Jika Anda membaca artikel ini, kemungkinan besar Anda sudah pernah mendengar tentang large language model (LLM). Siapa yang belum? Pada akhirnya, LLM berada di balik alat-alat super populer yang mendorong revolusi AI generatif saat ini, termasuk ChatGPT, Google Bard, dan DALL-E.
Untuk menghadirkan keajaibannya, alat-alat ini mengandalkan teknologi kuat yang memungkinkan mereka memproses data dan menghasilkan konten yang akurat sebagai respons atas pertanyaan yang diajukan pengguna. Di sinilah LLM berperan.
Artikel ini bertujuan memperkenalkan Anda pada LLM. Setelah membaca bagian-bagian berikut, kita akan mengetahui apa itu LLM, cara kerjanya, berbagai jenis LLM beserta contohnya, serta kelebihan dan keterbatasannya.
Bagi pemula, Kursus Konsep Large Language Models (LLMs) kami adalah tempat yang tepat untuk mendapatkan gambaran mendalam tentang LLM. Namun, jika Anda sudah familier dengan LLM dan ingin melangkah lebih jauh dengan mempelajari cara membangun aplikasi berbasis LLM, simak artikel kami Cara Membangun Aplikasi LLM dengan LangChain.
Mari kita mulai!
Apa itu Large Language Model?
LLM adalah sistem AI yang digunakan untuk memodelkan dan memproses bahasa manusia. Disebut "large" karena jenis model ini biasanya terdiri atas ratusan juta bahkan miliaran parameter yang menentukan perilaku model, yang di-pralatih menggunakan korpus data teks dalam jumlah masif.
Teknologi dasar LLM disebut jaringan saraf transformer, yang disingkat menjadi transformer. Seperti akan kami jelaskan lebih rinci pada bagian berikutnya, transformer adalah arsitektur saraf yang inovatif dalam bidang deep learning.
Dipresentasikan oleh peneliti Google dalam makalah terkenal Attention is All You Need pada 2017, transformer mampu menjalankan tugas pemrosesan bahasa alami (NLP) dengan akurasi dan kecepatan yang belum pernah ada sebelumnya. Dengan kemampuannya yang unik, transformer memberikan lompatan besar pada kapabilitas LLM. Dapat dikatakan, tanpa transformer, revolusi AI generatif saat ini tidak akan mungkin terjadi.
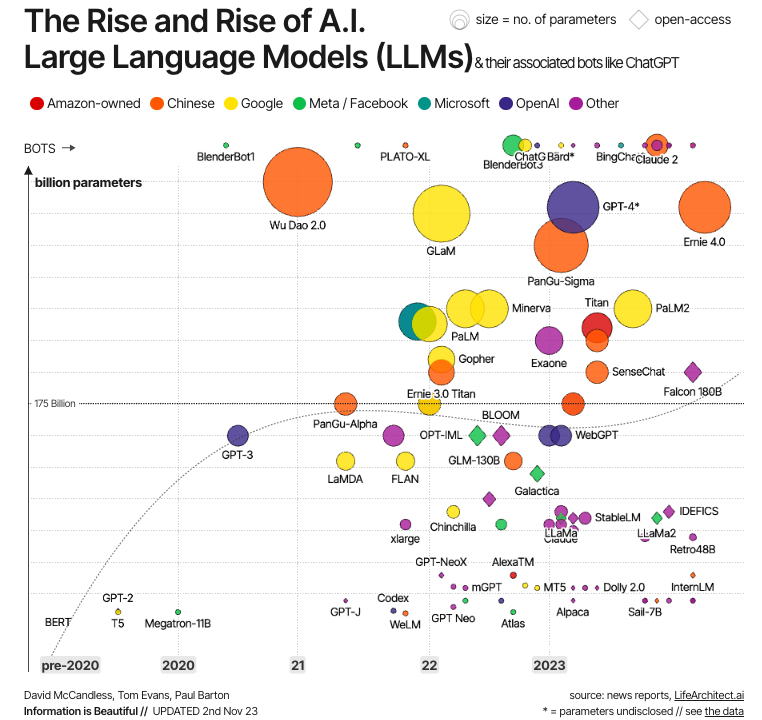
Sumber: Information is Beautiful
Evolusi ini digambarkan pada grafik di atas. Seperti dapat kita lihat, LLM modern pertama dibuat tepat setelah pengembangan transformer, dengan contoh paling signifikan seperti BERT –LLM pertama yang dikembangkan Google untuk menguji kekuatan transformer–, serta GPT-1 dan GPT-2, dua model pertama dalam seri GPT yang dibuat oleh OpenAI. Namun, baru pada 2020-an LLM menjadi arus utama, semakin besar (dalam hal jumlah parameter), dan karenanya semakin kuat, dengan contoh terkenal seperti GPT-4 dan LLaMa.
Bagaimana Cara Kerja LLM?
Kunci keberhasilan LLM modern adalah arsitektur transformer. Sebelum transformer dikembangkan oleh peneliti Google, memodelkan bahasa alami merupakan tugas yang sangat menantang. Terlepas dari kemunculan jaringan saraf canggih –mis., jaringan saraf resurens atau konvolusional– hasilnya hanya sebagian berhasil.
Tantangan utama terletak pada strategi yang digunakan jaringan saraf ini untuk memprediksi kata yang hilang dalam sebuah kalimat. Sebelum transformer, jaringan saraf mutakhir mengandalkan arsitektur encoder-decoder, suatu mekanisme yang kuat namun memakan waktu dan sumber daya, tidak cocok untuk komputasi paralel, sehingga membatasi kemungkinan skalabilitas.
Transformer memberikan alternatif terhadap pendekatan neural tradisional untuk menangani data berurutan, yakni teks (meskipun transformer juga telah digunakan pada jenis data lain, seperti gambar dan audio, dengan hasil yang sama suksesnya).
Komponen LLM
Transformer didasarkan pada arsitektur encoder-decoder yang sama seperti jaringan saraf resurens dan konvolusional. Arsitektur saraf seperti ini bertujuan menemukan hubungan statistik antar token teks.
Hal ini dilakukan melalui kombinasi teknik embedding. Embedding adalah representasi token, seperti kalimat, paragraf, atau dokumen, dalam ruang vektor berdimensi tinggi, di mana setiap dimensi merepresentasikan fitur atau atribut bahasa yang dipelajari.
Proses embedding berlangsung di encoder. Karena ukuran LLM yang sangat besar, pembuatan embedding memerlukan pelatihan ekstensif dan sumber daya yang besar. Namun, yang membedakan transformer dibanding jaringan saraf sebelumnya adalah proses embedding yang sangat dapat diparalelkan, sehingga pemrosesan menjadi lebih efisien. Hal ini dimungkinkan berkat mekanisme attention.
Jaringan saraf resurens dan konvolusional membuat prediksi kata semata-mata berdasarkan kata-kata sebelumnya. Dalam pengertian ini, mereka dapat dianggap searah. Sebaliknya, mekanisme attention memungkinkan transformer memprediksi kata secara dua arah, yakni berdasarkan kata sebelumnya dan sesudahnya. Tujuan lapisan attention, yang disematkan pada encoder dan decoder, adalah menangkap hubungan kontekstual yang ada antar berbagai kata dalam kalimat masukan.
Untuk memahami secara rinci bagaimana arsitektur encoder-decoder bekerja pada transformer, kami sangat merekomendasikan Anda membaca Pengantar Menggunakan Transformers dan Hugging Face.
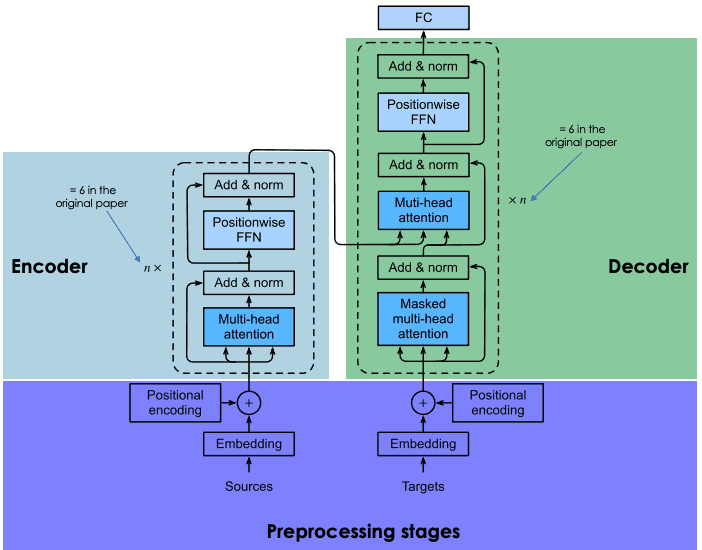
Penjelasan arsitektur transformer
Melatih LLM
Pelatihan transformer mencakup dua langkah: pralatih (pretraining) dan penyetelan lanjutan (fine-tuning).
Pralatih
Pada tahap ini, transformer dilatih pada sejumlah besar data teks mentah. Internet adalah sumber data utama.
Pelatihan dilakukan menggunakan teknik pembelajaran tanpa supervisi, jenis pelatihan inovatif yang tidak memerlukan tindakan manusia untuk memberi label data.
Tujuan pralatih adalah mempelajari pola statistik bahasa. Strategi mutakhir untuk mencapai akurasi transformer yang lebih baik adalah dengan memperbesar model (ini dapat dicapai dengan menambah jumlah parameter) dan menambah ukuran data pelatihan. Akibatnya, LLM paling canggih memiliki miliaran parameter (misalnya, PaLM 2 memiliki 340 miliar parameter, dan GPT-4 diperkirakan memiliki sekitar 1,8 triliun parameter) dan dilatih pada korpus data yang sangat besar.
Tren ini menimbulkan masalah aksesibilitas. Mengingat ukuran model dan data pelatihan, proses pralatih biasanya memakan waktu dan mahal, yang hanya dapat ditanggung oleh sekelompok kecil perusahaan.
Penyetelan lanjutan
Pralatih memungkinkan transformer memperoleh pemahaman dasar tentang bahasa, tetapi itu tidak cukup untuk menjalankan tugas praktis tertentu dengan akurasi tinggi.
Untuk menghindari iterasi pelatihan yang memakan waktu dan mahal, transformer memanfaatkan teknik transfer learning untuk memisahkan tahap (pra)latih dari tahap penyetelan lanjutan. Ini memungkinkan pengembang memilih model pralathih dan menyetelnya lebih lanjut berdasarkan basis data yang lebih sempit dan spesifik domain. Dalam banyak kasus, proses fine-tuning dilakukan dengan bantuan peninjau manusia, menggunakan teknik yang disebut Reinforcement Learning from Human Feedback.
Proses pelatihan dua langkah ini memungkinkan adaptasi LLM ke berbagai tugas hilir. Dengan kata lain, fitur ini menjadikan LLM sebagai foundation model bagi berbagai aplikasi yang dibangun di atasnya.
Multimodalitas LLM
LLM modern pertama adalah model teks-ke-teks (artinya, menerima masukan teks dan menghasilkan keluaran teks). Namun, dalam beberapa tahun terakhir, pengembang telah menciptakan LLM multimodal. Model-model ini menggabungkan data teks dengan jenis informasi lain, termasuk gambar, audio, dan video. Kombinasi berbagai jenis data memungkinkan terciptanya model khusus tugas yang canggih, seperti DALL-E dari OpenAI untuk pembuatan gambar, dan AudioCraft dari Meta untuk pembuatan musik dan audio.
Untuk Apa LLM Digunakan?
Didukung oleh transformer, LLM modern telah mencapai performa mutakhir dalam berbagai tugas NLP. Berikut beberapa tugas di mana LLM memberikan hasil yang istimewa:
- Generasi teks. LLM seperti ChatGPT mampu membuat teks yang panjang, kompleks, dan menyerupai tulisan manusia dalam hitungan detik.
- Terjemahan. Ketika LLM dilatih dalam banyak bahasa, mereka dapat melakukan operasi penerjemahan tingkat tinggi. Dengan multimodalitas, kemungkinannya tak terbatas. Misalnya, model SeamlessM4T milik Meta dapat melakukan terjemahan ucapan-ke-teks, ucapan-ke-ucapan, teks-ke-ucapan, dan teks-ke-teks hingga 100 bahasa tergantung tugasnya.
- Analisis sentimen. Segala jenis analisis sentimen dapat dilakukan dengan LLM, dari prediksi ulasan film positif dan negatif hingga opini kampanye pemasaran.
- AI percakapan. Sebagai teknologi dasar chatbot modern, LLM unggul dalam tanya jawab dan menjaga percakapan bahkan untuk tugas yang kompleks.
- Pelengkapan otomatis. LLM dapat digunakan untuk tugas pelengkapan otomatis, misalnya di email atau layanan pesan. Sebagai contoh, BERT dari Google mendukung alat pelengkapan otomatis di Gmail.
Kelebihan LLM
LLM memiliki potensi besar bagi organisasi, sebagaimana ditunjukkan oleh adopsi luas ChatGPT yang, hanya beberapa bulan setelah dirilis, menjadi aplikasi digital dengan pertumbuhan tercepat sepanjang masa.
Sudah ada banyak aplikasi bisnis dari LLM, dan jumlah kasus penggunaan hanya akan meningkat seiring alat ini makin meluas di berbagai sektor dan industri. Di bawah ini, Anda dapat menemukan daftar beberapa manfaat LLM:
- Pembuatan konten. LLM adalah tulang punggung berbagai alat AI generatif yang kuat. Dengan kapabilitasnya, LLM sangat cocok untuk menghasilkan konten (terutama teks, tetapi jika dikombinasikan dengan model lain, juga dapat menghasilkan gambar, video, dan audio). Bergantung pada data yang digunakan dalam proses fine-tuning, LLM dapat memberikan konten yang akurat dan spesifik domain di sektor apa pun, dari hukum dan keuangan hingga kesehatan dan pemasaran.
- Peningkatan efektivitas dalam tugas NLP. Seperti dijelaskan pada bagian sebelumnya, LLM memberikan performa unik dalam banyak tugas NLP. Mereka mampu memahami bahasa manusia dan berinteraksi dengan manusia dengan akurasi yang belum pernah ada sebelumnya. Namun, penting untuk dicatat bahwa alat ini tidak sempurna dan masih dapat menghasilkan hasil yang tidak akurat atau bahkan halusinasi secara umum,
- Peningkatan efisiensi. Salah satu manfaat bisnis utama LLM adalah kesesuaiannya untuk menyelesaikan tugas monoton yang memakan waktu dalam hitungan detik. Meskipun ada prospek besar bagi perusahaan yang dapat memetik lonjakan efisiensi ini, ada implikasi mendalam bagi pekerja dan pasar kerja yang perlu dipertimbangkan.
Tantangan dan Keterbatasan LLM
LLM berada di garis depan revolusi AI generatif. Namun, seperti halnya teknologi yang tengah berkembang, kekuatan datang bersama tanggung jawab. Terlepas dari kapabilitas unik LLM, penting untuk mempertimbangkan potensi risiko dan tantangannya.
Di bawah ini, Anda dapat menemukan daftar risiko dan tantangan yang terkait dengan adopsi luas LLM:
- Kurangnya transparansi. Keopakan algoritmik adalah salah satu kekhawatiran utama terkait LLM. Model-model ini sering dilabeli sebagai model 'kotak hitam' karena kompleksitasnya, yang membuat penalaran dan proses internalnya tidak dapat dipantau. Penyedia AI untuk LLM proprietari sering enggan memberikan informasi tentang model mereka, yang membuat pemantauan dan akuntabilitas sangat sulit.
- Monopoli LLM. Mengingat sumber daya besar yang diperlukan untuk mengembangkan, melatih, dan mengoperasikan LLM, pasar sangat terkonsentrasi pada segelintir perusahaan Big Tech yang memiliki pengetahuan dan sumber daya yang diperlukan. Untungnya, semakin banyak LLM open-source yang hadir di pasar, sehingga memudahkan pengembang, peneliti AI, dan masyarakat untuk memahami dan mengoperasikan LLM.
- Bias dan diskriminasi. Model LLM yang bias dapat menghasilkan keputusan yang tidak adil dan sering kali memperburuk diskriminasi, khususnya terhadap kelompok minoritas. Sekali lagi, transparansi sangat penting di sini untuk lebih memahami dan mengatasi potensi bias.
- Masalah privasi. LLM dilatih dengan jumlah data yang sangat besar yang sebagian besar diekstraksi secara indiscriminatif dari Internet. Sering kali, data tersebut memuat data pribadi. Hal ini dapat menimbulkan isu dan risiko terkait privasi serta keamanan data.
- Pertimbangan etika. LLM terkadang dapat mengarah pada keputusan yang memiliki implikasi serius dalam kehidupan kita, dengan dampak signifikan pada hak-hak fundamental. Kami membahas etika AI generatif dalam tulisan terpisah.
- Pertimbangan lingkungan. Peneliti dan pengawas lingkungan menyuarakan kekhawatiran tentang jejak lingkungan yang terkait dengan pelatihan dan pengoperasian LLM. LLM proprietari jarang memublikasikan informasi tentang energi dan sumber daya yang dikonsumsi LLM, maupun jejak lingkungan yang terkait, yang sangat bermasalah mengingat adopsi alat-alat ini yang cepat.
Beragam Jenis dan Contoh LLM
Desain LLM membuatnya menjadi model yang sangat fleksibel dan adaptif. Modularitas ini menghasilkan berbagai jenis LLM, khususnya:
- LLM zero-shot. Model-model ini mampu menyelesaikan tugas tanpa menerima contoh pelatihan apa pun. Misalnya, bayangkan LLM yang mampu memahami kosakata gaul baru berdasarkan hubungan posisional dan semantis kata-kata baru tersebut dengan teks lainnya.
- LLM yang di-fine-tune. Sangat umum bagi pengembang untuk mengambil LLM pralathih dan menyetelnya lebih lanjut dengan data baru untuk tujuan spesifik. Untuk mempelajari lebih lanjut tentang fine-tuning LLM, baca artikel kami Fine-Tuning LLaMA 2: Panduan Langkah demi Langkah untuk Menyesuaikan Large Language Model.
- LLM spesifik domain. Model-model ini dirancang khusus untuk menangkap jargon, pengetahuan, dan kekhasan suatu bidang atau sektor tertentu, seperti kesehatan atau hukum. Saat mengembangkan model ini, penting untuk memilih data pelatihan terkurasi, agar model memenuhi standar bidang terkait.
Saat ini, jumlah LLM proprietari dan open-source tumbuh pesat. Anda mungkin sudah pernah mendengar tentang ChatGPT, tetapi ChatGPT bukan LLM, melainkan aplikasi yang dibangun di atas LLM. Secara khusus, ChatGPT didukung oleh GPT-3.5, sedangkan ChatGPT-Plus didukung oleh GPT-4, saat ini LLM paling kuat. Untuk mengetahui lebih lanjut cara menggunakan model GPT dari OpenAI, baca artikel kami Menggunakan GPT-3.5 dan GPT-4 melalui OpenAI API di Python.
Di bawah ini, Anda dapat menemukan daftar beberapa LLM populer lainnya:
- BERT. Dikembangkan Google pada 2018 dan dirilis sebagai open-source, BERT adalah salah satu LLM modern pertama dan salah satu yang paling sukses. Simak artikel kami Apa itu BERT? untuk mengetahui segala hal tentang LLM klasik ini.
- PaLM 2. LLM yang lebih maju daripada pendahulunya PaLM, PaLM 2 adalah LLM yang mendukung Google Bard, chatbot paling ambisius untuk bersaing dengan ChatGPT.
- LLaMa 2. Dikembangkan oleh Meta, LLaMa 2 adalah salah satu LLM open-source terkuat di pasar. Untuk mengetahui lebih lanjut tentang ini dan LLM open-source lainnya, kami rekomendasikan membaca artikel khusus kami 8 LLM Open-Source Teratas.
Kesimpulan
LLM menggerakkan ledakan AI generatif saat ini. Potensi aplikasinya begitu luas sehingga setiap sektor dan industri, termasuk data science, kemungkinan akan terdampak oleh adopsi LLM di masa depan.
Kemungkinannya tidak terbatas, tetapi begitu pula risiko dan tantangannya. Dengan sifatnya yang transformatif, LLM memicu spekulasi tentang masa depan dan bagaimana AI akan memengaruhi pasar kerja dan banyak aspek lain dalam masyarakat kita. Ini adalah perdebatan penting yang perlu dibahas secara tegas dan kolektif karena taruhannya sangat besar.
DataCamp bekerja keras menyediakan sumber daya yang komprehensif dan mudah diakses bagi semua orang untuk tetap mengikuti perkembangan AI. Simak tautan berikut:
- Kursus Konsep Large Language Models (LLMs)
- Cara Membangun Aplikasi LLM dengan LangChain
- Cara Melatih LLM dengan PyTorch: Panduan Langkah demi Langkah
- 8 LLM Open-Source Teratas untuk 2024 dan Kegunaannya
- Tutorial Llama.cpp: Panduan Lengkap Inferensi dan Implementasi LLM yang Efisien
- Pengantar LangChain untuk Rekayasa Data & Aplikasi Data
- LlamaIndex: Kerangka Data untuk Aplikasi berbasis Large Language Models (LLMs)
- Cara Belajar AI dari Nol pada 2024: Panduan Lengkap dari Ahli

