Introduction to Data Engineering
BeginnerSkill Level
4 hr
109.1K learners

In the rapidly evolving landscape of today's world, where data is experiencing exponential growth and computational demands are skyrocketing, traditional approaches to processing information are often inadequate. This is where distributed processing comes into play.
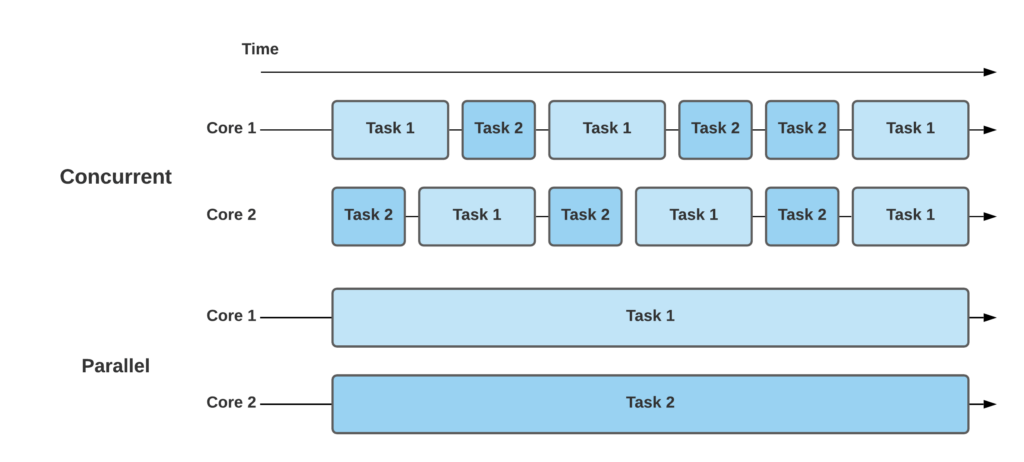
Distributed processing refers to the process of breaking down complex tasks into smaller, manageable parts and executing them concurrently across multiple machines or computing resources. By harnessing the collective power of these resources, distributed processing enables us to tackle large-scale computations efficiently and effectively.
The need for computing power to train machine learning (ML) models has been increasing rapidly. Since 2010, the demand for computing has grown ten times every 18 months. However, the capabilities of AI accelerators like GPUs and TPUs have not kept up with this demand, as they have only doubled during the same period.
As a result, organizations now need five times more AI accelerators or nodes every year and a half to train the newest ML models and take advantage of the latest ML capabilities. To fulfill these requirements, distributed computing is the only solution.
This tutorial introduces Ray, an open-source Python framework that simplifies distributed computing.
Ray is an open-source framework designed to enable the development of scalable and distributed applications in Python. It provides a simple and flexible programming model for building distributed systems, making it easier to leverage the power of parallel and distributed computing. Some key features and capabilities of the Ray framework include:
Ray allows you to easily parallelize your Python code by executing tasks concurrently across multiple CPU cores or even across a cluster of machines. This enables faster execution and improved performance for computationally intensive tasks.
Ray provides a distributed execution model, allowing you to scale your applications beyond a single machine. It offers tools for distributed scheduling, fault tolerance, and resource management, making it easier to handle large-scale computations.
With Ray, you can define Python functions that can be executed remotely. This enables you to offload computation to different nodes in a cluster, distributing the workload and improving overall efficiency.
Ray provides high-level abstractions for distributed data processing, such as distributed data frames and distributed object stores. These features make it easier to work with large datasets and perform operations like filtering, aggregation, and transformation in a distributed manner.
Ray includes built-in support for reinforcement learning algorithms and distributed training. It provides a scalable execution environment for training and evaluating machine learning models, enabling efficient experimentation and faster training times.
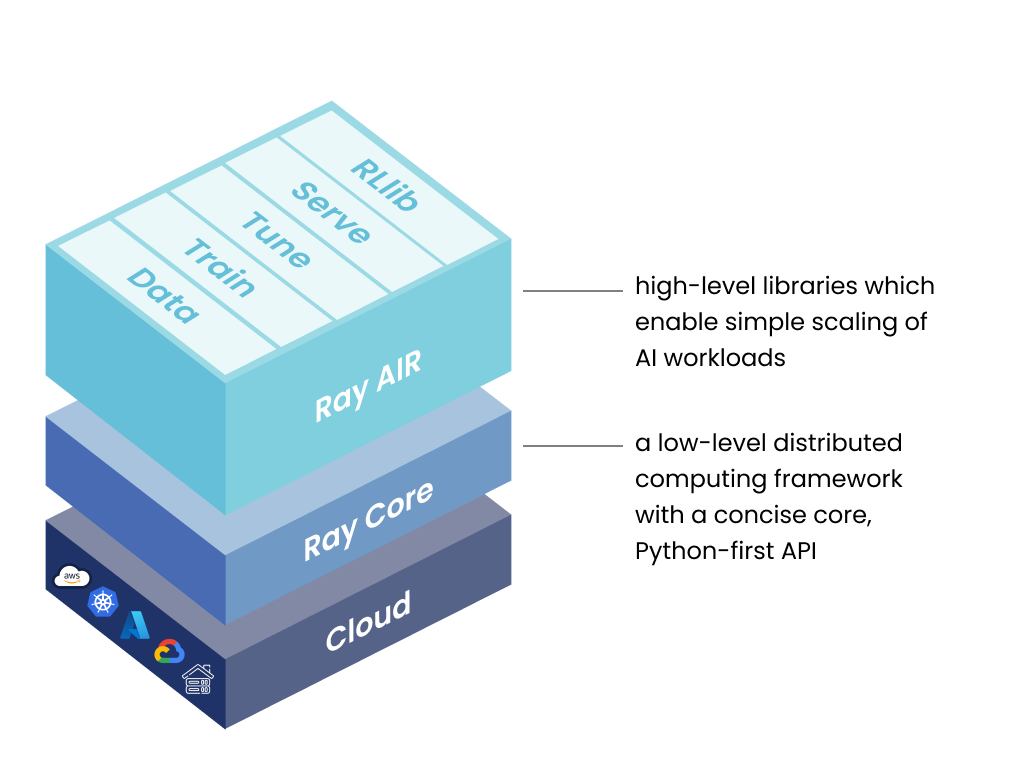
Ray's framework encompasses three layers:
This open-source collection of Python libraries is designed specifically for ML engineers, data scientists, and researchers. It equips them with a unified and scalable toolkit for developing ML applications. The Ray AI Runtime consists of 5 core libraries:
Achieve scalability and flexibility in data loading and transformation across various stages, such as training, tuning, and prediction, regardless of the underlying framework.
Enables distributed model training across multiple nodes and cores, incorporating fault tolerance mechanisms that seamlessly integrate with widely used training libraries.
Scale your hyperparameter tuning process to enhance model performance, ensuring optimal configurations are discovered.
Effortlessly deploy models for online inference with Ray's scalable and programmable serving capabilities. Optionally, leverage micro batching to further enhance performance.
Seamlessly integrate scalable distributed reinforcement learning workloads with other Ray AIR libraries, enabling efficient execution of reinforcement learning tasks.
This open-source Python library serves as a general-purpose distributed computing solution. It empowers ML engineers and Python developers to scale Python applications and accelerate the execution of machine learning workloads.
Ray allows you to run functions independently on separate Python workers. These functions are called "tasks" and can be executed asynchronously. Ray lets you specify the resources (such as CPUs, GPUs, and custom resources) that each task requires. The cluster scheduler then distributes the tasks across the cluster to run them in parallel.
Actors are an extension of Ray's API that goes beyond functions (tasks) to work with classes. An actor is like a worker that holds state or acts as a service. When you create a new actor, a dedicated worker is assigned to it. The methods of the actor are scheduled on that specific worker and can access and change its state. Similar to tasks, actors can also have resource requirements, such as CPUs, GPUs, and custom resources.
In Ray, tasks and actors operate on objects. These objects are known as remote objects because they can be stored anywhere within a Ray cluster. We use object references (object refs) to refer to these remote objects. Ray's distributed shared-memory object store caches these remote objects, and each node in the cluster has its own object store. In a cluster, a remote object can exist on one or multiple nodes, regardless of which node holds the object reference(s).
A Ray cluster consists of a group of worker nodes that are connected to a central Ray head node. These clusters can be configured with a fixed size or can dynamically autoscale based on the resource requirements of the applications running on the cluster.
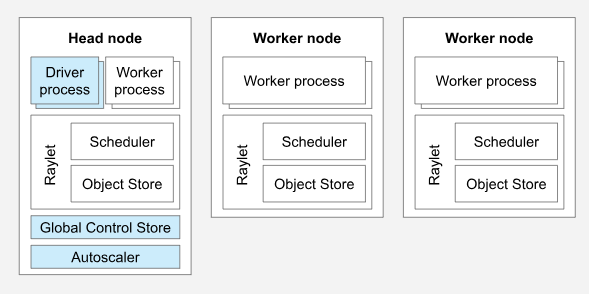
A Ray cluster with two worker nodes. Image Source
A Ray cluster comprises a collection of worker nodes linked to a central Ray head node. These clusters can either have a predefined size or dynamically scale up or down based on the resource requirements of the applications operating within the cluster.
In every Ray cluster, there is a designated head node responsible for cluster management tasks such as running the autoscaler and Ray driver processes. Although the head node functions as a regular worker node, it may also be assigned tasks and actors, which is not ideal for large-scale clusters.
Worker nodes in a Ray cluster are solely responsible for executing user code within Ray tasks and actors. They are not involved in running any head node management processes. These worker nodes play a crucial role in distributed scheduling and are responsible for storing and distributing Ray objects throughout the cluster's memory.
The Ray autoscaler, running on the head node, adjusts the cluster size based on the resource requirements of the Ray workload. When the workload surpasses the cluster's capacity, the autoscaler attempts to add more worker nodes. Conversely, it removes idle worker nodes from the cluster. It's crucial to note that the autoscaler responds exclusively to task and actor resource requests and does not consider application metrics or physical resource utilization.
A Ray job refers to a single application comprising a set of Ray tasks, objects, and actors that are derived from a common script. The worker responsible for executing the Python script is referred to as the job's driver.
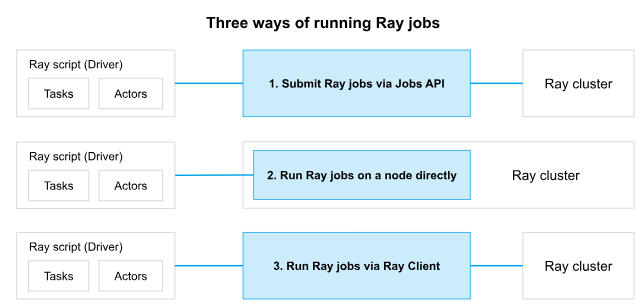
Three ways of running a job on a Ray cluster. Image Source
You can install the latest official version of Ray from PyPI. If you want to install Ray primarily for machine learning applications, you most likely need ray[air].
pip install ray[air]For general Python applications:
pip install ray[default]

OpenAI's ChatGPT, which is powered by the Ray platform, benefits from parallelized model training. This means that instead of using just one computer, multiple computers work together to train the model. This allows ChatGPT to train on a much larger dataset than it could handle on its own.
When training a language model like ChatGPT, it involves analyzing huge amounts of text data and adjusting the model's settings to improve its predictions. This process can be computationally intensive and time-consuming, especially when dealing with massive datasets.
Ray's distributed data structures and optimizers played a crucial role in managing and processing large volumes of data during the ChatGPT's training.
With Ray, you can run functions on a cluster as remote tasks. To use Ray, you need to add the @ray.remote decorator to the function you want to run remotely. Instead of calling the function directly, you use .remote() after the function name. This remote call gives you a future object, which is like a reference to the function's result. You can retrieve the actual result by using ray.get on the future object.
# Define the square task.
@ray.remote
def square(x):
return x * x
# Launch four parallel square tasks.
futures = [square.remote(i) for i in range(4)]
# Retrieve results.
print(ray.get(futures))The following code conducts a randomized search for hyperparameter tuning of a support vector machine (SVM) model using the Ray library for parallel processing. It begins by importing the necessary libraries and loading a dataset of handwritten digits from scikit-learn.
The search space for hyperparameters is defined in a dictionary called param_space. An SVM model with a radial basis function kernel is created using the sklearn.svm module, and a RandomizedSearchCV object is instantiated with the model and search space.
The code then sets up Ray for parallel processing and executes the hyperparameter search using the fit method. By leveraging Ray's parallel processing capabilities, the code speeds up the search process, exploring various hyperparameter combinations to find the best configuration for the SVM model.
import numpy as np
from sklearn.datasets import load_digits
from sklearn.model_selection import RandomizedSearchCV
from sklearn.svm import SVC
digits = load_digits()
param_space = {
'C': np.logspace(-6, 6, 30),
'gamma': np.logspace(-8, 8, 30),
'tol': np.logspace(-4, -1, 30),
'class_weight': [None, 'balanced'],
}
model = SVC(kernel='rbf')
search = RandomizedSearchCV(model, param_space, cv=5, n_iter=300, verbose=10)
import joblib
from ray.util.joblib import register_ray
register_ray()
with joblib.parallel_backend('ray'):
search.fit(digits.data, digits.target)

In this blog, we explored the power of distributed processing using the Ray framework in Python. Ray provides a simple and flexible solution for parallelizing AI and Python applications, allowing us to leverage the collective power of multiple machines or computing resources. We discussed the key features and capabilities of the Ray framework, including task parallelism, distributed computing, remote function execution, and distributed data processing.
Looking to dive into parallel programming frameworks beyond Ray? Meet Dask, a formidable contender! If you're itching to explore its capabilities, check out DataCamp’s captivating course, Parallel Programming with Dask in Python. Discover a whole new world of parallel computing and unleash the full potential of your Python applications!
Plus, discover how data scientists use the cloud to deploy data science solutions to production or to expand computing power in our blog post on Cloud Computing and Architecture for Data Scientists.
Tutorial
Bex Tuychiev
Tutorial
Kurtis Pykes
Tutorial
Zoumana Keita
Tutorial
Bex Tuychiev
Tutorial
Hafsa Jabeen
code-along
Sayak Paul





