/compiled.dbt run, kueri disiapkan untuk eksekusi, berpotensi dengan pembungkus tambahan.Proses ini mengubah SQL modular dan bertemplate menjadi kueri yang dapat dieksekusi spesifik untuk gudang data Anda. Kita dapat menggunakan dbt compile atau memeriksa direktori target/compiled untuk melihat dan debug SQL final untuk setiap model.
Sebagian besar pekerjaan data engineer berkutat pada membangun dan mengintegrasikan gudang data dengan dbt. Pertanyaan terkait skenario ini sangat umum dalam wawancara — itulah mengapa saya mengumpulkan yang paling sering ditanyakan:
Mengintegrasikan dbt dengan Airflow membantu membangun pipeline data yang efisien. Berikut beberapa keuntungannya:
Semantic layer dbt memungkinkan kita menerjemahkan data mentah ke bahasa yang kita pahami. Kita juga dapat mendefinisikan metrik dan melakukan kueri melalui command line interface (CLI).
Ini memungkinkan kita mengoptimalkan biaya karena persiapan data memakan waktu lebih sedikit. Selain itu, semua orang bekerja dengan definisi data yang sama karena semantic layer membuat metrik konsisten di seluruh organisasi.
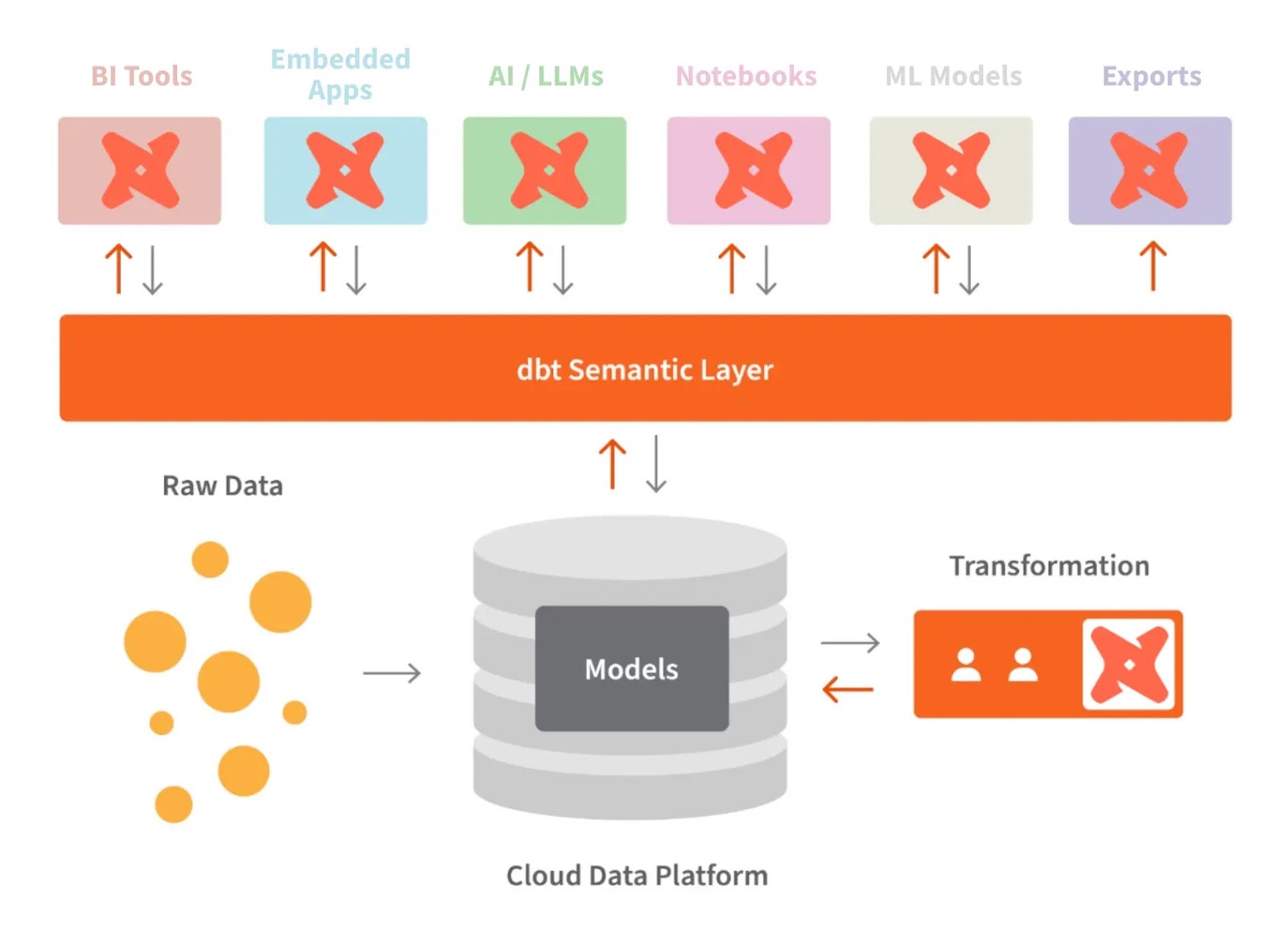
dbt dan semantic layer. Sumber gambar: dbt
Walaupun BigQuery sangat membantu dan dapat menangani banyak transformasi secara native, dbt tetap mungkin diperlukan. Alasannya:
ref() dan macro dbt memungkinkan kode SQL yang lebih modular dan dapat digunakan kembali.dbt hadir dalam dua versi: dbt Core dan dbt Cloud, seperti yang telah dibahas. dbt Core bersifat open source dan merupakan versi gratis. Karena itu, dbt Core tidak menawarkan fitur keamanan bawaan, dan pengguna bertanggung jawab atas deployment dan keamanannya.
Namun, dbt Cloud dirancang untuk menyediakan keamanan yang lengkap. dbt Cloud mematuhi HIPAA dan kerangka umum lainnya untuk memastikan privasi tidak terganggu. Jadi, tergantung kebutuhan, kita harus memilih versi dbt yang sesuai dengan kepatuhan bisnis kita.
Mengoptimalkan transformasi dbt untuk dataset besar sangat penting untuk meningkatkan kinerja dan mengurangi biaya, terutama saat berhadapan dengan gudang data berbasis cloud seperti Snowflake, BigQuery, atau Redshift. Berikut beberapa teknik kunci untuk mengoptimalkan kinerja dbt:
1. Gunakan model inkremental
Model inkremental memungkinkan dbt hanya memproses data baru atau yang diperbarui, bukan memproses ulang seluruh dataset setiap saat. Ini dapat secara signifikan mengurangi waktu run untuk dataset besar. Proses ini membatasi jumlah data yang diproses, mempercepat waktu transformasi.
2. Manfaatkan partisi dan cluster (untuk basis data seperti Snowflake dan BigQuery)
Partisi dan cluster pada tabel besar di Snowflake atau BigQuery membantu meningkatkan kinerja kueri dengan mengorganisir data secara efisien dan mengurangi jumlah data yang dipindai selama kueri.
Partisi memastikan hanya bagian data yang relevan yang dikuery, sementara clustering mengoptimalkan tata letak fisik data untuk pengambilan yang lebih cepat.
3. Optimalkan materialization (table, view, incremental)
Gunakan materialization yang sesuai untuk mengoptimalkan kinerja:
4. Gunakan LIMIT saat pengembangan
Saat mengembangkan transformasi, menambahkan klausa LIMIT pada kueri berguna untuk membatasi jumlah baris yang diproses. Ini mempercepat siklus pengembangan dan menghindari bekerja dengan dataset besar selama pengujian.
5. Jalankan kueri secara paralel
Manfaatkan kemampuan gudang data Anda untuk mengeksekusi kueri secara paralel. Misalnya, dbt Cloud mendukung paralelisme, yang dapat disesuaikan berdasarkan infrastruktur Anda.
6. Gunakan fitur optimasi spesifik basis data
Banyak gudang data cloud menyediakan fitur optimasi kinerja seperti:
Untuk mengoptimalkan run dbt di Snowflake:
1. Gunakan clustering tabel:
{{ config(
cluster_by = ["date_column", "category_column"]
) }}
SELECT ...2. Manfaatkan multi-cluster warehouse Snowflake untuk eksekusi model paralel:
models:
my_project:
materialized: table
snowflake_warehouse: transforming_wh3. Gunakan model inkremental bila sesuai:
{{ config(materialized='incremental', unique_key='id') }}
SELECT *
FROM source_table
{% if is_incremental() %}
WHERE updated_at > (SELECT MAX(updated_at) FROM {{ this }})
{% endif %}Optimasi ini dapat meningkatkan kinerja dan efisiensi biaya run dbt di Snowflake.
Di akhir proses wawancara, pewawancara biasanya menguji kemampuan pemecahan masalah Anda. Mereka mungkin menanyakan pertanyaan untuk melihat bagaimana Anda merespons masalah nyata.
Ingat kutipan ini terkait keterampilan lunak yang dibutuhkan untuk peran ini dari Deepak Goyal, CEO & Founder di Azurelib Academy, saat ia berbicara di podcast DataFramed:
Sebagai Data Engineer, Anda harus mampu berkomunikasi. Seorang data engineer harus berkomunikasi karena mereka harus berbicara dengan banyak pemangku kepentingan untuk memahami jenis keluaran atau hasil yang mereka cari.
Deepak Goya, CEO & Founder at Azurelib Academy
Pelajari lebih lanjut tentang data engineering dengan kursus-kursus ini!
Program
Kursus
Kursus
blogs
Dario Radečić
15 mnt
blogs
Javier Canales Luna
14 mnt
blogs
David Woods
13 mnt
blogs
Hugo Bowne-Anderson
13 mnt
