
Leerpad
Professionele data-engineer in Python
40 Hr
dbt (data build tool) is uitgegroeid tot een veelgebruikt ontwikkelkader in moderne data-engineering- en analytics-workflows. Data-analisten zijn vaak afhankelijk van data-engineers om transformaties in SQL te schrijven. Maar met dbt kunnen ze zelf transformaties schrijven en meer controle over data krijgen. Het biedt ook integratie met populaire versiebeheersystemen zoals Git, wat de samenwerking binnen teams verbetert.
Bereid je je voor op een rol in een datawarehouse, zoals data-engineer, data-analist of data scientist, dan moet je goed thuis zijn in basis- en gevorderde dbt-vragen!
In dit artikel heb ik de meest gestelde interviewvragen op een rij gezet om je basisconcepten en gevorderde probleemoplossende vaardigheden op te bouwen.
dbt is een open-source datatransformatiekader waarmee je data kunt transformeren, testen op nauwkeurigheid en wijzigingen kunt bijhouden binnen één platform. In tegenstelling tot andere ETL-tools (extract, transform, load) doet dbt alleen het transformatiegedeelte (de T).
Sommige andere ETL-tools extraheren data uit verschillende bronnen, transformeren die buiten het warehouse en laden het daarna terug. Dit vereist vaak gespecialiseerde codeerkennis en extra tools. dbt maakt dit eenvoudiger — het voert transformaties in het warehouse uit met alleen SQL.
Meer dan 40.000 grote bedrijven gebruiken dbt om data te stroomlijnen — daarom noemen recruiters het een van de belangrijkste skills voor data-gerelateerde rollen. Als je het zelfs als beginnende dataprofessional onder de knie krijgt, kan dat veel carrièrekansen openen!
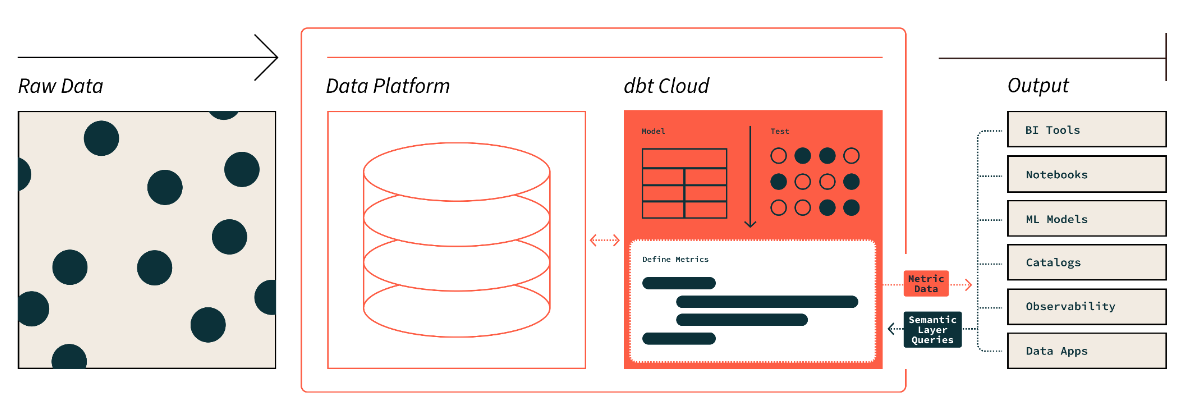
De dbt-semantic layer. Beeldbron: dbt
Aan het begin van het sollicitatieproces test de interviewer je basiskennis. Daarvoor kunnen ze je enkele fundamentele vragen stellen zoals deze:
dbt brengt een datateam op één lijn, waar ze hun data kunnen transformeren, documenteren en testen. Het helpt om data betrouwbaar en begrijpelijk te maken. De gangbare toepassingen van dbt zijn onder meer:
Nee, dbt is geen programmeertaal. Het is een tool die helpt bij datatransformatietaken in het warehouse. Als je SQL kunt schrijven, kun je eenvoudig met dbt werken. Het is ook begonnen met ondersteuning voor Python voor specifieke taken. Maar in de kern beheert en voert het SQL-gebaseerde transformaties uit.
dbt en Spark dienen verschillende doelen en richten zich op verschillende soorten workflows. Hier is een vergelijking van hun rol in de datainfrastructuur:
|
Functie |
dbt |
Spark |
|
Rol |
SQL-gebaseerde datatransformaties en modellering |
Gedistribueerde dataverwerking en analytics |
|
Kern-taal |
SQL-first, met beperkte Python-ondersteuning |
Ondersteunt SQL, Python, Scala, Java, R |
|
Datagovernance |
Documentatie- en lineage-ondersteuning |
Biedt toegangscontrole, auditing en data lineage |
|
Doelgebruikers |
SQL-gebruikers, analisten en teams zonder engineeringskills |
Data-engineers, data scientists, developers |
|
Transformatiecomplexiteit |
Richt zich alleen op SQL-transformaties en modellering |
Kan ook complexe transformaties in andere talen aan |
|
Testen en validatie |
Heeft ingebouwde testmogelijkheden |
Vereist aangepaste teststrategieën (unit en integratie) |
Hoewel dbt veel waarde biedt voor datateams, kan het ook uitdagingen opleveren, vooral wanneer schaal en complexiteit toenemen. Enkele van de meest voorkomende uitdagingen zijn:
Weten hoe je met bovenstaande potentiële uitdagingen omgaat, is iets waar werkgevers naar kijken, dus onderschat het belang van deze vraag niet.
Er zijn twee hoofdversies van dbt:
dbt Core is de gratis en open-source versie van dbt waarmee gebruikers lokaal SQL-gebaseerde transformaties kunnen schrijven, uitvoeren en beheren. Het biedt een command-line interface (CLI) om dbt-projecten uit te voeren, modellen te testen en datapijplijnen te bouwen. Omdat het open-source is, moeten gebruikers met dbt Core zelf zorgen voor deployment, orchestratie en infrastructuur, meestal integreren met tools als Airflow of Kubernetes voor automatisering.
dbt Cloud daarentegen is een beheerde dienst van de makers van dbt (Fishtown Analytics). Het biedt alle mogelijkheden van dbt Core, plus extra features zoals een webinterface, geïntegreerde scheduling, jobmanagement en samenwerkingstools. dbt Cloud bevat ook built-in CI/CD (continue integratie en uitrol), API-toegang en verbeterde security-compliance zoals SOC 2 en HIPAA voor organisaties met strengere beveiligingseisen.
Nu we de basisvragen hebben behandeld, volgen hier enkele dbt-vragen op gemiddeld niveau. Deze richten zich op specifieke technische aspecten en concepten.
In dbt zijn sources de ruwe datatabellen. We schrijven niet rechtstreeks SQL-queries op die ruwe tabellen — we specificeren het schema en de tabelnaam en definiëren ze als sources. Dit maakt het eenvoudiger om naar dataobjecten in tabellen te verwijzen.
Stel, je hebt een ruwe datatabel in je database met de naam orders in het sales-schema. In plaats van deze tabel direct te bevragen, definieer je die in dbt als een source, zoals hier:
Definieer de source in je sources.yml-bestand:
version: 2
sources:
- name: sales
tables:
- name: ordersGebruik de source in je dbt-modellen:
Zodra gedefinieerd, kun je naar de ruwe orders-tabel verwijzen in je transformaties zoals dit:
SELECT *
FROM {{ source('sales', 'orders') }}Deze aanpak abstraheert de definitie van de ruwe tabel, waardoor beheer eenvoudiger wordt en je, als de onderliggende tabelstructuur verandert, dit op één plek (de sourcedefinitie) kunt bijwerken in plaats van in elke query.
Voordelen van sources in dbt:
Een dbt-model is in essentie een SQL- of Python-bestand dat de transformatielogica voor ruwe data definieert. In dbt zijn modellen de kerncomponent waar je je transformaties schrijft, of het nu aggregaties, joins of andere vormen van datamanipulatie zijn.
SELECT-statements om transformaties te definiëren en worden opgeslagen als .sql-bestanden..py-bestanden en laten je Python-bibliotheken zoals pandas gebruiken om data te manipuleren.Voorbeeld van een SQL-model:
Een SQL-model transformeert ruwe data met SQL-queries. Bijvoorbeeld, om een samenvatting van orders te maken uit een orders-tabel:
--orders_summary.sql
WITH orders_cte AS (
SELECT
customer_id,
COUNT(order_id) AS total_orders,
SUM(order_amount) AS total_revenue
FROM {{ ref('orders') }}
GROUP BY customer_id
)
SELECT *
FROM orders_cteIn dit voorbeeld:
orders_summary.sql maakt een samenvatting van het totaal aantal orders en omzet per klant met SQL.orders-tabel (al gedefinieerd als dbt-model of source).Voorbeeld van een Python-model:
Een Python-model manipuleert ruwe data met Python-code. Dit is vooral handig voor complexe logica die in SQL omslachtig kan zijn.
# orders_summary.py
import pandas as pd
def model(dbt, session):
# Load the source data
orders = dbt.ref("orders").to_pandas()
# Perform transformations using pandas
orders_summary = orders.groupby('customer_id').agg(
total_orders=('order_id', 'count'),
total_revenue=('order_amount', 'sum')
).reset_index()
return orders_summaryIn dit voorbeeld:
Zo maak je een dbt-model:
models folder in het dbt-project. .sql-extensie in de map (of .py als het een Python-model is).dbt run uit om de transformatie toe te passen en het model aan te maken.dbt beheert modelafhankelijkheden met de functie ref(), die een duidelijke afhankelijkheidsketen tussen modellen creëert.
Wanneer je een transformatie in dbt definieert, verwijs je niet direct naar tabellen in je warehouse, maar naar andere dbt-modellen met de functie ref(). Zo zorgt dbt ervoor dat modellen in de juiste volgorde worden gebouwd door te identificeren welke modellen van andere afhankelijk zijn.
Als je bijvoorbeeld een model orders_summary hebt dat afhankelijk is van het model orders, definieer je het als volgt:
WITH orders AS (
SELECT * FROM {{ ref('orders') }}
)
SELECT
customer_id,
COUNT(order_id) AS total_orders,
SUM(order_amount) AS total_revenue
FROM orders
GROUP BY customer_idIn dit voorbeeld zorgt de functie {{ ref('orders') }} ervoor dat het orders model wordt gebouwd vóór orders_summary, omdat orders_summary afhankelijk is van de data in het orders-model.
Macros in dbt zijn herbruikbare blokken SQL-code die zijn geschreven met de Jinja-templating engine. Ze stellen je in staat repetitieve taken te automatiseren, complexe logica te abstraheren en SQL-code te hergebruiken in meerdere modellen, waardoor je dbt-project efficiënter en beter onderhoudbaar wordt.
Macros kunnen worden gedefinieerd in .sql-bestanden binnen de map macros van je dbt-project.
Macros zijn vooral handig als je vergelijkbare transformaties over meerdere modellen moet uitvoeren of om omgevingsspecifieke logica toe te passen, zoals verschillende schema's gebruiken of datumformaten aanpassen op basis van omgevingen (bijv. development, staging of productie).
Voorbeeld van het maken van macros:
-- macros/date_format.sql
{% macro format_date(column) %}
FORMAT_TIMESTAMP('%Y-%m-%d', {{ column }})
{% endmacro %}Gebruik in een model:
SELECT
customer_id,
{{ format_date('order_date') }} AS formatted_order_date
FROM {{ ref('orders') }}In dit voorbeeld wordt de macro format_date gebruikt om het formaat van de kolom order_date te standaardiseren in elk model waar deze wordt aangeroepen.
-- macros/custom_schema.sql
{% macro custom_schema_name() %}
{% if target.name == 'prod' %}
'production_schema'
{% else %}
'dev_schema'
{% endif %}
{% endmacro %}Gebruik in een model:
SELECT *
FROM {{ custom_schema_name() }}.ordersHier controleert de macro of de omgeving (target.name) "prod" is en geeft op basis daarvan de juiste schemanaam terug.
Hoe voer je macros uit:
Macros worden niet rechtstreeks uitgevoerd zoals SQL-modellen. In plaats daarvan worden ze aangeroepen in je modellen of andere macros en uitgevoerd wanneer het dbt-project draait. Als je bijvoorbeeld een macro in een model gebruikt, wordt de macro uitgevoerd wanneer je het commando dbt run uitvoert.
dbt run-operation. Dit wordt meestal gebruikt voor eenmalige taken, zoals seeden van data of onderhoudstaken.Singular tests en generic tests zijn de twee testtypen in dbt:
Voorbeeld: Stel dat je wilt garanderen dat er geen orders zijn met een negatieve order_amount. Je kunt een singular test schrijven in de map tests als volgt:
-- tests/no_negative_order_amount.sql
SELECT *
FROM {{ ref('orders') }}
WHERE order_amount < 0Als deze test faalt, retourneert dbt alle rijen uit de orders-tabel waar de order_amount negatief is.
|
Generic tests |
Definitie |
|
Unique |
Controleert op unieke waarden in de kolom. |
|
Not null |
Controleert op lege velden. |
|
Available values |
Verifieert dat kolomwaarden overeenkomen met een lijst verwachte waarden om standaardisatie te bewaren. |
|
Relationships |
Controleert referentiële integriteit tussen tabellen om inconsistente data te verwijderen. |
Voorbeeld: Je kunt eenvoudig een generic test toepassen om te garanderen dat customer_id in de tabel customers uniek en niet null is door dit te definiëren in je schema.yml-bestand:
version: 2
models:
- name: customers
columns:
- name: customer_id
tests:
- unique
- not_nullIn dit voorbeeld:
customer_id in de tabel customers uniek is.customer_id-waarden ontbreken of null zijn.Naarmate je verder komt, kun je complexere scenario's en geavanceerde concepten tegenkomen. Hier zijn een paar uitdagende interviewvragen om je expertise te peilen en je voor te bereiden op senior data-engineeringposities.
Incrementele modellen in dbt worden gebruikt om alleen nieuwe of gewijzigde data te verwerken in plaats van elke keer de volledige dataset opnieuw te verwerken. Dit is vooral nuttig bij grote datasets waarbij het volledig herbouwen van het model tijdrovend en resource-intensief zou zijn.
Een incrementeel model laat dbt alleen nieuwe data toevoegen (of gewijzigde data updaten) op basis van een voorwaarde, meestal een timestamp-kolom (zoals updated_at).
Hoe maak je een incrementeel model:
1. Definieer het model als incrementeel door dit te specificeren in de config van het model:
{{ config(
materialized='incremental',
unique_key='id' -- of een andere unieke kolom
) }}2. Gebruik de functie is_incremental() om nieuwe of gewijzigde rijen te filteren:
SELECT *
FROM source_table
{% if is_incremental() %}
WHERE updated_at > (SELECT MAX(updated_at) FROM {{ this }})
{% endif %}3. Wanneer dbt dit model voor het eerst draait, verwerkt het alle data. Bij volgende runs verwerkt het alleen de rijen waar updated_at groter is dan de meest recente waarde die al in het model staat.
Wanneer gebruik je incrementele modellen:
Jinja maakt onze SQL-code flexibeler. Met Jinja kunnen we herbruikbare templates definiëren voor veelvoorkomende SQL-patronen. En omdat de vereisten blijven veranderen, kunnen we Jinja's if-statements gebruiken om onze SQL-queries aan te passen afhankelijk van de voorwaarden. Dit verbetert meestal de SQL-code door complexe logica op te delen, waardoor deze begrijpelijker wordt.
Als je bijvoorbeeld het datumformaat wilt omzetten van "YYYY-MM-DD" naar "MM/DD/YYYY", is hier een dbt-macro als voorbeeld, die we eerder zagen:
{% macro change_date_format(column_name) %}
to_char({{ column_name }}::date, 'MM/DD/YYYY')
{% endmacro %}In dit codevoorbeeld is {{ column_name }} de plek waar Jinja de daadwerkelijke kolomnaam invoegt wanneer je de macro gebruikt. Dit wordt tijdens runtime vervangen door de echte kolomnaam. Zoals we in eerdere voorbeelden hebben gezien, gebruikt Jinja {{ }} om aan te geven waar de vervanging plaatsvindt.
Zo maak je een custom materialization in dbt:
materialization_name: {% materialization materialization_name, default -%}adapter.get_relation om de doeltabel in te stellen. Dit is waar data wordt geladen. {% set sql %}
SELECT * FROM {{ ref('your_source_table') }}
WHERE your_conditions = true
{% endset %}
{{ adapter.execute(sql) }}{{ return(target_relation) }}
{% endmaterialization %}Hier zijn twee manieren om onze dbt-modellen te debuggen:
1. Raadpleeg de gecompileerde SQL-bestanden in de target-map om fouten te identificeren en te traceren.
Wanneer je een dbt-project draait, compileert dbt je modellen (geschreven met Jinja-templating) naar ruwe SQL-queries en slaat deze op in de map target. Deze gecompileerde SQL is precies wat dbt uitvoert op je dataplatform, dus het bekijken van deze bestanden kan helpen te achterhalen waar problemen ontstaan:
dbt run of dbt test).target/compiled/ in je dbt-projectdirectory.2. Gebruik de dbt Power User Extension voor VS Code om queryresultaten direct te bekijken.
De dbt Power User Extension voor Visual Studio Code (VS Code) is een handige tool om dbt-modellen te debuggen. Deze extensie laat je je queries direct in je IDE bekijken en testen, zodat je minder hoeft te wisselen tussen dbt, de terminal en je database.
dbt compileert queries via de volgende stappen:
target/compiled.dbt run worden queries voorbereid op uitvoering, mogelijk met extra omhulling.Dit proces transformeert modulaire, getemplate SQL naar uitvoerbare queries die specifiek zijn voor je datawarehouse. We kunnen dbt compile gebruiken of de map target/compiled bekijken om de uiteindelijke SQL voor elk model te zien en te debuggen.
Het werk van de meeste data-engineers draait om het bouwen en integreren van datawarehouses met dbt. Vragen over deze scenario's komen heel vaak voor in interviews — daarom heb ik de meest gestelde verzameld:
Het integreren van dbt met Airflow helpt bij het bouwen van een gestroomlijnde datapijplijn. Enkele voordelen:
De semantic layer van dbt laat ons ruwe data vertalen naar de taal die we begrijpen. We kunnen ook metrics definiëren en ze opvragen met een command line interface (CLI).
Dit helpt om kosten te optimaliseren omdat datavoorbereiding minder tijd kost. Bovendien werkt iedereen met dezelfde datadefinities omdat metrics organisatiebreed consistent zijn.
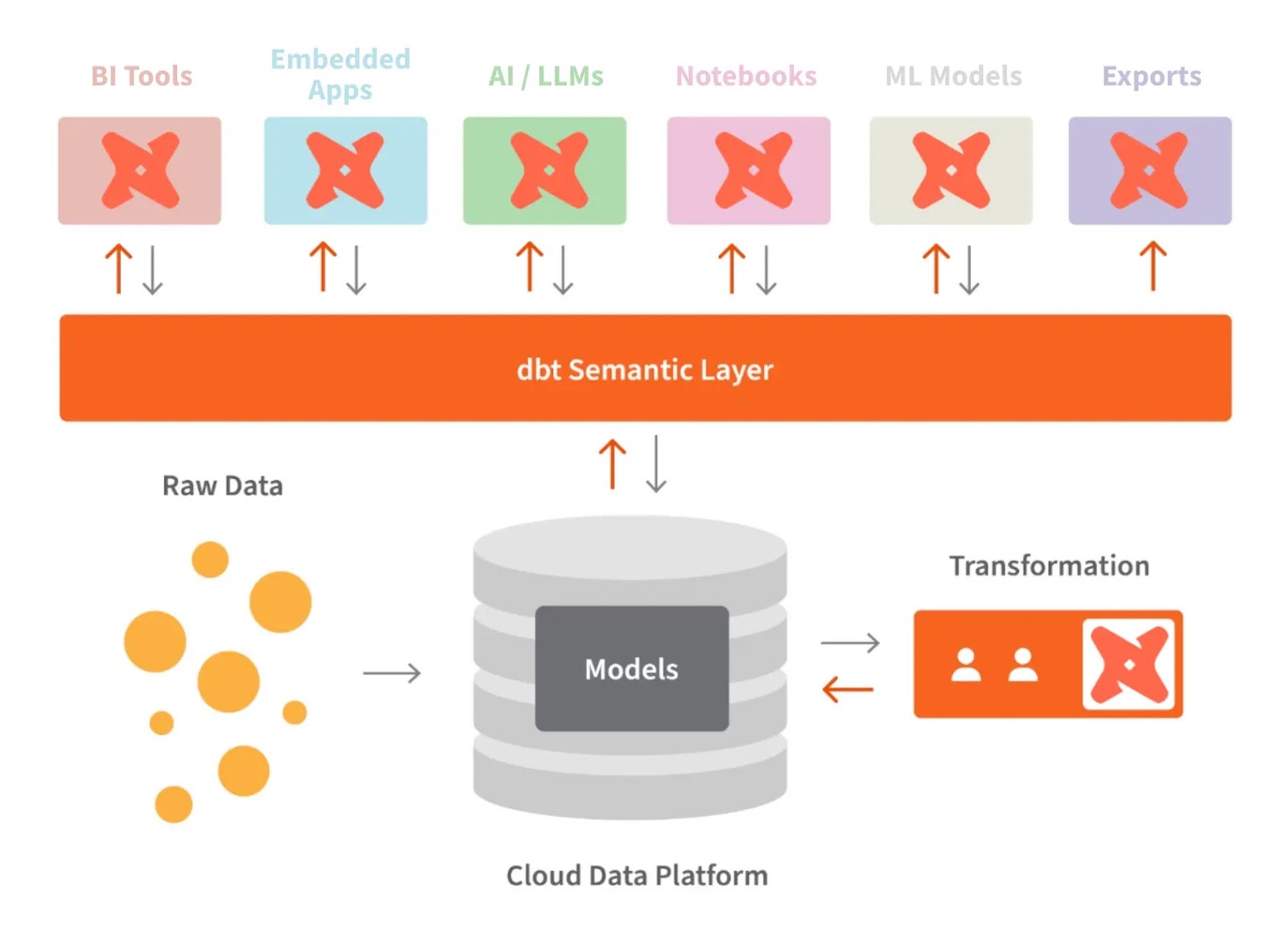
dbt en de semantic layer. Beeldbron: dbt
Hoewel BigQuery erg behulpzaam is en veel transformaties native aankan, kan dbt nog steeds nodig zijn. Daarom:
ref()-functie en macros maken SQL-code modularer en herbruikbaarder.dbt komt in twee versies: dbt Core en dbt Cloud, zoals we eerder zagen. dbt Core is open source en fungeert als een gratis versie. Daarom biedt het geen ingebouwde beveiligingsfeature, en zijn gebruikers verantwoordelijk voor deployment en security.
dbt Cloud is daarentegen ontworpen om volledige beveiliging te bieden. Het voldoet aan HIPAA en andere gangbare raamwerken om privacy te waarborgen. Afhankelijk van onze behoeften kiezen we dus een dbt-versie die past bij onze compliance-eisen.
Het optimaliseren van dbt-transformaties voor grote datasets is cruciaal om prestaties te verbeteren en kosten te verlagen, vooral bij cloudgebaseerde datawarehouses zoals Snowflake, BigQuery of Redshift. Hier zijn enkele belangrijke technieken om dbt-prestaties te optimaliseren:
1. Gebruik incrementele modellen
Incrementele modellen laten dbt alleen nieuwe of bijgewerkte data verwerken in plaats van elke keer de volledige dataset te herverwerken. Dit kan de runtimes voor grote datasets aanzienlijk verkorten. Dit beperkt de hoeveelheid verwerkte data en versnelt transformaties.
2. Maak gebruik van partitionering en clustering (voor databases zoals Snowflake en BigQuery)
Partitionering en clustering van grote tabellen in databases zoals Snowflake of BigQuery verbeteren de queryprestaties door data efficiënt te organiseren en de hoeveelheid gescande data te verminderen.
Partitionering zorgt ervoor dat alleen relevante datadelen worden bevraagd, terwijl clustering de fysieke lay-out van de data optimaliseert voor snellere retrieval.
3. Optimaliseer materializations (table, view, incremental)
Gebruik passende materializations om prestaties te optimaliseren:
4. Gebruik LIMIT tijdens ontwikkeling
Tijdens het ontwikkelen is het toevoegen van een LIMIT-clausule aan queries handig om het aantal verwerkte rijen te beperken. Dit versnelt ontwikkelingscycli en voorkomt werken met enorme datasets tijdens het testen.
5. Voer queries parallel uit
Maak gebruik van het vermogen van je datawarehouse om queries parallel uit te voeren. dbt Cloud ondersteunt bijvoorbeeld parallelisme, dat je kunt afstemmen op je infrastructuur.
6. Gebruik databasespecifieke optimalisatiefuncties
Veel cloud datawarehouses bieden prestatieoptimalisatie zoals:
Om dbt-runs in Snowflake te optimaliseren:
1. Gebruik table clustering:
{{ config(
cluster_by = ["date_column", "category_column"]
) }}
SELECT ...2. Benut Snowflake's multi-cluster warehouses voor parallelle modeluitvoering:
models:
my_project:
materialized: table
snowflake_warehouse: transforming_wh3. Gebruik waar passend incrementele modellen:
{{ config(materialized='incremental', unique_key='id') }}
SELECT *
FROM source_table
{% if is_incremental() %}
WHERE updated_at > (SELECT MAX(updated_at) FROM {{ this }})
{% endif %}Deze optimalisaties kunnen de prestaties en kosteneffectiviteit van dbt-runs in Snowflake verbeteren.
Aan het einde van het sollicitatieproces testen interviewers meestal je probleemoplossende vaardigheden. Ze kunnen vragen stellen om te zien hoe je reageert op realistische issues.
Onthoud dit citaat over de soft skills die voor de rol nodig zijn van Deepak Goyal, CEO & Founder bij Azurelib Academy, toen hij sprak in de DataFramed-podcast:
Als Data Engineer moet je kunnen communiceren. Een data-engineer moet communiceren omdat hij of zij met veel stakeholders moet praten om te begrijpen welk soort output of resultaat ze zoeken.
Deepak Goya, CEO & Founder at Azurelib Academy
Leer meer over data-engineering met deze cursussen!
Leerpad
Cursus
Cursus
blog
Adel Nehme
15 min
