Nếu bạn đang đọc bài viết này, rất có thể bạn đã nghe nói về các mô hình ngôn ngữ lớn (LLM). Ai mà chưa nghe chứ? Rốt cuộc, LLM đứng sau những công cụ siêu phổ biến đang tiếp sức cho cuộc cách mạng AI sinh sinh hiện nay, bao gồm ChatGPT, Google Bard và DALL-E.
Để tạo ra điều kỳ diệu của mình, các công cụ này dựa vào một công nghệ mạnh mẽ cho phép chúng xử lý dữ liệu và tạo nội dung chính xác để đáp lại câu hỏi do người dùng đưa ra. Đây chính là lúc LLM phát huy tác dụng.
Bài viết này nhằm giới thiệu bạn về LLM. Sau khi đọc các phần dưới đây, chúng ta sẽ biết LLM là gì, cách chúng hoạt động, các loại LLM khác nhau kèm ví dụ, cũng như ưu điểm và hạn chế của chúng.
Đối với những người mới bắt đầu, khóa học Khái niệm về Mô hình Ngôn ngữ Lớn (LLM) của chúng tôi là nơi lý tưởng để có cái nhìn sâu rộng về LLM. Tuy nhiên, nếu bạn đã quen thuộc với LLM và muốn tiến thêm một bước bằng cách học cách xây dựng ứng dụng chạy bằng LLM, hãy xem bài viết Cách xây dựng ứng dụng LLM với LangChain.
Bắt đầu thôi!
Mô hình Ngôn ngữ Lớn là gì?
LLM là các hệ thống AI dùng để mô hình hóa và xử lý ngôn ngữ tự nhiên của con người. Chúng được gọi là “lớn” vì các mô hình kiểu này thường gồm hàng trăm triệu hoặc thậm chí hàng tỷ tham số quyết định hành vi của mô hình, được tiền huấn luyện bằng một tập văn bản khổng lồ.
Công nghệ nền tảng của LLM được gọi là mạng nơ-ron transformer, thường được gọi ngắn gọn là transformer. Như chúng tôi sẽ giải thích chi tiết hơn ở phần tiếp theo, transformer là một kiến trúc nơ-ron đổi mới trong lĩnh vực học sâu.
Được giới thiệu bởi các nhà nghiên cứu Google trong bài báo nổi tiếng Attention is All You Need năm 2017, transformer có khả năng thực hiện các tác vụ xử lý ngôn ngữ tự nhiên (NLP) với độ chính xác và tốc độ chưa từng có. Với những năng lực độc đáo, transformer đã mang lại bước nhảy vọt đáng kể cho khả năng của LLM. Có thể nói rằng, nếu không có transformer, cuộc cách mạng AI sinh sinh hiện nay sẽ không thể xảy ra.
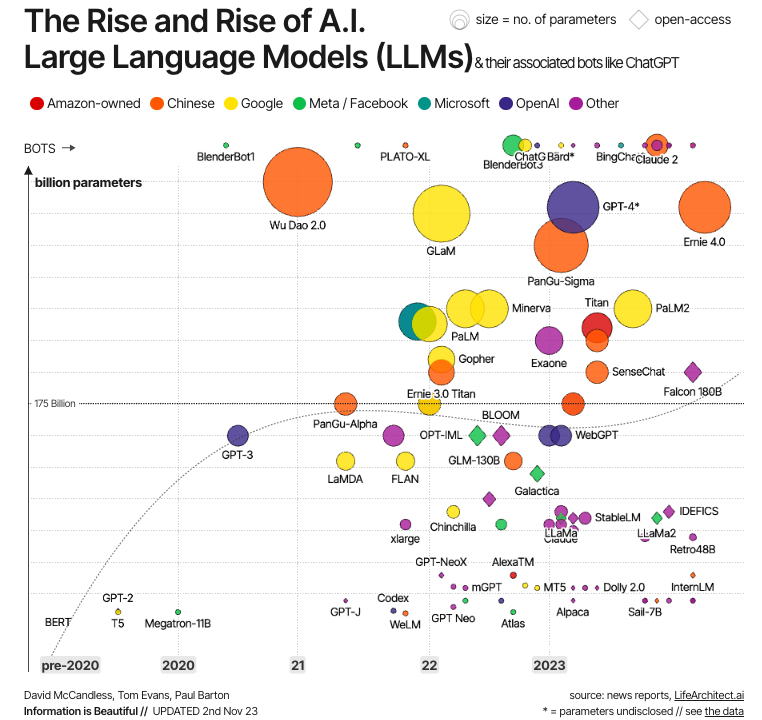
Nguồn: Information is Beautiful
Sự tiến hóa này được minh họa trong biểu đồ trên. Như có thể thấy, các LLM hiện đại đầu tiên được tạo ngay sau khi transformer ra đời, với các ví dụ tiêu biểu như BERT – LLM đầu tiên do Google phát triển để kiểm nghiệm sức mạnh của transformer –, cũng như GPT-1 và GPT-2, hai mô hình đầu tiên trong dòng GPT do OpenAI tạo ra. Nhưng chỉ đến thập niên 2020, LLM mới trở nên phổ biến, ngày càng lớn hơn (xét theo số tham số), và do đó mạnh hơn, với các ví dụ quen thuộc như GPT-4 và LLaMa.
LLM hoạt động như thế nào?
Chìa khóa thành công của các LLM hiện đại là kiến trúc transformer. Trước khi transformer được các nhà nghiên cứu Google phát triển, việc mô hình hóa ngôn ngữ tự nhiên là một nhiệm vụ rất thách thức. Dù các mạng nơ-ron tinh vi – như hồi quy (recurrent) hay tích chập (convolutional) – đã xuất hiện, kết quả chỉ thành công một phần.
Thách thức chính nằm ở chiến lược mà các mạng nơ-ron này dùng để dự đoán từ còn thiếu trong câu. Trước transformer, các mạng nơ-ron tối tân dựa vào kiến trúc mã hóa - giải mã (encoder-decoder), một cơ chế mạnh nhưng tốn thời gian và tài nguyên, không phù hợp cho tính toán song song, do đó hạn chế khả năng mở rộng.
Transformer cung cấp một lựa chọn thay thế cho các mạng nơ-ron truyền thống để xử lý dữ liệu tuần tự, cụ thể là văn bản (mặc dù transformer cũng đã được dùng với các loại dữ liệu khác như hình ảnh và âm thanh, và cũng thành công tương tự).
Các thành phần của LLM
Transformer dựa trên cùng kiến trúc mã hóa - giải mã như các mạng nơ-ron hồi quy và tích chập. Kiến trúc này nhằm khám phá các mối quan hệ thống kê giữa các token văn bản.
Điều này được thực hiện thông qua sự kết hợp các kỹ thuật nhúng (embedding). Embedding là cách biểu diễn các token, như câu, đoạn hay tài liệu, trong không gian vector có số chiều lớn, nơi mỗi chiều tương ứng với một đặc trưng hay thuộc tính ngôn ngữ đã học.
Quá trình embedding diễn ra ở bộ mã hóa (encoder). Do kích thước khổng lồ của LLM, việc tạo embedding đòi hỏi huấn luyện chuyên sâu và tài nguyên đáng kể. Tuy nhiên, điểm khác biệt của transformer so với các mạng nơ-ron trước đây là quá trình embedding có thể song song hóa cao, giúp xử lý hiệu quả hơn. Điều này khả thi nhờ cơ chế attention.
Các mạng nơ-ron hồi quy và tích chập dự đoán từ dựa hoàn toàn vào các từ trước đó. Theo nghĩa này, chúng có thể coi là một chiều. Ngược lại, cơ chế attention cho phép transformer dự đoán từ theo hai chiều, tức dựa vào cả các từ đứng trước lẫn đứng sau. Mục tiêu của lớp attention, có trong cả encoder và decoder, là nắm bắt các mối quan hệ ngữ cảnh giữa những từ khác nhau trong câu đầu vào.
Để hiểu chi tiết cách kiến trúc mã hóa - giải mã hoạt động trong transformer, chúng tôi khuyến nghị bạn đọc Giới thiệu về Sử dụng Transformers và Hugging Face.
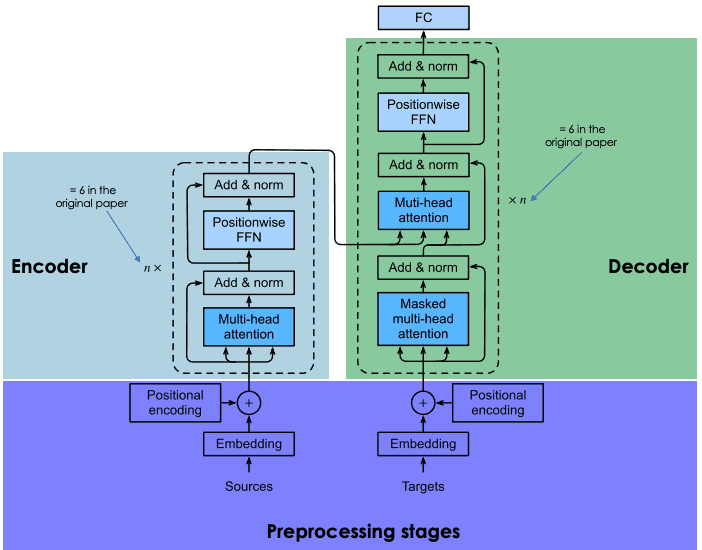
Giải thích kiến trúc của transformer
Huấn luyện LLM
Huấn luyện transformer gồm hai bước: tiền huấn luyện và tinh chỉnh.
Tiền huấn luyện
Trong giai đoạn này, transformer được huấn luyện trên lượng lớn dữ liệu văn bản thô. Internet là nguồn dữ liệu chính.
Việc huấn luyện được thực hiện bằng các kỹ thuật học không giám sát, một dạng huấn luyện đổi mới không cần con người gán nhãn dữ liệu.
Mục tiêu của tiền huấn luyện là học các mẫu thống kê của ngôn ngữ. Chiến lược tối tân để đạt độ chính xác cao hơn cho transformer là làm mô hình lớn hơn (có thể bằng cách tăng số tham số) và tăng kích thước dữ liệu huấn luyện. Kết quả là, hầu hết các LLM tiên tiến có hàng tỷ tham số (ví dụ, PaLM 2 có 340 tỷ tham số, và GPT-4 được ước tính khoảng 1,8 nghìn tỷ tham số) và được huấn luyện trên một kho dữ liệu khổng lồ.
Xu hướng này tạo ra vấn đề về khả năng tiếp cận. Do kích thước mô hình và dữ liệu huấn luyện, quá trình tiền huấn luyện thường tốn thời gian và chi phí, chỉ một nhóm nhỏ công ty có thể kham nổi.
Tinh chỉnh
Tiền huấn luyện giúp transformer có hiểu biết cơ bản về ngôn ngữ, nhưng chưa đủ để thực hiện các tác vụ thực tiễn cụ thể với độ chính xác cao.
Để tránh các vòng lặp huấn luyện tốn thời gian và chi phí, transformer tận dụng các kỹ thuật học chuyển giao để tách pha (tiền) huấn luyện khỏi pha tinh chỉnh. Điều này cho phép nhà phát triển chọn các mô hình đã tiền huấn luyện và tinh chỉnh chúng dựa trên một cơ sở dữ liệu hẹp hơn, theo miền cụ thể. Trong nhiều trường hợp, quá trình tinh chỉnh được tiến hành với sự hỗ trợ của người đánh giá, bằng kỹ thuật Học tăng cường từ phản hồi của con người.
Quy trình huấn luyện hai bước cho phép điều chỉnh LLM cho nhiều tác vụ hạ nguồn. Nói cách khác, đặc tính này khiến LLM trở thành mô hình nền tảng cho vô số ứng dụng xây dựng trên chúng.
Tính đa phương thức của LLM
Các LLM hiện đại đầu tiên là mô hình văn bản-sang-văn bản (tức nhận đầu vào là văn bản và sinh đầu ra là văn bản). Tuy nhiên, những năm gần đây, các nhà phát triển đã tạo ra các LLM gọi là đa phương thức. Các mô hình này kết hợp dữ liệu văn bản với những loại thông tin khác, bao gồm hình ảnh, âm thanh và video. Sự kết hợp các kiểu dữ liệu khác nhau đã cho phép tạo ra các mô hình chuyên biệt tinh vi, như DALL-E của OpenAI để tạo ảnh, và AudioCraft của Meta để tạo nhạc và âm thanh.
LLM được dùng để làm gì?
Được tăng lực bởi transformer, các LLM hiện đại đã đạt hiệu năng hàng đầu trong nhiều tác vụ NLP. Dưới đây là một số tác vụ nơi LLM mang lại kết quả vượt trội:
- Sinh văn bản. LLM như ChatGPT có thể tạo văn bản dài, phức tạp và tự nhiên như con người chỉ trong vài giây.
- Dịch thuật. Khi LLM được huấn luyện bằng nhiều ngôn ngữ, chúng có thể thực hiện các thao tác dịch ở mức độ cao. Với tính đa phương thức, khả năng là vô hạn. Ví dụ, mô hình SeamlessM4T của Meta có thể dịch giọng nói-sang-văn bản, giọng nói-sang-giọng nói, văn bản-sang-giọng nói và văn bản-sang-văn bản cho đến 100 ngôn ngữ tùy tác vụ.
- Phân tích cảm xúc. Mọi loại phân tích cảm xúc đều có thể thực hiện với LLM, từ dự đoán đánh giá phim tích cực/tiêu cực đến ý kiến về các chiến dịch tiếp thị.
- AI hội thoại. Là công nghệ nền của chatbot hiện đại, LLM rất giỏi đặt câu hỏi, trả lời và duy trì hội thoại ngay cả trong các tác vụ phức tạp.
- Tự động hoàn thành. LLM có thể dùng cho các tác vụ tự động hoàn thành, ví dụ trong email hoặc dịch vụ nhắn tin. Chẳng hạn, BERT của Google cung cấp năng lực tự động hoàn thành trong Gmail.
Ưu điểm của LLM
LLM có tiềm năng to lớn cho các tổ chức, thể hiện qua việc ChatGPT được áp dụng rộng rãi và chỉ vài tháng sau khi ra mắt đã trở thành ứng dụng kỹ thuật số phát triển nhanh nhất mọi thời đại.
Đã có khá nhiều ứng dụng kinh doanh của LLM, và số lượng trường hợp sử dụng sẽ còn tăng khi các công cụ này trở nên phổ biến hơn trên các lĩnh vực và ngành nghề. Dưới đây là một số lợi ích của LLM:
- Tạo nội dung. LLM là thành phần mạnh mẽ của mọi công cụ AI sinh sinh. Với năng lực của mình, LLM rất phù hợp để tạo nội dung (chủ yếu là văn bản, nhưng kết hợp với các mô hình khác, chúng cũng có thể tạo hình ảnh, video và âm thanh). Tùy vào dữ liệu dùng trong quá trình tinh chỉnh, LLM có thể cung cấp nội dung chính xác theo miền trong bất kỳ lĩnh vực nào bạn có thể nghĩ tới, từ pháp lý và tài chính đến y tế và tiếp thị.
- Tăng hiệu quả trong các tác vụ NLP. Như đã giải thích ở phần trước, LLM mang lại hiệu năng vượt trội ở nhiều tác vụ NLP. Chúng có khả năng hiểu ngôn ngữ con người và tương tác với con người với độ chính xác chưa từng có. Tuy nhiên, cần lưu ý rằng các công cụ này không hoàn hảo và vẫn có thể đưa ra kết quả thiếu chính xác hoặc thậm chí ảo giác tổng thể,
- Tăng hiệu suất. Một trong những lợi ích kinh doanh chính của LLM là chúng rất phù hợp để hoàn thành các công việc đơn điệu, tốn thời gian chỉ trong vài giây. Dù có triển vọng lớn cho các công ty có thể hưởng lợi từ bước nhảy vọt về hiệu suất này, nhưng cũng có những hệ lụy sâu sắc đối với người lao động và thị trường việc làm cần được cân nhắc.
Thách thức và hạn chế của LLM
LLM đang ở tuyến đầu của cuộc cách mạng AI sinh sinh. Tuy nhiên, như thường xảy ra với công nghệ mới nổi, quyền năng đi kèm trách nhiệm. Dù có năng lực độc đáo, điều quan trọng là cân nhắc các rủi ro và thách thức tiềm ẩn của LLM.
Dưới đây là danh sách các rủi ro và thách thức liên quan đến việc áp dụng LLM rộng rãi:
- Thiếu minh bạch. Độ mờ thuật toán là một trong những mối lo ngại chính liên quan đến LLM. Những mô hình này thường bị gắn nhãn là “hộp đen” do độ phức tạp, khiến không thể giám sát lập luận và hoạt động bên trong của chúng. Các nhà cung cấp AI với LLM sở hữu độc quyền thường ngần ngại cung cấp thông tin về mô hình, khiến việc giám sát và quy trách nhiệm trở nên rất khó khăn.
- Độc quyền LLM. Do nguồn lực đáng kể cần thiết để phát triển, huấn luyện và vận hành LLM, thị trường tập trung cao vào một nhóm các hãng công nghệ lớn có đủ bí quyết và nguồn lực. May mắn thay, ngày càng có nhiều LLM mã nguồn mở ra mắt, giúp nhà phát triển, nhà nghiên cứu AI và xã hội dễ hiểu và vận hành LLM hơn.
- Thiên lệch và phân biệt đối xử. Các mô hình LLM thiên lệch có thể dẫn đến quyết định không công bằng, thường làm trầm trọng thêm phân biệt đối xử, đặc biệt với các nhóm thiểu số. Một lần nữa, minh bạch là điều thiết yếu để hiểu rõ và xử lý các thiên lệch tiềm ẩn.
- Vấn đề quyền riêng tư. LLM được huấn luyện với lượng dữ liệu khổng lồ chủ yếu trích xuất tràn lan từ Internet. Thông thường, dữ liệu này có chứa dữ liệu cá nhân. Điều này có thể dẫn đến các vấn đề và rủi ro liên quan đến quyền riêng tư và an toàn dữ liệu.
- Cân nhắc đạo đức. LLM đôi khi có thể dẫn đến các quyết định có hệ quả nghiêm trọng trong cuộc sống của chúng ta, ảnh hưởng đáng kể đến các quyền cơ bản. Chúng tôi đã bàn về đạo đức của AI sinh sinh trong một bài viết riêng.
- Cân nhắc môi trường. Các nhà nghiên cứu và tổ chức giám sát môi trường đang bày tỏ lo ngại về dấu chân môi trường liên quan đến việc huấn luyện và vận hành LLM. Các LLM sở hữu độc quyền hiếm khi công bố thông tin về năng lượng và tài nguyên tiêu thụ, cũng như dấu chân môi trường đi kèm, điều này đặc biệt đáng lo trong bối cảnh các công cụ này được áp dụng nhanh chóng.
Các loại LLM khác nhau và ví dụ
Thiết kế của LLM khiến chúng trở thành các mô hình cực kỳ linh hoạt và thích ứng. Tính mô-đun này thể hiện ở các loại LLM khác nhau, cụ thể:
- LLM zero-shot. Những mô hình này có thể hoàn thành một tác vụ mà không cần bất kỳ ví dụ huấn luyện nào. Ví dụ, hãy hình dung một LLM có khả năng hiểu tiếng lóng mới dựa trên quan hệ vị trí và ngữ nghĩa của các từ mới này với phần còn lại của văn bản.
- LLM tinh chỉnh. Nhà phát triển rất thường xuyên lấy một LLM đã tiền huấn luyện và tinh chỉnh bằng dữ liệu mới cho các mục đích cụ thể. Để tìm hiểu thêm về tinh chỉnh LLM, hãy đọc bài Tinh chỉnh LLaMA 2: Hướng dẫn từng bước để tùy biến Mô hình Ngôn ngữ Lớn.
- LLM theo miền. Những mô hình này được thiết kế riêng để nắm bắt biệt ngữ, kiến thức và đặc thù của một lĩnh vực hay ngành nhất định, như y tế hoặc pháp lý. Khi phát triển các mô hình này, điều quan trọng là chọn dữ liệu huấn luyện đã được chọn lọc, để mô hình đáp ứng các tiêu chuẩn của lĩnh vực liên quan.
Ngày nay, số lượng LLM sở hữu độc quyền và mã nguồn mở đang tăng nhanh. Bạn có thể đã nghe về ChatGPT, nhưng ChatGPT không phải là LLM, mà là một ứng dụng xây dựng trên LLM. Cụ thể, ChatGPT chạy bằng GPT-3.5, trong khi ChatGPT-Plus chạy bằng GPT-4, hiện là LLM mạnh nhất. Để biết thêm cách sử dụng các mô hình GPT của OpenAI, hãy đọc bài Sử dụng GPT-3.5 và GPT-4 qua OpenAI API trong Python.
Dưới đây là danh sách một số LLM phổ biến khác:
- BERT. Do Google phát triển năm 2018 và phát hành mã nguồn mở, BERT là một trong những LLM hiện đại đầu tiên và thành công nhất. Xem bài BERT là gì? để biết mọi điều về LLM kinh điển này.
- PaLM 2. Một LLM tiên tiến hơn so với tiền nhiệm PaLM, PaLM 2 là LLM cung cấp sức mạnh cho Google Bard, chatbot tham vọng nhất cạnh tranh với ChatGPT.
- LLaMa 2. Được Meta phát triển, LLaMa 2 là một trong những LLM mã nguồn mở mạnh mẽ nhất trên thị trường. Để tìm hiểu thêm về mô hình này và các LLM mã nguồn mở khác, chúng tôi khuyến nghị bạn đọc bài tổng hợp 8 LLM Mã nguồn mở Hàng đầu.
Kết luận
LLM đang tiếp sức cho làn sóng bùng nổ AI sinh sinh hiện nay. Các ứng dụng tiềm năng rộng lớn đến mức mọi lĩnh vực và ngành nghề, bao gồm cả khoa học dữ liệu, nhiều khả năng sẽ chịu tác động từ việc áp dụng LLM trong tương lai.
Khả năng là vô hạn, nhưng rủi ro và thách thức cũng vậy. Với tính chất chuyển đổi của mình, LLM đã làm dấy lên suy đoán về tương lai và cách AI sẽ ảnh hưởng đến thị trường việc làm cùng nhiều khía cạnh khác của xã hội. Đây là một cuộc thảo luận quan trọng cần được giải quyết một cách kiên định và tập thể vì có quá nhiều điều hệ trọng.
DataCamp đang nỗ lực cung cấp các tài nguyên toàn diện và dễ tiếp cận để mọi người luôn cập nhật diễn biến AI. Hãy khám phá chúng:
- Khóa học Khái niệm về Mô hình Ngôn ngữ Lớn (LLM)
- Cách xây dựng ứng dụng LLM với LangChain
- Cách huấn luyện LLM với PyTorch: Hướng dẫn từng bước
- 8 LLM Mã nguồn mở Hàng đầu cho 2024 và Ứng dụng của chúng
- Hướng dẫn Llama.cpp: Cẩm nang đầy đủ về suy luận và triển khai LLM hiệu quả
- Giới thiệu LangChain cho Kỹ thuật Dữ liệu & Ứng dụng Dữ liệu
- LlamaIndex: Khung dữ liệu cho các ứng dụng dựa trên Mô hình Ngôn ngữ Lớn (LLM)
- Cách học AI từ con số 0 năm 2024: Hướng dẫn đầy đủ của chuyên gia
