
programa
Ingeniero de Datos Profesional en Python
40 h
dbt (herramienta de creación de datos) se ha convertido en un marco de desarrollo muy utilizado en los flujos de trabajo modernos de ingeniería y análisis de datos. Los analistas de datos dependen principalmente de los ingenieros de datos para escribir transformaciones en SQL. Pero con dbt, pueden escribir transformaciones y tener más control sobre los datos. También permite la integración con sistemas de control de versiones populares como Git, lo que mejora la colaboración en equipo.
Si te estás preparando para desempeñar una función relacionada con los almacenes de datos, como ingeniero de datos, analista de datos o científico de datos, ¡deberías estar bien versado en preguntas básicas y avanzadas sobre dbt!
En este artículo, he resumido las preguntas más frecuentes en las entrevistas para que puedas desarrollar tus conceptos básicos y tus habilidades avanzadas para la resolución de problemas.
dbt es un marco de transformación de datos de código abierto que te permite transformar datos, comprobar su precisión y realizar un seguimiento de los cambios en una única plataforma. A diferencia de otras herramientas ETL (extraer, transformar, cargar), dbt solo realiza la parte de transformación (la T).
Otras herramientas ETL extraen datos de diversas fuentes, los transforman fuera del almacén y luego los vuelven a cargar. Esto suele requerir conocimientos especializados de programación y herramientas adicionales. Pero dbt lo hace más fácil: permite realizar transformaciones en el almacén utilizando únicamente SQL.
Más de 40 000 grandes empresas utilizan dbt para optimizar los datos, por lo que los reclutadores lo incluyen como una de las habilidades más importantes para los puestos relacionados con los datos. Por lo tanto, si lo dominas incluso como principiante en el campo de los datos, ¡puede abrirte muchas oportunidades profesionales!
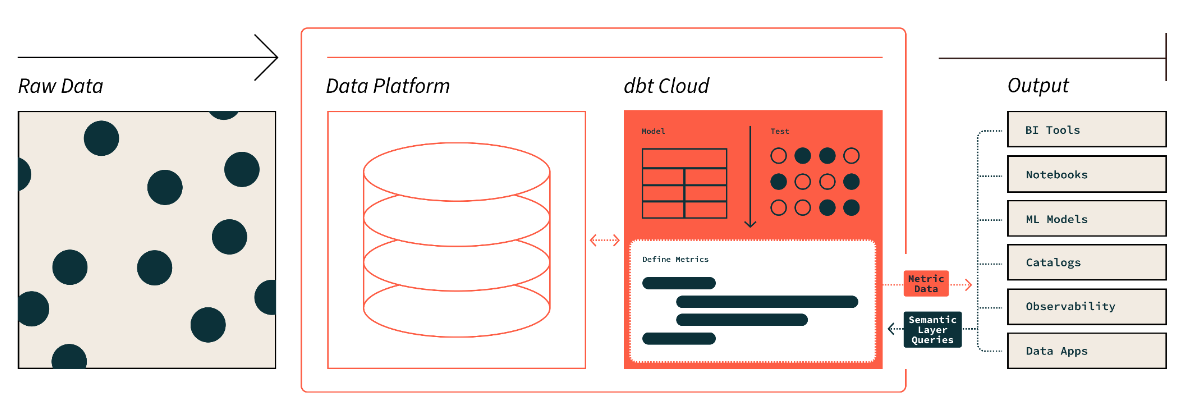
La capa semántica de dbt. Fuente de la imagen: dbt
El entrevistador evaluará tus conocimientos básicos al comienzo del proceso de entrevista. Para ello, es posible que te hagan algunas preguntas básicas como estas:
dbt reúne al equipo de datos en una sola página, donde pueden transformar, documentar y probar sus datos. Ayuda a garantizar que los datos sean fiables y fáciles de entender. Los usos comunes de dbt incluyen:
No, dbt no es un lenguaje de programación. Es una herramienta que ayuda con las tareas de transformación de datos en el almacén. Si sabes escribir SQL, podrás trabajar fácilmente con dbt. También ha comenzado a admitir Python para tareas específicas. Pero, en esencia, gestiona y ejecuta transformaciones basadas en SQL.
dbt y Spark tienen fines diferentes y se dirigen a distintos tipos de flujos de trabajo. A continuación, se muestra una comparación de vuestro papel en la infraestructura de datos:
|
Característica |
dbt |
Spark |
|
Función |
Transformaciones y modelado de datos basados en SQL |
Procesamiento y análisis de datos distribuidos |
|
Idioma principal |
SQL principalmente, con compatibilidad limitada con Python. |
Compatible con SQL, Python, Scala, Java y R. |
|
Gobernanza de datos |
Documentación y soporte de linaje |
Proporciona control de acceso, auditoría y linaje de datos. |
|
Usuarios objetivo |
Usuarios, analistas y equipos de SQL sin conocimientos de ingeniería. |
Ingenieros de datos, científicos de datos, programadores |
|
Complejidad de la transformación |
Se centra únicamente en las transformaciones y el modelado SQL. |
También puede manejar transformaciones complejas en otros idiomas. |
|
Pruebas y validación |
Tiene capacidades de prueba integradas. |
Necesidad de estrategias de prueba personalizadas (unidad e integración) |
Aunque el dbt aporta mucho valor a los equipos de datos, también puede plantear algunos retos, especialmente cuando aumenta la escala y la complejidad. Algunos de los retos más comunes son:
Saber cómo sortear los posibles retos mencionados anteriormente es algo que buscan los empleadores, así que no pases por alto la importancia de esta pregunta.
Hay dos versiones principales de dbt:
dbt Core es la versión gratuita y de código abierto de dbt que permite a los usuarios escribir, ejecutar y gestionar transformaciones basadas en SQL de forma local. Proporciona una interfaz de línea de comandos (CLI) para ejecutar proyectos dbt, probar modelos y crear canalizaciones de datos. Al ser de código abierto, dbt Core requiere que los usuarios se encarguen de la implementación, la coordinación y la configuración de la infraestructura, normalmente en un entorntegración con herramientas como Airflow o Kubernetes para la automatización.
Por otro lado, dbt Cloud es un servicio gestionado proporcionado por los creadores de dbt (Fishtown Analytics). Ofrece todas las capacidades de dbt Core, junto con características adicionales como una interfaz basada en web, programación integrada, gestión de tareas y herramientas de colaboración. dbt Nube también incluye baracterísticas CI/CD (integración y despliegue continuos) integradas, acceso a API y cumplimiento de seguridad mejorado, como SOC 2 e HIPAA, para organizaciones con necesidades de seguridad más rigurosas.
Ahora que hemos cubierto las preguntas básicas sobre dbt, aquí hay algunas preguntas de nivel intermedio sobre dbt. Se centran en aspectos técnicos y conceptos específicos.
En dbt, las fuentes son las tablas de datos sin procesar. No escribimos consultas SQL directamente en esas tablas sin procesar, sino que especificamos el esquema y el nombre de la tabla y los definimos como fuentes. Esto facilita la referencia a objetos de datos en tablas.
Imagina que tienes una tabla de datos sin procesar en tu base de datos llamada « orders » en el esquema « sales ». En lugar de consultar esta tabla directamente, la definirías como fuente en dbt de la siguiente manera:
Define la fuente en tu archivo sources.yml:
version: 2
sources:
- name: sales
tables:
- name: ordersUtiliza la fuente en tus modelos dbt:
Una vez definida, puedes hacer referencia a la tabla sin procesar orders en tus transformaciones de la siguiente manera:
SELECT *
FROM {{ source('sales', 'orders') }}Este enfoque abstrae la definición de la tabla sin procesar, lo que facilita su gestión y garantiza que, si cambia la estructura de la tabla subyacente, puedas actualizarla en un solo lugar (la definición de origen) en lugar de en cada consulta.
Ventajas de utilizar fuentes en dbt:
Un modelo dbt es esencialmente un archivo SQL o Python que define la lógica de transformación de los datos sin procesar. En dbt, los modelos son el componente central en el que escribes tus transformaciones, ya sean agregaciones, uniones o cualquier tipo de manipulación de datos.
SELECT ` para definir transformaciones y se guardan como archivos `.sql `..py y te permiten utilizar bibliotecas Python como pandas para manipular datos.Ejemplo de modelo SQL:
Un modelo SQL transforma datos sin procesar mediante consultas SQL. Por ejemplo, para crear un resumen de los pedidos de una tabla orders:
--orders_summary.sql
WITH orders_cte AS (
SELECT
customer_id,
COUNT(order_id) AS total_orders,
SUM(order_amount) AS total_revenue
FROM {{ ref('orders') }}
GROUP BY customer_id
)
SELECT *
FROM orders_cteEn este ejemplo:
orders_summary.sql crea un resumen del total de pedidos e ingresos de cada cliente utilizando SQL.orders (ya definida como modelo o fuente dbt).Ejemplo de modelo Python:
Un modelo Python manipula datos sin procesar utilizando código Python. Puede resultar especialmente útil para lógicas complejas que podrían resultar engorrosas en SQL.
# orders_summary.py
import pandas as pd
def model(dbt, session):
# Load the source data
orders = dbt.ref("orders").to_pandas()
# Perform transformations using pandas
orders_summary = orders.groupby('customer_id').agg(
total_orders=('order_id', 'count'),
total_revenue=('order_amount', 'sum')
).reset_index()
return orders_summaryEn este ejemplo:
A continuación se explica cómo crear un modelo dbt:
models » del proyecto dbt. .sql dentro del directorio (o .py si se trata de un modelo Python).dbt run » para aplicar la transformación y crear el modelo.dbt gestiona las dependencias de los modelos mediante la función « ref() », que crea una cadena de dependencias clara entre los modelos.
Cuando defines una transformación en dbt, en lugar de hacer referencia directa a las tablas de tu almacén, haces referencia a otros modelos dbt utilizando la función « ref() » (usar tabla de referencia). Esto garantiza que dbt construya los modelos en el orden correcto identificando qué modelos dependen de otros.
Por ejemplo, si tienes un modelo orders_summary que depende del modelo orders, lo definirías así:
WITH orders AS (
SELECT * FROM {{ ref('orders') }}
)
SELECT
customer_id,
COUNT(order_id) AS total_orders,
SUM(order_amount) AS total_revenue
FROM orders
GROUP BY customer_idEn este ejemplo, la función « {{ ref('orders') }} » garantiza que el modelo « orders » se construya antes que « orders_summary », ya que « orders_summary » depende de los datosdel modelo « orders ».
Las macros en dbt son bloques reutilizables de código SQL escritos con el motor de plantillas Jinja. Te permiten automatizar tareas repetitivas, abstraer lógica compleja y reutilizar código SQL en múltiples modelos, lo que hace que tu proyecto dbt sea más eficiente y fácil de mantener.
Las macros se pueden definir en archivos .sql dentro del directorio macros de tu proyecto dbt.
Las macros son especialmente útiles cuando necesitas realizar transformaciones similares en varios modelos o necesitas una lógica específica para cada entorno, como utilizar diferentes esquemas o modificar los formatos de fecha en función de los entornos de implementación (por ejemplo, desarrollo, prueba o producción).
Ejemplo de creación de macros:
-- macros/date_format.sql
{% macro format_date(column) %}
FORMAT_TIMESTAMP('%Y-%m-%d', {{ column }})
{% endmacro %}Uso en un modelo:
SELECT
customer_id,
{{ format_date('order_date') }} AS formatted_order_date
FROM {{ ref('orders') }}En este ejemplo, se utiliza la macro format_date para estandarizar el formato de la columna order_date en cualquier modelo en el que se llame.
-- macros/custom_schema.sql
{% macro custom_schema_name() %}
{% if target.name == 'prod' %}
'production_schema'
{% else %}
'dev_schema'
{% endif %}
{% endmacro %}Uso en un modelo:
SELECT *
FROM {{ custom_schema_name() }}.ordersAquí, la macro comprueba si el entorno (target.name) es «prod» y devuelve el nombre de esquema correcto en función de eso.
Cómo ejecutar macros:
Las macros no se ejecutan directamente como los modelos SQL. En su lugar, se hace referencia a ellas en tus modelos u otras macros y se ejecutan cuando se ejecuta el proyecto dbt. Por ejemplo, si utilizas una macro dentro de un modelo, la macro se ejecutará cuando ejecutes el comando « dbt run » (Aplicar macro).
dbt run-operation ». Esto se utiliza normalmente para tareas puntuales, como introducir datos o realizar operaciones de mantenimiento.Las pruebas singulares y las pruebas genéricas son los dos tipos de pruebas que existen en dbt:
Ejemplo: Supongamos que quieres asegurarte de que ningún pedido tenga un valor negativo en order_amount. Puedes escribir una prueba singular en el directorio tests de la siguiente manera:
-- tests/no_negative_order_amount.sql
SELECT *
FROM {{ ref('orders') }}
WHERE order_amount < 0Si esta prueba falla, dbt devolverá todas las filas de la tabla orders en las que order_amount sea negativo.
|
Pruebas genéricas |
Definición |
|
Único |
Comprueba si hay valores únicos en la columna. |
|
No nulo |
Comprueba si hay campos vacíos. |
|
Valores disponibles |
Verifica que los valores de las columnas coincidan con una lista de valores esperados para mantener la estandarización. |
|
Relaciones |
Comprueba la integridad referencial entre tablas para eliminar cualquier dato inconsistente. |
Ejemplo: Puedes aplicar fácilmente una prueba genérica para garantizar que customer_id en la tabla customers sea único y no nulo definiéndolo en tu archivo schema.yml:
version: 2
models:
- name: customers
columns:
- name: customer_id
tests:
- unique
- not_nullEn este ejemplo:
customer_id en la tabla customers sea único.customer_id ni haya ningún valor nulo.A medida que avances, es posible que te encuentres con situaciones más complejas y conceptos más avanzados. A continuación, te presentamos algunas preguntas difíciles para entrevistas que te ayudarán a evaluar tu experiencia y prepararte para puestos de ingeniería de datos de alto nivel.
Los modelos incrementales en dbt se utilizan para procesar únicamente los datos nuevos o modificados, en lugar de volver a procesar todo el conjunto de datos cada vez. Esto resulta especialmente útil cuando se trabaja con grandes conjuntos de datos, en los que reconstruir todo el modelo desde cero requeriría mucho tiempo y recursos.
Un modelo incremental permite a dbt añadir solo datos nuevos (o actualizar los datos modificados) en función de una condición, normalmente una columna de marca de tiempo (como updated_at).
Cómo crear un modelo incremental:
1. Define el modelo como incremental especificándolo en la configuración del modelo:
{{ config(
materialized='incremental',
unique_key='id' -- or another unique column
) }}2. Utiliza la función « is_incremental() » para filtrar las filas nuevas o modificadas:
SELECT *
FROM source_table
{% if is_incremental() %}
WHERE updated_at > (SELECT MAX(updated_at) FROM {{ this }})
{% endif %}3. Cuando dbt ejecuta este modelo por primera vez, procesará todos los datos. Para ejecuciones posteriores, solo procesará filas en las que updated_at sea mayor que el valor más reciente que ya se encuentra en el modelo.
Cuándo utilizar modelos incrementales:
Jinja hace que vuestro código SQL sea más flexible. Con Jinja, podemos definir plantillas reutilizables para patrones SQL comunes. Y dado que los requisitos cambian constantemente, podemos utilizar las sentencias « if » ( ) y «» ( ) de Jinja para ajustar nuestras consultas SQL en función de las condiciones. Hacerlo suele mejorar el código SQL al desglosar la lógica compleja, lo que facilita su comprensión.
Por ejemplo, si deseas convertir el formato de fecha de «AAAA-MM-DD» a «MM/DD/AAAA», aquí tienes un ejemplo de macro dbt para ello, que ya vimos en una pregunta anterior:
{% macro change_date_format(column_name) %}
to_char({{ column_name }}::date, 'MM/DD/YYYY')
{% endmacro %}En este ejemplo de código, {{ column_name }} es donde Jinja inserta el nombre real de la columna cuando usas la macro. Se sustituirá por el nombre real de la columna durante el tiempo de ejecución. Como hemos visto en ejemplos anteriores, Jinja utiliza {{ }} para mostrar dónde se producirá la sustitución.
A continuación, se explica cómo crear una materialización personalizada en dbt:
materialization_name: {% materialization materialization_name, default -%}adapter.get_relation para configurar la tabla de destino. Aquí es donde se cargarán los datos. {% set sql %}
SELECT * FROM {{ ref('your_source_table') }}
WHERE your_conditions = true
{% endset %}
{{ adapter.execute(sql) }}{{ return(target_relation) }}
{% endmaterialization %}Aquí hay dos formas de depurar nuestros modelos dbt:
1. Accede a los archivos SQL compilados en la carpeta de destino para identificar y programar errores.
Cuando ejecutas un proyecto dbt, dbt compila tus modelos (escritos utilizando plantillas Jinja) en consultas SQL sin procesar y los guarda en el directorio target. Este SQL compilado es exactamente lo que dbt ejecuta en tu plataforma de datos, por lo que revisar estos archivos puede ayudarte a identificar dónde se producen los problemas:
dbt run o dbt test).target/compiled/ » en el directorio de tu proyecto dbt.2. Utilizala extensión dbt Power User Extension para VS Code de para revisar los resultados de las consultas directamente.
La extensión dbt Power User para Visual Studio Code (VS Code) es una herramienta útil para depurar modelos dbt. Esta extensión te permite revisar y probar tus consultas directamente en tu IDE, lo que reduce la necesidad de cambiar entre dbt, el terminal y tu base de datos.
dbt compila las consultas siguiendo los siguientes pasos:
target/compiled.dbt run, las consultas se preparan para su ejecución, posiblemente con un envoltorio adicional.Este proceso transforma el SQL modular y basado en plantillas en consultas ejecutables específicas para tu almacén de datos. Podemos utilizar dbt compile o consultar el directorio target/compiled para ver y depurar el SQL final de cada modelo.
La mayoría de los trabajos de los ingenieros de datos giran en torno a la creación e integración de almacenes de datos con dbt. Las preguntas relacionadas con estas situaciones son muy habituales en las entrevistas, por eso he recopilado las más frecuentes:
La integración de dbt con Airflow ayuda a crear un canal de datos optimizado. Estas son algunas de sus ventajas:
La capa semántica de dbt nos permite traducir los datos sin procesar al lenguaje que entendemos. También podemos definir métricas y consultarlas con una interfaz de línea de comandos (CLI).
Esto nos permite optimizar el costo, ya que la preparación de los datos lleva menos tiempo. Además, todos trabajáis con las mismas definiciones de datos, lo que garantiza la coherencia de las métricas en toda la organización.
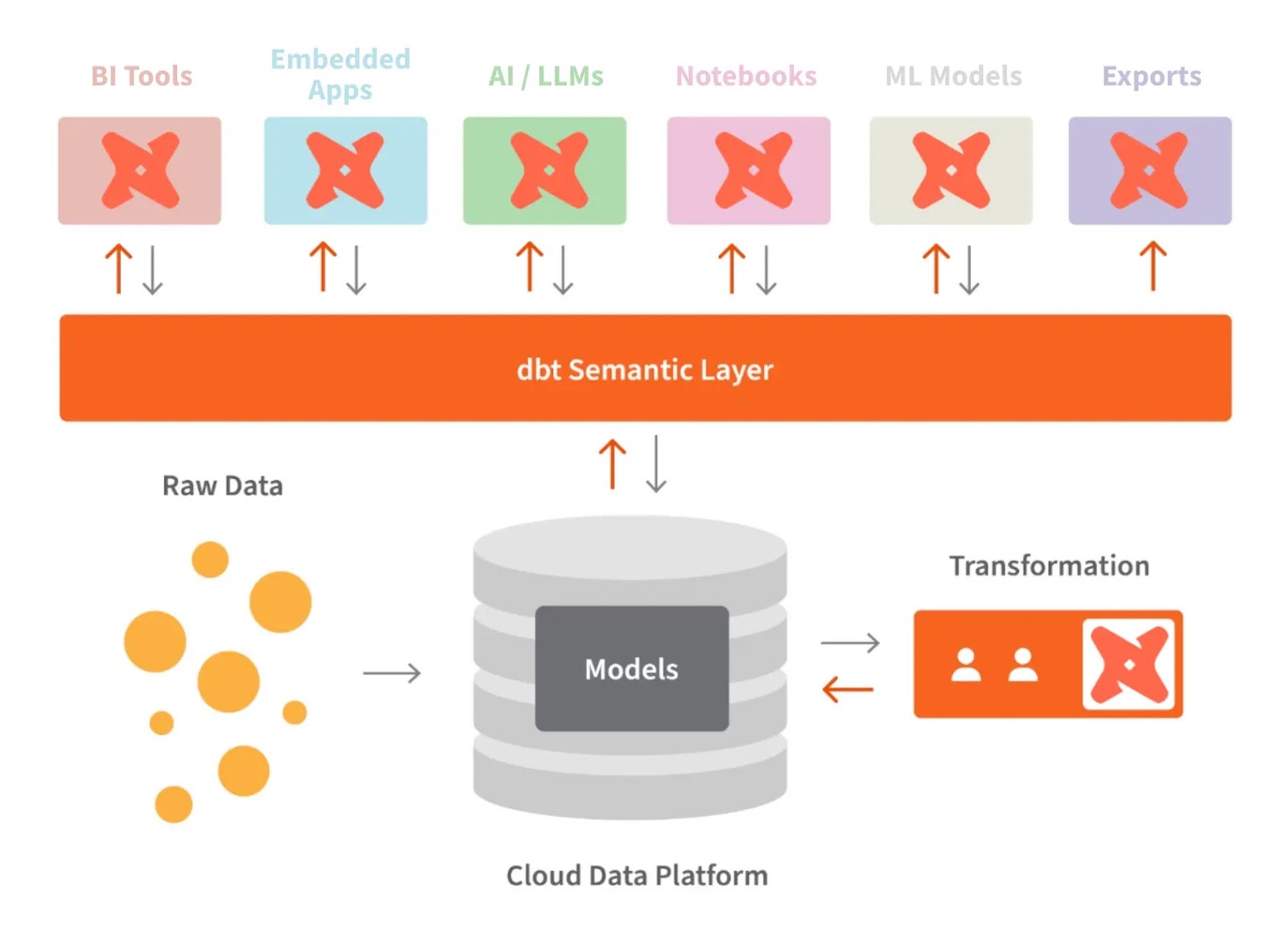
dbt y la capa semántica. Fuente de la imagen: dbt
Aunque BigQuery es muy útil y puede gestionar muchas transformaciones de forma nativa, es posible que sigas necesitando dbt. He aquí por qué:
ref() ` de dbt permiten un código SQL más modular y reutilizable.dbt viene en dos versiones: dbt Core y dbt Nube, como se ha visto en una pregunta anterior. dbt Core es de código abierto y funciona como versión gratuita. Por eso no ofrece ninguna función de seguridad integrada, y los usuarios son responsables de su implementación y seguridad.
Sin embargo, dbt Nube está diseñado para proporcionar una seguridad completa. Cumple con la HIPAA y otros marcos comunes para garantizar que no se vulnere la privacidad. Por lo tanto, dependiendo de vuestras necesidades, debéis elegir una versión de dbt que se adapte a vuestros requisitos de cumplimiento normativo empresarial.
Optimizar las transformaciones dbt para grandes conjuntos de datos es fundamental para mejorar el rendimiento y reducir los costes, especialmente cuando se trabaja con almacenes de datos basados en la nube como Snowflake, BigQuery o Redshift. A continuación, se indican algunas técnicas clave para optimizar el rendimiento de dbt:
1. Utilizar modelos incrementales
Los modelos incrementales permiten a dbt procesar solo los datos nuevos o actualizados, en lugar de volver a procesar todo el conjunto de datos cada vez. Esto puede reducir significativamente los tiempos de ejecución para grandes conjuntos de datos. Este proceso limita la cantidad de datos procesados, lo que acelera los tiempos de transformación.
2. Aprovecha la partición y la agrupación en clústeres (para bases de datos como Snowflake y BigQuery).
La partición y agrupación de tablas grandes en bases de datos como Snowflake o BigQuery ayudan a mejorar el rendimiento de las consultas al organizar los datos de manera eficiente y reducir la cantidad de datos escaneados durante las consultas.
La partición garantiza que solo se consulten las partes relevantes de un conjunto de datos, mientras que la agrupación optimiza la disposición física de los datos para agilizar su recuperación.
3. Optimizar materializaciones (tabla, vista, incremental)
Utiliza materializaciones adecuadas para optimizar el rendimiento:
4. Utiliza LIMIT durante el desarrollo.
Al desarrollar transformaciones, resulta útil añadir una cláusula « LIMIT » a las consultas para restringir el número de filas procesadas. Esto acelera los ciclos de desarrollo y evita tener que trabajar con enormes conjuntos de datos durante las pruebas.
5. Ejecutar consultas en paralelo
Aprovecha la capacidad de tu almacén de datos para ejecutar consultas en paralelo. Por ejemplo, dbt Nube admite el paralelismo, que se puede ajustar en función de tu infraestructura.
6. Utiliza funciones de optimización específicas de la base de datos.
Muchos almacenes de datos en la nube ofrecen funciones de optimización del rendimiento, como:
Para optimizar las ejecuciones de dbt en Snowflake:
1. Utiliza la agrupación de tablas:
{{ config(
cluster_by = ["date_column", "category_column"]
) }}
SELECT ...2. Aprovecha los almacenes multiclúster de Snowflake para la ejecución paralela de modelos:
models:
my_project:
materialized: table
snowflake_warehouse: transforming_wh3. Utiliza modelos incrementales cuando sea apropiado:
{{ config(materialized='incremental', unique_key='id') }}
SELECT *
FROM source_table
{% if is_incremental() %}
WHERE updated_at > (SELECT MAX(updated_at) FROM {{ this }})
{% endif %}Estas optimizaciones pueden mejorar el rendimiento y la rentabilidad de las ejecuciones de dbt en Snowflake.
Al final del proceso de entrevista, los entrevistadores suelen poner a prueba tus habilidades para resolver problemas. Es posible que te hagan preguntas para ver cómo respondes ante situaciones de la vida real. A continuación, te planteamos algunas preguntas sobre comportamiento y resolución de problemas:
A continuación, se explica cómo puedes gestionar la implementación de dbt en distintos entornos:
1. Configuraciones específicas del entorno
dbt te permite definir diferentes configuraciones para cada entorno (desarrollo, staging y producción) en el archivo dbt_project.yml. Puedes especificar diferentes configuraciones para aspectos como el esquema, la base de datos y las configuraciones del almacén de datos.
Ejemplo en dbt_project.yml:
models:
my_project:
dev:
schema: dev_schema
staging:
schema: staging_schema
prod:
schema: prod_schemaEn este ejemplo, dbt selecciona automáticamente el esquema correcto en función del entorno de destino (desarrollo, staging o producción) al ejecutar el proyecto.
2. Uso de la variable objetivo
La variable target en dbt se utiliza para definir en qué entorno estás trabajando (desarrollo, staging, producción). Puedes hacer referencia a esta variable en tus modelos o macros para personalizar el comportamiento en función del entorno.
Ejemplo en un modelo:
{% if target.name == 'prod' %}
SELECT * FROM production_table
{% else %}
SELECT * FROM {{ ref('staging_table') }}
{% endif %}Esta lógica garantiza que se utilicen diferentes tablas o esquemas en función del entorno.
3. Ramificación y control de versiones
Cada entorno debe tener su propia rama en el control de versiones (por ejemplo, Git). Los programadores trabajanen la rama dev, los probadores y analistas utilizan staging, y solo los cambios aprobados se fusionan en la rama prod.
4. Integración continua (CI) e implementación continua (CD)
En producción, es importante contar con un canal de implementación automatizado que realice pruebas y validaciones antes de implementar los modelos. En dbt Nube, puedes configurar programaciones de tareas para ejecutar tareas específicas en función del entorno. En el caso de dbt Core, esto se puede lograr mediante herramientas de CI/CD como GitHub Actions o Jenkins.
El control de versiones es esencial cuando se trabaja en proyectos dbt, especialmente en un entorno de equipo en el que varias personas contribuyen al mismo código base. Así es como gestiono el control de versiones en dbt:
1. Utiliza Git para el control de versiones.
Utilizamos Git como herramienta principal para el control de versiones en nuestros proyectos dbt. Cada miembro del equipo trabaja en su propia rama para cualquier cambio o característica que estéis implementando. Esto permite un desarrollo aislado y evita conflictos entre los miembros del equipo que trabajan en diferentes tareas simultáneamente.
Ejemplo: Cuando trabajo en un nuevo modelo dbt, creo una nueva rama de características como feature/customer_order_transformation.
2. Estrategia de ramificación
Seguimos una estrategia de ramificación Git en la que:
dev » se utiliza para el desarrollo y las pruebas continuas.staging » se utiliza para preparar los cambios para la producción.main o prod está reservada para el entorno de producción.Los miembros del equipo envían sus cambios a la rama dev y abren solicitudes de extracción (PR) para la revisión del código. Una vez que los cambios se revisan y aprueban, se fusionan en staging para realizar más pruebas y, a continuación, se promocionan a production.
3. Integración continua (CI)
Hemos integrado un canal de CI (por ejemplo, GitHub Actions, CircleCI) que ejecuta automáticamente pruebas dbt en cada solicitud de extracción. Esto garantiza que cualquier código nuevo supere las pruebas necesarias antes de integrarse en la rama principal.
El proceso de CI ejecuta dbt run para crear modelos y dbt test para validar los datos y comprobar si hay errores o inconsistencias.
4. Resolver conflictos de fusión
Cuando varios miembros del equipo realizan cambios en el mismo modelo o archivo, pueden producirse conflictos de fusión. Para solucionar esto, primero reviso los marcadores de conflicto en el código y decido qué cambios conservar:
Después de resolver el conflicto, realizo pruebas localmente para asegurarme de que la resolución del conflicto no haya introducido ningún error nuevo. Una vez confirmados, vuelvo a enviar los cambios resueltos a la rama.
5. Documentación y colaboración
Nos aseguramos de que cada solicitud de fusión o extracción incluya la documentación adecuada de los cambios realizados. Actualizamos la documentación dbt generada automáticamente para que todos los miembros del equipo comprendan claramente los modelos nuevos o actualizados.
Así es como implementaría dbt en un canal existente:
Cuando aparece el error «relation does not exist» (la relación no existe) en dbt, normalmente significa que el modelo está intentando hacer referencia a una tabla o modelo que no se ha creado o que está mal escrito. Así es como lo depuraría:
ref() ` y comprueba que se esté haciendo referencia al modelo o a la tabla correctos.SELECT * FROM {{ ref('orders') }} -- Ensure 'orders' is the correct model namedbt debug y comprueba los registros para obtener información detallada sobre lo que dbt intentó hacer y por qué falló.dbt run --models orders) para verificar que existen y que están construidos correctamente antes del modelo defectuoso.dbt es un nuevo marco que está mejorando gradualmente. Puede resultar abrumador estar al día de las nuevas actualizaciones mientras sigues aprendiendo el material antiguo. Por eso debes adoptar un enfoque equilibrado y empezar por las funciones básicas. Una vez que los domines, explora las novedades para comprender qué ha cambiado.
Sé que las entrevistas pueden ser estresantes, especialmente para una herramienta especializada como dbt. Pero no te preocupes, he recopilado algunos consejos para ayudarte a prepararte y sentirte seguro:
No puedo insistir lo suficiente en esto: familiarízate con los conceptos fundamentales de DBT, incluidos los modelos, las pruebas, la documentación y cómo encajan todos ellos entre sí. Un buen dominio de estos conceptos básicos te será muy útil en las discusiones técnicas.
DataCamp tiene el curso perfecto para esto: Introducción a dbt
DataCamp también ofrece algunos cursos aptos para principiantes que tratan otros temas relacionados con la ingeniería de datos en profundidad:
Leer sobre algo es bueno, pero hacerlo es aún mejor. Esta es una de las formas más eficaces de dominar las habilidades de dbt. Puedes encontrar una amplia lista de conjuntos de datos sin procesar en línea para realizar transformaciones y ejecutar pruebas. Configura tu propio proyecto dbt y prueba las diferentes funciones. Esto hará que te sientas mucho más seguro al hablar sobre dbt cuando lo hayas utilizado realmente.
A los entrevistadores les encanta escuchar sobre aplicaciones prácticas. ¿Se te ocurre algún problema que hayas resuelto utilizando dbt o cómo podrías utilizarlo en una situación hipotética? Ten preparados algunos de estos ejemplos para compartir. Para recopilar algunos ejemplos, puedes incluso estudiar varios casos prácticos en el sitio web oficial de dbt u obtener ideas de proyectos públicos de dbt en Git.
Hemos cubierto un amplio espectro de preguntas de entrevista sobre DBT, desde básicas hasta avanzadas, que te ayudarán en tu búsqueda de empleo. Al comprender cómo integrar dbt con los almacenes de datos en la nube, estarás bien equipado con habilidades avanzadas de transformación de datos, que son el núcleo de cualquier proceso de integración de datos.
Sin embargo, aprender DBT y SQL van de la mano. Por lo tanto, si eres nuevo en SQL, echa un vistazo a los cursos de SQL de DataCamp.
¡Aprende más sobre ingeniería de datos con estos cursos!
programa
Curso
Curso
blog
Abid Ali Awan
15 min
blog
Abid Ali Awan
15 min
blog
Tim Lu
9 min
blog
Josep Ferrer
15 min
blog
Javier Canales Luna
15 min


