If you’re reading this article, you probably have already heard about large language models (LLMs). Who hasn’t? In the end, LLMs are behind the super popular tools fueling the ongoing generative AI revolution, including ChatGPT, Google Bard, and DALL-E.
To deliver their magic, these tools rely on a powerful technology that allows them to process data and generate accurate content in response to the question prompted by the user. This is where LLMs kick in.
This article aims to introduce you to LLMs. After reading the following sections, we will know what LLMs are, how they work, the different types of LLMs with examples, as well as their advantages and limitations.
For newcomers to the subject, our Large Language Models (LLMs) Concepts Course is a perfect place to get a deep overview of LLMs. However, if you’re already familiar with LLM and want to go a step further by learning how to build LLM-power applications, check out our article How to Build LLM Applications with LangChain.
Let’s get started!
What is a Large Language Model?
LLMs are AI systems used to model and process human language. They are called “large” because these types of models are normally made of hundreds of millions or even billions of parameters that define the model's behavior, which are pre-trained using a massive corpus of text data.
The underlying technology of LLMs is called transformer neural network, simply referred to as a transformer. As we will explain in more detail in the next section, a transformer is an innovative neural architecture within the field of deep learning.
Presented by Google researchers in the famous paper Attention is All You Need in 2017, transformers are capable of performing natural language (NLP) tasks with unprecedented accuracy and speed. With its unique capabilities, transformers have provided a significant leap in the capabilities of LLMs. It’s fair to say that, without transformers, the current generative AI revolution wouldn’t be possible.
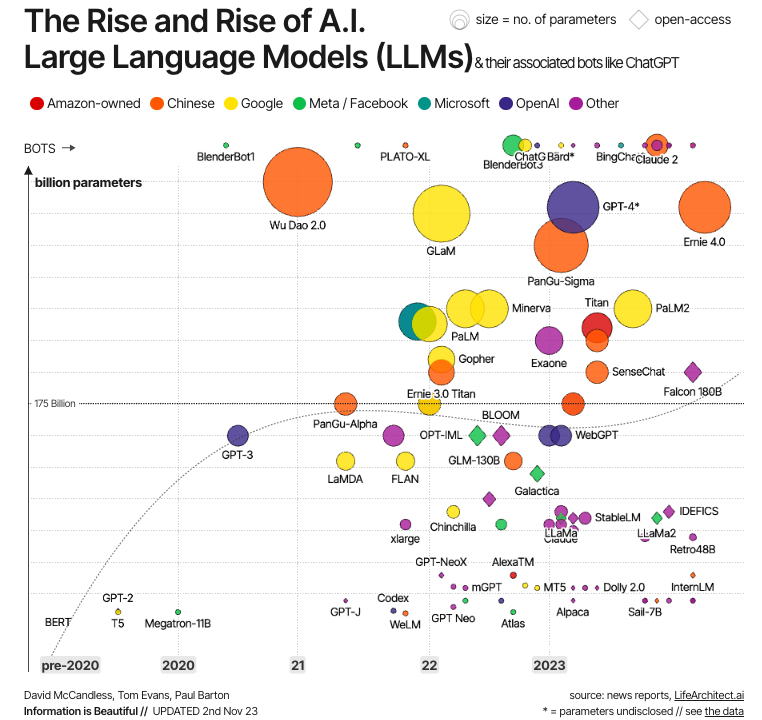
Source: Information is Beautiful
This evolution is illustrated in the graph above. As we can see, the first modern LLMs were created right after the development of transformers, with the most significant examples being BERT –the first LLM developed by Google to test the power of transformers–, as well as GPT-1 and GPT-2, the first two models in the GPT series created by OpenAI. But it’s only in the 2020s that LLMs become mainstream, increasingly bigger (in terms of parameters), and hence more powerful, with well-known examples like GPT-4 and LLaMa.
How do LLMs Work?
The key to the success of modern LLMs is the transformer architecture. Before transformers were developed by Google researchers, modeling natural language was a very challenging task. Despite the rise of sophisticated neural networks –i.e., recurrent or convolutional neural networks– the results were only partly successful.
The main challenge lies in the strategy these neural networks use to predict the missing word in a sentence. Before transformers, state-of-the-art neural networks relied on the encoder-decoder architecture, a powerful yet time-and-resource-consuming mechanism that is unsuitable for parallel computing, hence limiting the possibilities for scalability.
Transformers provide an alternative to traditional neural to handle sequential data, namely text (although transformers have also been used with other data types, like images and audio, with equally successful results).
Components of LLMs
Transformers are based on the same encoder-decoder architecture as recurrent and convolutional neural networks. Such a neural architecture aims to discover statistical relationships between tokens of text.
This is done through a combination of embedding techniques. Embeddings are the representations of tokens, such as sentences, paragraphs, or documents, in a high-dimensional vector space, where each dimension corresponds to a learned feature or attribute of the language.
The embedding process takes place in the encoder. Due to the huge size of LLMs, the creation of embedding takes extensive training and considerable resources. However, what makes transformers different compared to previous neural networks is that the embedding process is highly parallelizable, enabling more efficient processing. This is possible thanks to the attention mechanism.
Recurrent and convolutional neural networks make their word predictions based exclusively on previous words. In this sense, they can be considered unidirectional. By contrast, the attention mechanism allows transformers to predict words bidirectionally, that is, based on both the previous and the following words. The goal of the attention layer, which is incorporated in both the encoder and the decoder, is to capture the contextual relationships existing between different words in the input sentence.
To know in detail how the encoder-decoder architecture works in transformers, we highly recommend you to read our Introduction to Using Transformers and Hugging Face.
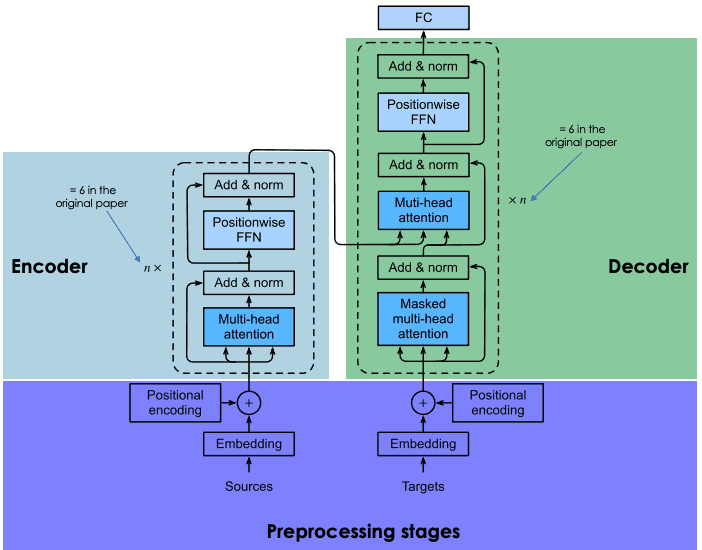
An explanation of the architecture of transformers
Training LLMs
Training transformers involves two steps: pretraining and fine-tuning.
Pre-training
In this phase, transformers are trained on large amounts of raw text data. The Internet is the primary data source.
The training is done using unsupervised learning techniques, an innovative type of training that doesn’t require human action to label data.
The goal of pre-training is to learn the statistical patterns of the language. The state-of-the-art strategy to achieve better accuracy of transformers is by making the model bigger (this can be achieved by increasing the number of parameters) and augmenting the size of the training data. As a result, most advanced LLMs come with billions of parameters (for example, PaLM 2 has 340 billion parameters, and GPT-4 is estimated to have around 1.8 trillion parameters) and have been trained on a humongous corpus of data.
This trend creates problems of accessibility. Given the size of the model and the training data, the pre-training process is normally time-consuming and costly, which only a reduced group of companies can afford.
Fine-tuning
Pre-training allows a transformer to gain a basic understanding of language, but it’s not enough to perform specific practical tasks with high accuracy.
To avoid time-consuming and costly iterations in the training process, transformers leverage transfer learning techniques to separate the (pre)training phase from the fine-tuning phase. This allows developers to choose pre-trained models and fine-tune them based on a narrower, domain-specific database. In many cases, the fine-tuning process is conducted with the assistance of human reviewers, using a technique called Reinforcement Learning from Human Feedback.
The two-step training process enables the adaptation of LLM to a wide range of downstream tasks. Put in another way, this feature makes LLMs the foundation model of endless applications built on top of them.
Multimodality of LLMs
The first modern LLMs were text-to-text models (i.e., they received a text input and generated text output). However, in recent years, developers have created so-called multimodal LLMs. These models combine text data with other kinds of information, including images, audio, and video. The combination of different types of data has allowed the creation of sophisticated task-specific models, such as OpenAI’s DALL-E. for image generation, and Meta’s AudioCraft for music and audio generation.
What are LLMs Used For?
Powered by transformers, modern LLMs have achieved state-of-the-art performance in multiple NLP tasks. Here are some of the tasks where LLMs have provided unique results:
- Text generation. LLMs like ChatGPT are capable of creating long, complex, and human-like text in a matter of seconds.
- Translation. When LLMs are trained in multiple languages, they can perform high-level translation operations. With multimodality, the possibilities are endless. For example, Meta’s SeamlessM4T model can perform speech-to-text, speech-to-speech, text-to-speech, and text-to-text translations for up to 100 languages depending on the task.
- Sentiment analysis. All kinds of sentiment analysis can be performed with LLMs, from positive and negative movie review predictions or marketing campaign opinions.
- Conversational AI. As the underlying technology of modern chatbots, LLMs are great for questioning, answering and holding conversations even in complex tasks.
- Autocomplete. LLMs can be used for autocomplete tasks, for example, in emails or messaging services. For example, Google’s BERT powers the autocomplete tool in Gmail.
Advantages of LLMs
LLM has immense potential for organizations, as illustrated by the widespread adoption of ChatGPT, which, only several months after its release, became the fastest-growing digital application of all time.
There are already a good number of business applications of LLMs, and the number of use cases will only increase as these tools become more ubiquitous across sectors and industries. Below, you can find a list of some of the benefits of LLMs:
- Content creation. LLMs are powerful all kinds of generative AI tools. With their capabilities, LLMs are great tools for generating content (mainly text, but, in combination with other models, they can also generate images, videos, and audio). Depending on the data used in the fine-tuning process, LLMs can deliver accurate, domain-specific content in any sector you may think of, from legal and finance to healthcare and marketing.
- Increased effectiveness in NLP tasks. As explained in the previous section, LLMs provide unique performance in many NLP tasks. They are capable of understanding human language and interact with humans with unprecedented accuracy. However, it’s important to note that these tools are not perfect and can still throw inaccurate results or even hallucinations overall,
- Increased efficiency. One of the main business benefits of LLMs is that they are perfect for completing monotonous, time-consuming tasks in a matter of seconds. While there are big prospects for companies that can benefit from this leap in efficiency, there are profound implications for workers and the job market that require consideration.
Challenges and Limitations of LLMs
LLMs are at the forefront of the generative AI revolution. However, as always occurs with emerging technologies, with power comes responsibility. Despite the unique capabilities of LLM, it’s important to consider its potential risks and challenges.
Below, you can find a list of risks and challenges associated with the widespread adoption of LLMs:
- Lack of transparency. Algorithmic opacity is one of the main concerns associated with LLMs. These modes are often labeled as ‘black box’ models because of their complexity, which makes it impossible to monitor their reasoning and inner workings. AI providers of proprietary LLMs are often reluctant to provide information about their models, which makes monitoring and accountability very difficult.
- LLM monopoly. Given the considerable resources required to develop, train, and operate LLMs, the market is highly concentrated in a bunch of Big Tech companies with the necessary know-how and resources. Fortunately, an increasing number of open-source LLMs are reaching the market, making it easier for developers, AI researchers, and society to understand and operate LLMs.
- Bias and discrimination. Biased LLM models can result in unfair decisions that often exacerbate discrimination, particularly against minority groups. Again, transparency is essential here to better understand and address potential biases.
- Privacy issues. LLMs are trained with vast amounts of data mainly extracted indiscriminately from the Internet. Commonly, it often contains personal data. This can lead to issues and risks related to data privacy and security.
- Ethical considerations. LLMs can sometimes lead to decisions that have serious implications in our lives, with significant impacts on our fundamental rights. We explored the ethics of generative AI in a separate post.
- Environmental considerations. Researchers and environmental watchdogs are raising concerns about the environmental footprint associated with training and operating LLMs. Proprietary LLMs rarely publish information on the energy and resources consumed by LLMs, nor the associated environmental footprint, which is extremely problematic with the rapid adoption of these tools.
Different Types and Examples of LLMs
The design of LLMs makes them extremely flexible and adaptable models. This modularity translates into different kinds of LLMs, in particular:
- Zero-shot LLMs. These models are capable of completing a task without having received any training example. For example, consider an LLM that is capable of understanding new slang based on the positional and semantic relationships of these new words with the rest of the text.
- Fine-tuned LLMs. It’s very common for developers to take a pre-trained LLM and fine-tune it with new data for specific purposes. To learn more about LLM fine-tuning, read our article Fine-Tuning LLaMA 2: A Step-by-Step Guide to Customizing the Large Language Model.
- Domain-specific LLMs. These models are specifically designed to capture the jargon, knowledge, and particularities of a particular field or sector, such as healthcare or legal. When developing these models, it’s important to choose curated training data, so that the model meets the standards of the field at hand.
Nowadays, the number of proprietary and open-source LLMs is rapidly growing. You may have already heard about ChatGPT, but ChatGPT is not a LLM, but an application built on top of a LLM. In particular, ChatGPT is powered by GPT-3.5, whereas ChatGPT-Plus is powered by GPT-4, currently the most powerful LLM. To know more about how to use OpenAI’s GPT models, read our article Using GPT-3.5 and GPT-4 via the OpenAI API in Python.
Below, you can find a list of some other popular LLMs:
- BERT. Google in 2018 and released in open-source, BERT is one of the first modern LLM and one of the most successful. Check our article What is BERT? to know everything about this classical LLM.
- PaLM 2. A more advanced LLM than its predecessor PaLM, PaLM 2 is the LLM that powers Google Bard, the most ambitious chatbot to compete with ChatGPT.
- LLaMa 2. Developed by Meta, LLaMa 2 is one of the most powerful open-source LLMs in the market. To know more about this and other open-source LLMs, we recommend you to read our dedicated article with the 8 Top Open-Source LLMs.
Conclusion
LLMs are powering the current generative AI boom. The potential applications are so vast that every sector and industry, including data science, is likely to be affected by the adoption of LLMs in the future.
The possibilities are endless, but also the risks and challenges. With its transformative and, LLMs have sparked speculation about the future and how AI will affect the job market and many other aspects of our societies. This is an important debate that needs to be addressed firmly and collectively since there is so much at stake.
DataCamp is working hard to provide comprehensive and accessible resources for everyone to keep updated with AI development. Check them out:
- Large Language Models (LLMs) Concepts Course
- How to Build LLM Applications with LangChain
- How to Train an LLM with PyTorch: A Step-By-Step Guide
- 8 Top Open-Source LLMs for 2024 and Their Uses
- Llama.cpp Tutorial: A Complete Guide to Efficient LLM Inference and Implementation
- Introduction to LangChain for Data Engineering & Data Applications
- LlamaIndex: A Data Framework for the Large Language Models (LLMs) based applications
- How to Learn AI From Scratch in 2024: A Complete Expert Guide

Code Along Series: Become an AI Developer
Build AI Systems and develop AI Applications using OpenAI, LangChain, Pinecone and Hugging Face!

