Se stai leggendo questo articolo, probabilmente hai già sentito parlare dei large language model (LLM). Chi non ne ha sentito parlare? In fin dei conti, gli LLM sono alla base degli strumenti super popolari che alimentano l’attuale rivoluzione dell’IA generativa, tra cui ChatGPT, Google Bard e DALL-E.
Per fare la loro magia, questi strumenti si basano su una tecnologia potente che consente loro di elaborare dati e generare contenuti accurati in risposta alla domanda posta dall’utente. È qui che entrano in gioco gli LLM.
Questo articolo ha l’obiettivo di introdurti agli LLM. Dopo aver letto le sezioni seguenti, sapremo cosa sono gli LLM, come funzionano, i diversi tipi di LLM con esempi, nonché i loro vantaggi e limiti.
Per chi è alle prime armi, il nostro corso sui concetti dei Large Language Model (LLM) è il punto di partenza perfetto per una panoramica approfondita. Se invece hai già familiarità con gli LLM e vuoi fare un passo avanti imparando a creare applicazioni basate su LLM, dai un’occhiata al nostro articolo Come creare applicazioni LLM con LangChain.
Iniziamo!
Che cos’è un Large Language Model?
Gli LLM sono sistemi di IA usati per modellare ed elaborare il linguaggio umano. Si chiamano “large” perché questi modelli sono in genere composti da centinaia di milioni o addirittura miliardi di parametri che ne definiscono il comportamento, pre-addestrati su un enorme corpus di testi.
La tecnologia alla base degli LLM si chiama rete neurale transformer, più semplicemente transformer. Come spiegheremo più nel dettaglio nella prossima sezione, un transformer è un’architettura neurale innovativa nell’ambito del deep learning.
Presentati dai ricercatori di Google nel famoso paper del 2017 Attention is All You Need, i transformer sono in grado di svolgere compiti di elaborazione del linguaggio naturale (NLP) con un’accuratezza e una velocità senza precedenti. Grazie alle loro capacità uniche, i transformer hanno segnato un grande balzo in avanti nelle potenzialità degli LLM. Si può dire che, senza i transformer, l’attuale rivoluzione dell’IA generativa non sarebbe possibile.
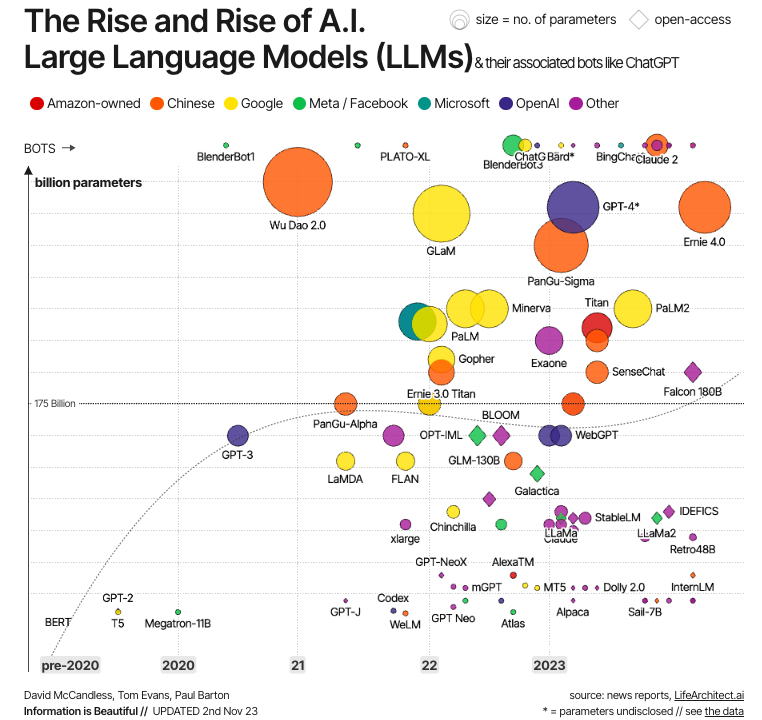
Fonte: Information is Beautiful
Questa evoluzione è illustrata nel grafico qui sopra. Come possiamo vedere, i primi LLM moderni sono stati creati subito dopo lo sviluppo dei transformer, con esempi significativi come BERT – il primo LLM sviluppato da Google per testare la potenza dei transformer –, nonché GPT-1 e GPT-2, i primi due modelli della serie GPT creati da OpenAI. Ma è solo negli anni 2020 che gli LLM diventano mainstream, sempre più grandi (in termini di parametri) e quindi più potenti, con esempi noti come GPT-4 e LLaMa.
Come funzionano gli LLM?
La chiave del successo dei moderni LLM è l’architettura transformer. Prima che i transformer venissero sviluppati dai ricercatori di Google, modellare il linguaggio naturale era un compito molto impegnativo. Nonostante l’ascesa di reti neurali sofisticate – ad esempio ricorrenti o convoluzionali –, i risultati erano solo parzialmente soddisfacenti.
La sfida principale risiede nella strategia con cui queste reti neurali prevedono la parola mancante in una frase. Prima dei transformer, le reti neurali allo stato dell’arte si basavano sull’architettura encoder-decoder, un meccanismo potente ma dispendioso in termini di tempo e risorse, non adatto all’elaborazione parallela e quindi limitante per la scalabilità.
I transformer offrono un’alternativa ai tradizionali modelli neurali per gestire dati sequenziali, ovvero il testo (sebbene i transformer siano stati utilizzati con successo anche con altri tipi di dati, come immagini e audio).
Componenti degli LLM
I transformer si basano sulla stessa architettura encoder-decoder delle reti neurali ricorrenti e convoluzionali. Questa architettura neurale mira a scoprire relazioni statistiche tra i token di testo.
Ciò avviene tramite una combinazione di tecniche di embedding. Gli embedding sono rappresentazioni di token, come frasi, paragrafi o documenti, in uno spazio vettoriale ad alta dimensionalità, in cui ogni dimensione corrisponde a una caratteristica o un attributo del linguaggio appreso.
Il processo di embedding avviene nell’encoder. Data la grande dimensione degli LLM, la creazione degli embedding richiede un addestramento intensivo e notevoli risorse. Tuttavia, ciò che rende i transformer diversi rispetto alle reti neurali precedenti è che il processo di embedding è altamente parallelizzabile, consentendo un’elaborazione più efficiente. Questo è possibile grazie al meccanismo di attenzione.
Le reti neurali ricorrenti e convoluzionali effettuano le loro previsioni basandosi esclusivamente sulle parole precedenti. In questo senso, possono essere considerate unidirezionali. Al contrario, il meccanismo di attenzione consente ai transformer di prevedere le parole in modo bidirezionale, cioè basandosi sia sulle parole precedenti sia su quelle successive. L’obiettivo dello strato di attenzione, presente sia nell’encoder sia nel decoder, è catturare le relazioni contestuali tra le diverse parole nella frase di input.
Per conoscere nel dettaglio come funziona l’architettura encoder-decoder nei transformer, ti consigliamo vivamente di leggere la nostra Introduzione all’uso dei Transformer e di Hugging Face.
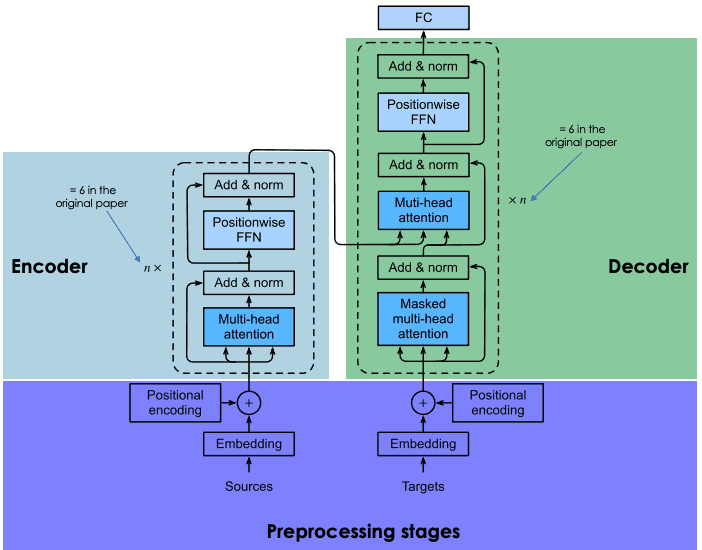
Una spiegazione dell’architettura dei transformer
Addestramento degli LLM
L’addestramento dei transformer prevede due fasi: pre-training e fine-tuning.
Pre-training
In questa fase, i transformer vengono addestrati su grandi quantità di dati testuali grezzi. Internet è la principale fonte di dati.
L’addestramento avviene con tecniche di apprendimento non supervisionato, un tipo di training innovativo che non richiede l’intervento umano per etichettare i dati.
L’obiettivo del pre-training è apprendere i modelli statistici del linguaggio. La strategia più avanzata per ottenere una migliore accuratezza dei transformer consiste nell’ingrandire il modello (aumentando il numero di parametri) e nell’ampliare la dimensione dei dati di addestramento. Di conseguenza, gli LLM più avanzati hanno miliardi di parametri (per esempio, PaLM 2 ne ha 340 miliardi e si stima che GPT-4 ne abbia circa 1,8 trilioni) e sono stati addestrati su un corpus di dati enorme.
Questa tendenza crea problemi di accessibilità. Data la dimensione del modello e dei dati, il processo di pre-training è in genere lungo e costoso, sostenibile solo da un numero ristretto di aziende.
Fine-tuning
Il pre-training consente a un transformer di acquisire una comprensione di base del linguaggio, ma non basta per svolgere compiti pratici specifici con alta accuratezza.
Per evitare iterazioni lunghe e costose nel processo di training, i transformer sfruttano tecniche di transfer learning per separare la fase di (pre)training da quella di fine-tuning. Ciò consente agli sviluppatori di scegliere modelli pre-addestrati e affinarli su un database più ristretto e specifico di dominio. In molti casi, il processo di fine-tuning viene svolto con l’assistenza di revisori umani, usando una tecnica chiamata Reinforcement Learning from Human Feedback.
Il training in due fasi consente di adattare gli LLM a un’ampia gamma di task a valle. In altre parole, questa caratteristica rende gli LLM il modello fondativo di innumerevoli applicazioni costruite sopra di essi.
Multimodalità degli LLM
I primi LLM moderni erano modelli text-to-text (cioè ricevevano un input testuale e generavano output testuale). Negli ultimi anni, però, gli sviluppatori hanno creato i cosiddetti LLM multimodali. Questi modelli combinano dati testuali con altri tipi di informazioni, incluse immagini, audio e video. La combinazione di diversi tipi di dati ha permesso la creazione di modelli sofisticati per compiti specifici, come il DALL-E di OpenAI per la generazione di immagini e l’AudioCraft di Meta per la generazione di musica e audio.
A cosa servono gli LLM?
Grazie ai transformer, i moderni LLM hanno raggiunto prestazioni all’avanguardia in molteplici task di NLP. Ecco alcuni dei compiti in cui gli LLM hanno fornito risultati unici:
- Generazione di testo. LLM come ChatGPT sono in grado di creare testi lunghi, complessi e simili a quelli umani in pochi secondi.
- Traduzione. Quando gli LLM sono addestrati su più lingue, possono eseguire traduzioni di alto livello. Con la multimodalità, le possibilità sono infinite. Ad esempio, il modello SeamlessM4T di Meta può effettuare traduzioni speech-to-text, speech-to-speech, text-to-speech e text-to-text fino a 100 lingue a seconda del task.
- Analisi del sentiment. Tutti i tipi di analisi del sentiment possono essere eseguiti con gli LLM, dalle previsioni di recensioni cinematografiche positive/negative alle opinioni su campagne di marketing.
- IA conversazionale. Come tecnologia alla base dei moderni chatbot, gli LLM sono ottimi per porre domande, rispondere e sostenere conversazioni anche in compiti complessi.
- Autocomplete. Gli LLM possono essere utilizzati per compiti di completamento automatico, ad esempio in email o servizi di messaggistica. Per esempio, BERT di Google alimenta lo strumento di completamento automatico in Gmail.
Vantaggi degli LLM
Gli LLM hanno un potenziale enorme per le organizzazioni, come dimostra l’ampia adozione di ChatGPT che, pochi mesi dopo il lancio, è diventata l’applicazione digitale a crescita più rapida di sempre.
Esistono già numerose applicazioni business degli LLM e il numero di casi d’uso aumenterà man mano che questi strumenti diventeranno più ubiqui tra settori e industrie. Di seguito trovi un elenco di alcuni benefici degli LLM:
- Creazione di contenuti. Gli LLM sono potenti strumenti di IA generativa di ogni tipo. Grazie alle loro capacità, sono ottimi per generare contenuti (principalmente testo ma, in combinazione con altri modelli, anche immagini, video e audio). A seconda dei dati usati nel fine-tuning, gli LLM possono fornire contenuti accurati e specifici di dominio in qualsiasi settore, dal legale e la finanza alla sanità e al marketing.
- Maggiore efficacia nei task di NLP. Come spiegato nella sezione precedente, gli LLM offrono prestazioni uniche in molti compiti di NLP. Sono in grado di comprendere il linguaggio umano e interagire con le persone con un’accuratezza senza precedenti. Tuttavia, è importante notare che questi strumenti non sono perfetti e possono ancora restituire risultati inesatti o persino allucinazioni.
- Aumento dell’efficienza. Uno dei principali vantaggi per le aziende è che gli LLM sono perfetti per completare compiti monotoni e dispendiosi in termini di tempo in pochi secondi. Sebbene ci siano grandi prospettive per le imprese che possono beneficiare di questo salto di efficienza, ci sono profonde implicazioni per i lavoratori e il mercato del lavoro che richiedono attenzione.
Sfide e limiti degli LLM
Gli LLM sono in prima linea nella rivoluzione dell’IA generativa. Tuttavia, come spesso accade con le tecnologie emergenti, a grandi poteri corrispondono grandi responsabilità. Nonostante le capacità uniche degli LLM, è importante considerarne i potenziali rischi e le sfide.
Di seguito trovi un elenco di rischi e sfide associati all’adozione diffusa degli LLM:
- Mancanza di trasparenza. L’opacità algoritmica è una delle principali preoccupazioni associate agli LLM. Questi modelli sono spesso etichettati come ‘scatole nere’ per via della loro complessità, che rende impossibile monitorarne il ragionamento e il funzionamento interno. I fornitori di IA con LLM proprietari sono spesso riluttanti a fornire informazioni sui loro modelli, rendendo molto difficile il monitoraggio e la responsabilità.
- Monopolio degli LLM. Dati i notevoli mezzi necessari per sviluppare, addestrare e gestire gli LLM, il mercato è altamente concentrato in poche Big Tech con il know-how e le risorse necessarie. Fortunatamente, un numero crescente di LLM open source sta arrivando sul mercato, rendendo più facile per sviluppatori, ricercatori di IA e società comprendere e utilizzare gli LLM.
- Bias e discriminazione. Modelli LLM con bias possono portare a decisioni ingiuste che spesso acuiscono la discriminazione, in particolare contro gruppi minoritari. Anche qui la trasparenza è essenziale per comprendere e affrontare meglio i potenziali bias.
- Problemi di privacy. Gli LLM sono addestrati con enormi quantità di dati estratti per lo più indiscriminatamente da Internet. Spesso contengono dati personali. Questo può comportare problemi e rischi legati alla privacy e alla sicurezza dei dati.
- Considerazioni etiche. Gli LLM possono talvolta portare a decisioni con serie implicazioni nelle nostre vite, con impatti significativi sui diritti fondamentali. Abbiamo esplorato l’etica dell’IA generativa in un post a parte.
- Considerazioni ambientali. Ricercatori e associazioni ambientaliste sollevano preoccupazioni riguardo all’impronta ambientale associata all’addestramento e all’uso degli LLM. Gli LLM proprietari raramente pubblicano informazioni su energia e risorse consumate, né sull’impatto ambientale associato, il che è estremamente problematico con la rapida adozione di questi strumenti.
Tipologie ed esempi di LLM
Il design degli LLM li rende modelli estremamente flessibili e adattabili. Questa modularità si traduce in diversi tipi di LLM, in particolare:
- LLM zero-shot. Questi modelli sono in grado di completare un compito senza aver ricevuto alcun esempio di training. Per esempio, considera un LLM capace di comprendere un nuovo gergo sulla base delle relazioni posizionali e semantiche di queste nuove parole con il resto del testo.
- LLM con fine-tuning. È molto comune che gli sviluppatori prendano un LLM pre-addestrato e lo affinino con nuovi dati per scopi specifici. Per saperne di più sul fine-tuning degli LLM, leggi il nostro articolo Fine-tuning di LLaMA 2: guida passo passo per personalizzare il Large Language Model.
- LLM specifici di dominio. Questi modelli sono progettati appositamente per catturare il gergo, le conoscenze e le particolarità di un determinato ambito o settore, come la sanità o il legale. Quando si sviluppano questi modelli, è importante scegliere dati di training curati, in modo che il modello rispetti gli standard del settore in questione.
Oggi, il numero di LLM proprietari e open source sta crescendo rapidamente. Potresti aver già sentito parlare di ChatGPT, ma ChatGPT non è un LLM, bensì un’applicazione costruita sopra un LLM. In particolare, ChatGPT è alimentato da GPT-3.5, mentre ChatGPT-Plus è basato su GPT-4, attualmente l’LLM più potente. Per sapere come usare i modelli GPT di OpenAI, leggi il nostro articolo Uso di GPT-3.5 e GPT-4 via OpenAI API in Python.
Di seguito trovi un elenco di altri LLM popolari:
- BERT. Creato da Google nel 2018 e rilasciato in open source, BERT è uno dei primi LLM moderni e tra i più riusciti. Consulta il nostro articolo Che cos’è BERT? per sapere tutto su questo classico LLM.
- PaLM 2. Un LLM più avanzato del suo predecessore PaLM, PaLM 2 è l’LLM che alimenta Google Bard, il chatbot più ambizioso in competizione con ChatGPT.
- LLaMa 2. Sviluppato da Meta, LLaMa 2 è uno degli LLM open source più potenti sul mercato. Per saperne di più su questo e altri LLM open source, ti consigliamo di leggere il nostro articolo dedicato sui 8 migliori LLM open source.
Conclusione
Gli LLM stanno alimentando l’attuale boom dell’IA generativa. Le potenziali applicazioni sono così vaste che ogni settore e industria, compresa la data science, sarà probabilmente influenzato dall’adozione degli LLM in futuro.
Le possibilità sono infinite, ma anche i rischi e le sfide. Con il loro potenziale trasformativo, gli LLM hanno alimentato speculazioni sul futuro e su come l’IA influenzerà il mercato del lavoro e molti altri aspetti delle nostre società. È un dibattito importante che va affrontato con decisione e collettivamente, dato che la posta in gioco è alta.
DataCamp sta lavorando sodo per offrire risorse complete e accessibili a tutti per restare aggiornati sugli sviluppi dell’IA. Dagli un’occhiata:
- Corso sui concetti dei Large Language Model (LLM)
- Come creare applicazioni LLM con LangChain
- Come addestrare un LLM con PyTorch: guida passo passo
- 8 migliori LLM open source per il 2024 e i loro usi
- Llama.cpp Tutorial: guida completa a inferenza ed esecuzione efficiente di LLM
- Introduzione a LangChain per Data Engineering e applicazioni dati
- LlamaIndex: un framework dati per applicazioni basate su Large Language Model (LLM)
- Come imparare l’IA da zero nel 2024: guida completa degli esperti


