Text embeddings are an essential tool in the field of natural language processing (NLP). They are numerical representations of text where each word or phrase is represented as a dense vector of real numbers.
The significant advantage of these embeddings is their ability to capture semantic meanings and relationships between words or phrases, which enables machines to understand and process human language efficiently.
Text embeddings are crucial in scenarios like text classification, information retrieval, and semantic similarity detection.
OpenAI, known for its remarkable contributions to the field of artificial intelligence, currently recommends using the Ada V2 model for creating text embeddings. This model is derived from the GPT series of models and has been trained to capture even better the contextual meaning and associations present in the text.
If you're not familiar with OpenAI's API or the openai Python package, it's recommended that you read Using GPT-3.5 and GPT-4 via the OpenAI API in Python before proceeding. This guide will help you set up the accounts and understand the benefits of API usage.
This tutorial also involves the use of clustering, a machine learning technique used to group similar instances together. If you're not familiar with clustering, particularly k-Means clustering, you should consider reading Introduction to k-Means Clustering with scikit-learn in Python.
What Can You Use Text Embeddings For?
Text-embeddings can be applied to multiple use cases including but not limited to:
- Text classification. Text embeddings help in creating accurate models for sentiment analysis or topic identification tasks.
- Information retrieval. They can be used to retrieve information relevant to a specific query, similar to what we can find in a search engine.
- Semantic similarity detection. Embeddings can identify and quantify the semantic similarity between text snippets.
- Recommendation systems. They can improve the quality of recommendations by understanding user preferences based on their interaction with text data.
- Text generation. Embeddings are used to generate more coherent and contextually relevant text.
- Machine translation. Text embeddings can capture semantic meanings across languages, which can improve the quality of machine translation process.
Getting Set Up
Several Python packages are required to work with text embeddings, as outlined below:
- os: A built-in Python library for interacting with the operating system.
- openai: the Python client to interact with OpenAI API.
- scipy.spatial.distance: provides functions to compute the distance between different data points.
- sklean.cluster.KMeans: used to compute KMeans clustering.
- umap.UMAP: a technic used to reduce the dimensionality of high-dimensional data.
Before using them, make sure to install openai, scipy, plotly sklearn, and umap with the following command. The full code is available in this DataLab workbook.
pip install -U openai, scipy, plotly-express, scikit-learn, umap-learnAfter a successful execution of the previous command, all the libraries can be imported as follows:
import os
import openai
from scipy.spatial import distance
import plotly.express as px
from sklearn.cluster import KMeans
from umap import UMAPNow we can set up the OpenAI API key as follows:
openai.api_key = "<YOUR_API_KEY_HERE>"Note: You will need to set up your own API KEY. The one from the source code is not available and was only for individual use.
The Code Pattern for Calling GPT via the API
The following helper function can be used to embed a line of text using the OpenAI API. In the code, we are using the existing ada version 2 to generate the embeddings.
def get_embedding(text_to_embed):
# Embed a line of text
response = openai.Embedding.create(
model= "text-embedding-ada-002",
input=[text_to_embed]
)
# Extract the AI output embedding as a list of floats
embedding = response["data"][0]["embedding"]
return embeddingAbout the Dataset
In this section, we will consider the Amazon musical instrument review data freely available from Kaggle. The data can also be downloaded from my Github account as follows:
import pandas as pd
data_URL = "https://raw.githubusercontent.com/keitazoumana/Experimentation-Data/main/Musical_instruments_reviews.csv"
review_df = pd.read_csv(data_URL)
review_df.head()
Out of all the columns, we are only interested in the reviewText column.
review_df = review_df[['reviewText']]
print("Data shape: {}".format(review_df.shape))
display(review_df.head())Data shape: (10261, 1)
There are many reviews in the dataset. For cost optimization purpose we will only use 100 randomly selected rows.

Now, we can generate the embeddings for each row in the whole dataset by applying the previous function using the lambda expression:
review_df = review_df.sample(100)
review_df["embedding"] = review_df["reviewText"].astype(str).apply(get_embedding)
# Make the index start from 0
review_df.reset_index(drop=True)
review_df.head(10)
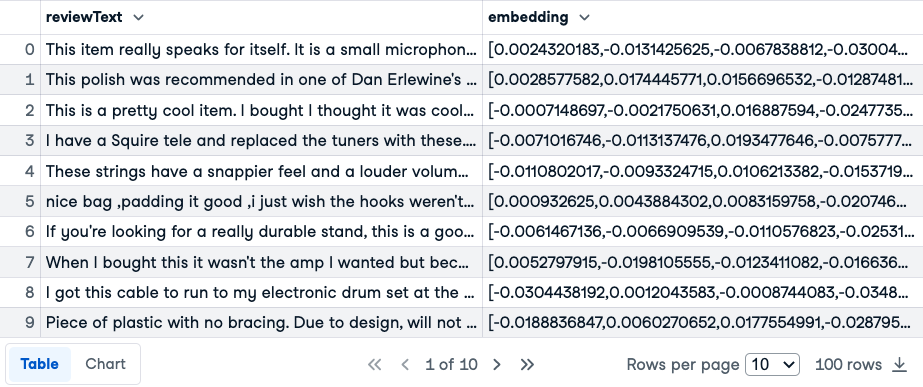
First 10 rows of the reviews and emdeddings
Understand Text Similarity
To showcase the concept of semantic similarity, let’s consider two reviews that could have similar sentiments:
“This product is fantastic!”
“It really exceeded my expectations!”
Using pdist() from scipy.spatial.distance, we can calculate the euclidean distance between their embeddings.
The Euclidean distance corresponds to the square root of the sum of the squared difference between the two embeddings, and an illustration is given below:
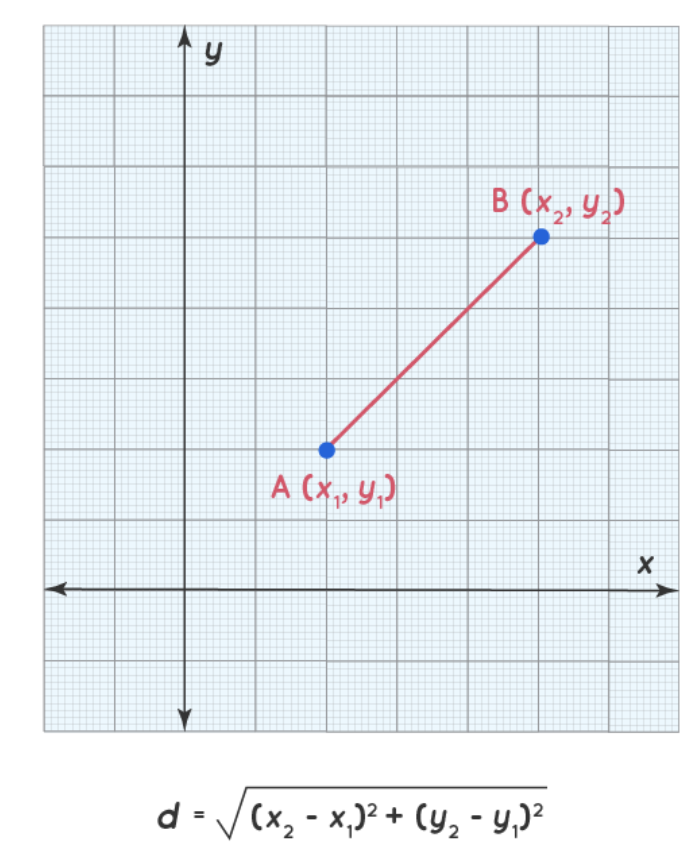
Illustration of the euclidean distance (source)
If these reviews are indeed similar, the distance should be relatively small.
Next, consider two different reviews:
“This product is fantastic!"
"I'm not satisfied with the item."
The distance between these reviews' embeddings will be significantly larger than the distance between the similar reviews.
Case Study: Use Text Embedding for Cluster Analysis
The text embeddings we have generated can be used to perform cluster analysis such that similar musical instruments that are more similar to each other can be grouped together.
There are multiple clustering algorithms available such as K-Means, DBSCAN, hierarchical clustering, and Gaussian Mixture Models. In this specific use case, we will use KMeans clustering. However, our An Introduction to Hierarchical Clustering in Python provides a good framework to understand the ins and outs of hierarchical clustering and its implementation in Python.
Cluster the text data
Using K-means clustering requires predefining the number of clusters to use, and we will set that number to 3 with the n_clusters parameter as follows:
kmeans = KMeans(n_clusters=3)
kmeans.fit(review_df["embedding"].tolist())Reduce dimensions of embedded text data
Humans are typically only able to visualize up to three dimensions. This section will use the UMAP, a relatively fast and scalable tool to perform dimensionality reduction.
First, we define an instance of the UMAP class and apply the fit_transform function to the embeddings, which generates a two-dimensional representation of the reviews embedding that can be plotted.
reducer = UMAP()
embeddings_2d = reducer.fit_transform(review_df["embedding"].tolist())Visualize the clusters
Finally, create a scatter plot of the 2-dimensional embeddings. The x and y coordinates are respectively taken from embeddings_2d[: , 0] and embeddings_2d[: , 1]
The clusters will be visually distinct:
fig = px.scatter(x=embeddings_2d[:, 0], y=embeddings_2d[:, 1], color=kmeans.labels_)
fig.show()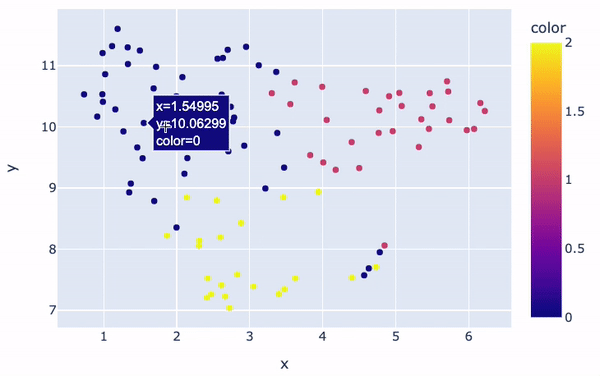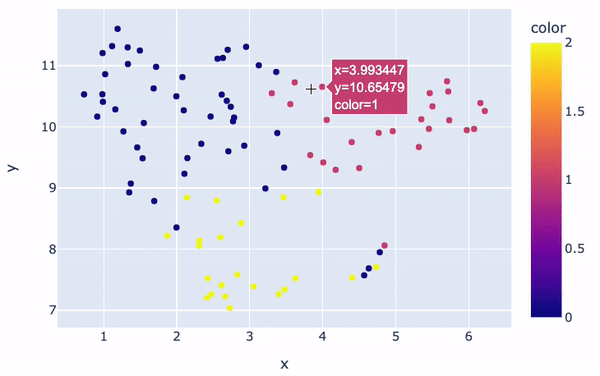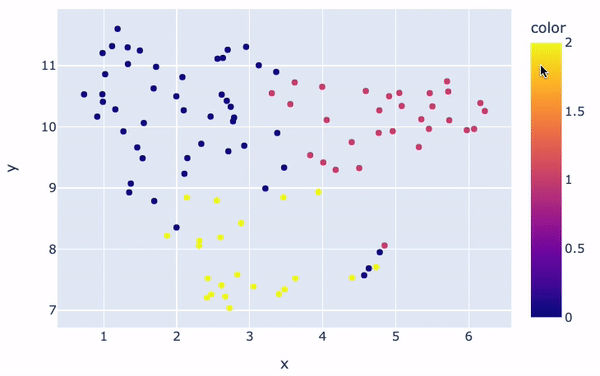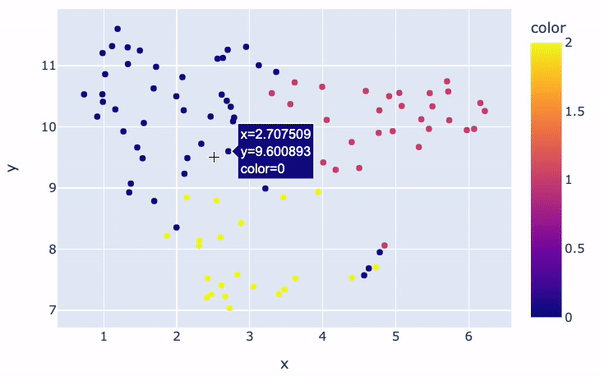
Clusters visualization
There are overall three main clusters with different colors. The color of each review in the figure is determined by the cluster label/number assigned to it by the K-Means model. Also, the positioning of each point gives a visual representation of how similar a given review of the others.
Take it to the Next Level
To deepen your understanding of text embeddings and the OpenAI API, consider the following material from DataCamp: Fine-Tuning GPT-3 Using the OpenAI API and Python and The OpenAI API in Python Cheat Sheet. It helps you unleash the full potential of GPT-3 through fine-tuning and also illustrates how to use OpenAI API and Python to improve this advanced neural network model for your specific use case.




