Si vous lisez cet article, vous avez probablement déjà entendu parler des grands modèles linguistiques (LLM). Qui ne l'a pas fait ? Au final, les LLM sont à l'origine des outils super populaires qui alimentent la révolution de l'IA générative en cours, notamment ChatGPT, Google Bard et DALL-E.
Pour opérer leur magie, ces outils s'appuient sur une technologie puissante qui leur permet de traiter les données et de générer un contenu précis en réponse à la question posée par l'utilisateur. C'est là que les LLM entrent en jeu.
Cet article a pour but de vous présenter les LLM. Après avoir lu les sections suivantes, vous saurez ce que sont les LLM, comment ils fonctionnent, les différents types de LLM avec des exemples, ainsi que leurs avantages et leurs limites.
Pour les nouveaux venus dans le domaine, notre cours de concepts sur les grands modèles de langage (LLM ) est l'endroit idéal pour obtenir une vue d'ensemble approfondie des LLM. Cependant, si vous êtes déjà familiarisé avec LLM et que vous souhaitez aller plus loin en apprenant comment construire des applications LLM puissantes, consultez notre article Comment construire des applications LLM avec LangChain.
Commençons !
Qu'est-ce qu'un modèle linguistique étendu ?
Les LLM sont des systèmes d'intelligence artificielle utilisés pour modéliser et traiter le langage humain. Ils sont appelés "grands" parce que ces types de modèles sont normalement constitués de centaines de millions, voire de milliards, de paramètres qui définissent le comportement du modèle et qui sont pré-entraînés à l'aide d'un corpus massif de données textuelles.
La technologie sous-jacente des LLM est appelée réseau neuronal à transformateur, plus simplement appelé transformateur. Comme nous l'expliquerons plus en détail dans la section suivante, un transformateur est une architecture neuronale innovante dans le domaine de l'apprentissage profond.
Présentés par les chercheurs de Google dans le célèbre article Attention is All You Need en 2017, les transformateurs sont capables d'effectuer des tâches de langage naturel (NLP) avec une précision et une rapidité sans précédent. Grâce à leurs capacités uniques, les transformateurs ont permis aux LLM de faire un bond en avant. Il est juste de dire que, sans les transformateurs, la révolution actuelle de l'IA générative ne serait pas possible.
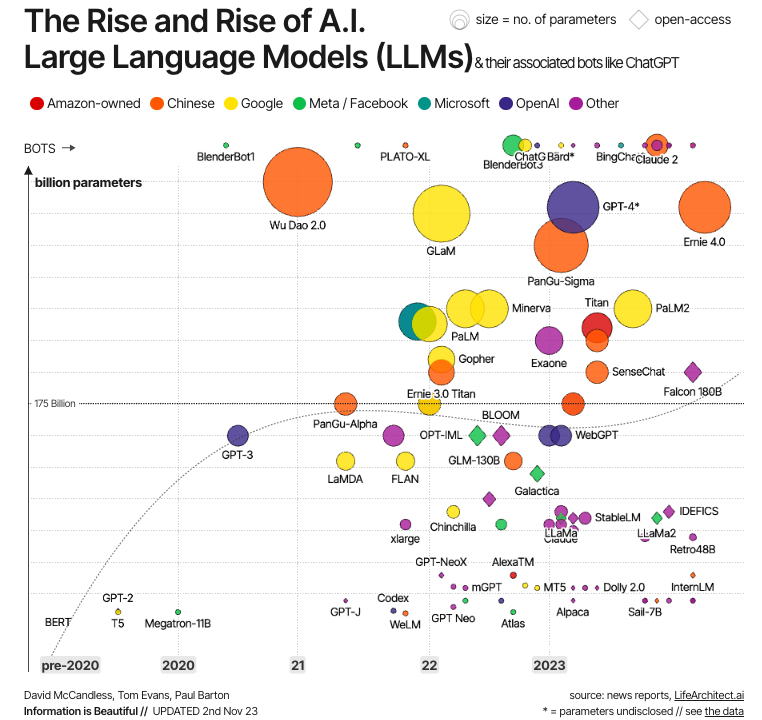
Source : L'information est belle
Cette évolution est illustrée dans le graphique ci-dessus. Comme nous pouvons le constater, les premiers LLM modernes ont été créés juste après le développement des transformateurs, les exemples les plus significatifs étant BERT - le premier LLM développé par Google pour tester la puissance des transformateurs -, ainsi que GPT-1 et GPT-2, les deux premiers modèles de la série GPT créés par OpenAI. Mais ce n'est qu'à partir des années 2020 que les LLM se généralisent, deviennent de plus en plus grands (en termes de paramètres) et donc plus puissants, avec des exemples bien connus comme GPT-4 et LLaMa.
Comment fonctionnent les LLM ?
La clé du succès des LLM modernes est l'architecture du transformateur. Avant que les transformateurs ne soient développés par les chercheurs de Google, la modélisation du langage naturel était une tâche très difficile. Malgré l'essor des réseaux neuronaux sophistiqués - c'est-à-dire les réseaux neuronaux récurrents ou convolutifs - les résultats n'ont été que partiellement satisfaisants.
La principale difficulté réside dans la stratégie utilisée par ces réseaux neuronaux pour prédire le mot manquant dans une phrase. Avant les transformateurs, les réseaux neuronaux de pointe reposaient sur l'architecture codeur-décodeur, un mécanisme puissant mais gourmand en temps et en ressources, qui n'est pas adapté au calcul parallèle, ce qui limite les possibilités d'extensibilité.
Les transformateurs offrent une alternative aux neurones traditionnels pour traiter les données séquentielles, à savoir le texte (bien que les transformateurs aient également été utilisés avec d'autres types de données, comme les images et l'audio, avec des résultats tout aussi fructueux).
Composantes des Mildes d'apprentissage tout au long de la vie
Les transformateurs sont basés sur la même architecture codeur-décodeur que les réseaux neuronaux récurrents et convolutifs. Une telle architecture neuronale vise à découvrir des relations statistiques entre les mots du texte.
Pour ce faire, on utilise une combinaison de techniques d'intégration. Les encastrements sont des représentations de jetons, tels que des phrases, des paragraphes ou des documents, dans un espace vectoriel à haute dimension, où chaque dimension correspond à une caractéristique ou à un attribut appris de la langue.
Le processus d'intégration a lieu dans le codeur. En raison de la taille considérable des LLM, la création de l'intégration nécessite une formation approfondie et des ressources considérables. Cependant, ce qui différencie les transformateurs des réseaux neuronaux précédents, c'est que le processus d'intégration est hautement parallélisable, ce qui permet un traitement plus efficace. Cela est possible grâce au mécanisme d'attention.
Les réseaux neuronaux récurrents et convolutifs effectuent leurs prédictions de mots en se basant exclusivement sur les mots précédents. En ce sens, ils peuvent être considérés comme unidirectionnels. En revanche, le mécanisme d'attention permet aux transformateurs de prédire les mots de manière bidirectionnelle, c'est-à-dire en se basant à la fois sur les mots précédents et sur les mots suivants. L'objectif de la couche d'attention, qui est incorporée à la fois dans le codeur et le décodeur, est de capturer les relations contextuelles existant entre les différents mots de la phrase d'entrée.
Pour savoir en détail comment fonctionne l'architecture codeur-décodeur dans les transformateurs, nous vous recommandons vivement de lire notre Introduction à l'utilisation des transformateurs et Hugging Face.
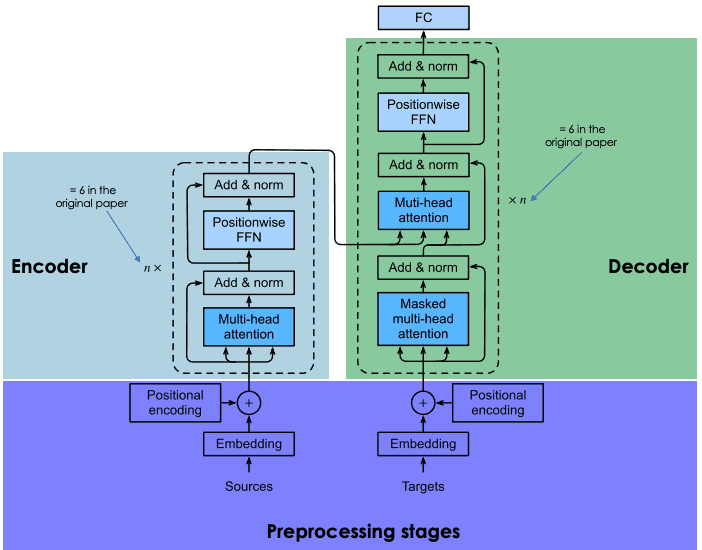
Explication de l'architecture des transformateurs
Formation des MLD
La formation des transformateurs comporte deux étapes : la préformation et le réglage fin.
Préformation
Au cours de cette phase, les transformateurs sont formés sur de grandes quantités de données textuelles brutes. L'Internet est la principale source de données.
La formation est effectuée à l'aide de techniques d'apprentissage non supervisé, un type de formation innovant qui ne nécessite pas d'action humaine pour étiqueter les données.
L'objectif du pré-entraînement est d'apprendre les modèles statistiques de la langue. La stratégie la plus moderne pour obtenir une meilleure précision des transformateurs consiste à agrandir le modèle (en augmentant le nombre de paramètres) et à augmenter la taille des données d'apprentissage. Par conséquent, les LLM les plus avancés comportent des milliards de paramètres (par exemple, PaLM 2 a 340 milliards de paramètres, et GPT-4 est estimé à environ 1,8 trillion de paramètres) et ont été entraînés sur un corpus de données gigantesque.
Cette tendance crée des problèmes d'accessibilité. Compte tenu de la taille du modèle et des données d'apprentissage, le processus de pré-entraînement est normalement long et coûteux, ce que seul un petit groupe d'entreprises peut se permettre.
Mise au point
La préformation permet à un transformateur d'acquérir une compréhension de base de la langue, mais elle n'est pas suffisante pour effectuer des tâches pratiques spécifiques avec une grande précision.
Pour éviter les itérations coûteuses en temps et en argent dans le processus de formation, les transformateurs utilisent des techniques d'apprentissage par transfert pour séparer la phase de (pré)formation de la phase de mise au point. Cela permet aux développeurs de choisir des modèles pré-entraînés et de les affiner sur la base d'une base de données plus étroite et spécifique à un domaine. Dans de nombreux cas, le processus d'affinage est mené avec l'aide de réviseurs humains, en utilisant une technique appelée Apprentissage par renforcement à partir du retour d'information humain.
Le processus de formation en deux étapes permet d'adapter le LLM à un large éventail de tâches en aval. En d'autres termes, cette caractéristique fait des LLM le modèle de base d' une infinité d'applications construites au-dessus d'eux.
Multimodalité des LLM
Les premiers LLM modernes étaient des modèles texte-texte (c'est-à-dire qu'ils recevaient un texte en entrée et généraient un texte en sortie). Cependant, ces dernières années, les développeurs ont créé des LLM multimodaux. Ces modèles combinent des données textuelles avec d'autres types d'informations, notamment des images, des sons et des vidéos. La combinaison de différents types de données a permis la création de modèles sophistiqués spécifiques à une tâche, tels que DALL-E. d'OpenAI pour la génération d'images, et AudioCraft de Meta pour la génération de musique et d'audio.
À quoi servent les masters en droit ?
Alimentés par des transformateurs, les LLM modernes ont atteint des performances de pointe dans de nombreuses tâches NLP. Voici quelques-unes des tâches pour lesquelles les LLM ont fourni des résultats uniques :
- Génération de texte. Les LLM comme ChatGPT sont capables de créer des textes longs, complexes et d'apparence humaine en quelques secondes.
- Translation. Lorsque les LLM sont formés dans plusieurs langues, ils peuvent effectuer des opérations de traduction de haut niveau. Avec la multimodalité, les possibilités sont infinies. Par exemple, le modèle SeamlessM4T de Meta peut effectuer des traductions de la parole vers le texte, de la parole vers la parole, de la parole vers le texte et du texte vers le texte dans une centaine de langues en fonction de la tâche.
- Analyse des sentiments. Les LLM permettent d'effectuer toutes sortes d'analyses de sentiments, qu'il s'agisse de prédictions de critiques de films positives ou négatives ou d'opinions sur des campagnes de marketing.
- L'IA conversationnelle. En tant que technologie sous-jacente des chatbots modernes, les LLM permettent de poser des questions, de répondre et de tenir des conversations, même dans le cadre de tâches complexes.
- Autocomplétion. Les LLM peuvent être utilisés pour des tâches d'autocomplétion, par exemple dans les courriels ou les services de messagerie. Par exemple, le BERT de Google alimente l'outil d'autocomplétion de Gmail.
Avantages des masters en droit
Le LLM présente un immense potentiel pour les organisations, comme l'illustre l'adoption généralisée du ChatGPT, qui, quelques mois seulement après sa sortie, est devenu l'application numérique à la croissance la plus rapide de tous les temps.
Il existe déjà un grand nombre d'applications commerciales des LLM, et le nombre de cas d'utilisation ne fera qu'augmenter à mesure que ces outils deviendront plus omniprésents dans les secteurs et les industries. Vous trouverez ci-dessous une liste de quelques-uns des avantages des masters en droit :
- Création de contenu. Les LLM sont de puissants outils d'IA générative. Grâce à leurs capacités, les LLM sont d'excellents outils pour générer du contenu (principalement du texte, mais, en combinaison avec d'autres modèles, ils peuvent également générer des images, des vidéos et du son). En fonction des données utilisées dans le processus d'affinage, les LLM peuvent fournir un contenu précis et spécifique à un domaine dans tous les secteurs auxquels vous pouvez penser, du droit à la finance en passant par la santé et le marketing.
- Efficacité accrue dans les tâches de la PNL. Comme expliqué dans la section précédente, les LLMs fournissent des performances uniques dans de nombreuses tâches NLP. Ils sont capables de comprendre le langage humain et d'interagir avec les humains avec une précision sans précédent. Toutefois, il est important de noter que ces outils ne sont pas parfaits et qu'ils peuvent encore produire des résultats inexacts, voire des hallucinations dans l'ensemble,
- Efficacité accrue. L'un des principaux avantages commerciaux des LLM est qu'ils sont parfaits pour accomplir des tâches monotones et fastidieuses en l'espace de quelques secondes. Si les perspectives sont grandes pour les entreprises qui peuvent bénéficier de ce bond en avant dans l'efficacité, les implications pour les travailleurs et le marché de l'emploi sont profondes et méritent d'être prises en compte.
Défis et limites des LLM
Les LLM sont à l'avant-garde de la révolution de l'IA générative. Toutefois, comme c'est toujours le cas avec les technologies émergentes, le pouvoir s'accompagne de responsabilités. Malgré les capacités uniques du LLM, il est important de prendre en compte les risques et les défis potentiels qu'il présente.
Vous trouverez ci-dessous une liste des risques et des défis liés à l'adoption généralisée des LLM :
- Manque de transparence. L'opacité algorithmique est l'une des principales préoccupations associées aux LLM. Ces modes sont souvent qualifiés de modèles "boîte noire" en raison de leur complexité, qui rend impossible le contrôle de leur raisonnement et de leur fonctionnement interne. Les fournisseurs d'IA de LLM propriétaires sont souvent réticents à fournir des informations sur leurs modèles, ce qui rend le suivi et la responsabilité très difficiles.
- Monopole du LLM. Compte tenu des ressources considérables nécessaires pour développer, former et exploiter les LLM, le marché est fortement concentré dans un groupe de grandes entreprises technologiques disposant du savoir-faire et des ressources nécessaires. Heureusement, un nombre croissant de LLM à code source ouvert arrivent sur le marché, ce qui permet aux développeurs, aux chercheurs en IA et à la société de comprendre et d'exploiter plus facilement les LLM.
- Les préjugés et la discrimination. Les modèles de gestion du cycle de vie biaisés peuvent donner lieu à des décisions injustes qui exacerbent souvent la discrimination, en particulier à l'encontre des groupes minoritaires. Là encore, la transparence est essentielle pour mieux comprendre et traiter les biais potentiels.
- Questions relatives à la protection de la vie privée. Les LLM sont formés à l'aide de grandes quantités de données, principalement extraites sans discernement de l'internet. Il contient souvent des données à caractère personnel. Cela peut entraîner des problèmes et des risques liés à la confidentialité et à la sécurité des données.
- Considérations éthiques. Les LLM peuvent parfois conduire à des décisions qui ont des implications graves dans nos vies, avec des impacts significatifs sur nos droits fondamentaux. Nous avons exploré l'éthique de l'IA générative dans un autre article.
- Considérations environnementales. Les chercheurs et les défenseurs de l'environnement s'inquiètent de l' empreinte écologique associée à la formation et à l'exploitation des MFR. Les LLM propriétaires publient rarement des informations sur l'énergie et les ressources consommées par les LLM, ni sur l'empreinte environnementale associée, ce qui est extrêmement problématique compte tenu de l'adoption rapide de ces outils.
Différents types et exemples de LLM
La conception des LLM en fait des modèles extrêmement flexibles et adaptables. Cette modularité se traduit par différents types de mécanismes d'apprentissage tout au long de la vie, en particulier :
- Les LLM à zéro coup. Ces modèles sont capables d'accomplir une tâche sans avoir reçu d'exemple de formation. Prenons l'exemple d'un LLM capable de comprendre un nouvel argot sur la base des relations positionnelles et sémantiques de ces nouveaux mots avec le reste du texte.
- Des LLM affinés. Il est très courant pour les développeurs de prendre un LLM pré-entraîné et de l'affiner avec de nouvelles données à des fins spécifiques. Pour en savoir plus sur le réglage fin du LLM, lisez notre article Fine-Tuning LLaMA 2 : Un guide étape par étape pour personnaliser le modèle de langue large.
- LLM spécifiques à un domaine. Ces modèles sont spécifiquement conçus pour capturer le jargon, les connaissances et les particularités d'un domaine ou d'un secteur particulier, comme les soins de santé ou le droit. Lors de l'élaboration de ces modèles, il est important de choisir des données d'entraînement validées, afin que le modèle réponde aux normes du domaine concerné.
Aujourd'hui, le nombre de LLM propriétaires et à code source ouvert augmente rapidement. Vous avez peut-être déjà entendu parler de ChatGPT, mais ChatGPT n'est pas un LLM, mais une application construite au-dessus d'un LLM. En particulier, ChatGPT est alimenté par GPT-3.5, tandis que ChatGPT-Plus est alimenté par GPT-4, actuellement le LLM le plus puissant. Pour en savoir plus sur l'utilisation des modèles GPT d'OpenAI, lisez notre article Utiliser GPT-3.5 et GPT-4 via l'API OpenAI en Python.
Vous trouverez ci-dessous une liste de quelques autres LLM populaires :
- BERT. Google en 2018 et publié en open-source, BERT est l'un des premiers LLM modernes et l'un des plus aboutis. Consultez notre article Qu'est-ce que le BERT ? pour tout savoir sur ce LLM classique.
- PaLM 2. LLM plus avancé que son prédécesseur PaLM, PaLM 2 est le LLM qui équipe Google Bard, le chatbot le plus ambitieux pour concurrencer ChatGPT.
- LLaMa 2. Développé par Meta, LLaMa 2 est l'un des LLM open-source les plus puissants du marché. Pour en savoir plus sur ce LLM et d'autres LLM open-source, nous vous recommandons de lire notre article consacré aux 8 meilleurs LLM open-source.
Conclusion
Les LLM sont à l'origine de l'essor actuel de l'IA générative. Les applications potentielles sont si vastes que tous les secteurs et industries, y compris la science des données, sont susceptibles d'être affectés par l'adoption des LLM à l'avenir.
Les possibilités sont infinies, mais les risques et les défis aussi. Avec son caractère transformateur et, les LLM ont suscité des spéculations sur l'avenir et sur la façon dont l'IA affectera le marché du travail et bien d'autres aspects de nos sociétés. Il s'agit d'un débat important qui doit être abordé fermement et collectivement, car les enjeux sont considérables.
DataCamp s'efforce de fournir des ressources complètes et accessibles à tous pour se tenir au courant du développement de l'IA. Consultez-les :
- Grands modèles de langage (LLM) Concepts Course
- Comment créer des applications LLM avec LangChain
- Comment former un LLM avec PyTorch : Un guide pas à pas
- 8 LLM Open-Source pour 2024 et leurs utilisations
- Tutoriel Llama.cpp : Un guide complet pour l'inférence et l'implémentation efficaces de LLM
- Introduction à LangChain pour l'ingénierie des données et les applications de données
- LlamaIndex : Un cadre de données pour les applications basées sur les grands modèles linguistiques (LLM)
- Comment apprendre l'IA à partir de zéro en 2024 : Un guide complet d'expert

Série Code Along : Devenez développeur en IA
Construisez des systèmes d'IA et développez des applications d'IA en utilisant OpenAI, LangChain, Pinecone et Hugging Face !

