Als je dit artikel leest, heb je waarschijnlijk al gehoord over large language models (LLM’s). Wie niet? LLM’s liggen tenslotte achter de razend populaire tools die de huidige generatieve AI-revolutie aanjagen, waaronder ChatGPT, Google Bard en DALL-E.
Om hun magie te leveren, leunen deze tools op een krachtige technologie die hen in staat stelt data te verwerken en nauwkeurige content te genereren als antwoord op de vraag van de gebruiker. Daar komen LLM’s om de hoek kijken.
Dit artikel wil je kennis laten maken met LLM’s. Na het lezen van de volgende secties weten we wat LLM’s zijn, hoe ze werken, de verschillende typen LLM’s met voorbeelden, en wat hun voordelen en beperkingen zijn.
Voor nieuwkomers is onze Large Language Models (LLMs) Concepts Course de perfecte plek voor een grondig overzicht van LLM’s. Ben je echter al bekend met LLM’s en wil je een stap verder gaan door te leren hoe je LLM-gestuurde applicaties bouwt, bekijk dan ons artikel How to Build LLM Applications with LangChain.
Laten we beginnen!
Wat is een Large Language Model?
LLM’s zijn AI-systemen die worden gebruikt om menselijke taal te modelleren en te verwerken. Ze worden “large” genoemd omdat dit soort modellen doorgaans uit honderden miljoenen of zelfs miljarden parameters bestaat die het gedrag van het model bepalen en die vooraf zijn getraind met een enorme hoeveelheid tekstdata.
De onderliggende technologie van LLM’s heet transformer-neuraal netwerk, kortweg een transformer. Zoals we in de volgende sectie uitgebreider zullen uitleggen, is een transformer een innovatieve neurale architectuur binnen het domein van deep learning.
Aangeboden door Google-onderzoekers in de beroemde paper Attention is All You Need uit 2017, zijn transformers in staat NLP-taken met ongekende nauwkeurigheid en snelheid uit te voeren. Met hun unieke capaciteiten hebben transformers een grote sprong voorwaarts mogelijk gemaakt in wat LLM’s kunnen. Je kunt gerust stellen dat zonder transformers de huidige generatieve AI-revolutie niet mogelijk zou zijn.
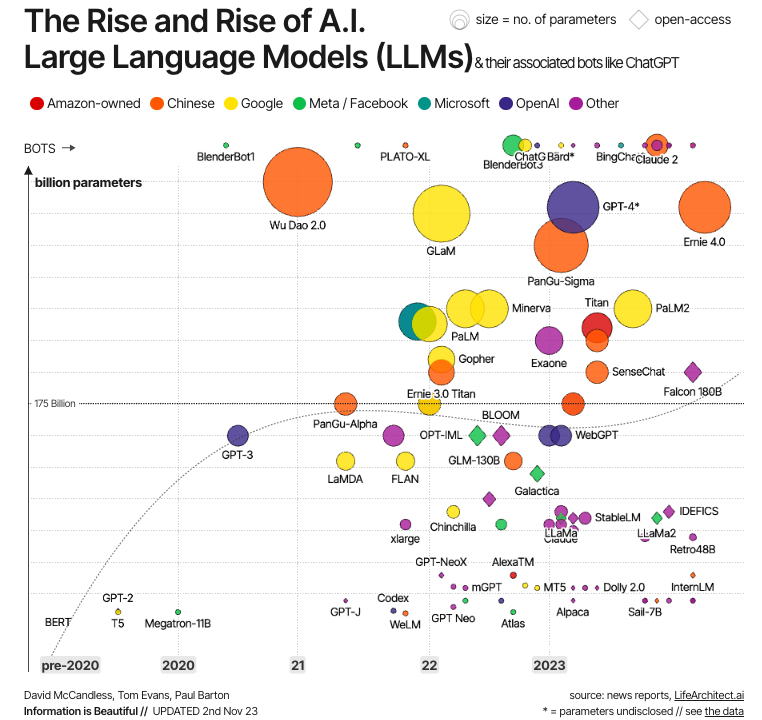
Bron: Information is Beautiful
Deze evolutie is weergegeven in de grafiek hierboven. Zoals we zien, ontstonden de eerste moderne LLM’s direct na de ontwikkeling van transformers, met als belangrijkste voorbeelden BERT – het eerste LLM dat door Google werd ontwikkeld om de kracht van transformers te testen – en GPT-1 en GPT-2, de eerste twee modellen in de GPT-serie van OpenAI. Maar pas in de jaren 2020 werden LLM’s mainstream, steeds groter (qua parameters) en daardoor krachtiger, met bekende voorbeelden als GPT-4 en LLaMa.
Hoe werken LLM’s?
De sleutel tot het succes van moderne LLM’s is de transformer-architectuur. Voordat transformers door Google-onderzoekers werden ontwikkeld, was het modelleren van natuurlijke taal een zeer uitdagende taak. Ondanks de opkomst van geavanceerde neurale netwerken – zoals recurrente of convolutionele neurale netwerken – waren de resultaten slechts deels succesvol.
De grootste uitdaging zit in de strategie die deze neurale netwerken gebruiken om het ontbrekende woord in een zin te voorspellen. Voor transformers vertrouwden state-of-the-art neurale netwerken op de encoder-decoderarchitectuur, een krachtige maar tijd- en middelenintensieve aanpak die ongeschikt is voor parallelle verwerking en daardoor de schaalbaarheid beperkt.
Transformers bieden een alternatief voor traditionele neurale benaderingen om sequentiële data te verwerken, met name tekst (al zijn transformers ook succesvol toegepast op andere datatypen, zoals afbeeldingen en audio).
Componenten van LLM’s
Transformers zijn gebaseerd op dezelfde encoder-decoderarchitectuur als recurrente en convolutionele neurale netwerken. Zo’n neurale architectuur is erop gericht statistische relaties tussen teksttokens te ontdekken.
Dit gebeurt via een combinatie van embeddingtechnieken. Embeddings zijn representaties van tokens, zoals zinnen, alinea’s of documenten, in een hoog-dimensionale vectorruimte, waarbij elke dimensie overeenkomt met een geleerde eigenschap of kenmerk van de taal.
Het embedden vindt plaats in de encoder. Door de enorme omvang van LLM’s vergt het maken van embeddings intensieve training en aanzienlijke middelen. Wat transformers echter onderscheidt van eerdere neurale netwerken, is dat het embedden sterk te parallelliseren is, wat efficiëntere verwerking mogelijk maakt. Dit is te danken aan het attention-mechanisme.
Recurrente en convolutionele neurale netwerken baseren hun woordvoorspellingen uitsluitend op voorgaande woorden. In die zin zijn ze unidirectioneel. Daarentegen stelt het attention-mechanisme transformers in staat woorden bidirectioneel te voorspellen, dus op basis van zowel de voorgaande als de volgende woorden. Het doel van de attention-laag, die zowel in de encoder als de decoder is opgenomen, is om de contextuele relaties tussen verschillende woorden in de invoerzinnen vast te leggen.
Wil je precies weten hoe de encoder-decoderarchitectuur in transformers werkt, lees dan zeker onze Introduction to Using Transformers and Hugging Face.
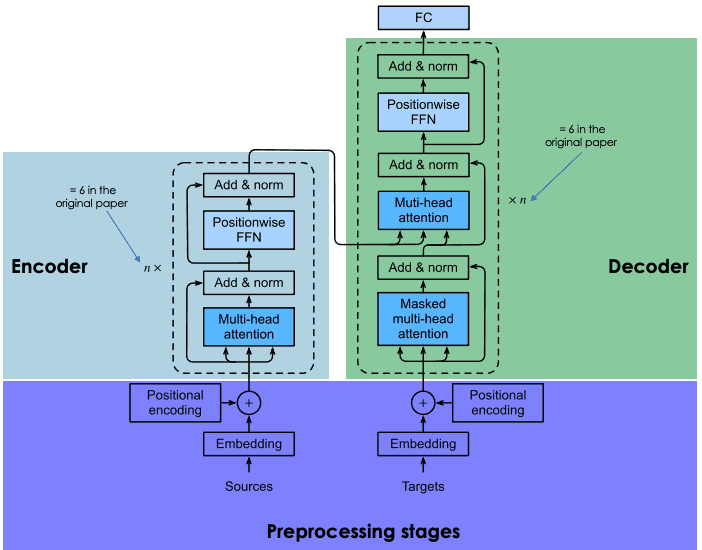
Een uitleg van de architectuur van transformers
LLM’s trainen
Het trainen van transformers omvat twee stappen: pretraining en fine-tuning.
Pretraining
In deze fase worden transformers getraind op grote hoeveelheden ruwe tekstdata. Het internet is de primaire databron.
De training gebeurt met unsupervised learning-technieken, een vernieuwende manier van trainen die geen menselijke actie vereist om data te labelen.
Het doel van pretraining is het leren van de statistische patronen van de taal. De state-of-the-art strategie om de nauwkeurigheid van transformers te verbeteren, is het model groter maken (door het aantal parameters te verhogen) en de trainingsdata te vergroten. Daardoor hebben de meest geavanceerde LLM’s miljarden parameters (zo heeft PaLM 2 340 miljard parameters en wordt geschat dat GPT-4 ongeveer 1,8 biljoen parameters heeft) en zijn ze getraind op een gigantische hoeveelheid data.
Deze trend brengt toegankelijkheidsproblemen met zich mee. Gezien de omvang van het model en de trainingsdata is het pretrainingsproces doorgaans tijdrovend en kostbaar, iets wat slechts een beperkte groep bedrijven zich kan veroorloven.
Fine-tuning
Pretraining geeft een transformer een basaal taalbegrip, maar dat is niet genoeg om specifieke praktische taken met hoge nauwkeurigheid uit te voeren.
Om tijdrovende en dure iteraties in het trainingsproces te vermijden, maken transformers gebruik van transfer learning-technieken om de (pre)trainingsfase te scheiden van de fine-tuningfase. Zo kunnen ontwikkelaars vooraf getrainde modellen kiezen en die fijnslijpen op basis van een smallere, domeinspecifieke database. In veel gevallen gebeurt het fine-tunen met hulp van menselijke reviewers, via een techniek die Reinforcement Learning from Human Feedback heet.
Het tweestaps-trainingsproces maakt de aanpassing van LLM’s aan een breed scala aan downstreamtaken mogelijk. Anders gezegd: deze eigenschap maakt van LLM’s het foundation model voor eindeloze toepassingen die erop voortbouwen.
Multimodaliteit van LLM’s
De eerste moderne LLM’s waren tekst-naar-tekstmodellen (dus ze ontvingen tekstinput en genereerden tekstoutput). In de afgelopen jaren hebben ontwikkelaars echter zogeheten multimodale LLM’s gemaakt. Deze modellen combineren tekstdata met andere soorten informatie, waaronder afbeeldingen, audio en video. De combinatie van verschillende soorten data heeft geleid tot geavanceerde, taakspecifieke modellen, zoals OpenAI’s DALL-E voor beeldgeneratie en Meta’s AudioCraft voor muziek- en audiogeneratie.
Waarvoor worden LLM’s gebruikt?
Aangedreven door transformers hebben moderne LLM’s state-of-the-art prestaties behaald in meerdere NLP-taken. Dit zijn enkele taken waarin LLM’s unieke resultaten hebben geleverd:
- Tekstgeneratie. LLM’s zoals ChatGPT kunnen lange, complexe en mensachtige teksten in enkele seconden creëren.
- Vertaling. Wanneer LLM’s in meerdere talen zijn getraind, kunnen ze vertalingen op hoog niveau uitvoeren. Met multimodaliteit zijn de mogelijkheden eindeloos. Zo kan Meta’s SeamlessM4T-model spraak-naar-tekst, spraak-naar-spraak, tekst-naar-spraak en tekst-naar-tekst vertalingen doen voor tot wel 100 talen, afhankelijk van de taak.
- Sentimentanalyse. Alle soorten sentimentanalyse kunnen met LLM’s worden uitgevoerd, van voorspellingen van positieve en negatieve filmrecensies tot meningen over marketingcampagnes.
- Conversational AI. Als de onderliggende technologie van moderne chatbots zijn LLM’s uitstekend in vragen stellen, beantwoorden en gesprekken voeren, zelfs bij complexe taken.
- Autocompletion. LLM’s kunnen worden gebruikt voor automatische aanvulfuncties, bijvoorbeeld in e-mails of berichtendiensten. Zo wordt Google’s BERT gebruikt voor de autocomplete-tool in Gmail.
Voordelen van LLM’s
LLM’s hebben een enorm potentieel voor organisaties, zoals blijkt uit de brede adoptie van ChatGPT, dat al enkele maanden na de lancering de snelst groeiende digitale applicatie ooit werd.
Er zijn nu al tal van zakelijke toepassingen van LLM’s, en het aantal use-cases zal alleen maar toenemen naarmate deze tools sectoren en industrieën doordringen. Hieronder vind je een lijst met enkele voordelen van LLM’s:
- Contentcreatie. LLM’s zijn krachtige generatieve AI-tools. Met hun capaciteiten zijn LLM’s geweldige hulpmiddelen voor het genereren van content (vooral tekst, maar in combinatie met andere modellen ook afbeeldingen, video en audio). Afhankelijk van de data die in het fine-tunen worden gebruikt, kunnen LLM’s nauwkeurige, domeinspecifieke content leveren in elke sector die je maar kunt bedenken, van juridisch en finance tot gezondheidszorg en marketing.
- Hogere effectiviteit in NLP-taken. Zoals in de vorige sectie uitgelegd, leveren LLM’s unieke prestaties in veel NLP-taken. Ze begrijpen menselijke taal en communiceren met mensen met ongekende nauwkeurigheid. Het is echter belangrijk te benadrukken dat deze tools niet perfect zijn en nog steeds onnauwkeurige resultaten of zelfs hallucinaties kunnen geven.
- Meer efficiëntie. Een van de belangrijkste zakelijke voordelen van LLM’s is dat ze uitermate geschikt zijn om monotone, tijdrovende taken in enkele seconden uit te voeren. Hoewel er grote vooruitzichten zijn voor bedrijven die van deze efficiencysprong kunnen profiteren, zijn er ook ingrijpende gevolgen voor werknemers en de arbeidsmarkt die aandacht verdienen.
Uitdagingen en beperkingen van LLM’s
LLM’s staan vooraan in de generatieve AI-revolutie. Maar zoals altijd bij opkomende technologieën, komt met macht ook verantwoordelijkheid. Ondanks de unieke capaciteiten van LLM’s is het belangrijk om de potentiële risico’s en uitdagingen te overwegen.
Hieronder vind je een lijst met risico’s en uitdagingen die samenhangen met de brede adoptie van LLM’s:
- Gebrek aan transparantie. Algoritmische ondoorzichtigheid is een van de belangrijkste zorgen rond LLM’s. Deze modellen worden vaak ‘black box’ genoemd vanwege hun complexiteit, waardoor hun redenering en innerlijke werking niet te volgen zijn. AI-aanbieders van propriëtaire LLM’s zijn vaak terughoudend met het verstrekken van informatie over hun modellen, wat monitoring en verantwoording zeer moeilijk maakt.
- LLM-monopolie. Gezien de aanzienlijke middelen die nodig zijn om LLM’s te ontwikkelen, trainen en exploiteren, is de markt sterk geconcentreerd bij een handvol Big Tech-bedrijven met de benodigde expertise en middelen. Gelukkig komen er steeds meer open-source LLM’s op de markt, waardoor het voor ontwikkelaars, AI-onderzoekers en de samenleving gemakkelijker wordt om LLM’s te begrijpen en te gebruiken.
- Bias en discriminatie. Vooringenomen LLM-modellen kunnen leiden tot oneerlijke beslissingen die vaak discriminatie verergeren, met name tegen minderheidsgroepen. Ook hier is transparantie essentieel om mogelijke biases beter te begrijpen en aan te pakken.
- Privacykwesties. LLM’s worden getraind met enorme hoeveelheden data die voornamelijk ongericht van het internet zijn gehaald. Vaak bevat die persoonlijke gegevens. Dit kan leiden tot problemen en risico’s rond gegevensprivacy en -beveiliging.
- Ethische overwegingen. LLM’s kunnen soms leiden tot beslissingen met grote gevolgen voor ons leven, met aanzienlijke impact op onze grondrechten. We verkenden de ethiek van generatieve AI in een apart bericht.
- Milieuoverwegingen. Onderzoekers en milieuwaakhonden uiten zorgen over de ecologische voetafdruk die samenhangt met het trainen en gebruiken van LLM’s. Propriëtaire LLM’s publiceren zelden informatie over de energie en middelen die LLM’s verbruiken, noch over de bijbehorende milieu-impact, wat uiterst problematisch is bij de snelle adoptie van deze tools.
Verschillende typen en voorbeelden van LLM’s
De opzet van LLM’s maakt het extreem flexibele en aanpasbare modellen. Deze modulariteit vertaalt zich in verschillende soorten LLM’s, met name:
- Zero-shot LLM’s. Deze modellen kunnen een taak voltooien zonder ook maar één trainingsvoorbeeld te hebben gekregen. Denk bijvoorbeeld aan een LLM die nieuw straattaal kan begrijpen op basis van de positionele en semantische relaties van deze nieuwe woorden met de rest van de tekst.
- Fijngetunede LLM’s. Het is heel gebruikelijk dat ontwikkelaars een vooraf getraind LLM nemen en het met nieuwe data fijnslijpen voor specifieke doeleinden. Wil je meer weten over LLM-fine-tuning, lees dan ons artikel Fine-Tuning LLaMA 2: A Step-by-Step Guide to Customizing the Large Language Model.
- Domeinspecifieke LLM’s. Deze modellen zijn specifiek ontworpen om de jargon, kennis en bijzonderheden van een bepaald vakgebied of sector, zoals gezondheidszorg of juridisch, te vatten. Bij het ontwikkelen van deze modellen is het belangrijk om gecureerde trainingsdata te kiezen, zodat het model voldoet aan de standaarden van het betreffende domein.
Tegenwoordig groeit het aantal propriëtaire en open-source LLM’s snel. Je hebt vast al gehoord van ChatGPT, maar ChatGPT is geen LLM, het is een applicatie die boven op een LLM is gebouwd. Concreet draait ChatGPT op GPT-3.5, terwijl ChatGPT-Plus wordt aangedreven door GPT-4, momenteel het krachtigste LLM. Wil je meer weten over het gebruik van de GPT-modellen van OpenAI, lees dan ons artikel Using GPT-3.5 and GPT-4 via the OpenAI API in Python.
Hieronder vind je een lijst met enkele andere populaire LLM’s:
- BERT. Door Google in 2018 en als open source uitgebracht, is BERT een van de eerste moderne LLM’s en een van de meest succesvolle. Bekijk ons artikel What is BERT? om alles te weten te komen over dit klassieke LLM.
- PaLM 2. Een geavanceerder LLM dan zijn voorganger PaLM; PaLM 2 is het LLM achter Google Bard, de meest ambitieuze chatbot om te concurreren met ChatGPT.
- LLaMa 2. Ontwikkeld door Meta is LLaMa 2 een van de krachtigste open-source LLM’s op de markt. Wil je meer weten over dit en andere open-source LLM’s, lees dan ons speciale artikel met de 8 Top Open-Source LLMs.
Conclusie
LLM’s drijven de huidige boom in generatieve AI. De potentiële toepassingen zijn zo groot dat elke sector en industrie, inclusief data science, waarschijnlijk beïnvloed zal worden door de adoptie van LLM’s in de toekomst.
De mogelijkheden zijn eindeloos, maar dat geldt ook voor de risico’s en uitdagingen. Met hun transformerende aard hebben LLM’s speculatie aangewakkerd over de toekomst en hoe AI de arbeidsmarkt en vele andere aspecten van onze samenleving zal beïnvloeden. Dit is een belangrijk debat dat vastberaden en gezamenlijk gevoerd moet worden, omdat er veel op het spel staat.
DataCamp werkt hard aan toegankelijke en complete resources voor iedereen die op de hoogte wil blijven van AI-ontwikkelingen. Bekijk ze hier:
- Large Language Models (LLMs) Concepts Course
- How to Build LLM Applications with LangChain
- How to Train an LLM with PyTorch: A Step-By-Step Guide
- 8 Top Open-Source LLMs for 2024 and Their Uses
- Llama.cpp Tutorial: A Complete Guide to Efficient LLM Inference and Implementation
- Introduction to LangChain for Data Engineering & Data Applications
- LlamaIndex: A Data Framework for the Large Language Models (LLMs) based applications
- How to Learn AI From Scratch in 2024: A Complete Expert Guide

