Wenn du diesen Artikel liest, hast du wahrscheinlich schon von großen Sprachmodellen (LLMs) gehört. Wer kennt das nicht? Schließlich stecken LLMs hinter den beliebten Tools, die die generative KI-Revolution vorantreiben, darunter ChatGPT, Google Bard und DALL-E.
Um ihre Magie zu entfalten, verlassen sich diese Tools auf eine leistungsstarke Technologie, die es ihnen ermöglicht, Daten zu verarbeiten und genaue Inhalte als Antwort auf die vom Nutzer gestellte Frage zu generieren. Hier kommt der LLM ins Spiel.
Dieser Artikel soll dir die LLMs näher bringen. Nach der Lektüre der folgenden Abschnitte werden wir wissen, was LLMs sind, wie sie funktionieren, die verschiedenen Arten von LLMs mit Beispielen, sowie ihre Vorteile und Grenzen.
Für Neulinge auf dem Gebiet ist unser Large Language Models (LLMs) Concepts Course der perfekte Ort, um einen umfassenden Überblick über LLMs zu bekommen. Wenn du jedoch bereits mit LLM vertraut bist und einen Schritt weiter gehen möchtest, indem du lernst, wie du LLM-kompatible Anwendungen erstellen kannst, schau dir unseren Artikel Wie man LLM-Anwendungen mit LangChain erstellt an.
Lass uns loslegen!
Was ist ein großes Sprachmodell?
LLMs sind KI-Systeme, die die menschliche Sprache modellieren und verarbeiten. Sie werden als "groß" bezeichnet, weil diese Art von Modellen normalerweise aus Hunderten von Millionen oder sogar Milliarden von Parametern besteht, die das Verhalten des Modells definieren und die anhand eines riesigen Textdatenkorpus trainiert werden.
Die Technologie, die den LLMs zugrunde liegt, heißt Transformator Neuronales Netz, kurz Transformator genannt. Wie wir im nächsten Abschnitt näher erläutern werden, ist ein Transformer eine innovative neuronale Architektur im Bereich des Deep Learning.
Die von Google-Forschern 2017 in dem berühmten Paper Attention is All You Need vorgestellten Transformers sind in der Lage, Aufgaben im Bereich der natürlichen Sprache (NLP) mit einer noch nie dagewesenen Genauigkeit und Geschwindigkeit auszuführen. Mit ihren einzigartigen Fähigkeiten haben die Transformatoren einen bedeutenden Sprung in den Möglichkeiten der LLMs gemacht. Man kann mit Fug und Recht behaupten, dass die aktuelle Revolution der generativen KI ohne Transformatoren nicht möglich wäre.
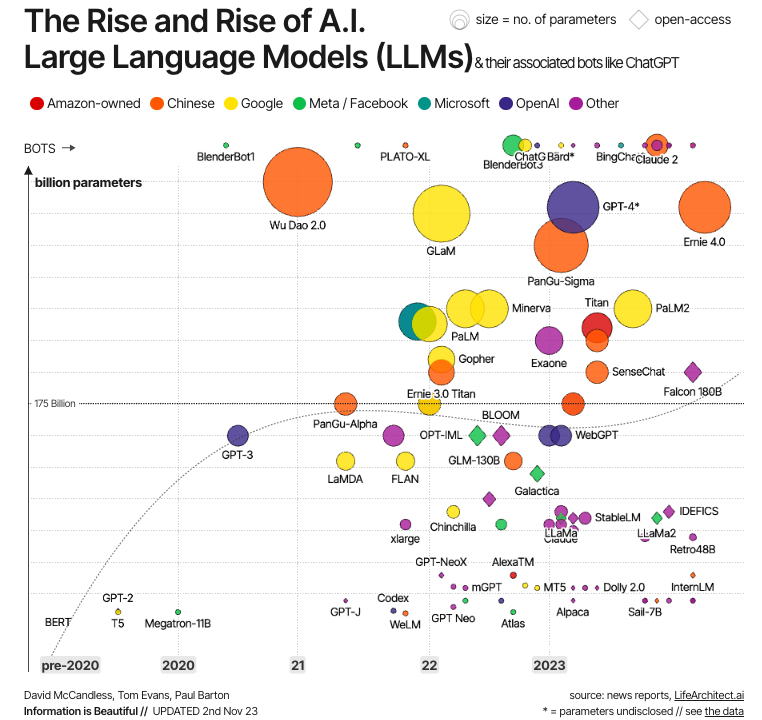
Quelle: Information ist schön
Diese Entwicklung ist in der Grafik oben dargestellt. Wie wir sehen können, wurden die ersten modernen LLMs direkt nach der Entwicklung von Transformatoren entwickelt. Die wichtigsten Beispiele sind BERT - das erste LLM, das von Google entwickelt wurde, um die Leistung von Transformatoren zu testen - sowie GPT-1 und GPT-2, die ersten beiden Modelle der GPT-Serie von OpenAI. Aber erst in den 2020er Jahren werden LLMs zum Mainstream, immer größer (in Bezug auf die Parameter) und damit leistungsfähiger, mit bekannten Beispielen wie GPT-4 und LLaMa.
Wie funktionieren LLMs?
Der Schlüssel zum Erfolg der modernen LLMs ist die Transformator-Architektur. Bevor die Google-Forscher die Transformatoren entwickelten, war die Modellierung natürlicher Sprache eine sehr schwierige Aufgabe. Trotz des Aufkommens ausgeklügelter neuronaler Netze - z. B. rekurrenter oder faltungsorientierter neuronaler Netze - waren die Ergebnisse nur teilweise erfolgreich.
Die größte Herausforderung liegt in der Strategie, die diese neuronalen Netze verwenden, um das fehlende Wort in einem Satz vorherzusagen. Vor den Transformatoren basierten moderne neuronale Netze auf der Encoder-Decoder-Architektur, einem leistungsstarken, aber zeit- und ressourcenintensiven Mechanismus, der sich nicht für parallele Berechnungen eignet und daher die Möglichkeiten der Skalierbarkeit einschränkt.
Transformatoren bieten eine Alternative zu traditionellen neuronalen Systemen, um sequentielle Daten, nämlich Text, zu verarbeiten (obwohl Transformatoren auch für andere Datentypen wie Bilder und Audio verwendet wurden, mit ebenso erfolgreichen Ergebnissen).
Bestandteile von LLMs
Transformatoren basieren auf der gleichen Encoder-Decoder-Architektur wie rekurrente und konvolutionäre neuronale Netze. Eine solche neuronale Architektur zielt darauf ab, statistische Beziehungen zwischen Token eines Textes zu entdecken.
Dies wird durch eine Kombination von Einbettungstechniken erreicht. Einbettungen sind die Repräsentationen von Token, wie Sätzen, Absätzen oder Dokumenten, in einem hochdimensionalen Vektorraum, wobei jede Dimension einem erlernten Merkmal oder einer Eigenschaft der Sprache entspricht.
Der Einbettungsprozess findet im Encoder statt. Aufgrund der enormen Größe von LLMs erfordert die Erstellung von Einbettungen umfangreiche Schulungen und beträchtliche Ressourcen. Was Transformatoren jedoch von früheren neuronalen Netzen unterscheidet, ist, dass der Einbettungsprozess hochgradig parallelisierbar ist, was eine effizientere Verarbeitung ermöglicht. Das ist dank des Aufmerksamkeitsmechanismus möglich.
Rekurrente und konvolutionale neuronale Netze machen ihre Wortvorhersagen ausschließlich auf der Grundlage vorheriger Wörter. In diesem Sinne können sie als unidirektional betrachtet werden. Im Gegensatz dazu ermöglicht der Aufmerksamkeitsmechanismus den Transformatoren, Wörter bidirektional vorherzusagen, d.h. auf der Grundlage sowohl des vorherigen als auch des folgenden Wortes. Das Ziel der Aufmerksamkeitsschicht, die sowohl im Encoder als auch im Decoder enthalten ist, besteht darin, die kontextuellen Beziehungen zwischen verschiedenen Wörtern im Eingabesatz zu erfassen.
Um im Detail zu erfahren, wie die Encoder-Decoder-Architektur in Transformatoren funktioniert, empfehlen wir dir, unsere Einführung in die Verwendung von Transformatoren und Hugging Face zu lesen .
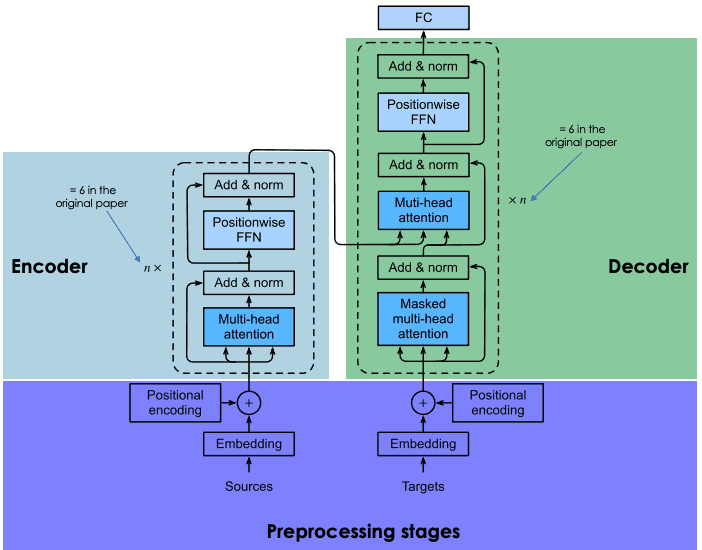
Eine Erklärung der Architektur von Transformatoren
Ausbildung LLMs
Die Ausbildung von Transformatoren umfasst zwei Schritte: das Vortraining und die Feinabstimmung.
Vor der Ausbildung
In dieser Phase werden die Transformatoren auf großen Mengen von Rohtextdaten trainiert. Das Internet ist die wichtigste Datenquelle.
Das Training wird mit unüberwachten Lerntechniken durchgeführt, einer innovativen Art des Trainings, bei der die Daten nicht von Menschenhand gekennzeichnet werden müssen.
Das Ziel des Vortrainings ist es, die statistischen Muster der Sprache zu lernen. Die modernste Strategie, um eine bessere Genauigkeit der Transformatoren zu erreichen, besteht darin, das Modell zu vergrößern (dies kann durch eine höhere Anzahl von Parametern erreicht werden) und die Größe der Trainingsdaten zu erhöhen. Daher verfügen die meisten fortschrittlichen LLMs über Milliarden von Parametern (PaLM 2 hat zum Beispiel 340 Milliarden Parameter und GPT-4 schätzungsweise 1,8 Billionen Parameter) und wurden auf einem riesigen Datenkorpus trainiert.
Dieser Trend führt zu Problemen mit der Zugänglichkeit. Angesichts der Größe des Modells und der Trainingsdaten ist der Pre-Trainingsprozess in der Regel zeit- und kostenintensiv, was sich nur eine begrenzte Gruppe von Unternehmen leisten kann.
Feinabstimmung
Die Vorschulung ermöglicht es einem Transformator, ein grundlegendes Verständnis der Sprache zu erlangen, aber sie reicht nicht aus, um bestimmte praktische Aufgaben mit hoher Genauigkeit auszuführen.
Um zeitaufwändige und kostspielige Iterationen im Trainingsprozess zu vermeiden, nutzen Transformatoren Transfer-Learning-Techniken, um die (Vor-)Trainingsphase von der Feinabstimmungsphase zu trennen. Dies ermöglicht es den Entwicklern, vorgefertigte Modelle auszuwählen und sie auf der Grundlage einer engeren, domänenspezifischen Datenbank fein abzustimmen. In vielen Fällen wird der Feinabstimmungsprozess mit Hilfe von menschlichen Prüfern durchgeführt, die eine Technik namens Reinforcement Learning from Human Feedback anwenden.
Der zweistufige Trainingsprozess ermöglicht die Anpassung des LLM an eine breite Palette von nachgelagerten Aufgaben. Anders ausgedrückt: Diese Eigenschaft macht LLMs zum Grundmodell für endlose Anwendungen, die darauf aufbauen.
Multimodalität von LLMs
Die ersten modernen LLMs waren Text-zu-Text-Modelle (d.h. sie erhielten eine Texteingabe und erzeugten eine Textausgabe). In den letzten Jahren haben die Entwickler jedoch sogenannte multimodale LLMs entwickelt. Diese Modelle kombinieren Textdaten mit anderen Arten von Informationen, darunter Bilder, Audio und Video. Die Kombination verschiedener Datentypen hat die Erstellung anspruchsvoller aufgabenspezifischer Modelle ermöglicht, wie z.B. DALL-E. von OpenAI für die Bilderzeugung und AudioCraft von Meta für die Musik- und Audioerzeugung.
Wofür werden LLMs verwendet?
Moderne LLMs, die von Transformatoren angetrieben werden, haben bei verschiedenen NLP-Aufgaben eine Spitzenleistung erzielt. Hier sind einige der Aufgaben, bei denen LLMs einzigartige Ergebnisse erzielt haben:
- Textgenerierung. LLMs wie ChatGPT sind in der Lage, lange, komplexe und menschenähnliche Texte in Sekundenschnelle zu erstellen.
- Übersetzung. Wenn LLMs in mehreren Sprachen ausgebildet sind, können sie Übersetzungsaufgaben auf hohem Niveau durchführen. Mit Multimodalität sind die Möglichkeiten endlos. Das Modell SeamlessM4T von Meta kann zum Beispiel je nach Aufgabe Sprache-zu-Text-, Sprache-zu-Sprache-, Text-zu-Sprache- und Text-zu-Text-Übersetzungen für bis zu 100 Sprachen durchführen.
- Stimmungsanalyse. Mit LLMs können alle Arten von Sentiment-Analysen durchgeführt werden, von positiven und negativen Vorhersagen für Filmkritiken bis hin zu Meinungen zu Marketingkampagnen.
- Konversationelle KI. Als zugrundeliegende Technologie moderner Chatbots eignen sich LLMs hervorragend, um Fragen zu stellen, zu beantworten und Gespräche zu führen, selbst bei komplexen Aufgaben.
- Autovervollständigen. LLMs können für Autovervollständigungsaufgaben verwendet werden, zum Beispiel in E-Mails oder Nachrichtendiensten. Das BERT von Google unterstützt zum Beispiel die Autovervollständigung in Google Mail.
Vorteile von LLMs
LLM hat ein immenses Potenzial für Unternehmen, wie die breite Akzeptanz von ChatGPT zeigt, das nur wenige Monate nach seiner Veröffentlichung zur am schnellsten wachsenden digitalen Anwendung aller Zeiten wurde.
Es gibt bereits eine ganze Reihe von Geschäftsanwendungen für LLMs, und die Zahl der Anwendungsfälle wird nur noch zunehmen, wenn diese Tools in allen Sektoren und Branchen allgegenwärtig werden. Nachfolgend findest du eine Liste mit einigen Vorteilen des LLMs:
- Erstellung von Inhalten. LLMs sind leistungsstarke generative KI-Werkzeuge. Mit ihren Fähigkeiten sind LLMs großartige Werkzeuge für die Generierung von Inhalten (hauptsächlich Text, aber in Kombination mit anderen Modellen können sie auch Bilder, Videos und Audio generieren). Abhängig von den Daten, die bei der Feinabstimmung verwendet werden, können LLMs genaue, domänenspezifische Inhalte in jedem erdenklichen Bereich liefern, von Recht und Finanzen bis hin zu Gesundheit und Marketing.
- Erhöhte Effektivität bei NLP-Aufgaben. Wie im vorherigen Abschnitt erläutert, bieten LLMs bei vielen NLP-Aufgaben eine einzigartige Leistung. Sie sind in der Lage, die menschliche Sprache zu verstehen und mit einer nie dagewesenen Genauigkeit mit Menschen zu interagieren. Es ist jedoch wichtig zu wissen, dass diese Instrumente nicht perfekt sind und immer noch ungenaue Ergebnisse oder sogar Halluzinationen hervorrufen können,
- Gesteigerte Effizienz. Einer der wichtigsten geschäftlichen Vorteile von LLMs ist, dass sie perfekt geeignet sind, um monotone, zeitraubende Aufgaben in Sekundenschnelle zu erledigen. Während sich für Unternehmen, die von diesem Effizienzsprung profitieren können, große Chancen ergeben, gibt es auch tiefgreifende Auswirkungen auf die Arbeitnehmer/innen und den Arbeitsmarkt, die berücksichtigt werden müssen.
Herausforderungen und Beschränkungen von LLMs
LLMs stehen an der Spitze der generativen KI-Revolution. Doch wie immer bei neuen Technologien kommt mit der Macht auch die Verantwortung. Trotz der einzigartigen Möglichkeiten, die das LLM bietet, ist es wichtig, seine potenziellen Risiken und Herausforderungen zu berücksichtigen.
Im Folgenden findest du eine Liste der Risiken und Herausforderungen, die mit der breiten Einführung von LLMs verbunden sind:
- Mangel an Transparenz. Algorithmische Undurchsichtigkeit ist eines der Hauptprobleme im Zusammenhang mit LLMs. Diese Modelle werden oft als "Blackbox"-Modelle bezeichnet, weil sie so komplex sind, dass es unmöglich ist, ihre Gedankengänge und inneren Abläufe zu überwachen. KI-Anbieter von proprietären LLMs geben oft nur ungern Auskunft über ihre Modelle, was die Überwachung und Rechenschaftspflicht sehr erschwert.
- LLM-Monopol. Angesichts der beträchtlichen Ressourcen, die für die Entwicklung, die Ausbildung und den Betrieb von LLMs erforderlich sind, konzentriert sich der Markt auf eine Reihe von Big-Tech-Unternehmen, die über das nötige Know-how und die nötigen Ressourcen verfügen. Glücklicherweise kommen immer mehr Open-Source-LLMs auf den Markt, die es Entwicklern, KI-Forschern und der Gesellschaft leichter machen, LLMs zu verstehen und zu betreiben.
- Vorurteile und Diskriminierung. Voreingenommene LLM-Modelle können zu ungerechten Entscheidungen führen, die oft die Diskriminierung, insbesondere von Minderheiten, noch verschärfen. Auch hier ist Transparenz wichtig, um mögliche Vorurteile besser zu verstehen und zu beseitigen.
- Datenschutzfragen. LLMs werden mit riesigen Datenmengen trainiert, die hauptsächlich wahllos aus dem Internet gezogen werden. In der Regel enthalten sie oft persönliche Daten. Dies kann zu Problemen und Risiken in Bezug auf Datenschutz und Sicherheit führen.
- Ethische Überlegungen. LLMs können manchmal zu Entscheidungen führen, die schwerwiegende Auswirkungen auf unser Leben haben, mit erheblichen Auswirkungen auf unsere Grundrechte. Wir haben die Ethik der generativen KI in einem anderen Beitrag untersucht.
- Umweltaspekte. Forscher und Umweltschützer machen sich Sorgen über den ökologischen Fußabdruck, der mit der Ausbildung und dem Betrieb von LLMs verbunden ist. Proprietäre LLMs veröffentlichen nur selten Informationen über den Energie- und Ressourcenverbrauch der LLMs und den damit verbundenen ökologischen Fußabdruck, was angesichts der schnellen Verbreitung dieser Tools äußerst problematisch ist.
Verschiedene Arten und Beispiele von LLMs
Das Design der LLMs macht sie zu extrem flexiblen und anpassungsfähigen Modellen. Diese Modularität schlägt sich insbesondere in verschiedenen Arten von LLMs nieder:
- Zero-Shot LLMs. Diese Modelle sind in der Lage, eine Aufgabe zu erledigen, ohne ein Trainingsbeispiel erhalten zu haben. Nehmen wir zum Beispiel ein LLM, das in der Lage ist, neue Slangwörter zu verstehen, indem es die Position und die semantischen Beziehungen dieser neuen Wörter zum Rest des Textes berücksichtigt.
- Feinabgestimmte LLMs. Es ist sehr üblich, dass Entwickler ein vortrainiertes LLM nehmen und es mit neuen Daten für bestimmte Zwecke feinabstimmen. Um mehr über die LLM-Feinabstimmung zu erfahren, lies unseren Artikel Feinabstimmung LLaMA 2: Eine Schritt-für-Schritt-Anleitung zur Anpassung des großen Sprachmodells.
- Bereichsspezifische LLMs. Diese Modelle wurden speziell entwickelt, um den Fachjargon, das Wissen und die Besonderheiten eines bestimmten Bereichs oder Sektors zu erfassen, z. B. im Gesundheitswesen oder im Rechtswesen. Bei der Entwicklung dieser Modelle ist es wichtig, kuratierte Trainingsdaten zu wählen, damit das Modell den Standards des jeweiligen Bereichs entspricht.
Heutzutage wächst die Zahl der proprietären und Open-Source-LLMs rasant. Du hast vielleicht schon von ChatGPT gehört, aber ChatGPT ist kein LLM, sondern eine Anwendung, die auf einem LLM aufbaut. ChatGPT wird von GPT-3.5 angetrieben, während ChatGPT-Plus von GPT-4 angetrieben wird, dem derzeit leistungsstärksten LLM. Wenn du mehr darüber erfahren möchtest, wie du die GPT-Modelle von OpenAI nutzen kannst, lies unseren Artikel GPT-3.5 und GPT-4 über die OpenAI-API in Python nutzen.
Unten findest du eine Liste mit einigen anderen beliebten LLMs:
- BERT. Google 2018 und als Open-Source veröffentlicht, ist BERT eines der ersten modernen LLM und eines der erfolgreichsten. In unserem Artikel Was ist BERT? erfährst du alles über diesen klassischen LLM.
- PaLM 2. PaLM 2 ist ein fortschrittlicherer LLM als sein Vorgänger PaLM und treibt Google Bard an, den ambitioniertesten Chatbot, der mit ChatGPT konkurriert.
- LLaMa 2. LLaMa 2 wurde von Meta entwickelt und ist einer der leistungsfähigsten Open-Source-LLMs auf dem Markt. Um mehr über diesen und andere Open-Source-LLMs zu erfahren, empfehlen wir dir, unseren Artikel mit den 8 besten Open-Source-LLMs zu lesen .
Fazit
LLMs treiben den aktuellen Boom der generativen KI an. Die Anwendungsmöglichkeiten sind so groß, dass jeder Sektor und jede Branche, einschließlich der Datenwissenschaft, in Zukunft von der Einführung von LLMs betroffen sein dürfte.
Die Möglichkeiten sind endlos, aber auch die Risiken und Herausforderungen. Mit ihren transformativen und LLMs haben sie Spekulationen über die Zukunft ausgelöst und darüber, wie KI den Arbeitsmarkt und viele andere Aspekte unserer Gesellschaft beeinflussen wird. Dies ist eine wichtige Debatte, die entschlossen und gemeinsam geführt werden muss, denn es steht so viel auf dem Spiel.
DataCamp arbeitet hart daran, umfassende und zugängliche Ressourcen für alle bereitzustellen, um mit der KI-Entwicklung Schritt zu halten. Schau sie dir an:
- Große Sprachmodelle (LLMs) Konzepte Kurs
- Wie man LLM-Anwendungen mit LangChain erstellt
- Wie man ein LLM mit PyTorch trainiert: Eine Schritt-für-Schritt-Anleitung
- Die 8 besten Open-Source-LLMs für 2024 und ihr Nutzen
- Llama.cpp Tutorial: Ein kompletter Leitfaden zur effizienten LLM-Inferenz und Implementierung
- Einführung in LangChain für Data Engineering & Datenanwendungen
- LlamaIndex: Ein Daten-Framework für die auf großen Sprachmodellen (LLMs) basierenden Anwendungen
- Wie du im Jahr 2024 KI von Grund auf lernst: Ein kompletter Expertenleitfaden

Code Along Series: Werde ein KI-Entwickler
Baue KI-Systeme und entwickle KI-Anwendungen mit OpenAI, LangChain, Pinecone und Hugging Face!

