Bu makaleyi okuyorsanız, muhtemelen büyük dil modellerini (LLM) zaten duymuşsunuzdur. Kim duymadı ki? Sonuçta LLM’ler, üretken yapay zekâ devrimini ateşleyen son derece popüler araçların arkasındaki güçtür; ChatGPT, Google Bard ve DALL-E gibi.
Bu araçlar, kullanıcıların sorduğu sorulara yanıt olarak verileri işleyip tutarlı içerik üretebilmelerini sağlayan güçlü bir teknolojiye dayanır. İşte LLM’ler burada devreye girer.
Bu makalenin amacı sizi LLM’lerle tanıştırmaktır. Aşağıdaki bölümleri okuduktan sonra LLM’lerin ne olduğunu, nasıl çalıştıklarını, farklı LLM türlerini örnekleriyle birlikte ve ayrıca avantajları ile sınırlılıklarını öğreneceğiz.
Konuya yeni başlayanlar için, Büyük Dil Modelleri (LLM) Kavramları Kursumuz LLM’lere kapsamlı bir bakış için mükemmel bir başlangıçtır. Ancak LLM’lere zaten aşinaysanız ve LLM destekli uygulamalar geliştirmeyi öğrenerek bir adım daha ileri gitmek istiyorsanız, LangChain ile LLM Uygulamaları Nasıl Geliştirilir başlıklı makalemize göz atın.
Haydi başlayalım!
Büyük Dil Modeli nedir?
LLM’ler, insan dilini modellemek ve işlemek için kullanılan yapay zekâ sistemleridir. “Büyük” olarak adlandırılırlar çünkü bu tür modeller genellikle modelin davranışını tanımlayan yüz milyonlarca hatta milyarlarca parametreden oluşur ve bu parametreler devasa bir metin veri külliyatı üzerinde önceden eğitilir.
LLM’lerin temelindeki teknolojiye dönüştürücü sinir ağı, kısaca bir transformer denir. Bir sonraki bölümde daha ayrıntılı açıklayacağımız üzere, transformer, derin öğrenme alanındaki yenilikçi bir sinir mimarisidir.
Google araştırmacıları tarafından 2017 tarihli ünlü Attention is All You Need makalesinde sunulan transformer’lar, doğal dil işleme (NLP) görevlerini benzersiz bir doğruluk ve hızla gerçekleştirebilir. Eşsiz yetenekleriyle transformer’lar, LLM’lerin kapasitesinde önemli bir sıçrama sağlamıştır. Transformer’lar olmadan mevcut üretken yapay zekâ devriminin mümkün olmayacağını söylemek abartı olmaz.
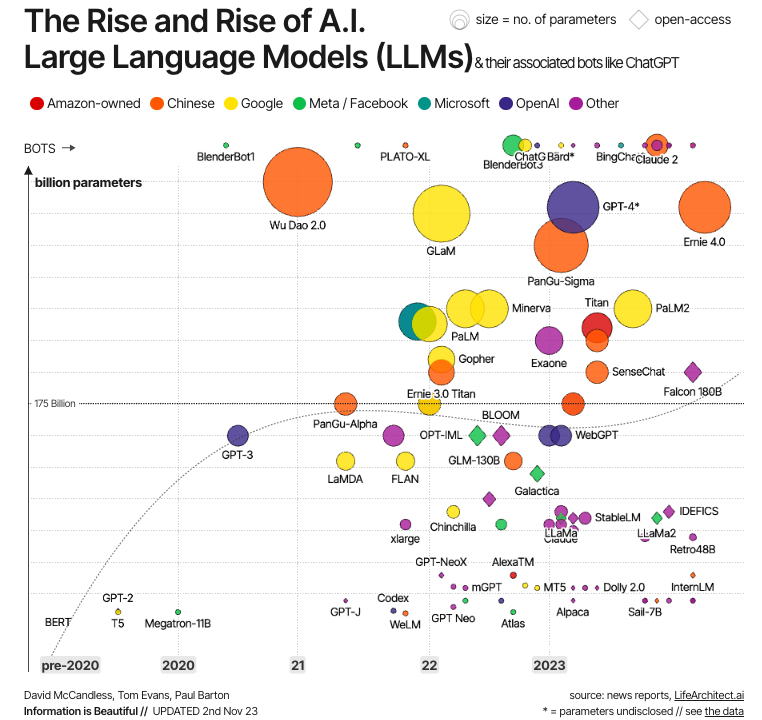
Kaynak: Information is Beautiful
Bu evrim yukarıdaki grafikte gösterilmektedir. Görüldüğü gibi, ilk modern LLM’ler transformer’ların geliştirilmesinin hemen ardından yaratıldı; en önemli örnekler arasında Google’ın transformer’ların gücünü test etmek için geliştirdiği BERT ile OpenAI tarafından oluşturulan GPT serisinin ilk iki modeli GPT-1 ve GPT-2 yer alır. Ancak LLM’ler yalnızca 2020’lerde ana akım hâline geldi; (parametre sayısı açısından) giderek büyüyüp dolayısıyla daha güçlü hâle geldi. GPT-4 ve LLaMa gibi bilinen örnekler bunun göstergesidir.
LLM’ler nasıl çalışır?
Modern LLM’lerin başarısının anahtarı transformer mimarisidir. Google araştırmacıları tarafından transformer geliştirilmeden önce doğal dili modellemek son derece zorlu bir görevdi. yinelenen veya evrişimsel sinir ağları gibi sofistike mimarilerin yükselişine rağmen sonuçlar ancak kısmen başarılıydı.
Asıl zorluk, bu sinir ağlarının bir cümledeki eksik kelimeyi tahmin etmek için kullandığı stratejide yatıyordu. Transformer öncesinde, en gelişmiş sinir ağları paralel hesaplamaya uygun olmayan, dolayısıyla ölçeklenebilirliği sınırlayan, güçlü ancak zaman ve kaynak tüketen bir mekanizma olan encoder-decoder mimarisine dayanıyordu.
Transformer’lar, sıralı verileri (başta metin) işlemek için geleneksel sinir ağlarına alternatif sunar (transformer’ların görüntü ve ses gibi diğer veri türleriyle de benzer başarıyla kullanıldığını not edelim).
LLM’lerin bileşenleri
Transformer’lar, yinelenen ve evrişimsel sinir ağlarıyla aynı encoder-decoder mimarisine dayanır. Bu sinir mimarisi, metin belirteçleri (token) arasındaki istatistiksel ilişkileri keşfetmeyi hedefler.
Bu, gömme (embedding) tekniklerinin bir kombinasyonu ile yapılır. Gömme; cümleler, paragraflar veya belgeler gibi belirteçlerin, her bir boyutun dilin öğrenilmiş bir özelliğine veya özniteliğine karşılık geldiği yüksek boyutlu bir vektör uzayındaki temsilleridir.
Gömme işlemi encoder içinde gerçekleşir. LLM’lerin büyük boyutu nedeniyle gömme oluşturma, yoğun eğitim ve ciddi kaynaklar gerektirir. Ancak transformer’ları önceki sinir ağlarından ayıran şey, gömme sürecinin yüksek düzeyde paralelleştirilebilir olması ve böylece daha verimli işlemeyi mümkün kılmasıdır. Bu da dikkat mekanizması sayesinde olur.
Yinelenen ve evrişimsel sinir ağları, kelime tahminlerini yalnızca önceki kelimelere dayandırır. Bu anlamda tek yönlüdürler. Buna karşılık, dikkat mekanizması, transformer’ların kelimeleri çift yönlü olarak, yani hem önceki hem de sonraki kelimelere dayanarak tahmin etmesine olanak tanır. Hem encoder hem de decoder içinde yer alan dikkat katmanının amacı, giriş cümlesindeki farklı kelimeler arasındaki bağlamsal ilişkileri yakalamaktır.
Transformer’lardaki encoder-decoder mimarisinin nasıl çalıştığını ayrıntılı olarak öğrenmek için Transformer ve Hugging Face Kullanımına Giriş yazımızı okumanızı şiddetle öneririz.
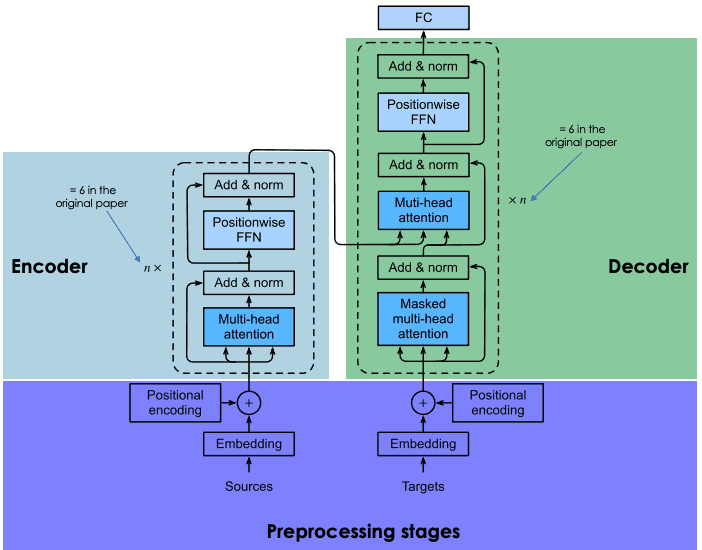
Transformer mimarisinin açıklaması
LLM’lerin eğitimi
Transformer’ları eğitmek iki aşamadan oluşur: ön eğitim (pretraining) ve ince ayar (fine-tuning).
Ön eğitim
Bu aşamada transformer’lar büyük miktarda ham metin verisi üzerinde eğitilir. Birincil veri kaynağı internettir.
Eğitim, verilerin etiketlenmesi için insan müdahalesi gerektirmeyen yenilikçi bir yöntem olan denetimsiz öğrenme teknikleri kullanılarak yapılır.
Ön eğitimin amacı, dilin istatistiksel örüntülerini öğrenmektir. Transformer doğruluğunu artırmaya yönelik en gelişmiş strateji, modeli büyütmek (parametre sayısını artırarak) ve eğitim verisinin boyutunu genişletmektir. Sonuç olarak, en gelişmiş LLM’lerin milyarlarca parametresi vardır (örneğin PaLM 2’nin 340 milyar parametresi bulunur ve GPT-4’ün yaklaşık 1,8 trilyon parametreye sahip olduğu tahmin edilir) ve devasa bir veri külliyatı üzerinde eğitilmiştir.
Bu eğilim erişilebilirlik sorunları yaratır. Modelin ve eğitim verisinin boyutu göz önüne alındığında, ön eğitim süreci genellikle zaman alıcı ve maliyetlidir; bunu karşılayabilen yalnızca sınırlı sayıda şirket vardır.
İnce ayar
Ön eğitim, bir transformer’a dil hakkında temel bir anlayış kazandırır, ancak belirli pratik görevleri yüksek doğrulukla yerine getirmek için yeterli değildir.
Eğitim sürecindeki zaman alıcı ve maliyetli yinelemelerden kaçınmak için transformer’lar, (ön) eğitim aşamasını ince ayar aşamasından ayırmak üzere transfer öğrenimi tekniklerinden yararlanır. Bu sayede geliştiriciler, önceden eğitilmiş modelleri seçip bunları daha dar, alan odaklı bir veri tabanına göre ince ayar yapabilir. Pek çok durumda ince ayar süreci, İnsan Geri Bildiriminden Pekiştirmeli Öğrenme adı verilen bir teknik kullanılarak insan değerlendiricilerin yardımıyla yürütülür.
Bu iki aşamalı eğitim süreci, LLM’lerin çok çeşitli aşağı akış (downstream) görevlere uyarlanmasını sağlar. Başka bir deyişle, bu özellik LLM’leri, üzerlerine inşa edilen sonsuz sayıda uygulamanın temel modeli hâline getirir.
LLM’lerin çok kipli (multimodal) olması
İlk modern LLM’ler metinden-metne modellerdi (yani metin girdisi alır ve metin çıktısı üretirlerdi). Ancak son yıllarda geliştiriciler, çok kipli (multimodal) LLM’ler geliştirdi. Bu modeller metin verisini görseller, ses ve video gibi diğer bilgi türleriyle birleştirir. Farklı veri türlerinin birleşimi, OpenAI’ın görsel üretimi için DALL-E’si ve Meta’nın müzik ve ses üretimi için AudioCraft’ı gibi sofistike, göreve özel modellerin ortaya çıkmasını sağlamıştır.
LLM’ler ne için kullanılır?
Transformer’lar sayesinde modern LLM’ler çok sayıda NLP görevinde son teknoloji düzeyinde performansa ulaşmıştır. LLM’lerin benzersiz sonuçlar sunduğu bazı görevler şunlardır:
- Metin üretimi. ChatGPT gibi LLM’ler, saniyeler içinde uzun, karmaşık ve insan benzeri metinler oluşturabilir.
- Çeviri. LLM’ler birden çok dilde eğitildiğinde üst düzey çeviri işlemleri gerçekleştirebilir. Çok kipli yapı ile olanaklar sınırsızdır. Örneğin Meta’nın SeamlessM4T modeli, göreve bağlı olarak 100’e kadar dilde konuşmadan-metne, konuşmadan-konuşmaya, metinden-konuşmaya ve metinden-metne çeviriler yapabilir.
- Duygu analizi. Olumlu/olumsuz film yorumu tahminlerinden pazarlama kampanyası görüşlerine kadar her tür duygu analizi LLM’lerle yapılabilir.
- Konuşmaya dayalı yapay zekâ. Modern sohbet robotlarının temel teknolojisi olarak LLM’ler, sorgulama, yanıtlama ve hatta karmaşık görevlerde sohbeti sürdürme konusunda çok iyidir.
- Otomatik tamamlama. LLM’ler e-posta veya mesajlaşma servislerinde olduğu gibi otomatik tamamlama görevlerinde kullanılabilir. Örneğin Gmail’deki otomatik tamamlama aracı Google’ın BERT modeli tarafından desteklenir.
LLM’lerin avantajları
LLM’ler, yayımlandıktan sadece birkaç ay sonra tarihin en hızlı büyüyen dijital uygulaması hâline gelen ChatGPT’nin yaygın benimsenmesinin de gösterdiği gibi, kuruluşlar için muazzam bir potansiyele sahiptir.
LLM’lerin hâlihazırda çok sayıda iş uygulaması var ve bu araçlar sektörler ve endüstriler genelinde daha da yaygınlaştıkça kullanım örneklerinin sayısı artacaktır. Aşağıda LLM’lerin bazı faydalarının bir listesini bulabilirsiniz:
- İçerik üretimi. LLM’ler her tür üretken yapay zekâ aracı için güçlüdür. Yetenekleri sayesinde LLM’ler içerik üretimi (ağırlıklı olarak metin; ancak diğer modellerle birlikte kullanıldığında görsel, video ve ses de üretebilirler) için harika araçlardır. İnce ayar sürecinde kullanılan verilere bağlı olarak LLM’ler, hukuktan finansa, sağlıktan pazarlamaya kadar aklınıza gelebilecek her sektörde doğru ve alanına özgü içerik sunabilir.
- NLP görevlerinde artan etkililik. Önceki bölümde açıklandığı gibi LLM’ler birçok NLP görevinde benzersiz performans sunar. İnsan dilini anlayabilir ve insanlarla eşi görülmemiş bir doğrulukla etkileşime girebilirler. Ancak bu araçların kusursuz olmadığını ve zaman zaman hatalı sonuçlar veya hatta halüsinasyonlar üretebileceklerini not etmek önemlidir.
- Artan verimlilik. LLM’lerin başlıca iş faydalarından biri, tekdüze ve zaman alan görevleri saniyeler içinde tamamlamak için mükemmel olmalarıdır. Bu verimlilik sıçramasından faydalanabilecek şirketler için büyük fırsatlar olsa da çalışanlar ve işgücü piyasası açısından dikkate alınması gereken derin etkiler vardır.
LLM’lerin zorlukları ve sınırlamaları
LLM’ler üretken yapay zekâ devriminin ön saflarında yer alıyor. Ancak her yeni teknolojide olduğu gibi, güç sorumluluğu da beraberinde getirir. LLM’lerin benzersiz yeteneklerine rağmen, potansiyel risklerini ve zorluklarını göz önünde bulundurmak önemlidir.
Aşağıda LLM’lerin yaygın benimsenmesiyle ilişkili risk ve zorlukların bir listesini bulabilirsiniz:
- Şeffaflık eksikliği. Algoritmik kapalılık, LLM’lerle ilgili başlıca endişelerden biridir. Bu modeller karmaşıklıkları nedeniyle genellikle ‘siyah kutu’ olarak etiketlenir; bu da akıl yürütmelerini ve iç işleyişlerini izlemeyi imkânsız kılar. Mülki LLM sağlayıcıları genellikle modelleri hakkında bilgi vermeye isteksizdir; bu da izleme ve hesap verebilirliği çok zorlaştırır.
- LLM tekel riski. LLM geliştirmek, eğitmek ve işletmek için gereken ciddi kaynaklar nedeniyle pazar, gerekli bilgi birikimine ve kaynaklara sahip birkaç büyük teknoloji şirketinde yoğunlaşmıştır. Neyse ki giderek artan sayıda açık kaynak LLM piyasaya çıkıyor; bu da geliştiricilerin, yapay zekâ araştırmacılarının ve toplumun LLM’leri anlamasını ve kullanmasını kolaylaştırıyor.
- Önyargı ve ayrımcılık. Önyargılı LLM modelleri, özellikle azınlık gruplarına karşı ayrımcılığı artıran adaletsiz kararlara yol açabilir. Potansiyel önyargıları daha iyi anlamak ve ele almak için burada da şeffaflık esastır.
- Gizlilik sorunları. LLM’ler, çoğunlukla internetten ayrım gözetmeksizin toplanan büyük miktarda veriyle eğitilir. Bu veriler sıklıkla kişisel bilgiler içerir. Bu durum, veri gizliliği ve güvenliğiyle ilgili sorun ve risklere yol açabilir.
- Etik hususlar. LLM’ler bazen yaşamlarımız üzerinde ciddi etkileri olan, temel haklarımızı etkileyen kararlara zemin hazırlayabilir. Üretken yapay zekânın etiğini ayrı bir yazıda inceledik.
- Çevresel hususlar. Araştırmacılar ve çevre gözlemcileri, LLM’lerin eğitim ve işletilmesiyle ilişkili çevresel ayak izine dair endişelerini dile getiriyor. Mülki LLM’ler, tüketilen enerji ve kaynaklar ile bunların çevresel etkisine ilişkin bilgileri nadiren yayımlar; bu da bu araçların hızla benimsenmesi düşünüldüğünde son derece sorunludur.
Farklı LLM türleri ve örnekleri
LLM’lerin tasarımı onları son derece esnek ve uyarlanabilir modeller hâline getirir. Bu modülerlik özellikle şu tür farklı LLM’lere dönüşür:
- Sıfır örnekli (zero-shot) LLM’ler. Bu modeller, herhangi bir eğitim örneği almadan bir görevi tamamlayabilir. Örneğin, yeni kelimelerin geri kalan metinle konumsal ve anlamsal ilişkilerine dayanarak yeni argo ifadeleri anlayabilen bir LLM düşünün.
- İnce ayarlı LLM’ler. Geliştiricilerin, önceden eğitilmiş bir LLM alıp belirli amaçlar için yeni verilerle ince ayar yapması çok yaygındır. LLM ince ayarı hakkında daha fazla bilgi edinmek için LLaMA 2 İnce Ayarı: Büyük Dil Modelini Özelleştirmeye Adım Adım Rehber yazımızı okuyun.
- Alana özgü LLM’ler. Bu modeller, sağlık veya hukuk gibi belirli bir alanın jargonu, bilgisi ve özelliklerini yakalamak için özel olarak tasarlanır. Bu modeller geliştirilirken, eldeki alanın standartlarını karşılaması için seçilmiş (curated) eğitim verilerini tercih etmek önemlidir.
Günümüzde mülki ve açık kaynak LLM sayısı hızla artıyor. ChatGPT’yi duymuş olabilirsiniz; ancak ChatGPT bir LLM değil, bir LLM üzerine inşa edilmiş bir uygulamadır. Özellikle ChatGPT, GPT-3.5 tarafından; ChatGPT-Plus ise şu anda en güçlü LLM olan GPT-4 tarafından desteklenir. OpenAI’ın GPT modellerini nasıl kullanacağınızı öğrenmek için Python'da OpenAI API üzerinden GPT-3.5 ve GPT-4 Kullanımı makalemizi okuyun.
Aşağıda diğer popüler LLM’lerden bazılarının bir listesini bulabilirsiniz:
- BERT. Google tarafından 2018’de geliştirilen ve açık kaynak olarak yayımlanan BERT, ilk modern LLM’lerden ve en başarılılarından biridir. Bu klasik LLM hakkında her şeyi öğrenmek için BERT nedir? başlıklı yazımıza göz atın.
- PaLM 2. Selefi PaLM’den daha gelişmiş bir LLM olan PaLM 2, ChatGPT’ye rakip en iddialı sohbet botu olan Google Bard’ı güçlendiren LLM’dir.
- LLaMa 2. Meta tarafından geliştirilen LLaMa 2, piyasadaki en güçlü açık kaynak LLM’lerden biridir. Bu ve diğer açık kaynak LLM’ler hakkında daha fazla bilgi edinmek için 2024'ün En İyi 8 Açık Kaynak LLM'i başlıklı makalemizi okumanızı öneririz.
Sonuç
LLM’ler, mevcut üretken yapay zekâ patlamasına güç veriyor. Potansiyel uygulamalar o kadar geniş ki, veri bilimi dâhil her sektör ve endüstri, gelecekte LLM’lerin benimsenmesinden etkilenecek gibi görünüyor.
Olanaklar sınırsız, ancak riskler ve zorluklar da öyle. Dönüştürücü etkileriyle LLM’ler, geleceğe ve yapay zekânın işgücü piyasasını ve toplumlarımızın birçok yönünü nasıl etkileyeceğine dair spekülasyonları tetikledi. Bu, çok şeyin söz konusu olduğu önemli bir tartışma ve kararlılıkla, kolektif biçimde ele alınması gerekiyor.
DataCamp, herkesin yapay zekâ gelişmelerini takip edebilmesi için kapsamlı ve erişilebilir kaynaklar sunmak üzere yoğun şekilde çalışıyor. Göz atın:
- Büyük Dil Modelleri (LLM) Kavramları Kursu
- LangChain ile LLM Uygulamaları Nasıl Geliştirilir
- PyTorch ile Bir LLM Nasıl Eğitilir: Adım Adım Rehber
- 2024 İçin En İyi 8 Açık Kaynak LLM ve Kullanımları
- Llama.cpp Eğitimi: Verimli LLM Çıkarımı ve Uygulamasına Kapsamlı Rehber
- Veri Mühendisliği ve Veri Uygulamaları için LangChain'e Giriş
- LlamaIndex: Büyük Dil Modelleri (LLM) Tabanlı Uygulamalar için Bir Veri Çerçevesi
- 2024'te Sıfırdan Yapay Zekâ Nasıl Öğrenilir: Kapsamlı Uzman Rehberi

